Nos últimos anos foi possível observar um crescimento vertiginoso no desempenho dos processadores com o surgimento das tecnologias multi-core e hyperthreading. Um fenômeno parecido ocorreu com as memórias, cuja velocidade de acesso aumentou significativamente.
No entanto, năo se pode dizer o mesmo para as tecnologias de disco rígido. Apesar do aumento da capacidade de armazenamento, em termos de desempenho a evoluçăo foi bem menor. Para constatar isso, basta observarmos que os discos rotativos mais rápidos da atualidade, de 15.000 RPM, já existem há mais de 10 anos.
As interfaces de conexăo também evoluíram, desde o SCSI, até SAS e FC, mas o meio físico continua fundamentalmente o mesmo. Neste cenário, a tecnologia SSD (Solid-state Disk) possibilita altíssimas velocidades de acesso, mas o seu custo ainda é proibitivo para grande parte das aplicaçőes, e a sua confiabilidade ainda năo está no mesmo nível dos discos de tecnologia tradicional.
Ou seja, ainda será necessário convivermos com os discos rotativos por algum tempo e, portanto é preciso aprender a extrair deles o máximo desempenho.
Quando falamos de armazenamento em geral, existem diversos fatores a serem analisados, como velocidade do disco, capacidade, interface de conexăo, nível de RAID e, em um nível mais alto, o tipo de filesystem adotado.
Neste artigo focaremos nesse último aspecto. Em particular, analisaremos este conteúdo relacionado ŕ plataforma Linux, que oferece diversas opçőes nesta área; diferentemente de outros sistemas operacionais, como o Windows, que oferece basicamente uma opçăo de sistema de arquivos de alta performance, o NTFS.
A seguir săo apresentados, com brevidade, os diferentes tipos de sistemas de arquivos que serăo analisados:
· ext3: sigla para “Third Extended Filesystem”. Foi criado por Stephen Tweedie em 1999 e integrado ao kernel em 2001. Até hoje é o filesystem mais comum em distribuiçőes Linux. O grande diferencial do ext3 para o seu antecessor, o ext2, está no fato dele incorporar a tecnologia de journaling, que permite ao filesystem ser recuperado rapidamente em caso de falha (ver BOX 1);
· ext4: sigla para “Fourth Extended Filesystem”, é o sucessor do ext3. Criado em 2008, tem como objetivo prover um melhor desempenho que o ext3;
· XFS: o XFS foi criado pela SGI (Silicon Graphics Inc.) em 1994 para a sua distribuiçăo de Unix, o IRIX. Seu código fonte foi liberado em 2000 e integrado ao kernel do Linux em 2002. O XFS possui características interessantes, como redimensionamento e desfragmentaçăo online e capacidade de “congelamento” do I/O para a execuçăo de cópias consistentes;
· JFS: sigla para “Journaling Filesystem”, foi criado pela IBM em 1990 para a sua distribuiçăo de Unix, o AIX. Posteriormente foi incorporado no OS/2 (sistema operacional para processadores Intel x86, comum nos anos 1990), e em 1999 seu código fonte foi liberado para a comunidade, para que fosse portado para Linux. O filesystem conhecido como JFS no Linux é equivalente ao JFS2 do IBM AIX, e năo deve ser confundido com o JFS1, também do AIX, porém mais antigo.
Journaling é uma tecnologia utilizada por filesystems modernos, onde todas as solicitaçőes de gravaçăo em disco săo realizadas primeiro em uma estrutura chamada journal, e só depois săo efetivamente gravadas em disco. Isto serve para garantir uma recuperaçăo rápida em caso de falhas de disco ou do servidor, como quedas de energia. O journal funciona como um log das transaçőes realizadas no filesystem, e os dados permanecem ali somente até serem persistidos em disco.
Conceitos gerais
Antes de apresentarmos os testes realizados, é importante compreender, ao menos de forma breve, alguns conceitos. Vamos iniciar esse estudo analisando os diferentes tipos de acesso:
· Sequencial: é o acesso realizado em uma ordem pré-estabelecida. Normalmente utilizado quando se precisa ler ou gravar um conjunto grande de dados, isto é, quando é menos custoso para o disco fazer poucos acessos sequenciais do que milhares de acessos randômicos. Por exemplo, quando um banco de dados precisa ler uma tabela inteira (“full table scan”), este se utiliza de uma leitura sequencial;
· Randômico: é o acesso realizado por meio de um endereço específico de um dado no disco. Normalmente utilizado para acessos pontuais, em pequenas quantidades. Por exemplo, quando um banco de dados faz uma busca de um registro por índice, ocorre uma leitura sequencial no índice, e uma vez que o ponteiro para o dado foi encontrado, ocorre uma leitura randômica para buscar o registro inteiro.
