Como funciona, para que serve e como usar com o Hibernate
Qualquer aplicaçăo web que acesse bancos de dados precisa estar preparada para receber vários acessos simultâneos de usuários acessando a página e ainda assim acessar o banco de dados usando uma conexăo com o banco. Mas o que acontece quando o número de usuário é muito grande? Cada vez que uma requisiçăo é feita, o servidor deve abrir uma conexăo com o banco de dados e fechá-la no final da requisiçăo? Além do tempo de latęncia ser grande ao ficar abrindo e fechando conexőes com o banco, deixando o sistema mais lento, isso simplesmente pode deixar a aplicaçăo inutilizável no caso de um número grande de requisiçőes.
Para evitar que isso aconteça, é recomendado o uso de um connection pool para as conexőes com o banco dados. Nesse artigo, esse conceito será explicado em detalhes e um exemplo de uso com o framework Hibernate será mostrado.
Pré-requisitos
Quase todo o artigo pode ser perfeitamente entendido sem conhecimento de Hibernate. Para entender a parte específica para o framework, é necessário conhecer o mesmo. É aconselhável que o leitor já saiba o que săo conexőes JDBC e o que é um driver JDBC.
Como funciona
Um connection pool significaria “piscina de conexőes” em portuguęs. Basicamente, é uma camada que fica entre o cliente de banco de dados, que faz as conexőes com o banco, e o próprio banco. Em aplicaçőes Java, o cliente normalmente é um EJB, um Servlet, uma Action Struts, ou uma classe Java qualquer e o banco seria representado por uma conexăo com o driver JDBC para algum servidor de banco de dados.
A idéia dessa camada intermediária é que o cliente possa criar conexőes com o banco usando o connection pool quase da mesma forma que criaria usando JDBC diretamente, de modo que fica transparente para ele como a conexăo é retornada. O que importa é conseguir uma conexăo com o banco de dados para poder realizar as operaçőes desejadas.
As figuras 1 e 2 ilustram a forma de acesso ao pool de conexőes.
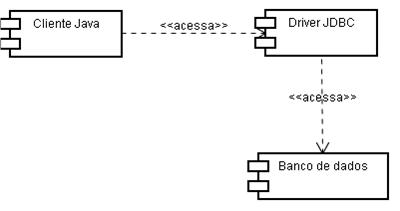
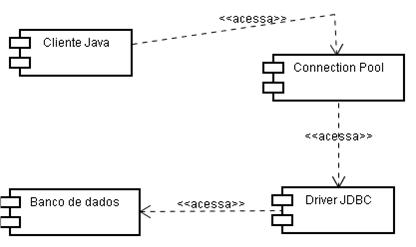
Mas o que faz o pool? Basicamente, ele mantém certo número de conexőes abertas com o banco de dados. Quando o cliente Java abre uma conexăo usando o pool, ao invés de abrir uma nova conexăo com o banco usando o driver JDBC, este simplesmente pega uma das conexőes que ele já mantinha aberta com o banco e a marca como alocada para aquele cliente Java.
O cliente Java entăo usa a conexăo normalmente e faz as operaçőes desejadas no banco. Quando o cliente fecha a conexăo usando o pool, este năo fecha a conexăo com o banco. Ao invés disso, mantém a mesma aberta, mas a marca como disponível.
Quando o número de conexőes que os clientes abrem usando o pool passa do número de conexőes que o connection pool mantém abertas, o pool abre uma nova conexăo com o banco de dados, a năo ser que tenha atingido um número máximo de conexőes reais, caso no qual seria lançada uma exceçăo.
Para que serve
Esse mecanismo tem duas vantagens chave:
- Evita a necessidade de ficar abrindo e fechando conexőes reais com o banco de dados toda hora, evitando assim o custo ocasionado pelo tempo de abrir e fechar as conexőes, tornando o aplicativo razoavelmente mais rápido.
- Permite servir um número grande de requisiçőes sem necessidade de manter um número tăo grande de conexőes com o banco. O número de conexőes do pool tem que ser tăo grande quanto o número de conexőes simultâneas.
Qualquer aplicaçăo J2EE bem feita deve usar pools de conexăo. Perceba que, apesar do conceito estar sendo aplicado para conexőes com o banco de dados, poderia perfeitamente ser aplicado para outros tipos de conexăo, como acessos a EJBs, servlets, etc. Para esses tipos de serviço, contudo, o container de aplicaçőes normalmente cria um connection pool internamente, livrando o desenvolvedor dessa preocupaçăo.
