P>

Clique aqui para ler todos os artigos desta ediçăo
Mecanismos de Persistęncia em Java
por Fernando Lozano
A comunidade de desenvolvedores Java, mais do que qualquer outra, adotou as práticas de orientaçăo a objetos no desenvolvimento de sistemas de informaçăo. Năo apenas pelo uso de componentes, como ocorre em ambientes RAD estilo Delphi e VB, mas como forma de modelar e construir as regras de negócios de uma aplicaçăo.
Entretanto, sistemas de informaçăo necessitam de bancos de dados, e a tecnologia mais popular nesta área ainda é a relacional. Mesmo quando săo adotados bancos de dados OO (ou Objeto/Relacionais, como Oracle e PostgreSQL), o modelo de objetos do banco é bastante diferente do modelo de objetos utilizado pelo Java, ou por qualquer outra linguagem de programaçăo. Afinal, enquanto que a linguagem lida com objetos em memória, o banco lida com objetos em disco, o que exige algoritmos e estratégias diferenciados. Dessa forma, há a necessidade de uma camada que compatibilize a visăo OO dos objetos de negócios da aplicaçăo com a visăo relacional (ou OO) do banco. Daí surgem os mecanismos ou frameworks de persistęncia.
Este artigo apresenta inicialmente características comuns a qualquer mecanismo de persistęncia, depois apresenta os principais mecanismos do universo Java.
A Necessidade da Persistęncia de Objetos
Persistir objetos consiste em garantir que um objeto instanciado durante uma execuçăo da aplicaçăo tenha seu estado recuperado durante uma execuçăo posterior de modo que ele seja o mesmo objeto.
A linguagem Smalltalk, berço das modernas práticas OO, lidava com a questăo de um modo simples: todos os objetos eram persistentes. Entre uma execuçăo e outra do ambiente Smalltalk, uma imagem do heap era salva em disco e posteriormente recuperada. É claro, isto funcionava apenas enquanto houvesse memória RAM suficiente para manter todos os objetos instanciados, coisa que năo é possível para a maioria dos sistemas de informaçăo atuais.
Estratégia similar vem sendo adotada pela prevalęncia de objetos, cuja implementaçăo mais popular é o Prevayler (www.prevayler.org) (ver Nota 1). Entretanto, se vocę năo tem memória RAM suficiente para manter todos os objetos, vocę precisa de um outro mecanismo de persistęncia, baseado no armazenamento de objetos em disco.
Nota 1. O Prevayler
O prevayler (www.prevayler.org), ou prevalęncia de objetos, é uma alternativa radical para os desenvolvedores OO mais puristas, que năo desejam “poluir” suas aplicaçőes e modelos de classes com o universo relacional. Em um mundo perfeito, seria muito mais produtivo lidar apenas com modelos de objetos e os recursos das várias classes de coleçăo do Java, como mapas, árvores e hashes, e năo ter que carregar ou salvar dados em disco.
Ele é baseado em um mecanismo simples de snapshot (fotografia) do heap de objetos em disco, e este snapshot é atualizado periodicamente pela aplicaçăo. Um log das operaçőes realizadas sobre cada objeto permite a recuperabilidade em caso de falhas ou a implementaçăo de mecanismos de distribuiçăo (clustering).
Entretanto, o prevayler assume que todos os dados da aplicaçăo podem ser mantidos em memória principal, e sua performance degrada-se rapidamente caso seja necessário utilizar memória virtual. Todas as afirmaçőes “bombásticas” dos seus desenvolvedores sobre as incríveis vantagens de performance em relaçăo a bancos de dados tradicionais devem ser pesadas em relaçăo a este fato, de que os SGBDs săo otimizados para acesso a disco, enquanto que o prevlayer é otimizado para acesso em memória. Também falta ao prevlayer a comprovaçăo prática que os bancos relacionais já possuem em ambientes de missăo crítica quanto ŕ confiabilidade e escalabilidade.
O prevayler năo utiliza um banco de dados, nem é capaz de utilizar um como meio de armazenar o shapshot dos objetos em memória, de modo que ele năo faz parte do escopo deste artigo.
A maioria das linguagens OO fornece algum mecanismo nativo de serializaçăo de objetos, que permite o seu envio pela rede para uma outra aplicaçăo ou a sua gravaçăo em um arquivo seqüencial. A serializaçăo atende a várias aplicaçőes, mas da mesma forma como arquivos seqüenciais năo săo adequados para sistemas de informaçăo, levando ao uso de arquivos randômicos e indexados (e daí aos modernos SGBDs), a serializaçăo também năo é adequada para sistemas de informaçăo.