A seguir explicamos a diferença entre I/O síncrono e assíncrono, que săo particularmente relevantes para aplicaçőes que efetuam grande volume de escritas em disco:
· I/O Síncrono (sync): é aquele em que o kernel só responde para a aplicaçăo que o acesso foi concluído após este ter sido confirmado no disco. A aplicaçăo fica bloqueada naquele ponto até que a confirmaçăo seja recebida. No caso de escritas, isso ajuda a garantir que o dado de fato está no disco, ao preço de tornar a escrita potencialmente mais lenta;
· I/O Assíncrono (libaio): é aquele em que o kernel confirma a conclusăo do acesso assim que este for recebido, sem bloquear a aplicaçăo. No caso de leituras, existem mecanismos para informar a aplicaçăo de que o dado está disponível, como as funçőes select e poll do Linux, e no caso de escritas, o dado é colocado em memória pelo kernel para ser processado posteriormente.
Isso ajuda a tornar as aplicaçőes mais responsivas, ao preço de uma pequena probabilidade de perda de dados em caso de falha de energia.
Por padrăo, todas as solicitaçőes de leitura e escrita realizadas pelas aplicaçőes em sistemas Linux passam primeiro pela memória, antes de chegar no disco. Essa área de memória é chamada de cache de filesystem, e tem a finalidade principal de tornar mais rápido o acesso a arquivos muito utilizados.
Os sistemas Linux por padrăo utilizam boa parte da memória livre como cache de filesystem. Quando executamos o comando free para verificar a quantidade de memória livre no servidor, podemos perceber que existe uma coluna de nome cached, que indica a quantidade de memória alocada para o cache de filesystem no momento. Conforme as aplicaçőes demandam mais memória, o kernel dinamicamente devolve memória do cache para ser utilizada por estas.
Para algumas aplicaçőes específicas, contudo, pode ser benéfico pular a etapa de cache. Por exemplo, bancos de dados normalmente possuem uma estrutura própria de cache de dados, que por ter sido construída tendo em mente as suas estruturas internas de dados, săo mais eficientes do que o cache de filesystem, que é genérico e idealizado somente para acesso a arquivos. Nesses casos, podemos configurar a aplicaçăo para realizar o acesso diretamente ao disco (direct I/O), sem passar pelo cache.
É comum em bancos de dados, como o MySQL, Oracle e Sybase, a opçăo de utilizar os dispositivos de disco diretamente, em vez de filesystems tradicionais. Nesse caso, o acesso será realizado diretamente no disco, sem passar pelo cache do sistema operacional.
Nos nossos testes, utilizamos filesystems tradicionais, e configuramos o acesso com ou sem cache como um parâmetro.
Metodologia dos Testes
Para realizaçăo dos nossos testes, foram utilizados os seguintes cenários:
· Leitura Sequencial;
· Escrita Sequencial;
· Misto de Leitura/Escrita Sequenciais;
· Leitura Randômica;
· Escrita Randômica;
· Misto de Leitura/Escrita Randômicas.
Para cada cenário de teste, foram incluídas tręs variáveis, com todas as combinaçőes possíveis. A seguir podemos verificar as variáveis:
· I/O síncrono ou assíncrono;
· I/O com cache ou direto;
· Poucos arquivos grandes x muitos arquivos pequenos.
Tudo isso somado nos dá 48 casos de teste para cada um dos filesystems selecionados. Além destes cenários, foram criados outros dois, nos quais foi simulada uma carga de quatro processos em paralelo, realizando um misto de leituras e escritas randômicas, poucos arquivos grandes e I/O direto, só alternando entre I/O síncrono e assíncrono.
Para os testes, foi utilizada uma máquina virtual com CentOS 6.5 de 64 bits, 8GB de RAM, 2 vCPUs e 4 discos virtuais pré-alocados de 8GB, sendo um para cada filesystem em teste. A máquina virtual foi criada em ambiente VirtualBox, sobre Windows 7 em um computador com CPU i7-3520, 16GB de RAM e disco SATA de 500GB e 7200 RPM. Além disso, os discos foram formatados com o tamanho de bloco default de 4KB e montados com suas opçőes padrăo, sem otimizaçőes.
Ferramenta de Testes
Para este comparativo, foi utilizada a ferramentafio (Flexible I/O Tester), criada por Jens Axboe, que é um dos mantenedores do kernel do Linux. Esta ferramenta possui dezenas de opçőes e permite grande flexibilidade nos testes.
Para instalar o fio é preciso ter os pacotes libaio, gcc e make instalados, pois ele é distribuído na forma de código fonte. É possível baixar o pacote deste a partir do site do projeto (veja a seçăo Links). No nosso teste foi utilizada a versăo 2.1.5, cujo pacote se chama fio-2.1.5.tar.gz.
Para compilar o pacote, utilize os comandos apresentados na Listagem 1.