Mesmo para conexőes com o banco de dados, é possível configurar um connection pool no próprio container. Para isso, ao invés de obter uma conexăo JDBC diretamente a partir do driver, deve-se criar um DataSource no container (como o WebLogic, Tomcat, WebSphere, JRun, etc.) e configurá-lo para usar um pool de conexőes. Nossa aplicaçăo Java abriria entăo conexőes com o banco usando a especificaçăo JNDI, como ilustra a figura 3.
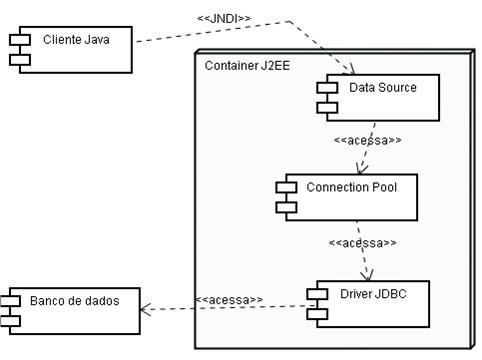
A explicaçăo detalhada de como configurar o connection pool nesse caso está fora do escopo desse artigo. Para mostrar pelo menos um exemplo, vejamos como ficaria o uso de connection pools usando o framework Hibernate.
Uso com o Hibernate
Como o leitor já sabe, o Hibernate tem uma abstraçăo a mais para a conexăo com o banco, que é a sessăo. No Hibernate, para realizar operaçőes com o banco usamos o objeto session, que pode ser obtido conforme ilustrado na listagem 01.
SessionFactory sessions = …;
//Obtém uma session factory a partir da configuraçăo do Hibernate
Session session = sessions.openSession();
// Abre uma session a partir da session factory
É obtido uma instância da classe SessionFactory a partir da configuraçăo do Hibernate. Entăo, essa instância é usada para construir a session, que é usada para realizar as operaçőes no banco. Para que seja possível realizar tais operaçőes, é óbvio que a session precisa obter uma conexăo com o banco de dados. O que queremos é que a session use um pool de conexőes para isso.
Existem várias maneiras de fazer isso. Caso a session obtenha uma conexăo para o banco via um datasource, obtido via JNDI, fica fácil, pois podemos configurar o container para usar um conection pool. Bastaria entăo configurar a session factory no “hibernate.cfg.xml” para obter as conexőes através de um datasource. Basicamente, isso poderia ser feito configurando o valor da propriedade hibernate.connection.datasource na configuraçăo do Hibernate com o nome JNDI do datasource criado no container.
A segunda maneira é usar o pool interno do Hibernate. Nesse modo, precisamos configurar no hibernate os dados de conexăo com o banco e informar o número máximo de conexőes do pool. Isso é feito configurando valores para as propriedades a seguir:
- hibernate.connection.driver_class – classe do Driver JDBC a ser instanciada
- hibernate.connection.url – URL de conexăo JDBC
- hibernate.connection.username – Nome de usuário do banco de dados
- hibernate.connection.password – Senha do usuário no banco de dados
- hibernate.connection.pool_size – Número máximo de conexőes abertas pelo pool.
As quatro primeiras propriedades simplesmente configuram os parâmetros para o driver JDBC. A última propriedade define o número máximo de conexőes abertas pelo pool.
Esse pool interno que vem com o Hibernate é suficiente para quando estamos desenvolvendo ou testando a aplicaçăo. Para rodá-la em um ambiente de produçăo, contudo, năo é recomendável o uso de uma implementaçăo tăo simples de connection pool.
Se ao invés de configurarmos o número máximo de conexőes com o banco através da propriedade hibernate.connection.pool_size nós configurarmos parâmetros específicos de um pool de terceiros, o hibernate tentará automaticamente usar esse pool ao invés do pool interno.
O pool de terceiros mais famoso que pode ser usando com o Hibernate é o chamado C3P0, que já vem junto com a distribuiçăo do Hibernate, na pasta lib. A listagem 2 mostra um exemplo de configuraçăo usando esse pool, usando como exemplo o banco de dados PostgreSQL.
hibernate.connection.driver_class = org.postgresql.Driver
hibernate.connection.url = jdbc:postgresql://localhost/mydatabase
hibernate.connection.username = myuser
hibernate.connection.password = secret
hibernate.c3p0.min_size=5
hibernate.c3p0.max_size=20
hibernate.c3p0.timeout=1800
hibernate.c3p0.max_statements=50
hibernate.dialect = org.hibernate.dialect.PostgreSQLDialect
Perceba que săo definidos mais parâmetros para o pool, como número mínimo e máximo de conexőes abertas, tempo de timeout, etc.
Bem, é isso. Esse foi um artigo bem básico sobre pools de conexăo. Nunca deixe de usá-los em suas aplicaçőes J2EE. Um abraço e até o próximo artigo!







