


Otimizaçăo e tunning de um banco de dados SQL Server 2000 definitivamente năo é uma cięncia exata : existem o que podemos chamar de “regras de boa conduta” que devem ser implementadas de modo a extrair o máximo de performance, mas nem sempre as configuraçőes válidas num determinado ambiente poderăo ser aplicadas com o mesmo ęxito noutra configuraçăo, isso porquę para que seja feito um ajuste fino na base de dados săo necessários esforços bastante abrangentes, que văo desde a análise de códigos Transact SQL até a análise do hardware do servidor (memória, discos, processador e rede) .Nessa matéria, analisaremos o plano de execuçăo de queries, forneceremos também dicas sobre otimizaçăo de códigos Transact SQL e finalizaremos com um breve estudo sobre bloqueios.
Analisaremos um comando “select” executado no database NorthWind conforme a seguir, presente nas instalaçőes default do SQL Server 2000:
select *
from [NorthWind].[dbo].[Orders] o
inner join
[Northwind].[dbo].[Order Details] od
on o.OrderID = od.OrderID
where o.orderid =10248As tabelas utilizadas “Orders” e “Orders Details” (Figura 1) tiveram seus índices alterados conforme demonstrado na Figura 2. O plano de execuçăo gerado pode ser obtido diretamente no Query Analyzer, selecionando “Display Estimated Execution Plan” na opçăo “Query” e os detalhamentos em amarelo na Figura 3 săo obtidos ao posicionar o cursor no respectivo objeto. Toda análise descrita a seguir refere-se a Figura 4.
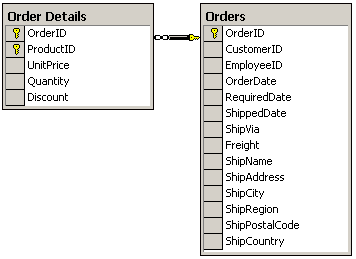
Figura 1. Estrutura de “Orders” e “Orders Details” no database “NorthWind”
| order details | PK_Order_Details | clustered, unique, primary key located on PRIMARY | OrderID, ProductID |
| Orders | CustomerID | nonclustered located on PRIMARY | CustomerID |
| Orders | PK_Orders | nonclustered located on PRIMARY | OrderID |
Figura 2.Composiçăo dos indices em “Orders” e “Orders Details”

Figura 3. Análise do plano de execuçăo da query
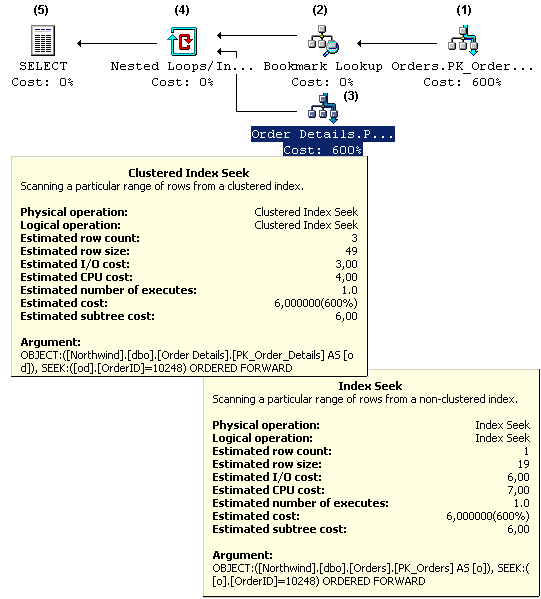
Figura 4. Análise completa
Nested Loop: o otimizador elege uma tabela (conhecida por “Outer Table”) que servirá de base para a varredura de registros. A cada registro lido nessa tabela, é efetuada uma busca pelo registro correspondente na outra tabela participante do join (conhecida por “Inner Table” e esta deve possuir índice adequado para busca). Esse método é bastante eficiente quando uma das tabelas possui quantidade pequena de registros (ou o join possui filtros que tornam o result-set pequeno) e a outra um índice adequado formado pela(s) coluna(s) que unem as duas tabelas. A tabela com menor número de registros será definida como Outer Table.
Merge Join: se as duas tabelas possuírem índices adequados, que permitam sortear o conteúdo das tabelas participantes do join (considerando os filtros estabelecidos na cláusula “where”) esse tipo será o escolhido. O otimizador recupera uma coluna de cada lista sorteada, efetuando a comparaçăo. Em caso de igualdade, retorna as colunas selecionadas. Caso contrário, a coluna de menor valor será descartada, obtendo o próximo valor dessa mesma lista onde foi efetuado o descarte. O processo se repete até que todas as linhas tenham sido processadas. Esse tipo de join é bastante eficaz, normalmente sendo utilizado para tabelas com grande número de registros, que inviabilizam o Nested Loop.