Listagem 1. Compilando e instalando o pacote do fio.
$ tar zxvf fio-2.1.5.tar.gz
$ cd fio-2.1.5
$ ./configure
$ make
$ sudo make installUma vez que o programa esteja compilado e instalado, podemos começar a explorar suas funcionalidades. Tipicamente, criamos um arquivo de configuraçăo com os parâmetros do teste que desejamos executar.
A seguir, apresentamos alguns dos principais parâmetros do fio:
· rw: indica o perfil de I/O que será realizado no teste. Pode ter os valores read (leitura sequencial), write (escrita sequencial), rw (leitura e escrita sequenciais), randread (leitura randômica), randwrite (escrita randômica) e randrw (leitura e escrita randômica);
· blocksize: indica o tamanho do bloco a ser utilizado nos testes, em bytes;
· ioengine: indica o tipo de I/O a ser realizado. Valores comuns săo sync (síncrono) e libaio (assíncrono);
· nrfiles: indica a quantidade de arquivos que serăo criados no filesystem de teste;
· size: indica o volume total de dados a ser criado no filesystem para os testes;
· directory: indica o caminho do diretório onde será executado o teste;
· runtime: indica a duraçăo do teste em segundos;
· direct: indica se o I/O deve utilizar cache ou năo (0 ou 1).
Na Listagem 2 podemos ver um exemplo de arquivo de configuraçăo do fio. Com este arquivo, o teste executará um job de nome “my_job” que faz somente leituras sequenciais, com blocos de 4 KB, de forma síncrona, com 200 arquivos totalizando 256 MB, no diretório /mnt/myfs, por 60 segundos.
Listagem 2. Exemplo de arquivo de configuraçăo do fio.
[my_job]
rw=read
blocksize=4096
ioengine=sync
nrfiles=200
size=256m
directory=/mnt/myfs
runtime=60Para submeter dois jobs em paralelo, basta colocar dois blocos de configuraçăo no mesmo arquivo.
Para executar o teste, grave as configuraçőes em um arquivo (aqui chamado de my_job.conf) e utilize o comando a seguir:
$ fio my_job.conf
Os resultados da execuçăo do fio săo bastante detalhados, e por isso podem ser difíceis de interpretar em um primeiro momento. Na Listagem 3 podemos verificar um exemplo.
Listagem 3. Exemplo de resultado gerado a partir da execuçăo do fio.
my_job: (g=0): rw=read, bs=4K-4K/4K-4K/4K-4K, ioengine=sync, iodepth=1
fio-2.1.5
Starting 1 process
my_job: Laying out IO file(s) (2 file(s) / 256MB)
Jobs: 1 (f=2): [R] [100.0% done] [29714KB/0KB/0KB /s] [7428/0/0 iops] [eta 00m:00s]
my_job: (groupid=0, jobs=1): err= 0: pid=20620: Tue Mar 4 14:00:23 2014
read : io=262144KB, bw=30330KB/s, iops=7582, runt= 8643msec
clat (usec): min=0, max=27853, avg=118.78, stdev=1053.20
lat (usec): min=0, max=27857, avg=122.89, stdev=1053.25
clat percentiles (usec):
| 1.00th=[ 3], 5.00th=[ 3], 10.00th=[ 3], 20.00th=[ 5],
| 30.00th=[ 5], 40.00th=[ 5], 50.00th=[ 5], 60.00th=[ 5],
| 70.00th=[ 5], 80.00th=[ 6], 90.00th=[ 6], 95.00th=[ 6],
| 99.00th=[ 5728], 99.50th=[ 9664], 99.90th=[13376], 99.95th=[14144],
| 99.99th=[18816]
bw (KB /s): min=23133, max=34471, per=99.25%, avg=30101.18, stdev=3315.97
lat (usec) : 2=0.01%, 4=13.76%, 10=83.38%, 20=0.59%, 50=0.10%
lat (usec) : 100=0.63%, 250=0.10%, 500=0.01%, 750=0.02%, 1000=0.02%
lat (msec) : 2=0.05%, 4=0.11%, 10=0.75%, 20=0.44%, 50=0.01%
cpu : usr=0.24%, sys=15.46%, ctx=955, majf=0, minf=29
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued : total=r=65536/w=0/d=0, short=r=0/w=0/d=0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
READ: io=262144KB, aggrb=30330KB/s, minb=30330KB/s, maxb=30330KB/s, mint=8643msec, maxt=8643msec
Disk stats (read/write):
sdb: ios=1054/3, merge=1/0, ticks=24369/47, in_queue=24403, util=98.67%Para os nossos testes, estamos interessados apenas na informaçăo de IOPS (I/O por segundo), que indica a capacidade de vazăo (throughput) de um determinado sistema de arquivos.
