Na arquitetura do SQL Server, um dos grandes componentes Ú o SQLOS (Sistema Operacional do SQL Server), que tem por objetivo lidar com os recursos que podem ser considerados de responsabilidade do sistema operacional, como o gerenciamento de mem¾ria, detecþÒo de Deadlock, sincronizaþÒo de objetos, entre outros. O SQLOS estß presente em uma camada entre o SQL Server e o Windows, tendo como seu serviþo principal o Scheduling (Agendamento).
Modelo de ExecuþÒo
Para entendermos conceitualmente o Scheduling dentro do SQLOS, serß necessßrio iniciarmos pelo modelo de execuþÒo utilizado pelo SQL Server.
Quando uma aplicaþÒo faz uma autenticaþÒo no SQL Server, Ú estabelecida uma conexÒo no contexto de uma sessÒo, na qual podemos identificar pelo Session_id ou pelo SPID. Um SPID Ú uma conexÒo ou canal pelo qual as requisiþ§es podem ser enviadas.
Uma vez que Ú feito uma requisiþÒo para a sessÒo criada, o SQL Server divide seu trabalho em uma ou mais tarefas (Tasks) e, em seguida, associa um Worker Thread para cada tarefa ao longo de sua duraþÒo. O Worker Thread Ú uma representaþÒo l¾gica do SQL Server para uma Thread.
Cada Thread tem um Scheduler associado, que tem a funþÒo de agendar um tempo no processador para cada uma das Threads. O n·mero Schedulers disponÝveis no SQL Server Ú igual ao n·mero de processadores l¾gicos que o SQL Server pode utilizar adicionado a mais um, para o DAC (Dedicated Administrator Connection). Veja exemplo na Figura 1.
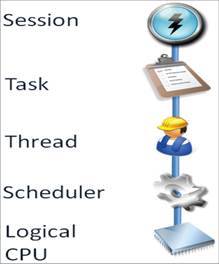
Figura 1. Relacionamento entre a sessÒo, tarefa, Thread, Scheduler e CPU L¾gico.
Scheduling
Antes do SQL Server 7.0, o Scheduling dependia totalmente do sistema operacional Windows. Embora isso signifique que o SQL Server irß tirar vantagem do Windows para melhorar a escalabilidade e uso eficiente do processador, existem limites definidos. Isso porque o Scheduler do Windows nÒo sabe nada sobre as necessidades de um sistema de banco de dados relacional, ele trata as Worker Threads do SQL Server da mesma maneira que outro processo qualquer que roda no sistema operacional. No entanto, um sistema de alto desempenho como o SQL Server funciona melhor quando um Scheduler pode atender suas necessidades especiais. SQL Server 7.0 e todas as vers§es subsequentes foram projetados para lidar com seu pr¾prio Scheduler e ganhar diversas vantagens.
Nas vers§es do SQL Server 7.0 e 2000 os Schedulers eram chamados de User Mode Scheduler (UMS) para refletir o que ocorreu primeiramente no modo de usußrio, ao contrßrio do modo Kernel. Da versÒo do SQL Server 2005 em frente, foi chamado de SOS Scheduler e melhorou o UMS ainda mais.
No SQL Server 2012 cada CPU tem um Scheduler criado para ele quando o SQL Server Ú iniciado. Esse processo ocorre mesmo se a configuraþÒo de Affinity Mask estiver em uso para determinar quais CPUs fÝsicos o SQL Server utilizarß. Baseando-se na configuraþÒo do Affinity Mask, cada Scheduler pode ter os status de Online e Offline, por padrÒo todos os Schedulers estÒo Online e as exceþ§es sÒo poucas.
Cada Scheduler Ú identificado por seu ·nico Scheduler_Id. Valores entre 0 e 254 sÒo reservados para os Schedulers que estÒo rodando requisiþ§es de usußrios. Schedulers com o Scheduler_Id maiores 255 sÒo reservados para o uso do Sistema e tambÚm para o Dedicated Administrator Connection, tipicamente sÒo atribuÝdos a mesma tarefa.
A consulta da Listagem 1 mostra algumas informaþ§es importantes da DMV Sys.dm_os_schedulers. Veja na Figura 2 o resultado.