Hash Join: se năo existirem índices adequados para a igualdade definida no join, esse método será utilizado. Para que o join possa acontecer, o otimizador precisará de uma maneira bastante rápida de indexar as duas tabelas, por isso utiliza um algoritmo de hash para codificar as colunas envolvidas no join e estabelecer a combinaçăo.Unir duas tabelas sem índices apropriados ou com baixa seletividade é um fator de queda de performance, portanto investigue as ocorręncias desse tipo de join.
Após a escolha do tipo de join, a query é executada retornando o select para a estaçăo
Abaixo, săo listados mais alguns objetos importantes na avaliaçăo do plano de execuçăo. A lista completa dos objetos utilizados pelo otimizador na resoluçăo de queries pode ser obtida no procurando por “execution plan icons” na guia “Search” do SQL Server Books On Line. Após pesquisa, selecione “Graphically Displaying the Execution Plan Using SQL Query Analyzer”. (ou no endereço http://msdn.microsoft.com/library/default.asp?url=/library/en-us/optimsql/odp_tun_1_5pde.asp)
1 ) Conheça os passos dados pelo otimizador para resolver uma query :
Listagem 1. Select’s idęnticos para o otimizador
select o.OrderId
from
[NorthWind].[dbo].[Orders] o
inner join
[Northwind].[dbo].[Order Details] od
on o.OrderID = od.OrderIDSeleçăo do melhor plano de execuçăo, baseado nos custos calculados no item 3.
2 ) Limite sua busca restringindo ao máximo o número de colunas solicitadas na cláusula “select”. Colunas adicionais, além de consumir mais recursos de I/O e largura de banda, muitas vezes inibem a utilizaçăo de índices ou causam buscas desnecessárias na área de dados ŕ partir do índice (bookmark lookup).
3 ) Filtre sempre o resultado de suas pesquisas, fornecendo parâmetros de busca que se adequem ŕ estrutura dos índices existentes, obedecendo a ordenaçăo de suas colunas.
Ex: para o índice composto PK_Order_Detals, formado pelas colunas OrderId e ProductId, é fundamental que uma pesquisa forneça pelo menos o número da ordem a ser pesquisada (OrderId). Fornecendo somente ProductId, torna pouco provável a utilizaçăo do índice pelo otimizador.
4 ) Evite utilizaçăo de funçőes diretamente sobre colunas pesquisadas, que inibem a utilizaçăo de índices. Ex:
substitua ... where substring(ShipName,1,1) = ‘M’
por ………where ShipName like (‘M%’)Se năo for possível evitar a funçăo, considere a criaçăo de índices sobre colunas calculadas:
select datepart(month,ShippedDate)
from [NorthWind].[dbo].[Orders]
where datepart(month,ShippedDate)=7
Pode ser otimizado se criarmos um índice sobre uma coluna calculada:
alter table [NorthWind].[dbo].[Orders]
add Month_OrderDate as datepart(month,ShippedDate)
create index IX_Month_OrderDate
on [NorthWind].[dbo].[Orders](Month_OrderDate)Podemos agora reescrever o “select” :
select Month_OrderDate
from [NorthWind].[dbo].[Orders]
where Month_OrderDate=7 
Repare que o “Table Scan” foi substituído por um “Indes Seek” !
5 ) Utilize tabelas derivadas em oposiçăo ŕ tabelas temporárias. Tabela derivada é o resultado da utilizaçăo de um comando select após a clausula “from” num “select” existente. Apenas para efeito de exemplo :
select o.EmployeeId,od.Quantity
from [NorthWind].[dbo].[Orders] o
inner join
( select * from [Northwind].[dbo].[Order Details] od where ProductId=11 ) as od
on o.OrderID = od.OrderID6 ) Lembre-se que índices existem para comparar igualdades. Evite a utilizaçăo de operadores do tipo “<>”,”!>”,”!<”, “NOT”. A utilizaçăo de “lógica negativa” inibe a escolha de índices pelo otimizador.
7 ) Para fins de performance, considere a utilizaçăo de Indexed Views. A utilizaçăo de views simplifica bastante a programaçăo, mas năo otimiza performance, haja visto que seu código é executado de maneira integral a cada solicitaçăo.
8 ) Se a sua query utiliza agrupamentos e filtragem de dados na cláusula “having”, considere a opçăo de filtragem diretamente na cláusula “where”, reduzindo significativamente o trabalho do “group by”, já que um número menor de registros deverăo ser processados.