Na Listagem 3 podemos ver na linha em negrito o valor “iops=7582”, o que indica que o filesystem foi capaz de entregar 7.582 I/O por segundo durante o teste.
Resultados dos testes
Após a execuçăo dos 50 casos de teste para os quatro sistemas de arquivo selecionados, analisaremos a partir de agora, separados pelo perfil de I/O realizado em cada teste, os gráficos com o comparativo entre estes filesystems.
Na Figura 1 podemos ver os resultados do teste para leitura sequencial. A partir do gráfico apresentado é possível observar alguns fatos interessantes, a saber:
1. A diferença causada pelo uso de cache nos testes. No caso de múltiplos arquivos pequenos, o acesso com cache foi 40 vezes mais rápido do que o acesso direto;
2. Certa vantagem do ext3 e do JFS na leitura de poucos arquivos grandes, quando utilizando cache. Vantagem esta que desaparece quando utilizado I/O direto;
3. Pequena vantagem do ext3 e do XFS na leitura de múltiplos arquivos pequenos, quando utilizando cache, mas que também desaparece quando utilizado I/O direto;
4. O acesso direto a poucos arquivos grandes é aproximadamente 10 vezes mais rápido do que o acesso a múltiplos arquivos pequenos.
Como pudemos observar, de modo geral os resultados săo equivalentes, isto é, sem aparentes vencedores.
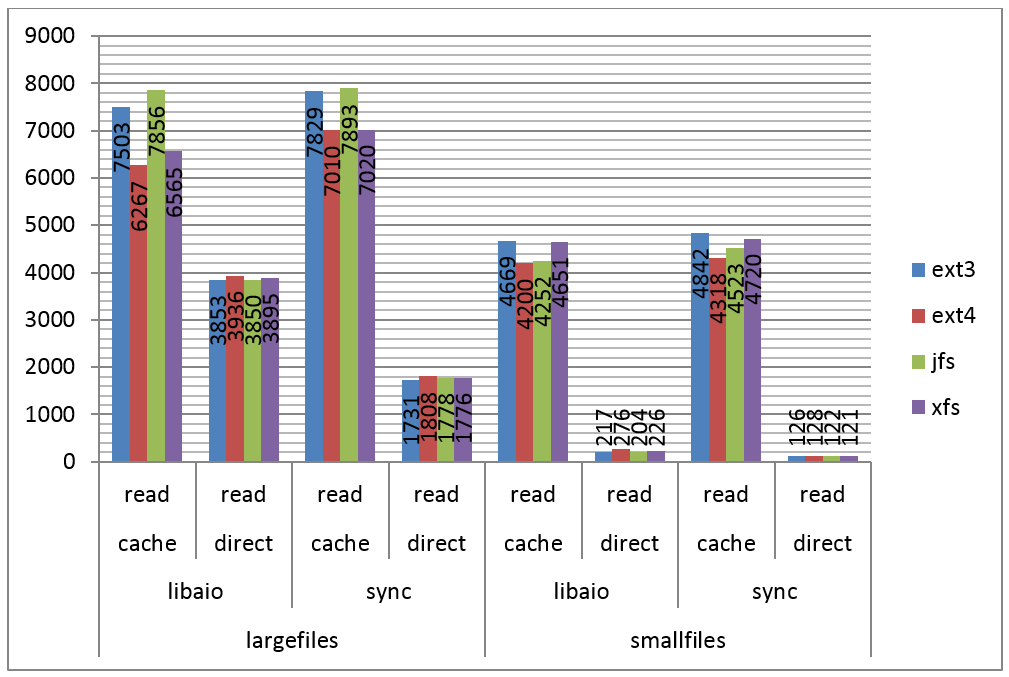
Figura 1. IOPS por filesystem, leitura sequencial.
Na Figura 2 podemos verificar os resultados dos testes para escrita sequencial.
Novamente o cache tem papel fundamental no desempenho, mas é possível observar um padrăo diferente neste caso. O ext3 foi muito mais lento nas escritas com arquivos grandes do que os demais e nas escritas utilizando I/O assíncrono, mas foi mais rápido no caso de acesso a múltiplos arquivos pequenos, com I/O síncrono. Já os demais filesystems tiveram desempenho equivalente.