Além disso, o que fazer quando a aplicaçăo for utilizada por vários usuários simultâneos? Cada ambiente Smalltalk iria enviar, em broadcast, as modificaçőes do estado de uma instância para que sejam aplicadas sobre os demais ambientes Smalltalk E ainda nem falamos sobre como delimitar unidades lógicas de trabalho, ou melhor, transaçőes, e garantir sua recuperabilidade. Concorręncia, consistęncia e integridade de dados năo săo coisas triviais de se obter, por isso existem os SGBDs. A funçăo do mecanismo de persistęncia é nada mais do que gerenciar o salvamento e recuperaçăo de objetos do heap da linguagem de programaçăo para o SGBD. Entretanto, esta funçăo também năo é trivial, dadas as diferenças conceituais entre os modelos OO e Relacional.
Componentes de um mecanismo de persistęncia
Todo mecanismo de persistęncia Objeto/Relacional é formado por tręs componentes, a saber:
· Uma linguagem para descrever o mapeamento de classes e atributos da aplicaçăo para tabelas e colunas do banco de dados;
· Uma API que permite o salvamento e recuperaçăo de objetos do banco de dados;
· Uma linguagem de consulta, em geral semelhante ao SQL, mas baseada em objetos e năo em tabelas.
Mecanismos que năo utilizam bancos de dados, como o Prevayler, năo necessitam de uma linguagem de mapeamento (pois só existe o modelo de objetos em memória, năo existe um modelo em disco para ser mapeado) nem de uma linguagem de consulta (basta percorrer o grafo de objetos). Por outro lado, mecanismos baseados em bancos năo-relacionais terăo componentes com finalidades semelhantes. Por exemplo, um mecanismo de persistęncia baseado em documentos XML teria que mapear o modelo de objetos para um XML Schema e utilizar XPath como linguagem de consulta.
Mapeamento OO/Relacional
Embora seja possível construir um mapeamento OO para um banco relacional pré-existente, o uso dos mecanismos de persistęncia é mais eficiente quando se parte de um modelo OO e daí é derivado o banco relacional.
A forma mais comum de descrever este mapeamento hoje é por meio de documentos XML, que săo lidos em tempo de compilaçăo ou em tempo de execuçăo pelo mecanismo de persistęncia para gerar os comandos SQL utilizados no acesso ao banco. Como o modelo OO é mais rico do que o modelo relacional, há várias formas de se mapear um mesmo modelo de classes para tabelas, com diferentes compromissos de performance para consultas, para atualizaçăo ou flexibilidade para a evoluçăo futura do modelo.
Por exemplo, considere o endereço de um cliente. No modelo OO, a classe Cliente teria um atributo do tipo Endereço. A classe Endereço, por sua vez, possui atributos String como nome do logradouro, bairro e cidade. Em um banco relacional, a mesma situaçăo seria modelada como várias colunas adicionais da tabela “cliente”, gerando um modelo plano (já o modelo OO, onde Cliente contém um Endereço, é um modelo hierarquizado). Mas nada nos impede de criar uma tabela “endereço” e estabelecer um relacionamento 1:1 de endereço para cliente (ver Figura 1).
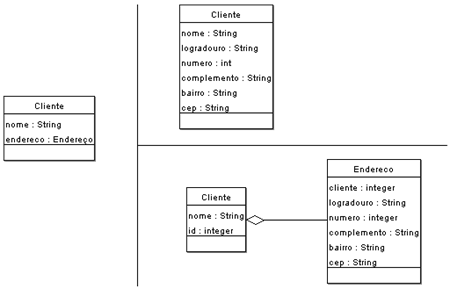
Figura 1. Diferentes formas de se mapear um modelo OO (esquerda) para um banco relacional (direita).
Um modelo OO pode conter atributos multivalorados (por exemplo, vários números de telefone para o mesmo cliente), enquanto que o modelo relacional exige a criaçăo de várias colunas (telefone1, telefone2, etc) ou de uma tabela relacionada.
A herança torna a situaçăo ainda mais complicada. Pode-se criar uma “supertabela” contendo todos os atributos possíveis para cada subclasse, ou várias tabelas representando cada nível da hierarquia de classes, com relacionamentos 1:1 entre elas.
E năo podemos nos esquecer das diversas semânticas de coleçőes Java: listas, conjuntos e mapas. Transformar cada uma em tabelas relacionadas e preservar a semântica da coleçăo năo é nada trivial.