9 ) Utilize a cláusula “like” com critério. Lembre-se que o comando “… where name like(‘SQL%’)“ utilizará um índice formatado para a coluna “name”, se esse índice existir. Já o comando “… where name like (‘%SQL’) “ realizará um table scan (ou clustered index scan, se a tabela possuir índice cluster) na tabela em questăo.
10 ) Evite ao máximo a utilizaçăo de cursor nos servidores. Experimente reescrever o código utilizando subqueries, tabelas derivadas, tabelas temporárias ou mesmo a cláusula “case”.
11 ) Sempre que possível, utilize variáveis do tipo “table” em oposiçăo ŕ tabelas temporárias.
12 ) Para monitoramento, utilize o Profiler para capturar as queries mais demoradas, analisando seu plano de execuçăo.
13 ) Existem duas configuraçőes de servidor que podem ser utilizadas para limitar o tempo de execuçăo de uma query, săo elas : “query governor cost limit” e “query wait”. A primeira (“query governor”) é baseada numa projeçăo de tempo de execuçăo da query calculada pelo otimizador: se o tempo projetado for superior ao limite pré-definido nessa configuraçăo a query é abortada ANTES de sua execuçăo. “Query wait” simplesmente aborta uma query se esta superar o limite estabelecido nesse parâmetro, o que pode ser desastroso principalmente se a transaçăo for extensa e já houver adquirido muitos locks. Como sugestăo, avalie a opçăo “query governor”. Implante limites que vocę considera suficientes para seu ambiente (com boa margem de segurança !) e vá reduzindo gradativamente, até chegar ao ponto ótimo.
Bloqueios săo fundamentais para garantia da consistęncia de dados em transaçőes. O isolamento fornecido por um bloqueio no SQL Server 2000 permite que uma transaçăo năo efetue leituras ou modifique dados que estăo sendo utilizados por outra transaçăo.
Existem vários tipos de locks, cada um estabelecendo o isolamento necessário para comandos de manipulaçăo de dados (select / insert / update / delete). O tipo de lock (shared, update, exclusive, shema lock ou bulk update lock) é selecionado automaticamente pelo SQL Server 2000 a menos que vocę utilize um hint, o que năo é aconselhável.
O SQL Server 2000 trabalha com escalonamento de locks, permitindo que um bloqueio de registro seja promovido para um bloqueio de página ou de tabela. O escalonamento possibilita a economia de recursos (um lock consome 64 bytes de memória), pois ao promover um lock os bloqueios de nível menor săo liberados. Como ilustraçăo, imagine uma operaçăo de update envolvendo todas as 1000 linhas de uma tabela - o que seria mais eficiente: 1000 locks de registro ou um lock de tabela ? É lógico que a segunda opçăo, já que todas as linhas serăo atualizadas.
O problema relacionado a bloqueios advém de seu tempo de duraçăo. Bloqueios curtos săo eficientes, bloqueios longos săo um transtorno. Alguns fatores que acarretam no aumento da duraçăo de bloqueios săo transaçőes longas, ausęncia, excesso ou ineficięncia de índices, nível de isolamento das transaçőes, bases de dados năo normalizadas, utilizaçăo indiscriminada de cursores, etc. Nesses ambientes, as mensagens de erro envolvendo query timeout (#1222) ou deadlocks (#1205) tendem a ocorrer com mais freqüęncia.
Query timeout acontece quando, ao executar um comando de manipulaçăo de dados, aguardamos sua conclusăo por tempo superior a um limite previamente estabelecido. Já deadlocks acontecem quando dois processos ficam aguardando pela liberaçăo de recursos que o outro processo mantém, situaçăo essa que é resolvida pelo SQL Server 2000 finalizando-se a conexăo que consumir menos recursos.A seguir temos os códigos para gerar dois tipos de deadlock: cíclicos e de conversăo.
Tipo cíclico:
begin tran
update [NorthWind].[dbo].[order details]
set discount=1
where orderid=10248 and productid=11 begin tran
update [NorthWind].[dbo].[orders]
set employeeid=4
where orderid=10248
update [NorthWind].[dbo].[orders]
set employeeid=5
where orderid=10248
commit
update [NorthWind].[dbo].[order details]
set discount=0
where orderid=10248 and productid=11
commit
Server: Msg 1205, Level 13, State 50, Line 1
Transaction (Process ID 70) was deadlocked on lock resources with another process
and has been chosen as the deadlock victim. Rerun the transaction.