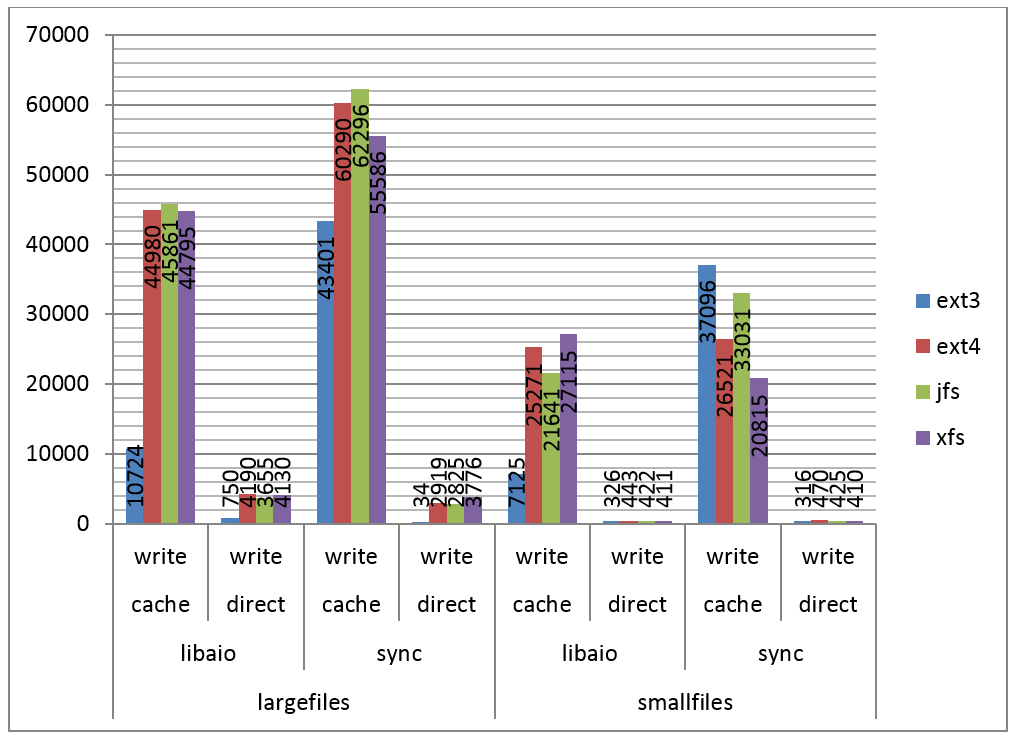
Figura 2. IOPS por filesystem, escrita sequencial.
Na Figura 3 podemos ver os resultados do teste para um misto de leitura e escrita sequenciais.
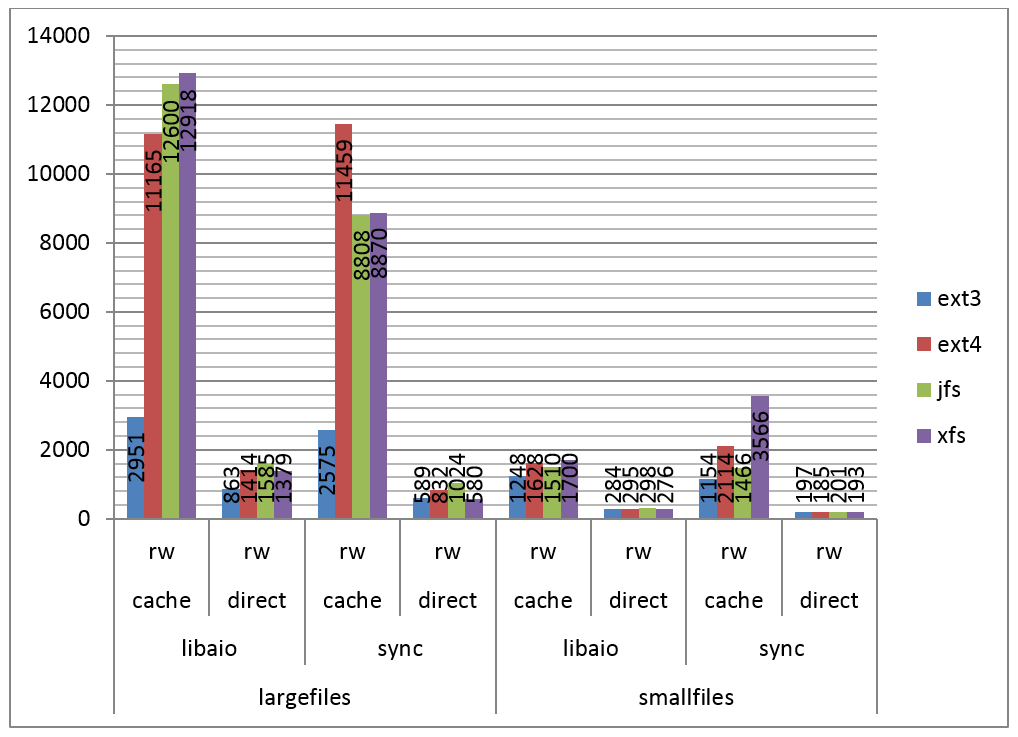
Figura 3. IOPS por filesystem, leitura e escrita sequenciais.
Neste teste podemos perceber um padrăo similar ao encontrado no teste de escritas sequenciais, onde o ext3 é razoavelmente mais lento com arquivos grandes, e uma pequena vantagem para o ext4 e o xfs em alguns casos.
