Esse artigo faz parte da revista SQL Magazine ediçăo 62. Clique aqui para ler todos os artigos desta ediçăo
azenados no servidor local. De outra forma, quando um candidato se inscreve para o vestibular da FATEC Sorocaba (usando o mesmo site da FATEC Indaiatuba), os dados serăo armazenados no servidor localizado na cidade de Sorocaba e assim por diante.
Para esse sistema, simulamos em laboratório sete unidades da FATEC, ou seja, o sistema reconhece sete instâncias diferentes do SGBD (SQL Server 2005) como se estivessem dispersos por diversas cidades do estado de Săo Paulo. O artigo está dividido em duas partes: a primeira apresenta alguns conceitos de distribuiçăo e os scripts usados na elaboraçăo do projeto; a segunda apresenta um roteiro para a elaboraçăo de um software, codificado em Java, que acessa o sistema distribuído. A Figura 1 ilustra o projeto de distribuiçăo entre as instâncias do SQL Server.
Em nosso projeto, a distribuiçăo dos dados será realizada por meio da fragmentaçăo. A fragmentaçăo é um processo de criar fragmentos (pedaços) de uma tabela. Em outras palavras, uma mesma tabela é dividida em fragmentos e cada fragmento pode ser armazenado em um local diferente. Na verdade, a mesma tabela é criada nas diferentes instâncias do SGBD e cada tabela mantém uma parte dos dados, ou seja, a uniăo dos dados presentes em cada uma das instâncias irá compor o conjunto total dos dados. Para o SGBD, năo existe diferença entre uma tabela e um fragmento, já que o fragmento é a própria tabela. Como veremos ao longo deste artigo, a fragmentaçăo utilizada nesse artigo foi a horizontal, ou seja, cada fragmento representa um conjunto de registros da tabela.
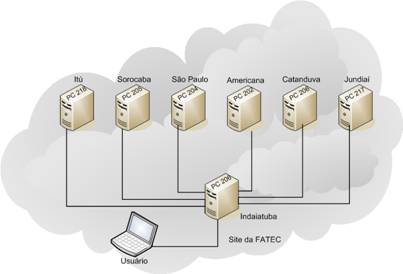
Figura 1. Distribuiçăo entre as instâncias do SQL Server
Definiçăo de Banco de Dados Distribuídos
Banco de Dados Distribuídos (BDD) se refere a uma coleçăo de vários bancos de dados logicamente inter-relacionados e distribuídos por uma rede de computadores. Existem dois tipos de BDD, os homogęneos e os heterogęneos. Os homogęneos săo compostos por apenas um tipo de Sistema Gerenciador de Banco de Dados (SGBD), por exemplo, vários servidores SQL Server. Esse artigo apresenta um exemplo de sistema distribuído homogęneo, pois no caso todas as instâncias serăo do SQL Server 2005. Os heterogęneos săo compostos por mais de um tipo de SGBD, ou seja, em um mesmo ambiente distribuído pelo menos um dos SGBDs é diferente em relaçăo aos demais. Os SGBDs que suportam distribuiçăo săo conhecidos como SGBDD (Sistema Gerenciador de Banco de Dados Distribuídos). O próximo tópico apresenta algumas características dos SGBDDs.
Principais características de um SGBDD
De acordo com Date (2004), um SGBDD deve conter diversas características para ser considerado como tal. Os itens seguintes abordam essas características de forma resumida.
1. Autonomia local: cada nó participante de um sistema distribuído (cada SGBDD) deve ser independente dos outros nós e prover mecanismos de segurança, bloqueio, acesso, integridade e recuperaçăo após falha;
2. Independęncia de um nó central: um SGBDD năo deve depender de um nó central. Se a dependęncia ocorrer, o sistema fica menos robusto, já que possui um único ponto de falha. Isso afetaria todos os outros nós. Um nó central pode acarretar perda de desempenho do sistema, já que tende a ficar muito “carregado”;
3. Operaçăo contínua: um sistema distribuído năo deve necessitar desativaçăo. As operaçőes de backup e a recuperaçăo devem ter suporte on-line. As operaçőes devem ser rápidas o bastante para năo afetarem o funcionamento do sistema (backup incremental, por exemplo);
4. Transparęncia e independęncia de localidade: os usuários do sistema năo precisam ter cięncia do local onde os dados estăo armazenados. Para o usuário, os dados devem ser vistos como se fossem locais.