Listagem 1. C¾digo da consulta na DVM sys.dm_os_schedulers.
select parent_node_id, scheduler_id, cpu_id, status, scheduler_address
from sys.dm_os_schedulers
order by scheduler_id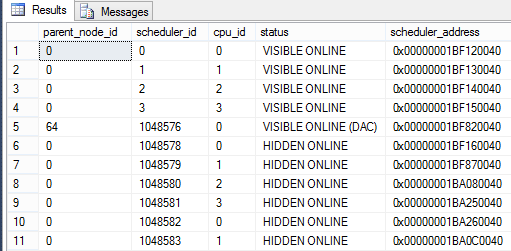
Figura 2. Retorno da consulta na DVM sys.dm_os_schedulers.
Os resultados acima mostram quatro linhas com o Scheduler_Id menor que 255, ou seja, os resultados sÒo de uma mßquina com quatro processadores l¾gicos (Cores). TambÚm Ú possÝvel de ser visto um Scheduler_Id com valor de 1048576 que tem o Status de Visible Online (DAC), indicando que Ú utilizado pelo Dedicated Administrator Connection. Os Schedulers_Id maiores que 255 sÒo reservados para o uso do sistema.
Windows Scheduler
Windows Ú um sistema operacional de prop¾sito geral e nÒo Ú otimizado para aplicaþ§es baseadas em servidor, em particular o SQL Server. Em vez disso, o objetivo da equipe de desenvolvimento do Windows Ú garantir que todas as aplicaþ§es irÒo funcionar corretamente e ter um bom desempenho. Isso por que o Windows precisa trabalhar bem um com uma vasta gama de cenßrios e a equipe de desenvolvimento nÒo irß fazer nada de especial que possa apenas ser utilizada por menos de 1% das aplicaþ§es. Por exemplo, o Scheduler no Windows Ú muito bßsico para assegurar que Ú adequado para uma causa comum.
Otimizando o caminho que as Threads sÒo escolhidas para execuþÒo sempre vai ser limitado por causa desse objetivo amplo de desempenho, mas se uma aplicaþÒo faz seu pr¾prio Scheduler, entÒo nÒo hß mais inteligÛncia sobre a pr¾xima escolha, como a atribuiþÒo de mais Threads com prioridades maiores ou decidindo uma Thread para execuþÒo que irß evitar que as outras Threads sejam bloqueadas posteriormente.
O Scheduler bßsico do Windows Ú conhecido como Scheduler Preemptivo e ele atribui fatias de tempo conhecidos como Quantums para cada tarefa a ser executada. A vantagem disso Ú que os desenvolvedores nÒo tem que se preocupar com o Scheduler quando criam as aplicaþ§es, a desvantagem Ú que a execuþÒo pode ser interrompida a qualquer momento enquanto o Windows balanceia as requisiþ§es de execuþÒo de m·ltiplos processos.
Todas as vers§es do SQL Server usam o Windows Scheduler para tirar vantagem do trabalho que o time de Windows tem feito ao longo da hist¾ria para otimizaþÒo do uso do processador.
Task
Uma Task Ú uma requisiþÒo para fazer alguma unidade de trabalho. A Task por si s¾ nÒo faz nada, Ú apenas um contÛiner para que uma unidade de trabalho seja concluÝda. Para realmente fazer algo, a Task precisa ser agendada em um dos Schedulers e associada a um Worker.
A consulta da Listagem 2 mostra algumas informaþ§es importantes da DMV Sys.dm_os_task. Veja na Figura 3 mostra o retorno da consulta.
Listagem 2. C¾digo da consulta na DVM sys.dm_os_tasks.
Select * from sys.dm_os_tasks
Figura 3. Retorno da consulta na DVM sys.dm_os_tasks.
Uma Task Ú um contÛiner de trabalho que estß sendo feito, mas ao observar a DMV acima, nÒo existe indicaþÒo de qual trabalho exatamente Ú feito. Para descobrir o que cada Task realmente estß fazendo requer uma consulta mais elaborada, como mostra a Listagem 3. Veja o resultado na Figura 4.
Listagem 3. C¾digo da consulta elaborada.
Select t.task_address, s.text
From sys.dm_os_tasks as t inner join sys.dm_exec_requests as r
on t.task_address = r.task_address
Cross apply sys.dm_exec_sql_text (r.plan_handle) as s
where r.plan_handle is not null
Figura 4. Retorno da consulta elaborada.
