A arquitetura Lambda, proposta por Nathan Marz (criador da arquitetura) representa a tecnologia mais avançada desse assunto em relaçăo aos aspectos de modelagem de aplicaçőes Big Data. Veremos nesse artigo as possíveis questőes relacionadas ŕ evoluçăo da Big Data para Fast Data, um novo conceito que promete acelerar o processamento de quantidades imensas de informaçőes, bem como discutir ferramentas cujo propósito é facilitar o desenvolvimento de software nesse cenário.
Embora, năo exista uma definiçăo formal do tamanho, formato ou aplicabilidade que engloba todas as características peculiares de uma perspectiva puramente computacional, Big Data pode ser definida como uma quantidade de dados maior do que a tecnologia mais popular é capaz de processar, e por essa definiçăo, é um alvo em movimento, ou seja, o que é Big Data de hoje năo será amanhă.
Năo deixe de conferir também todos os outros cursos de Java da DevMedia.
O modelo 3vs descreve a Big Data através dos eixos Volume, Variedade e Velocidade, conforme ilustrado na Figura 1. Por Volume entende-se o aumento exponencial da quantidade de dados presentes, gerados e manipulados pelos sistemas computacionais atuais. A Variedade diz respeito ŕs diferentes fontes de dados que podemos ter hoje em dia e ao contraponto entre a era SQL, onde havia uma estrutura unificada para descriçăo e acesso aos dados, e a era NoSQL, onde existem distintos modelos de dados - e até quem pregue que năo se deve haver modelo de dados nenhum, ou seja, os dados devem ser completamente năo estruturados. Finalmente, a Velocidade pode ser traduzida pela necessidade de sistemas cada vez mais rápidos que possam processar essa infinidade de dados – estruturados e năo estruturados - em tempo real.
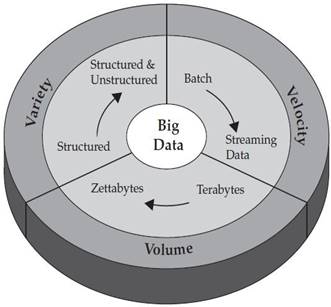
Figura 1. 3Vs da Big Data
Os dois primeiros Vs – Variedade e Volume – săo geralmente resolvidos pelo uso de banco de dados NoSQL e de MapReduce. Contudo, para atingir os tręs eixos envolvidos na Big Data temos que ser capazes de lidar năo só com um enorme volume de dados vindos de variadas fontes, mas também de fazer isso em uma velocidade que seja próxima a tempo real.
Com vista nesse problema, Nathan Marz publicou uma arquitetura genérica que ele desenvolveu enquanto trabalhava no Twitter. A Figura 2 apresenta uma visăo geral da arquitetura Lambda. A proposta é que uma mesma informaçăo – na figura anotada como “new data” - irá disparar dois fluxos independentes de análise. No primeiro fluxo existem dois componentes: o primeiro é denominado “batch layer”, e é responsável por persistir os dados, possivelmente em um banco de dados NoSQL ou em um sistema de arquivos distribuídos (de forma parecida ao que estamos acostumados); o outro componente, chamado de “serving layer”, é responsável por realizar análises ou views sobre esses dados persistidos e disponibilizá-las através de distintas visőes. Por outro lado, há a “speed layer”, que cria análises em tempo real. Ambas as camadas podem ser consultadas pela aplicaçăo final, por exemplo, um site de e-commerce. Além disso, os dados de ambas podem ainda ser computados, cruzados ou agregados.
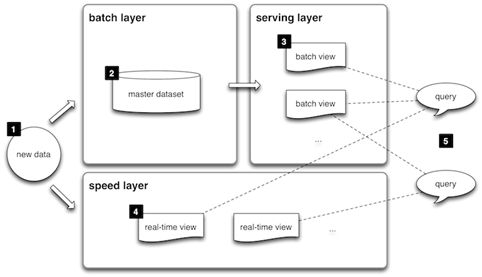
Figura 2. Visăo geral da arquitetura Lambda
A ideia da arquitetura é que essas duas camadas sejam complementares, ou seja, que em toda aplicaçăo as camadas sejam igualmente importantes. Conforme ilustrado na Figura 3, a camada de batch sempre está um passo atrás do tempo real, já que é esperado que a camada batch faça análises mais complicadas e que tais análises sejam feitas contra uma massa muito maior de dados (ilustrada em azul na figura). Além disso, depois que os dados em tempo real sejam “alcançados” pela análise batch, as informaçőes das views em tempo real podem ser simplesmente descartadas para dar lugar a informaçőes mais atualizadas.