Na Figura 4 podemos ver os resultados do teste para leitura randômica.
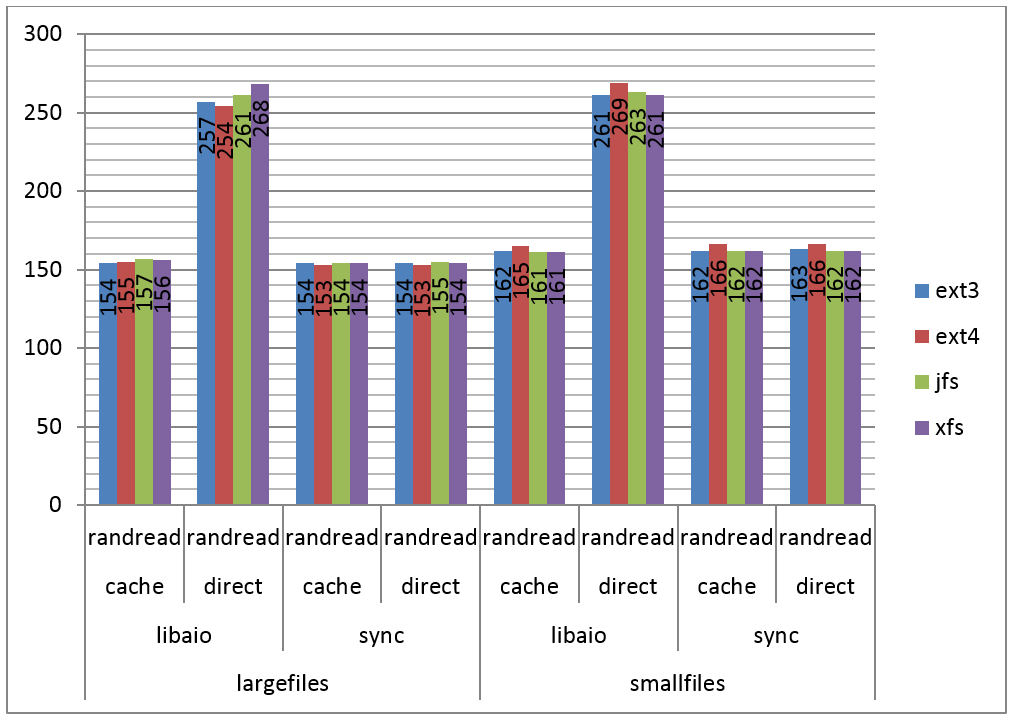
Figura 4. IOPS por filesystem, leitura randômica.
Neste caso podemos perceber que o cache teve participaçăo quase nula no desempenho, inclusive causando degradaçăo de desempenho em alguns casos. Tanto para arquivos grandes como pequenos, o I/O direto e assíncrono se mostrou quase duas vezes mais rápido.
Na Figura 5 săo apresentados os resultados do teste para escrita randômica.
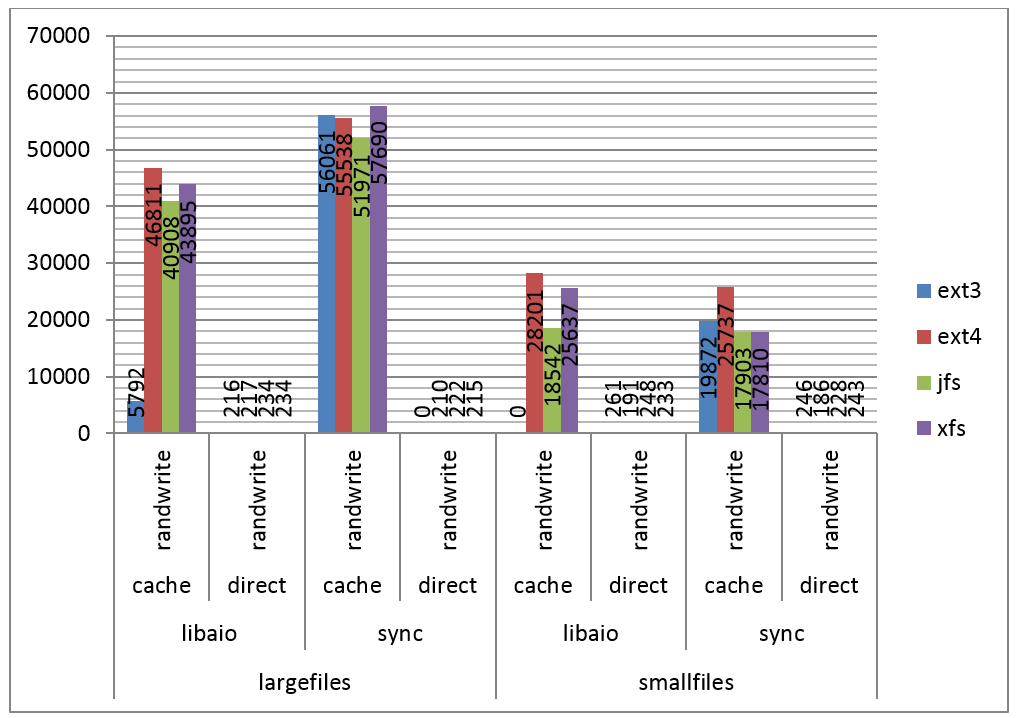
Figura 5. IOPS por filesystem, escrita randômica.