Workers
╔ possÝvel pensarmos no SQL Server Scheduler como um CPU l¾gico usado pelo SQL Server Workers. Um Worker pode ser uma Thread ou Fibra ligados a um Scheduler l¾gico. Se o Affinity Mask estiver configurado, cada Scheduler Ú mapeado para um determinado CPU, sendo assim, cada Worker tambÚm Ú associado a um ·nico CPU. Cada Scheduler Ú associado a um Worker que tem seu limite configurado com base na opþÒo de Max Worker Threads e n·mero de Schedulers. Os Schedulers sÒo responsßveis por criarem ou destruÝrem os Workers conforme necessßrio. Um Worker nÒo pode se mover de um Scheduler para outro, mas como podem ser destruÝdos e criados, Ú possÝvel que eles apareþam como se estivessem se movendo entre os Schedulers.
Os Workers sÒo criados quando o Scheduler recebe uma requisiþÒo e quando nÒo existem Workers ociosos, sendo que, podem ser destruÝdos caso esteja ocioso por pelo menos 15 minutos ou se o SQL Server estiver sob pressÒo de mem¾ria. Cada Worker pode utilizar pelo menos meio megabyte de mem¾ria em um ambiente 32-bit ou atÚ 2Mb em 64 Bit, sendo assim, destruindo os Workers irß liberar mem¾ria e imediatamente melhorar o desempenho do ambiente.
O SQL Server lida com os Workers de maneira muito eficiente e mesmo em ambientes muito grandes com centenas de usußrios, o atual n·mero de Workers pode ser muito mais baixo do que o valor configurado para a configuraþÒo de Max Worker Threads.
A consulta da Listagem 4 mostra algumas informaþ§es importantes da DMV Sys.dm_os_workers. Veja o resultado na Figura 5.
Listagem 4. C¾digo da consulta na DVM sys.dm_os_workers.
Select Task_address, State, Last_wait_type, Scheduler_address From sys.dm_os_workers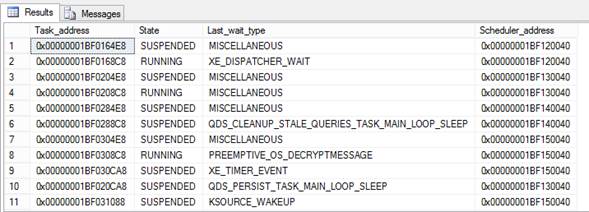
Figura 5. Retorno da consulta na DVM sys.dm_os_workers.
As colunas mais interessantes para observamos sÒo as seguintes:
- Task_address û Possibilita a ligaþÒo com a Task;
- State û Mostra o estado atual do Worker;
- Last_wait_type û Mostra o ·ltimo Wait Type que aquele Worker estß esperando;
- Scheduler_address û Possibilita a ligaþÒo com os Schedulers.
Thread
Complementando o modelo de execuþÒo mostrado inicialmente, o SQLOS tambÚm contÚm objetos para as Threads do sistema operacional que estß usando.
A consulta da Listagem 5 mostra algumas informaþ§es importantes da DMV Sys.dm_os_threads e podemos ver o resultado da Figura 6.
Listagem 5. C¾digo da consulta na DVM sys.dm_os_threads.
Select Scheduler_address, Worker_address, Kernel_time, Usermode_time From sys.dm_os_threads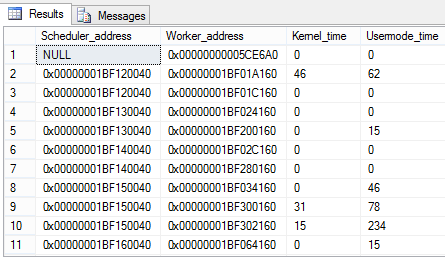
Figura 6. Retorno da consulta na DVM sys.dm_os_threads.
As colunas mais interessantes para observamos sÒo as seguintes:
- Scheduler_address û Endereþo do Scheduler com que a Thread estß associada;
- Worker_address û Endereþo do atual Worker associado a Thread;
- Kernel_time û Quantidade de tempo de Kernel que uma Thread usa desde que foi iniciada;
- Usermode_time û Quantidade de tempo de usußrio que uma Thread tem usado desde que foi iniciada.
NUMA
Non-Uniform Memory Architecture (NUMA) Ú um modelo de hardware que aumenta a escalabilidade do servidor, pois elimina os gargalos na placa-mÒe. Em um sistema NUMA, cada processador tem sua controladora de mem¾ria e conexÒo direta a um grupo dedicado de RAM, a que se refere como mem¾ria local e juntas sÒo representadas como um n¾ (Node) NUMA.