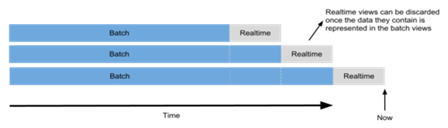
Figura 3. Relaçăo entre os dados analisados em Batch e em Tempo real
Além disso, ainda que năo esteja explícito no modelo, a arquitetura Lambda prevę a imutabilidade dos dados na camada batch. Ou seja, é esperado que nenhuma informaçăo persistida na camada batch seja excluída ou alterada, uma ideia interessante, mas controversa. Na Tabela 1 temos um exemplo consistido do valor de endereços para dois usuários, onde, em lugar de cada usuário possuir apenas um valor para endereço (como estamos acostumados), temos persistido o histórico completo dos endereços desses usuários, e cada um tem um timestamp representando seu momento de inserçăo.
A ideia é que năo há a necessidade de modificar os dados, já que o fato de uma pessoa mudar de endereço năo modifica que essa mesma pessoa já teve outro lugar como endereço no passado. Assim, a imutabilidade dos dados cria uma relaçăo direta entre a informaçăo e tempo. Isso traz vantagens muito interessantes, como a possibilidade de criar diferentes views sobre o mesmo conjunto de dados, a possibilidade de excluir ou desativar tais views conforme ficam obsoletas, uma maior segurança em relaçăo ŕ consistęncia de dados e a possibilidade de recuperar informaçőes que forem danificadas por um erro de programaçăo. Obviamente, existem também problemas como, por exemplo, uma possível duplicaçăo nos dados e um aumento exponencial na quantidade de informaçőes armazenadas.
|
Usuário |
Endereço |
Timestamp |
|
José |
Lins-SP |
Março/1983 |
|
Maria |
Santo Ângelo-RS |
Setembro/1986 |
|
Maria |
Florianópolis-SC |
Fevereiro/2015 |
|
José |
Florianópolis-SC |
Fevereiro/2015 |
Tabela 1. Imutabilidade de dados
Ainda que năo seja revolucionária em si, a arquitetura Lambda oferece uma boa maneira de organizar o pensamento do arquiteto de software e facilitar a troca de informaçőes sobre projetos de desenvolvimento. Ainda assim, algumas dúvidas podem surgir quando vemos esse o modelo. Podemos listar as mais importantes:
- No mundo real, qual tipo de aplicaçăo pode utilizar a arquitetura Lambda?
- MapReduce e Hadoop năo săo suficientes para Big Data?
- Se o Hadoop năo é suficiente, que ferramenta vou utilizar?
- Se é possível, porque năo fazer todo o processamento em tempo real?
Para responder a primeira questăo, devemos introduzir um termo relativamente novo: Fast Data. A Fast Data pode ser definida como a capacidade de analisar um fluxo enorme de informaçăo em tempo real. O mercado está se movendo na direçăo da Fast Data, e muitos analistas já começam a discutir quais săo os requisitos dessa nova etapa da Big Data. Assim, algumas aplicaçőes já podem se beneficiar dessa novidade, dentre as quais podemos citar:
- Aplicaçőes dependentes de contexto;
- Aplicaçőes dependentes da localizaçăo do usuário;
- Aplicaçőes de emergęncia;
- Redes sociais.
No último caso, muitas redes sociais já oferecem uma experięncia em tempo real, podemos ver isso quando tuitamos ou compartilhamos algo no Facebook. Por outro lado, existem aplicaçőes, como o Waze e o próprio Google, que năo oferecem uma atualizaçăo em tempo real. Essas aplicaçőes - provavelmente por alguma decisăo de projeto – possuem um comportamento mais próximo do MapReduce, já que, atendem um tsunami de informaçăo de forma escalável e com alta vasăo, mas com uma alta latęncia – ou seja, uma informaçăo nova demora até estar disponível.