Neste caso percebemos o cache fazendo o seu papel novamente, elevando os números significativamente. Como pode ser observado, em quase todos os testes o ext4 mostrou certa vantagem em relaçăo aos demais, e o ext3 apresentou resultados inválidos (0) em dois casos, o que pode indicar algum bug no fio.
Foi possível observar também um padrăo interessante, similar ao do teste de escritas sequenciais, no qual o ext3 teve um desempenho muito abaixo dos demais com cache e arquivos grandes, mas se saiu muito melhor com múltiplos arquivos pequenos.
Na Figura 6 săo apresentados os resultados do teste para leitura e escrita randômicas.
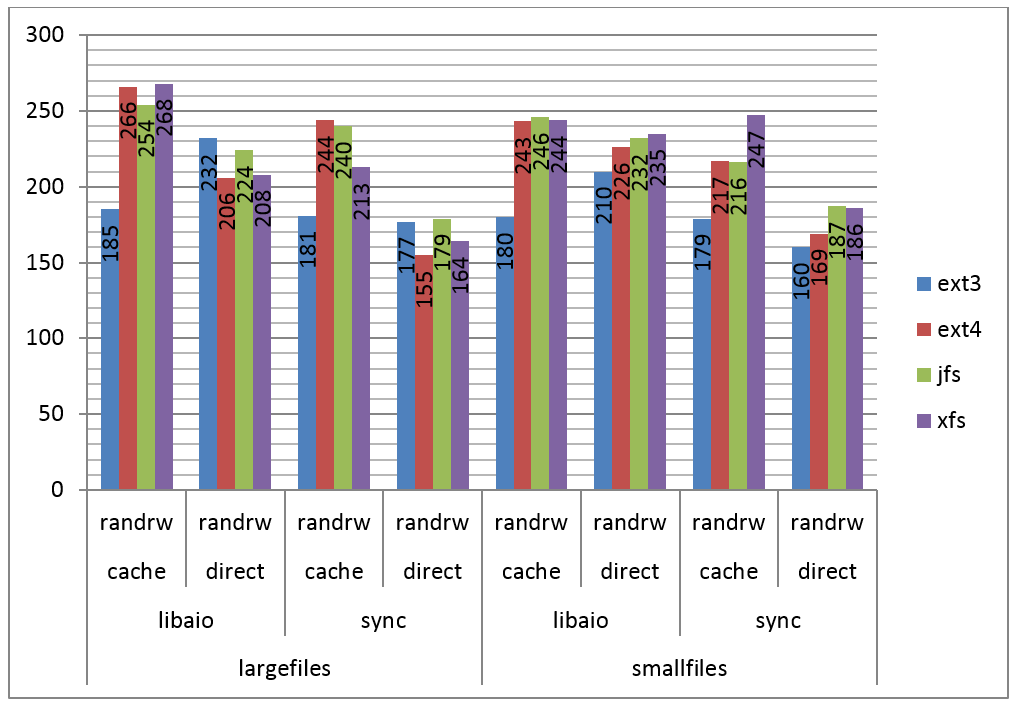
Figura 6. IOPS por filesystem, leitura e escrita randômicas.
Neste caso, novamente o cache năo teve papel importante e o ext3 foi o mais lento em quase todos os testes.
Por fim, na Figura 7 podemos ver os resultados do teste para leitura e escrita randômicas, com quatro processos em paralelo, I/O síncrono e assíncrono.
