O presente artigo apresenta os principais conceitos sobre alta disponibilidade e as soluçőes que podem ser implementadas utilizando o SQL Server.
Para que serve:
Este artigo serve de base introdutória para a construçăo de uma soluçăo que mantém a disponibilidade de um sistema após uma falha de hardware ou software.
Em que situaçăo o tema é útil:
Minimizar o tempo de inatividade de um sistema em caso de alguma falha de software ou hardware, disponibilizando um segundo servidor responsável em assumir os serviços do servidor principal.
Alta disponibilidade pode ser definida como uma soluçăo que mascara os efeitos de uma falha de hardware ou software e mantém a disponibilidade dos aplicativos, de modo a minimizar o tempo de inatividade de um sistema.
Para algumas empresas, esta definiçăo significa que deverá existir um hardware redundante igual ao de produçăo, o que requer que os dados e o hardware tenham duraçăo e disponibilidade de 99,995 % ou mais. Outras empresas necessitam apenas que os dados propriamente ditos tenham alta disponibilidade, sem tanta preocupaçăo com o desempenho do nível de produçăo caso um failover (processo no qual uma máquina assume os serviços de outra, quando esta última apresenta alguma falha) seja necessário.
Para determinar a melhor soluçăo de alta disponibilidade, é necessário avaliar questőes referentes aos tipos de interrupçőes que poderăo ocorrer e indicar como isso afeta seus Contratos de Nível de Serviço (SLAs). As interrupçőes que podem afetar a disponibilidade săo:
· Desempenho Planejado: normalmente é uma manutençăo programada sobre a qual os usuários dos sistemas săo informados com antecedęncia;
· Năo Planejado: geralmente resulta de uma falha de hardware ou software que torna os dados inacessíveis; e
· Degradaçăo do Desempenho: a degradaçăo do desempenho também pode provocar interrupçőes, e normalmente é medida no tempo de resposta do usuário final.
E por fim, identificar o nível de atividade dos dados e se estes devem estar sempre on-line ou off-line ocasionalmente. A seguir será descrito previamente cada opçăo de disponibilidade disponível para o Microsoft SQL Server 2005, que seriam: Cluster de Failover, Espelhamento de banco de dados, Log Shipping e Replicaçăo.
Cluster de Failover
O Cluster de failover é basicamente uma soluçăo de hardware que consiste em um grupo de computadores independentes que trabalham juntos para aumentar a disponibilidade de aplicativos e serviços. Os servidores em cluster (chamados de nós) săo conectados através de cabos físicos e de software. Se um dos nós do cluster falhar, outro começará a fornecer os serviços, sendo que os usuários do sistema teriam o mínimo de interrupçőes nos serviços.
Um requisito inicial que deve ser verificado antes da instalaçăo do cluster é identificar se o hardware é certificado pela Microsoft. Este deve constar na lista de soluçőes de hardware certificada, chamada de Hardware Compatibility List (HCL). Por ser uma soluçăo de alta disponibilidade, é preciso assegurar que componentes lógicos e físicos funcionam da maneira adequada.
Para uma soluçăo em cluster, săo necessários os seguintes componentes físicos (ver Figura 1):
· Nós de cluster (Cluster Nodes): é um servidor que faz parte do cluster e compartilha os recursos do cluster. Todos os nós do cluster devem possuir o mesmo sistema operacional e plataforma (32 bits ou 64 bits).
· Rede Privada (Private Network): a funçăo da rede privada é verificar se os nós que compőem o cluster estăo funcionando e disponíveis. A rede privada é implementada através de uma placa de rede dedicada e exclusiva no nó do cluster.
· Rede Pública (Public Network): a funçăo da rede pública é permitir que as aplicaçőes conectem-se no cluster e que o cluster possa conectar-se na rede. A rede pública é implementada através de uma placa de rede dedicada e exclusiva no nó do cluster.
· Conjunto de discos compartilhados (Shared Disk Array): conjunto de discos físicos (SCSI ou Fiber Channel) que săo acessados pelos nós do cluster. O conjunto de discos compartilhados também é conhecido como “storage do cluster”. A “storage” apresenta para os nós do cluster um conjunto lógico de discos que săo acessados pelo sistema operacional como se fossem discos internos do servidor. O serviço de cluster da Microsoft implementa o conceito de shared nothing disk, pois desta forma somente um nó do cluster tem acesso exclusivo a uma ou mais unidades lógicas da “storage” de cada vez.
· Disco de Quorum (Quorum Disk): é uma unidade lógica na “storage” que contém o arquivo de log e informaçőes de estado do cluster. O nó que for o dono do disco de quorum é o nó responsável pelo cluster.