Com a configuraþÒo NUMA, cada n¾ tem um subgrupo de processadores e o mesmo n·mero de Schedulers. Se a mßquina estß configurada para utilizar hardware NUMA, o n·mero de processadores em cada n¾ Ú prÚ-definido, mas para Soft-NUMA que foi configurado a si mesmo, vocÛ mesmo pode decidir quantos processadores sÒo atribuÝdos para cada n¾. VocÛ ainda tem o mesmo n·mero de Schedulers quanto processadores, entretanto, quando os SPIDs sÒo inicialmente criados, eles atribuem Round-Robin (Algoritmo de agendamento de processos no sistema operacional) aos n¾s.
Dynamic Affinity
No SQL Server 2012, o Processor Affinity pode ser controlado dinamicamente. Quando o SQL Server inicia, todos os Schedulers Tasks sÒo iniciados, de modo que cada CPU tem seu Scheduler. Se o Process Affinity foi configurado, alguns Schedulers sÒo marcados como Offline e nenhuma outra tarefa Ú atribuÝda a eles.
Quando o Process Affinity Ú alterado para incluir CPUs adicionais, a nova CPU Ú colocada Online. O Scheduler Monitor entÒo percebe que ocorreu um desequilÝbrio na carga de trabalho e comeþa a escolher os Workers para atribuir Ó nova CPU. Quando uma CPU Ú colocada Offline pela mudanþa do Process Affinity, o Scheduler daquela CPU continua trabalhando com os Workers ativos, mas o pr¾prio Scheduler Ú movido para um dos outros CPUs que estÒo Online. Nenhum novo Worker Ú atribuÝdo ao Scheduler que estß Offline e quando todos os Workers ativos terminarem terminar suas tarefas, o Scheduler para.
Atribuindo Schedulers a CPU
Normalmente os Schedulers nÒo sÒo atribuÝdos a CPUs em uma rÝgida relaþÒo de um para um, mesmo quando o n·mero de Schedulers Ú igual ao de CPUs. O Scheduler Ú atribuÝdo ao CPU apenas quando o Process Afinity estß configurado, mesmo que seja especificado que o Process Afinity utilize todos os CPUs, o que Ú a configuraþÒo padrÒo. Por exemplo, o valor padrÒo para o Process Afinity Ú Auto, que significa que serÒo utilizados todos os CPUs. Em alguns casos quando o servidor estß sofrendo com cargas altas, o Windows pode trabalhar com dois Schedulers em um CPU.
Em algumas situaþ§es pode ser preferÝvel poder limitar o n·mero de CPUs disponÝveis, mas nÒo atribuir um Scheduler particular a um ·nico CPU. Supondo que tenhamos uma mßquina com 64 processadores que estß rodando oito instÔncias do SQL Server e vocÛ quer que cada instÔncia use os oito processadores. Cada instÔncia tem um Process Affinity diferente que especifica um grupo distinto de 64 processadores, isso por que ap¾s o Process Affinity ser configurado, cada instÔncia tem uma ligaþÒo do Scheduler com o CPU. Caso deseje limitar o n·mero de CPUs, mas ainda nÒo querendo que um determinado Scheduler rode em um especifico CPU, Ú possÝvel iniciar o SQL Server com a Trace Flag 8002. Essa Trace Flag permite que tenhamos CPUs mapeados para uma instÔncia, mas dentro das instÔncias os Schedulers nÒo sÒo atribuÝdos a CPUS.
Identificando Gargalos
AtravÚs do conhecimento obtido a respeito dos Schedulers, podemos nos basear nas informaþ§es da DMV sys.dm_os_schedulers para identificar pressÒo de CPU.
Provavelmente o Wait Type chamado Sos_Scheduler_Yield jß foi visto em alguma anßlise de desempenho jß feita no seu ambiente do SQL Server. O Books Online da Microsoft o descreve como evento que ocorre quando uma Task cede o Scheduler para a execuþÒo de outras Tasks.Durante essa espera, a Task estß esperando que seu Quantum seja renovado.
De forma mais simples, o Sos_Scheduler_Yield Ú um comum Wait Type e ocorre quando existe uma pressÒo de CPU. O SQL Server executa m·ltiplas Threads e tenta permitir que todas as Threads executem sem problemas. Entretanto, se todas as Threads estÒo ocupadas em cada Scheduler e nÒo podem deixar outras Threads executarem, ela pr¾pria irß se ceder para outra Thread, dessa forma criando o Wait Type Sos_Scheduler_Yield.