5. Independęncia de fragmentaçăo: as tabelas do sistema de banco de dados distribuído podem estar fragmentadas e localizadas fisicamente em diferentes nós, de forma transparente para o usuário. Usuários e aplicaçőes năo devem saber que as tabelas estăo armazenadas em nó diferente do nó onde săo feitas as operaçőes. A fragmentaçăo pode ser horizontal (fragmentaçăo em linhas) ou vertical (fragmentaçăo em colunas). Maiores detalhes serăo apresentados na continuidade deste artigo;
6. Independęncia de replicaçăo: dados replicados em vários nós da rede, de forma transparente. Assim como nas regras de independęncia de localizaçăo e fragmentaçăo, a independęncia de replicaçăo é projetada para livrar os usuários de preocupaçőes relacionados com o local onde os dados estăo armazenados. No caso da replicaçăo, os usuários e as aplicaçőes năo precisam saber que réplicas de dados săo mantidas e sincronizadas automaticamente pelo SGBDD;
7. Processamento de consultas distribuído: o desempenho de uma consulta deve ser independente do local onde a mesma é executada. O SGBDD deve possuir um otimizador que possa selecionar năo apenas o melhor caminho para o acesso a um determinado nó da rede, mas também otimizar o desempenho de uma consulta distribuída, levando em conta a localizaçăo dos dados, utilizaçăo de CPU e I/O e ainda o tráfego da rede;
8. Gerenciamento de transaçőes distribuídas: Em um sistema distribuído, uma única transaçăo pode envolver a execuçăo de código de vários sites. A transaçăo, nesse caso, consiste em vários agentes. O sistema precisa saber quando dois agentes săo partes da mesma transaçăo; esses agentes năo devem ter impasses entre eles (deadlock).
9. Independęncia de hardware: é uma característica desejável que um SGBDD năo dependa de um determinado hardware, nem deve ser limitado a uma determinada plataforma;
10. Independęncia de sistema operacional: da mesma forma que o item anterior, é desejável que um SGBDD năo dependa de um sistema operacional em especial;
11. Independęncia de rede: um SGBDD deve ser projetado para executar independente do protocolo de comunicaçăo e da topologia de rede;
12. Independęncia de SGBD: um SGBDD ideal deve possuir capacidades para se comunicar com outros sistemas de banco de dados executando em nós diferentes, ainda que heterogęneos.
Vantagens dos Bancos de Dados Distribuídos
Quais motivos levam uma empresa a utilizar um BDD? Para responder essa pergunta, vamos apresentar algumas características que justificam a utilizaçăo da distribuiçăo dos dados.
Primeiramente, as empresas săo distribuídas geograficamente (matriz, filiais etc). Da mesma forma, um banco de dados pode ser distribuído fisicamente em várias instâncias, onde cada qual armazena os dados que dizem respeito a si. Em nosso caso, cada unidade da FATEC possui candidatos ao vestibular para uma determinada localidade (Indaiatuba, Săo Paulo, etc.). Sendo assim, é mais sensato armazenar os candidatos no servidor local de cada unidade da FATEC. Dessa forma, o BD passa a refletir a estrutura física da instituiçăo.
Além disso, através do uso de SGBDDs é possível acessar os dados localizados em sites próximos aos usuários e, ao mesmo tempo, compartilhar dados armazenados em outros sites. Em organizaçőes descentralizadas, o gerenciamento dos dados pode ser delegado aos administradores locais, permitindo maior autonomia e responsabilidade.
Considerando-se a replicaçăo de dados, se houver problemas com a perda de dados de uma localidade, é possível recuperar esses dados a partir de outras localidades. Em nosso projeto, năo estaremos considerando a utilizaçăo da replicaçăo de dados.
Por fim, ao utilizar um SGBDD, os esforços e custos associados ao aumento no número de sites em uma rede podem ser menores quando comparados com os custos associados ŕ expansăo de um banco de dados centralizado. Provavelmente, a expansăo do banco centralizado necessitaria de atualizaçăo do hardware e incrementaria os custos do sistema como um todo. A facilidade de inserçăo de um novo nó (nova instância) no sistema distribuído aumenta a potencialidade de expansăo do sistema. De forma semelhante, em organizaçőes geograficamente distribuídas e muito distantes entre si, a distribuiçăo de dados pode apresentar benefícios, já que manter dados centralizados pode envolver um custo muito alto. Na maioria das vezes, os dados distribuídos podem ser compartilhados por vários locais a um custo bem inferior.
Fragmentaçăo e Replicaçăo
Em um ambiente distribuído, os dados săo divididos pelas instâncias dos SGBDDs espalhadas pela rede. Essa distribuiçăo pode ocorrer de tręs formas: fragmentaçăo, replicaçăo ou uma mistura de ambas.