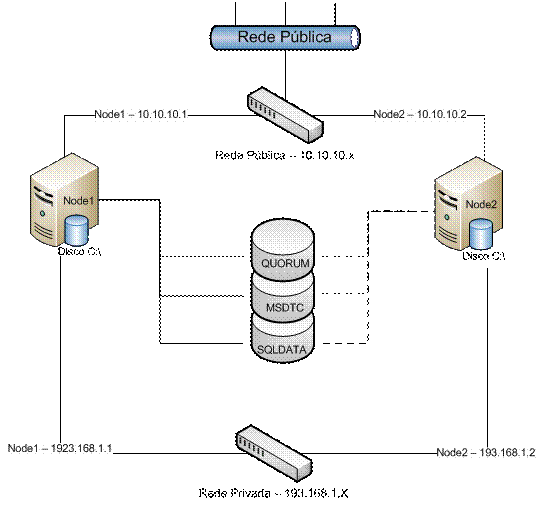
Figura 1. Cluster Completo
Na Figura 1 é possível visualizar como ficaria um cluster completo com todos os seus componentes mais um disco onde possui uma instalaçăo de uma instância (serviço) do SQL Server. No caso de uma falha no nó principal, o segundo nó assumirá os serviços que estavam sendo disponibilizados, sendo transparente para o usuário final. A mudança entre os nós pode ser feita de forma manual ou automática.
Espelhamento de banco de dados
O espelhamento de banco de dados é basicamente uma soluçăo de software para aumentar a disponibilidade dos dados, dando suporte a failover quase instantâneo. O espelhamento de banco de dados mantém duas cópias de um único banco de dados em servidores diferentes. Uma instância do servidor atua como banco de dados para os clientes (servidor principal) enquanto a outra instância funciona como servidor em espera ativa ou passiva (servidor de espelho), dependendo da configuraçăo.
A configuraçăo mais simples do espelhamento do banco de dados envolve apenas os servidores: principal e espelho. Nessa configuraçăo, se o servidor principal for perdido, o servidor espelho poderá ser usado como um servidor de espera passiva (a mudança deve ocorrer de forma manual), onde poderá ocorrer possível perda de dados (Ver Figura 2).
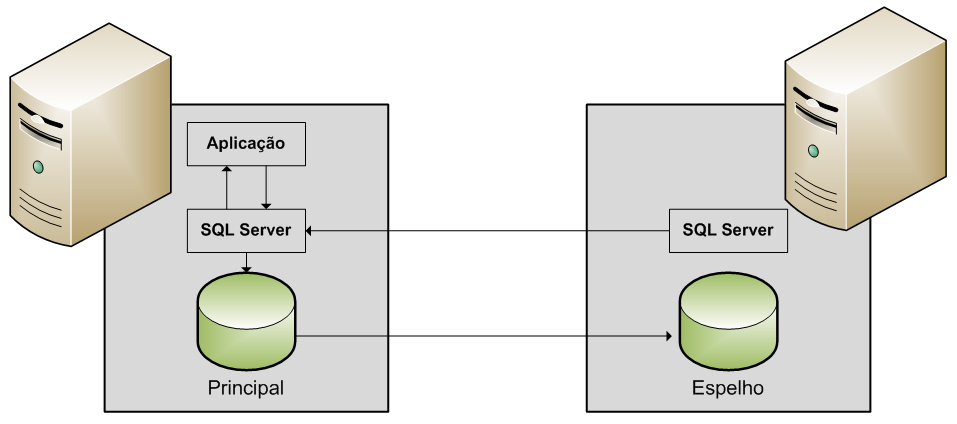
Figura 2. Espelhamento de Banco de Dados
Outra configuraçăo é dita como modo de alta segurança com failover. Neste caso envolverá mais uma instância de servidor de banco de dados, conhecido como testemunha, que possibilita que o servidor espelho atue como um servidor em espera ativa (a mudança ocorre de forma automática) (ver Figura 3). O failover do banco principal para o banco de espelho normalmente demora vários segundos.
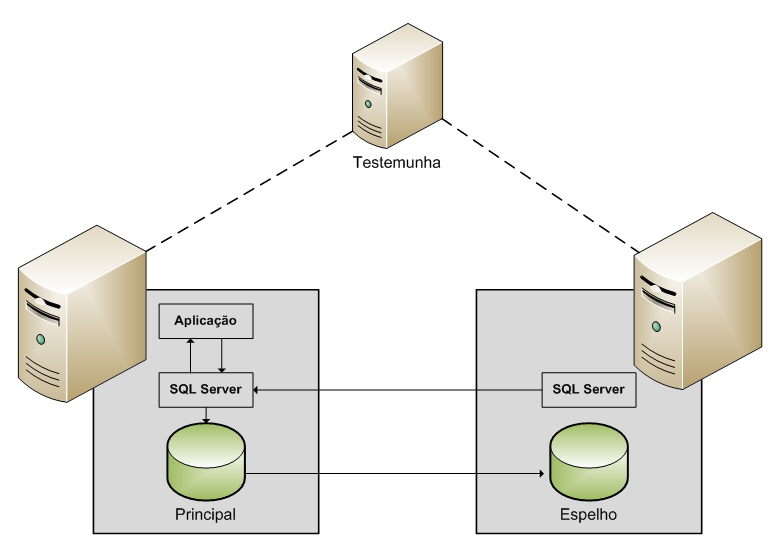
Figura 3. Espelhamento com Servidor de Testemunha
As Figuras 2 e 3 demonstram como resultaria a configuraçăo do espelhamento de banco de dados com e sem o servidor de testemunha. Caso ocorra uma falha no banco de dados principal o servidor espelho deverá assumir o seu lugar, fazendo com que os usuários possam continuar acessando o aplicativo, mesmo após a ocorręncia de alguma falha.