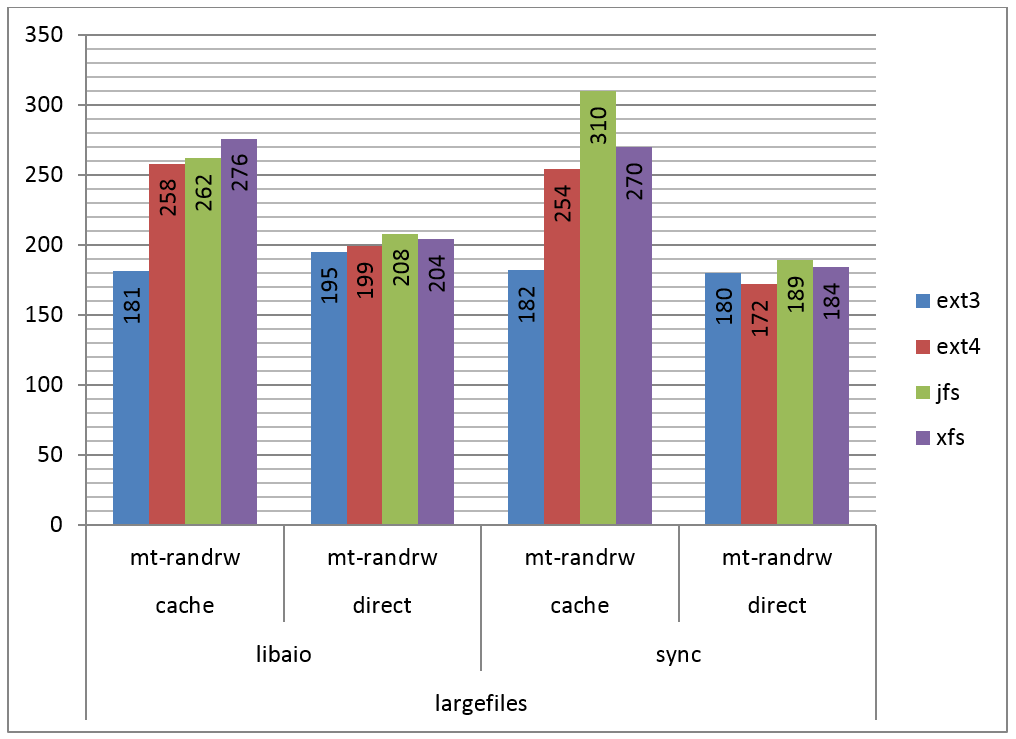
Figura 7. IOPS por filesystem, leitura e escrita randômicas e quatro processos.
Este teste pode ser considerado como um de perfil mais próximo do real para um servidor, onde tipicamente ocorrem requisiçőes de acesso ao disco em paralelo. Nele, podemos observar que o JFS foi ligeiramente melhor na maioria dos testes, com o ext4 e o XFS mostrando números parecidos.
Além disso, podemos constatar que o cache fez pouca diferença e o ext3 mais uma vez se mostrou mais lento com cache do que com I/O direto.
É válido ressaltar que os testes foram realizados em condiçőes genéricas, sem ter um caso de uso específico em mente, e com hardware simples, com o único propósito de mostrar as diferenças entre as principais opçőes de sistemas de arquivos. Ao optar por um ou outro filesystem, é preciso ter em mente a finalidade a que ele se destina e o hardware que o suportará.
Daí a importância de se pensar em uma metodologia de testes e aprender a executá-los por conta própria. Neste contexto, o fio se mostrou uma ótima ferramenta, trazendo extrema flexibilidade e suporte a diversos cenários. Como pôde-se constatar, grande parte do trabalho de utilizá-lo resume-se a definir os testes que săo relevantes para o problema em questăo.
Após a análise dos resultados, podemos afirmar, de modo geral, que ext4, JFS e XFS apresentaram resultados consistentemente melhores do que os apresentados por ext3, com poucas exceçőes, e muitas vezes equivalentes entre si. O JFS, relativamente pouco utilizado e conhecido, a năo ser por quem conhece AIX, surpreendeu com ótimos números, comparáveis aos do XFS e ext4, que vęm se tornando referęncia no mundo Linux.
Como o JFS é um filesystem pouco difundido, e provavelmente possui uma comunidade menor ao seu redor, é preciso que se tenha uma justificativa muito boa para adotá-lo em ambientes críticos de produçăo.
Por outro lado, tanto o XFS quanto o ext4 cada vez mais estăo se tornando os líderes de aceitaçăo na plataforma Linux, e de acordo com os nossos testes, com razăo, pois apresentaram resultados consistentes com a sua fama. A escolha por um ou outro se dará mais por conta de alguma funcionalidade específica que somente um ofereça.
Como orientaçăo final, faça seus próprios testes, adequados ŕs suas necessidades, e tire suas próprias conclusőes. Nestas situaçőes, testes e comparativos săo insubstituíveis.
Artigo sobre utilizaçăo do fio
http://www.linux.com/learn/tutorials/
442451-inspecting-disk-io-performance-with-fio
Site para download do fio
http://brick.kernel.dk/snaps/
Site do projeto XFS
http://xfs.org/index.php/Main_Page
Site do projeto JFS for Linux
http://jfs.sourceforge.net/
Site explicativo sobre o ext4
http://kernelnewbies.org/Ext4
FAQ sobre o ext3
http://batleth.sapienti-sat.org/projects/FAQs/ext3-faq.html