Nesse sentido, é importante notar que mesmo sendo revolucionário, é um erro enorme considerar o paradigma MapReduce como soluçăo de todos os problemas computacionais. Isso porque, por projeto tal paradigma foi desenvolvido como soluçăo de um problema muito específico: aumentar a vasăo na análise de dados. Ou seja, o Map Reduce – e os frameworks que o implementam, como o Hadoop – foram pensados para analisar uma quantidade imensa de dados. Entretanto, esse aumento de vasăo năo implica, necessariamente, num aumento da velocidade dessa análise.
Com vista nessa limitaçăo, muitas ferramentas estăo sendo desenvolvidas para resolver esse problema. Entre elas podemos destacar:
- Apache
Storm, também desenvolvida por Nathan Marz, oferece uma interessante abstraçăo
para o desenvolvimento de aplicaçőes em tempo real. Sua ideia é criar um
cluster no qual os desenvolvedores possam publicar topologias responsáveis pela
execuçăo de tarefas. Conforme ilustrado na Figura
4, cada topologia é composta por dois componentes: os spouts, que săo responsáveis
por receber a streaming de dados; e os bolts que processarăo esses dados. Além
disso, o elemento de informaçăo básico que flui nessa arquitetura é chamado de
tupla.
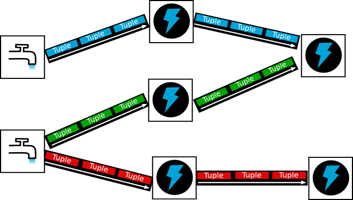
Figura 4. Apache Storm - Apache
Kafka, desenvolvido em Scala pelo LinkedIn, é um sistema de troca de mensagens
altamente escalável e em tempo real. Como apresentado na Figura 5, a ideia é criar um broker (agenciador), um componente de
software que se localiza entre os produtores e os consumidores das mensagens a
fim de gerenciar e acelerar a análise dos dados. A empresa Confluent foi criada pelos mesmos desenvolvedores do Kafka para oferecer a aplicaçăo como
serviço.
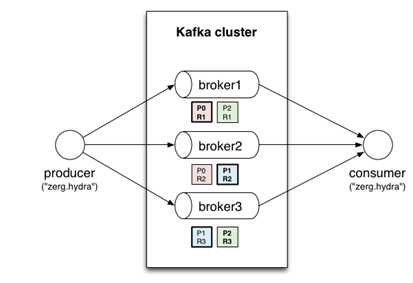
Figura 5. Apache Kafka - Apache Spark tem como trunfo o uso de memória distribuída a fim de realizar o máximo de computaçăo possível diretamente na memória principal. A empresa Databricks também foi criada pelos desenvolvedores dessa ferramenta para oferecer suporte e liderar seu desenvolvimento.
- Apache
Flume também oferece uma interessante abstraçăo sobre o Map Reduce comum,
conectando fontes de dados streaming com persistęncia no HDFS através de um
canal em memória primária, conforme descrito na Figura 6.
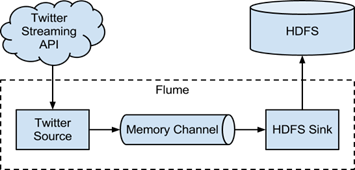
Figura 6. Apache Flume



A primeira conclusăo que podemos depreender da lista de ferramentas é que a fundaçăo Apache lidera os esforços. Isso é ótimo porque além de atestar a qualidade do software desenvolvido, garante que os códigos estăo disponíveis para consulta e que existe uma comunidade de suporte. Além disso,
- Todas as aplicaçőes săo desenvolvidas para atuar em clusteres altamente escaláveis;
- A maioria usa ferramentas que também săo parte do Hadoop, como o Zookeeper;
- Todos usam em algum dos seus componentes o MapReduce;
- O Spark e o Flume tentam realizar suas atividades em tempo real através do uso intensivo da memória primária;
- O Storm atinge o tempo real através da criaçăo de monitores que gerenciam o tempo de cada atividade.