O espelhamento de banco de dados oferece os seguintes benefícios:
· Detecçăo e failover automático;
· Failover manual;
· Redirecionamento transparente para os clientes;
· Opera em nível de banco de dados;
· Usa uma única cópia duplicada do banco de dados;
· Usa servidores padrăo;
· Fornece relatórios no servidor de espelho, usando cópias do banco de dados (instantâneos);
· Quando opera sincronicamente, proporciona zero perda de trabalho por meio de confirmaçăo atrasada no banco de dados principal.
Log Shipping (Envio de Logs)
Assim como o espelhamento de banco de dados, o Log Shipping também é uma soluçăo de software. Este recurso pode ser utilizado para manter um ou mais banco de dados de espera passiva (banco de dados secundário) para um banco de dados de produçăo (banco de dados primário).
O Log Shipping permite o envio automático de backups do log de transaçőes (ver Nota DevMan 1) de um banco de dados primário para um banco de dados secundário. Os backups de logs de transaçăo săo aplicados individualmente aos bancos de dados secundários, dessa forma existindo cópias do banco de dados primário. Uma terceira instância de servidor opcional, conhecido como servidor monitor, registra o histórico e o status das operaçőes de backup e restauraçăo e podendo emitir alertas se essas operaçőes năo forem executadas corretamente.
A Figura 4 mostra a configuraçăo do envio de logs com uma instância do servidor primário, uma instância secundária e uma instância de servidor monitor. Esta figura ilustra as etapas executadas pelos backups, cópia e restauraçăo:
1. A instância do servidor primário executa o trabalho de backup do log de transaçőes do banco de dados primário. Essa instância do servidor coloca o backup do log em um arquivo de backup de log primário, enviado para a pasta de backup.
2. A instância de servidor secundário executa seu próprio trabalho de cópia do arquivo de backup de log primário para a sua própria pasta de destino local.
3. O servidor secundário executa seu próprio trabalho de restauraçăo do arquivo de backup de log a partir da pasta de destino local no banco de dados secundário local.
Controle de Log e Transaçőes do SQL Server: Uma transaçăo garante que qualquer operaçăo seja ou totalmente completada ou desfeita caso ocorra uma falha, mas nunca permite que o banco de dados fique em um estado intermediário. O SQL Server implementa as transaçőes usando um arquivo de Log. Quaisquer mudanças realizadas em qualquer dado irăo atualizar a memória cachę, simultaneamente todas as operaçőes realizadas serăo escritas no Log.
As instâncias de servidor primário e secundário enviam seus próprios históricos e status para a instância do servidor de monitoramento.
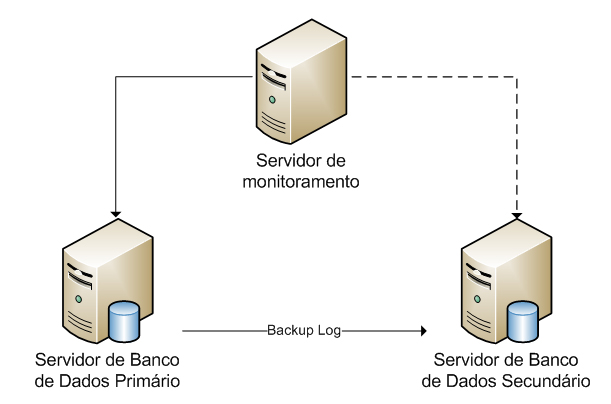
Figura 4. Configuraçăo Típica Log Shipping
O Log Shipping envolve um atraso modificável pelo usuário entre o momento em que o servidor primário cria um backup de log do banco de dados e quando o servidor secundário restaura um banco do backup. Antes que um failover possa ocorrer, um banco de dados deve ser atualizado completamente pela aplicaçăo manual de quaisquer backups de log năo restaurados.
Esta soluçăo fornece a flexibilidade de suportar vários bancos de dados de espera, oferecendo as seguintes funcionalidades:
· Suporte a vários bancos de dados secundários em várias instâncias de servidor para um único banco de dados primário;
· Permite um atraso especificado pelo usuário entre o momento em que o servidor primário faz backup do log do banco de dados primário e quando os servidores secundários devem restaurar o backup de log. Um atraso mais longo pode ser útil, por exemplo, se dados forem alterados acidentalmente no banco de dados primário. Se a alteraçăo acidental for notada rapidamente, um atraso pode permitir que vocę recupere dados ainda inalterados de banco de dados secundário, antes que alteraçăo seja refletida.
Se precisar de vários bancos de dados de espera, poderá usar o Log Shipping independentemente ou como um suplemento para o espelhamento de banco de dados.