Tipo Conversăo:
begin tran
select * from [NorthWind].[dbo].[Orders] (holdlock)
where orderid=10248
begin tran
select * from [NorthWind].[dbo].[Orders] (holdlock)
where orderid=10248update [NorthWind].[dbo].[Orders]
set employeeid=4
where orderid=10248
commitupdate [Northnd].[dbo].[Orders]
set employeeid=5
where orderid=10248
commitServer: Msg 1205, Level 13, State 50, Line 1
Transaction (Process ID 70) was deadlocked on lock resources with another process
and has been chosen as the deadlock victim. Rerun the transactionUma das maneiras de se monitorar as transaçőes envolvidas num deadlock é ativar as trace flags 3605 e 1204, que geram informaçőes detalhadas no log do SQL Server 2000 ŕ respeito do deadlock. Execute “dbcc traceon(3605) dbcc traceon(1204) “ para habilitar as trace flags; “dbcc traceoff (3605) dbcc traceoff (1204)” para desabilitar.
Outra possibilidade de monitoramento é através do SQL Profiler, habilitando-se o evento “Lock: DeadLock Chain”, que produz resultado semelhante ŕs trace flags habilitadas acima.
Um aspecto interessante é que a duraçăo de um lock é ilimitada no SQL Server 2000. Portanto se vocę năo quiser que um processo aguarde indefinidamente pela liberaçăo de um lock mantido noutra sessăo, utilize em sua sessăo a cláusula LockTimeOut (set LockTimeOut ) antes de comandos de manipulaçăo de dados e efetue tratamento para erros de código #1222.
Minimizar tempo de bloqueios implica no cumprimento de algumas regras, a saber:
1 ) Adicionar coluna TS tipo TimeStamp em [Orders]
Alter table [Orders] add TS timestamp2 ) Efetuar leitura de colunas da tabela Orders, submetendo-as a aplicaçăo de front-end
declare @ShipName varchar (80)
declare @ShipAddress varchar(120)
declare @TS binary (8)
select @ShipName=ShipName
,@ShipAddress=ShipAddress
,@TS=TS
from [Orders] where OrderId=10248
3 ) Após alteraçőes pelo vendedor, submeter o comando de update fornecendo a coluna timestamp guardada no passo anterior:
update [Orders]
set ShipName = @ShipName
, ShipAddress = @ShipAddress
where OrderId =10248 and TS=@TS
if @@rowcount = 0
begin
/*
Significa que o registro foi alterado noutra sessăo ; a aplicaçăo deverá ser desviada
para o passo-2, relendo a ordem submetendo-a novamente ŕ análise do vendedor
*/
raiserror ('Ordem alterada por outro vendedor. Verifique !',11,1)
end
Normalmente só pensamos em otimizaçăo no momento em que nos deparamos com situaçőes realmente críticas de performance, quando pode ser tarde demais.

Eu sabia pouquíssimas coisas de programaçăo antes de começar a estudar com vocęs, fui me especializando em várias áreas e ferramentas que tinham na plataforma, e com essa bagagem consegui um estágio logo no início do meu primeiro período na faculdade.
Estudo aqui na Dev desde o meio do ano passado!
Nesse período a Dev me ajudou a crescer muito aqui no trampo.
Fui o primeiro desenvolvedor contratado pela minha
empresa. Hoje eu lidero um time de desenvolvimento!
Minha meta é continuar estudando e praticando para ser um
Full-Stack Dev!
Economizei 3 meses para assinar a plataforma e sendo sincero valeu muito a pena, pois a plataforma é bem intuitiva e muuuuito didática a metodologia de ensino. Sinto que estou EVOLUINDO a cada dia. Muito obrigado!
Nossa! Plataforma maravilhosa. To amando o curso de desenvolvimento front-end, tinha coisas que eu ainda năo tinha visto. A didática é do jeito que qualquer pessoa consegue aprender. Sério, to apaixonado, adorando demais.
Adquiri o curso de vocęs e logo percebi que săo os melhores do Brasil. É um passo a passo incrível. Só năo aprende quem năo quer. Foi o melhor investimento da minha vida!
Foi um dos melhores investimentos que já fiz na vida e tenho aprendido bastante com a plataforma. Vocęs estăo fazendo parte da minha jornada nesse mundo da programaçăo, irei assinar meu contrato como programador graças a plataforma.
Wanderson Oliveira
Comprei a assinatura tem uma semana, aprendi mais do que 4 meses estudando outros cursos. Exercícios práticos que năo tem como năo aprender, estăo de parabéns!
Obrigado DevMedia, nunca presenciei uma plataforma de ensino tăo presente na vida acadęmica de seus alunos, parabéns!
Eduardo Dorneles
Aprendi React na plataforma da DevMedia há cerca de 1 ano e meio... Hoje estou há 1 ano empregado trabalhando 100% com React!
Adauto Junior
Já fiz alguns cursos na área e nenhum é tăo bom quanto o de vocęs. Estou aprendendo muito, muito obrigado por existirem. Estăo de parabéns... Espero um dia conseguir um emprego na área.