Entăo, qual ferramenta escolher? O Storm parece ser a aplicaçăo mais completa, por ser mais antiga e possuir uma abstraçăo simples e poderosa.
Para ilustrar essa simplicidade, o código das Listagens 1 a 3 apresentam um código completo para executar o Storm em um ambiente de desenvolvimento Java. Essa aplicaçăo, distribuída como exemplo no próprio código do Storm, irá contar as palavras de uma série de sentenças emitidas por um Spout. Na Listagem 1 apresenta-se a dependęncia Maven que deve ser adicionado ao pom.xml.
Listagem 1. Dependęncia Maven para o Storm
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>0.9.4</version>
</dependency>
Na Listagem 2 apresenta-se uma topologia deve ser criada: o ponto mais importante é a declaraçăo do Spout e dos Bolts. Os Bolts também estăo definidos como sub-classes da Listagem 2.
Listagem 2. Topologia e definiçăo de spouts
package storm.starter;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.task.ShellBolt;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
import storm.starter.spout.RandomSentenceSpout;
import java.util.HashMap;
import java.util.Map;
/**
* This topology demonstrates Storm's stream groupings and multilang capabilities.
*/
public class WordCountTopology {
public static class SplitSentence extends ShellBolt implements IRichBolt {
public SplitSentence() {
super("python", "splitsentence.py");
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
public static class WordCount extends BaseBasicBolt {
Map<String, Integer> counts = new HashMap<String, Integer>();
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
String word = tuple.getString(0);
Integer count = counts.get(word);
if (count == null)
count = 0;
count++;
counts.put(word, count);
collector.emit(new Values(word, count));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
}
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new RandomSentenceSpout(), 5);
builder.setBolt("split", new SplitSentence(), 8).shuffleGrouping("spout");
builder.setBolt("count", new WordCount(), 12).fieldsGrouping("split", new Fields("word"));
Config conf = new Config();
conf.setDebug(true);
if (args != null && args.length > 0) {
conf.setNumWorkers(3);
StormSubmitter.submitTopology(args[0], conf, builder.createTopology());
}
else {
conf.setMaxTaskParallelism(3);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("word-count", conf, builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
}
}Na Listagem 3 apresenta-se o código para o Spout.
Listagem 3. Código do Spout
package storm.starter.spout;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;
import java.util.Map;
import java.util.Random;
public class RandomSentenceSpout extends BaseRichSpout {
SpoutOutputCollector _collector;
Random _rand;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
_collector = collector;
_rand = new Random();
}
@Override
public void nextTuple() {
Utils.sleep(100);
String[] sentences = new String[]{ "the cow jumped over the moon", "an apple a day keeps the doctor away",
"four score and seven years ago", "snow white and the seven dwarfs", "i am at two with nature" };
String sentence = sentences[_rand.nextInt(sentences.length)];
_collector.emit(new Values(sentence));
}
@Override
public void ack(Object id) {
}
@Override
public void fail(Object id) {
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}Nesse sentido, é fácil chegar em uma conclusăo um tanto quanto perigosa: se é possível, o melhor é fazer tudo em tempo real. Contudo, é importante lembrar que trabalhar em tempo real tem um custo, que pode se manifestar em distintas perspectivas:
- Melhor (mais caro) ambiente computacional;
- Equipe mais qualificada;
- Maior custo de manutençăo em caso de mudanças;
- Difícil integraçăo com os ambientes atuais;
Por isso, ao desenvolver para tempo real em Big Data, a arquitetura Lambda oferece um importante ponto de partida, além de ser um meio tempo interessante: temos o melhor dos dois mundos – batch e real time - de maneira organizada. A Figura 7 ilustra uma possível instância da arquitetura Lambda projetada a partir de tręs tecnologias:
- O Hadoop e o HDFS com seu sistema de arquivos distribuídos;
- O banco de dados NoSQL Apache HBase; e
- O Apache Storm.