Replicaçăo
A replicaçăo é utilizada para copiar dados para um servidor e distribuí-los para outros servidores. Também pode ser utilizada para copiar, transformar e distribuir os dados personalizados entre os múltiplos servidores. Usando a replicaçăo, é possível distribuir dados para diferentes locais e para usuários remotos e móveis através de redes locais e de longa distância, conexőes dial-up, conexőes sem fio e a Internet. Algumas razőes para usar a replicaçăo incluem:
· Sincronizar alteraçőes para bancos de dados remotos com um banco de dados central. Por exemplo, se a equipe de vendas utiliza laptops remotos, vocę pode precisar criar uma cópia de dados para a regiăo de vendas da equipe no laptop. Mais tarde, um vendedor no campo poderá desconectado da rede, acrescentar informaçőes ou fazer alteraçőes. Com a replicaçăo, essas modificaçőes seriam sincronizadas com o banco de dados central.
· Criar múltiplas instâncias de um banco de dados para que vocę possa distribuir a carga de trabalho. Por exemplo, se tiver um banco de dados central que é atualizado regularmente, talvez seja recomendável obter alteraçőes para os bancos de dados departamentais ŕ medida que elas ocorram. Os empregados podem entăo acessar os dados departamentais em vez de tentar se conectar ao banco de dados central.
· Mover conjuntos de dados específicos de um servidor central e distribuí-los para vários outros servidores. Por exemplo, usar a replicaçăo para um banco de dados central que precisasse distribuir os dados de vendas para todos os bancos de dados de lojas de departamento da empresa.
A replicaçăo foi projetada para atender ŕs necessidades de uma ampla variedade de ambientes. A arquitetura de replicaçăo é dividida em vários processos, procedimentos e componentes diferentes, cada um dos quais é utilizado para personalizar a replicaçăo para uma situaçăo particular. A arquitetura de replicaçăo inclui:
· Componentes da replicaçăo: săo os componentes servidores e dados na replicaçăo. Sendo eles:
o Publicador: săo servidores que disponibilizam os dados para a replicaçăo em outros servidores. Também monitoram alteraçőes nos dados e mantęm outras informaçőes sobre o banco de dados de origem. Todo agrupamento de dados tem apenas um publicador.
o Distribuidor: săo servidores que distribuem os dados replicados. Os distribuidores armazenam o banco de dados de distribuiçăo, os metadados, os dados históricos e (para replicaçăo transacional) as transaçőes.
o Assinante: săo servidores de destino para replicaçőes. Esses servidores armazenam os dados replicados e recebem atualizaçőes. Os assinantes também podem fazer alteraçőes em dados. Os dados podem ser publicados em múltiplos assinantes.
· Agentes e trabalhos de replicaçăo: Aplicativos que auxiliam no processo de replicaçăo.
· Variantes da replicaçăo: Săo os tipos de replicaçăo, sendo elas:
o Replicaçăo Transacional: normalmente é usada em cenários de servidor para servidor que requerem alta taxa de transferęncia, incluindo: melhora da escalabilidade e disponibilidade; armazenamento de dados data warehouse e relatórios; integraçăo de dados de vários sites; integraçăo de dados heterogęneos e descarregamento de processamento em lote.
o Replicaçăo de Mesclagem: é projetada principalmente para aplicativos móveis ou de servidor distribuído que possuem possíveis conflitos de dados. Os cenários comuns incluem: troca de dados com usuários móveis; aplicativos de POS (ponto de vendas) para o consumidor e integraçăo de dados de vários sites.
o Replicaçăo de Instantâneo (Snapshot): é usada para fornecer o conjunto inicial de dados para replicaçăo transacional e de mesclagem. Ela também pode ser usada quando as atualizaçőes completas de dados estiverem apropriadas.
A Figura 5 demonstra como ficaria a arquitetura da replicaçăo.
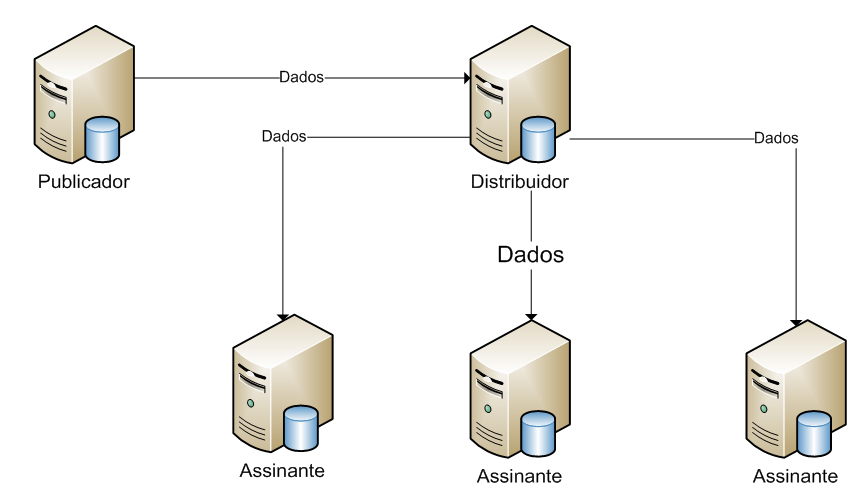
Figura 5. Replicaçăo
A replicaçăo possibilita disponibilidade em tempo real e escalabilidade entre servidores. Suporta filtragem para fornecer um subconjunto de dados nos Assinantes e também permite atualizaçőes particionadas. Os Assinantes ficam online e disponíveis para relatórios e outras funçőes, sem recuperaçăo de consultas.
Configurando Espelhamento de Banco de Dados
Agora que conhecemos as soluçőes disponíveis para disponibilidade de um banco de dados, vamos agora simular uma das soluçőes de disponibilidade que o SQL Server 2005/2008 fornece levando em consideraçăo o seguinte estudo de caso: vocę é administrador de um banco de dados de uma empresa que vende seus produtos através da web. É preciso garantir a disponibilidade dos dados, sem qualquer tipo de interrupçăo. Analisando o ambiente do cliente, vocę decide implementar o espelhamento do banco com espera ativa.
Antes de aprendermos como criar um espelhamento no banco, vamos criar o banco de dados SQLMagazine e as tabelas que o compőem: PRODUTOS, CLIENTES e VENDAS (Ver Listagem 1). Para executar a Listagem 1, abra o SQL Server Management Studio, conecte-se na instância que será o serviço principal do espelhamento. Em seguida, na barra de ferramentas solicite uma nova query (Ver Figura 6).
.jpg)
Figura 6. Solicitando uma nova query
Listagem 1. Criando banco de dados e tabelas
USE [MASTER]
GO
-- CRIA O BANCO DE DADOS
CREATE DATABASE SQLMagazine
GO
USE [SQLMAGAZINE]
GO
-- TABELA CLIENTE
CREATE TABLE [dbo].[CLIENTE](
[PKID] [int] IDENTITY(1,1) PRIMARY KEY CLUSTERED NOT NULL,
[RAZAO_SOCIAL] [varchar](50) NULL,
[NOME_FANTASIA] [varchar](50) NULL,
[CPF_CNPJ] [varchar](18) NOT NULL,
[TIPO] [int] NULL,
[DATA_CADASTRO] [datetime] NOT NULL CONSTRAINT [DF_ DATA_CADASTRO] DEFAULT (getdate()),
[MUNICIPIO] [varchar](50) NULL,
[ENDERECO] [varchar](60) NULL,
[NUMERO] [varchar](7) NULL,
[BAIRRO] [varchar](30) NULL,
[COMPLEMENTO] [varchar](40) NULL,
[CEP] [varchar](10) NULL
)GO
-- TABELA PRODUTO
CREATE TABLE [dbo].PRODUTOS(
[PKCODIGO] [varchar](20) PRIMARY KEY CLUSTERED NOT NULL,
[VALOR_UNITARIO] [decimal](18, 2) NULL,
[STATUS] [bit] NOT NULL,
[PRECO_VENDA] [decimal](18, 2) NOT NULL,
[QTDE_ESTOQUE] [decimal](18, 4) NULL,
[DATA_VALIDADE] [datetime] NULL
)
GO
-- TABELA VENDA
CREATE TABLE [dbo].[VENDA](
[PKID] [int] IDENTITY(1,1) PRIMARY KEY CLUSTERED NOT NULL,
[CLIENTE_PKID] [int] NULL,
[PRODUTO_PKCODIGO] [varchar](20) NULL,
[DATA_VENDA] [datetime] NULL,
[QUANTIDADE] [decimal](18, 2) NULL,
[VALOR_TOTAL] [decimal](18, 2) NULL
)
GO
-- CRIANDO O RELACIONAMENTO DAS TABELAS ENTRE VENDA/CLIENTE
ALTER TABLE [dbo].[VENDA] WITH CHECK ADD CONSTRAINT [FK_VENDA_CLIENTE]
FOREIGN KEY([CLIENTE_PKID])
REFERENCES [dbo].[CLIENTE] ([PKID])
GO
-- CRIANDO O RELACIONAMENTO DAS TABELAS ENTRE VENDA/PRODUTO
ALTER TABLE [dbo].[VENDA] WITH CHECK ADD CONSTRAINT [FK_VENDA_PRODUTO_SERVICO]
FOREIGN KEY([PRODUTO_PKCODIGO])
REFERENCES [dbo].[PRODUTOS] ([PKCODIGO])
GO
Agora que possuímos nosso banco de dados, vamos preparar o nosso ambiente. É necessário ter uma atençăo especial na preparaçăo inicial do espelhamento de banco de dados, cuidando para atender todos os pré-requisitos. Sendo eles:
· Os servidores que vocę escolher para o espelhamento devem possuir a mesma ediçăo do SQL Server 2005/2008. Sendo que as versőes que permitem o espelhamento săo SQL Server Enterprise e SQL Server Standard, para os papéis do banco principal e espelho. A terceira instância, que é responsável pelo failover, poderá utilizar as seguintes versőes: SQL Server Express, SQL Server Workgroup. Para verificar as versőes, vocę deve executar uma consulta em todas as instâncias que serăo utilizadas. Para tal, abra uma nova query (Figura 6), digite e execute a consulta mostrada na Figura 7.