O Hadoop foi usado na Batch Layer para armazenar os dados no HDFS e computar views usando o MapReduce. Essas podem ser agregaçőes sobre os dados, contagens ou análises estatísticas. Por exemplo, um e-commerce poderia usar essas views para computar o total histórico de vendas de um determinado produto. O Storm é empregado para processar a stream de entrada e criar visőes mais simples, que provavelmente consideram apenas um intervalo pequeno de tempo – por exemplo, o mesmo e-commerce pode computar quais foram os produtos mais acessados nos últimos 15 minutos. Finalmente, na Serving Layer essas visőes săo combinadas e armazenadas no HBase, facilitando seu acesso pela aplicaçăo. O interessante é que mesmo essas quatro tecnologias sendo desenvolvidas em Java ou ferramentas relacionadas (Scala e Clojure), podemos utilizar várias outras linguagens de programaçăo para desenvolver a iteraçăo entre os componentes.
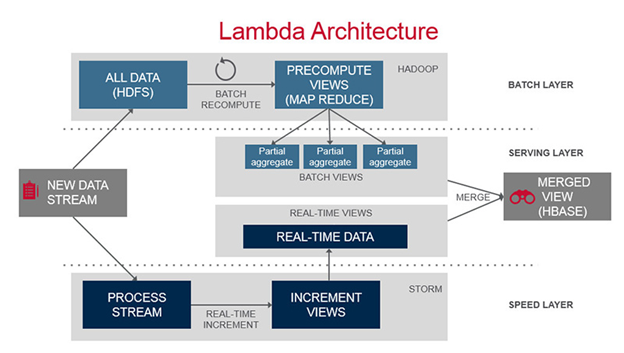
Figura 7. Uma possível instância da arquitetura Lambda
Normalmente, lidar com tantos componentes năo é simples.
No exemplo anterior foram listadas tręs ferramentas que fogem completamente do padrăo tradicional de cięncia da computaçăo. Assim, existe um notável esforço para simplificar a implementaçăo desse tipo de arquitetura, dentre os quais o mais destacado é o Buildoop, uma ferramenta semelhante ao Apache Bigtop mas com foco na construçăo do ecossistema da arquitetura Lambda. O Buildoop é baseado em Groovy e JSON para definiçőes das ferramentas que văo ser empregadas na arquitetura.
A Listagem 4 ilustra os comandos para criaçăo de arquiteturas baseadas na “receita” cluster.json - como é chamada esse tipo de definiçăo -, para diferentes tipos de ambientes. A ferramenta está em rápido em desenvolvimento, mas apenas nas fases iniciais de maturidade. Contudo, já pode ser usada para construir sistema completos (vide seçăo Links.)
Listagem 4. Receita cluster.json
deploop -f conf/cluster.json --deploy batch
deploop -f conf/cluster.json --deploy batch,speed,bus,serving
deploop --cluster production --layer batch --stop
deploop --cluster production --layer batch --startEm resumo, a adiçăo de uma outra camada de processamento tem grandes vantagens: os dados (históricos) podem ser processados com alta precisăo sem perda da informaçăo de curto prazo, como alertas e insights fornecidos pela camada de tempo real. Além disso, a carga computacional de uma nova camada é compensada pela reduçăo drástica da leitura e escrita no dispositivo de armazenamento, o que permite acessos muito mais rápidos.
Do ponto de vista conceitual, ainda que seja recente, os conceitos em Big Data evoluem muito rapidamente. Por isso, é importante se manter informado sobre as novidades para a aplicaçăo da Fast Data. Nesse sentido, o site da arquitetura Lambda oferece muitos recursos para entender mais e também oferece listas de ferramentas que se encaixam para cada uma das tręs camadas: batch,speed e serving.
Links
Arquitetura Lambda
http://lambda-architecture.net/
3Vs da Big Data
https://apandre.wordpress.com/2013/11/19/datawatch/
Fast Data
http://blogs.wsj.com/cio/2015/01/06/fast-data-applications-emerge-to-manage-real-time-data/
Apache Storm
https://storm.apache.org/
https://github.com/apache/storm
Apache Kafka
http://kafka.apache.org/
https://github.com/apache/kafka
Apache Spark
https://spark.apache.org
https://github.com/apache/spark
Apache Flume
https://flume.apache.org/
https://github.com/apache/flume
Deploop
http://deploop.github.io/