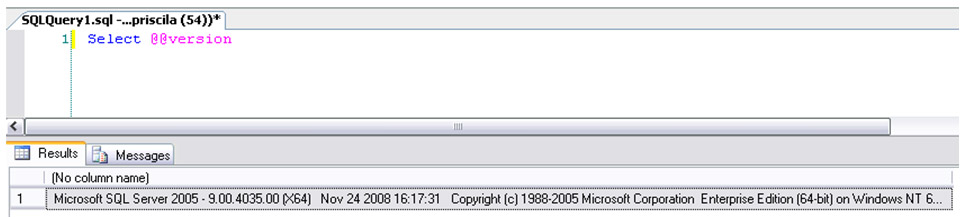
Figura 7. Verificando a versăo do SQL Server
Verifique se todos os servidores estăo se comunicam. Está verificaçăo pode ser feita dando um ping nos servidores através dos seguintes passos:
o Menu Iniciar -> Executar;
o Digite CMD;
o Na janela que aparece, digite ping [Nome Servidor], conforme pode ser visualizado na Figura 8.
.png)
Figura 8. Verificando a comunicaçăo
Repita o processo nos outros servidores, disparando o comando de um para outro, por exemplo, ping SRV01 – no servidor SRV02; ping SRV02 – no servidor SRV01.
O banco de dados principal deve estar configurado com o modo de recuperaçăo FULL. Execute a Listagem 2 em uma nova query para configurar está opçăo.
Listagem 2. Alterando o modo de recuperaçăo
USE [master]
GO
ALTER DATABASE [SQLMagazine] SET RECOVERY FULL
GO
Após concluir os pré-requisitos, poderemos iniciar a configuraçăo do espelho do banco de dados. Em uma ambiente de produçăo, o ideal é que cada instância esteja em máquinas diferentes, mas a título de teste vocę pode instalar tręs instâncias na mesma máquina.
Para iniciar o processo, conecte-se na instância que será o principal. Deve-se realizar um backup completo e um backup de log. Este backup será restaurado na instância que será o espelho, isto é necessário para sincronizar as informaçőes. Após o backup, o ideal é que nenhum aplicativo adicione novos dados no banco principal. Para realizar os backups, execute a Listagem 3 em uma nova query.
Listagem 3. Realizando o backup do banco de dados SQLMagazine
USE [master]
GO
-- BACKUP COMPLETO
BACKUP DATABASE SQLMagazine TO DISK='C:\Backup\BKPSQLMagazine.bak' WITH INIT
GO
-- BACKUP DO LOG
BACKUP LOG SQLMagazine TO DISK='C:\Backup\BKPLOG_SQLMagazine.trn' WITH INIT
GO
Com os backups realizados, o próximo passo é restaurá-los na instância que será o espelho. Copie os arquivos para o servidor espelho, conecte-se na instância que possuíra o espelho do banco. Abra uma nova query e execute o código da Listagem 4.
Listagem 4. Restaurando o banco de dados SQLMagazine no servidor espelho
USE [master]
GO
-- RESTAURANDO OS ARQUIVOS
RESTORE DATABASE SQLMagazine FROM DISK='C:\Backup\BKPSQLMagazine.bak' WITH NORECOVERY
GO
-- RESTAURANDO O LOG
BACKUP LOG SQLMagazine TO DISK='C:\Backup\BKPLOG_SQLMagazine.trn' WITH REPLACE, NORECOVERY
GO
Ao restaurar o banco de dados espelho, verifique se o banco de dados possui o mesmo nome do banco principal, e a restauraçăo deve ser no modo WHIT NORECOVERY, conforme Listagem 4. Se possível, o caminho do banco de dados espelho deve ser idęntico ao caminho do banco de dados principal. Se os caminhos năo forem idęnticos, será necessário adicionar a opçăo MOVE na instruçăo de restauraçăo (ver Listagem 5).
Listagem 5. Restaurando o banco de dados (MOVE)
USE [master]
GO
RESTORE DATABASE SQLMagazine FROM DISK='C:\Backup\BKPSQLMagazine.bak' WITH REPLACE,NORECOVERY,
MOVE 'SQLMagazine_Data' TO 'F:/Dados/SQLMagazine_Data.mdf',
MOVE 'SQLMagazine_Log' TO 'F:/Dados/SQLMagazine_Log.ldf'
GO
Concluída esta etapa, vocę deverá possuir uma imagem semelhante ŕ Figura 9 na instância do banco de dados espelho.
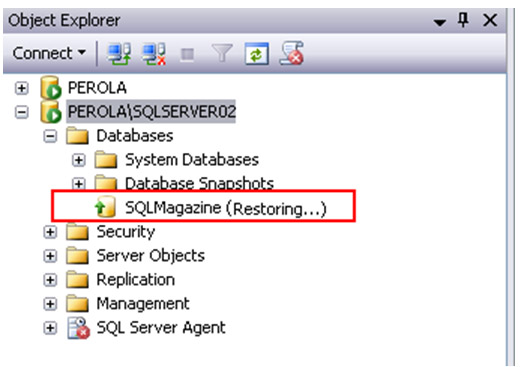
Figura 9. Banco de Dados Espelho
Com o servidor espelho preparado, retornaremos para o servidor principal para configurar o espelhamento. Para isto, conecte-se na instância que possui o banco principal. No Object Explore, clique com o botăo direito no banco, nas opçőes que aparecem selecione Task ŕ Mirror (Figura 10).
.png)
Figura 10. Acessando a opçăo de criaçăo de Espelho (Mirror)
Em seguida, aparecerá uma nova janela (Figura 11) onde vocę configurará a conexăo entre os servidores e modo de operaçăo, que poderá ser escolhido uma das tręs opçőes disponíveis. Após a configuraçăo do espelhamento elas serăo habilitadas. As opçőes disponíveis săo:
- High Availability: Para maximizar o desempenho, o banco de dados espelho fica sempre um pouco atrás do banco de dados principal, isto é, há uma demora para sincronizar todos os dados do banco. Porém, a lacuna entre os bancos de dados é geralmente pequena. A perda de um parceiro tem o seguinte efeito:
- Se a instância do servidor espelho ficar indisponível, o principal continuará.
- Se a instância do servidor principal ficar indisponível, o espelho irá parar; mas se a sessăo năo tiver um servidor testemunha (como recomendado) ou se o servidor testemunha estiver conectado ao servidor espelho, o servidor espelho ficará acessível como espera passiva e o proprietário do banco de dados poderá forçar o serviço para a instância do servidor espelho (com possível perda de dados).
- High Protection: Todas as transaçőes confirmadas tęm a garantia de serem gravadas no disco do servidor espelho. O failover manual é possível quando os parceiros estăo conectados um ao outro e o banco de dados está sincronizado. A perda de um parceiro tem o seguinte efeito:
- Se a instância do servidor espelho ficar indisponível, o principal continuará.
- Se a instância do servidor principal ficar indisponível o espelho irá parar, mas ficará acessível como espera passiva e o DBA poderá forçar a inicializaçăo do serviço do servidor espelho (com possível perda de dados).
- High Performance: Todas as transaçőes confirmadas tęm a garantia de serem gravadas no disco no servidor espelho. A disponibilidade é maximizada incluindo uma instância do servidor testemunha para dar suporte ao failover automático. Observe que vocę só pode selecionar a opçăo Alta segurança com failover automático (síncrono) se tiver antes especificado o endereço de um servidor testemunha. Na presença de um servidor testemunha, a perda de um parceiro tem o seguinte efeito:
- Se a instância do servidor principal ficar indisponível, ocorrerá failover automático. A instância do servidor espelho é alternada para a funçăo principal e oferece seu banco de dados como banco de dados principal.
- Se a instância do servidor espelho ficar indisponível, o principal continuará.
Feito isso, clique no botăo Configure Security... (Figura 11). Aparecerá um Wizard que ajudará a configurar o espelhamento. Clique next nesta primeira janela.
.png)
Figura 11. Configurando o espelho
A primeira etapa a ser configurada é se a sessăo de espelhamento possuirá um servidor de testemunha. No nosso exemplo, precisamos do failover automático, entăo selecionaremos a opçăo Yes. Clique em next. Aparecerá uma lista com os servidores que deverăo fazer parte do espelhamento (Figura 12). Deixe as opçőes padrăo e clique em next.
.png)
Figura 12. Servidores que serăo configurados
A próxima etapa consiste em criar as conexőes entre os servidores. Para tal, o SQL Server criará um endpoint, que é um objeto que permite a comunicaçăo entre a rede. Quando o espelhamento é configurado, a instância requer seu próprio e dedicado endpoint mirroring, que é usado exclusivamente para receber a comunicaçăo entre os bancos de dados (principal, espelho e testemunha). As Figuras 13, 14 e 15 mostram essa configuraçăo. Vocę deverá identificar cada instância SQL Server que irá participar e informar uma porta (se as instâncias estivem em máquinas diferentes pode deixar a porta default; caso contrário deverá informar portas diferentes). Para a conexăo nos servidores, utilize Windows Authentication se estiverem no mesmo domínio, senăo utilize a SQL Authentication, informando um usuário e senha.
.png)
Figura 13. Principal Server
.png)
Figura 14. Server Mirror
.png)
Figura 15. Server Witness
Após terminar de configurar o Witness e clicar em next, aparecerá uma janela pedindo para informar a conta que deve iniciar o serviço (Figura 16). Se a mesma conta iniciar todos os serviços ,vocę poderá deixar as caixas em brancos, caso contrário deverá informar uma conta que possua permissőes de acesso em todos os servidores.
.png)
Figura 16. Contas de Serviço
Clique em next, aparecerá uma listagem com todos as configuraçőes que foram efetuadas. Se estiver tudo de acordo clique em Finish, e o SQL Server irá criar todas as configuraçőes. Se tudo estiver correto vocę verá a Figura 17.
.png)
Figura 17. Finalizando a criaçăo dos endpoints
Ao clicar em close, aparecerá uma mensagem se vocę deseja iniciar o espelhamento (Ver Figura 18).
.png)
Figura 18. Iniciando o espelhamento
Clique no botăo iniciar, para que o espelhamento comece. Como configuramos um servidor testemunha, ele iniciará com o modo High Performance. Se tudo estiver ocorrido bem vocę verá a seguinte imagem no Object Explorer (Figura 19).
.png)
Figura 19. Verificando o espelhamento
Pronto! O espelhamento está configurado e iniciado. Agora vocę pode inserir, alterar ou excluir os dados ou criar novas tabelas, que as mudanças serăo refletidas para o banco espelho. Para testar isto, vamos criar uma nova tabela, bem simples, apenas para teste. Execute a Listagem 6 para criar uma nova tabela no banco de dados principal.
Listagem 6. Criando uma nova tabela
USE [SQLMagazine]
GO
CREATE TABLE TB01(
COD INT NOT NULL
)
GO
Vamos verificar agora se a tabela foi replicada para o banco espelho. Iremos parar o serviço do banco de dados principal. Com a interrupçăo do serviço, deverá ocorrer um failover automático para o banco espelho. Para isto, selecione com o botăo direito do mouse na instância principal. Nas opçőes que aparecem cliquem em Stop (Figura 20).
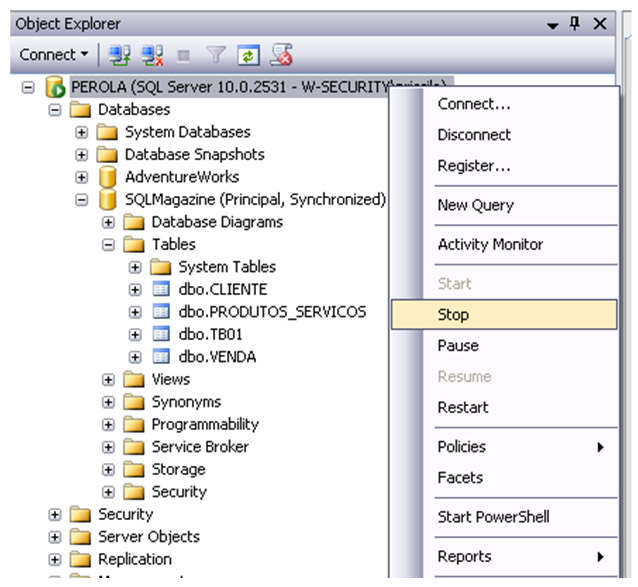
Figura 20. Parando serviço do banco principal
Atualize as instâncias e poderá ser verificado que agora quem está como principal é a segunda instância (Figura 21).
.png)
Figura 21. Verificando o failover
Conforme podemos visualizar na Figura 21, a segunda instância assumiu os serviços do banco principal. Verificamos também que a tabela que foi criada no banco principal foi replicada para o espelho, possuindo a mesma estrutura, dados e informaçőes. É possível visualizar que ao lado do banco vemos o status do banco, que aparece SQLMagazine (Principal, Disconnected). A mensagem Desconectado aparece por que o outro parceiro ainda năo está no ar. Quando iniciarmos o serviço novamente, os bancos ficarăo como a tela mostrada na Figura 19, apenas com os papéis trocados.
O espelhamento é útil quando os dados devem estar sempre disponíveis. Assim poderemos ter uma alternativa rápida de troca de serviços quando um problema acontece ou quando o servidor principal precisa passar uma manutençăo, que exigem deixá-lo indisponível.
Conclusăo
A alta disponibilidade tem como objetivo eliminar as paradas năo planejadas. Paradas năo planejadas ocorrem por defeitos, já as paradas planejadas săo normalmente por causa de atualizaçőes, manutençăo preventiva e atividades correlatas.
Desta forma é preciso identificar primeiramente todas as necessidades de negócios da empresa para que se possa definir a correta opçăo de alta disponibilidade. No artigo foram apresentadas, de forma resumida, as diversas opçőes que o SQL Server disponibiliza para a alta disponibilidade dos dados, assim como foi demonstrado como é configurado um espelhamento do banco de dados, que é uma das opçőes de alta disponibilidade. Possuindo assim as informaçőes em outro servidor que poderá assumir o papel de principal sem que os usuários percebam e sem grandes transtornos.
Books Online SQL Server 2005
http://msdn.microsoft.com/en-us/library/ms130214.aspx
Artigo “Cluster de Failover”.
http://technet.microsoft.com/pt-br/library/cc725923.aspx
Artigo “Replicaçăo do SQL Server”.
http://msdn.microsoft.com/pt-br/library/ms151198.aspx
Artigo “Visăo Geral: Envio de Logs”.
http://msdn.microsoft.com/pt-br/library/ms187103.aspx
Artigo “Visăo geral do espelhamento de banco de dados”.
http://msdn.microsoft.com/pt-br/library/ms187103.aspx
Artigo “Database Mirroring – Configurando Alta disponibilidade no Banco de Dados”, escrito por Nilton Pinheiro.
http://www.mcdbabrasil.com.br/modules.php?name=News&file=article&sid=336