Para fazer a anßlise dos maiores Waits Stats no ambiente utilizaremos a consulta criada pelo Tim Ford e Glenn Berry, como mostra a Listagem 6. O resultado pode ser visto na Figura 7.
Listagem 6. C¾digo da consulta com os maiores Wait Stats do ambiente.
WITH Waits AS
(
SELECT
wait_type,
wait_time_ms / 1000. AS wait_time_s,
100. * wait_time_ms / SUM(wait_time_ms) OVER() AS pct,
ROW_NUMBER() OVER(ORDER BY wait_time_ms DESC) AS rn
FROM sys.dm_os_wait_stats
WHERE wait_type
NOT IN
('CLR_SEMAPHORE', 'LAZYWRITER_SLEEP', 'RESOURCE_QUEUE',
'SLEEP_TASK', 'SLEEP_SYSTEMTASK', 'SQLTRACE_BUFFER_FLUSH', 'WAITFOR',
'CLR_AUTO_EVENT', 'CLR_MANUAL_EVENT')
) û Filtro para elimitar Waits irrelevantes para essa analise
SELECT W1.wait_type,
CAST(W1.wait_time_s AS DECIMAL(12, 2)) AS wait_time_s,
CAST(W1.pct AS DECIMAL(12, 2)) AS pct,
CAST(SUM(W2.pct) AS DECIMAL(12, 2)) AS running_pct
FROM Waits AS W1
INNER JOIN Waits AS W2 ON W2.rn <= W1.rn
GROUP BY W1.rn,
W1.wait_type,
W1.wait_time_s,
W1.pct
HAVING SUM(W2.pct) - W1.pct < 95; -- Limite de porcentagem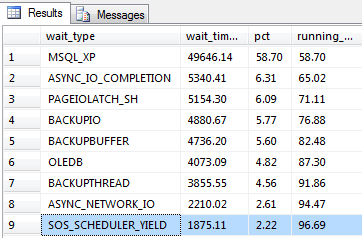
Figura 7. Retorno da consulta com os maiores Wait Stats do ambiente.
Ap¾s executar essa consulta podemos observar que apenas 2,2% dos Waits presentes no ambiente sÒo devido a pressÒo de CPU, podendo concluir que esta Ú uma das causas para um desempenho ruim.
Uma das maneiras para se resolver essa pressÒo de CPU Ú utilizando a DVM Sys.dm_os_schedulers. Como essa DMV retorna informaþ§es como, n·mero de Workers, Tasks ativas, status de cada Scheduler e outros, podem nos ajudar a identificar certos problemas, mas a informaþÒo mais importante estß na coluna que conta a fila de Tasks, a Runnable_task_count. Essa coluna exibe o n·mero de Tasks, com tarefas atribuÝdas a eles, que estÒo esperando por outras Tasks, resultando no Sos_Scheduler_Yield Wait Type. Caso o valor para o Runnable_task_count frequentemente seja maior que zero, entÒo pode existir uma pressÒo de CPU e bloqueios podem ocorrer.
Para ver a mÚdia das Tasks atuais e suas esperas, podemos utilizar a consulta da Listagem 7, com resultado apresentado na Figura 8.
Listagem 7. C¾digo da consulta com as Tasks existentes.
SELECT AVG(current_tasks_count) AS [Avg Current Task],
AVG(runnable_tasks_count) AS [Avg Wait Task]
FROM sys.dm_os_schedulers
WHERE scheduler_id < 255
AND status = 'VISIBLE ONLINE'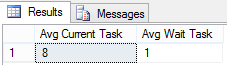
Figura 8. Retorno da consulta com as Tasks existentes.
Outra consulta ·til (Listagem 8) nos retorna as Queries em execuþÒo e seu Scheduler associado no qual estÒo rodando. Podemos ver o resultado na Figura 9.
Listagem 8. C¾digo da consulta com os Schedulers para cada Query em execuþÒo.
SELECT
a.scheduler_id ,
b.session_id,
(SELECT TOP 1 SUBSTRING(s2.text,statement_start_offset / 2+1 ,
( (CASE WHEN statement_end_offset = -1
THEN (LEN(CONVERT(nvarchar(max),s2.text)) * 2)
ELSE statement_end_offset END) - statement_start_offset) / 2+1)) AS sql_statement
FROM sys.dm_os_schedulers a
INNER JOIN sys.dm_os_tasks b on a.active_worker_address = b.worker_address
INNER JOIN sys.dm_exec_requests c on b.task_address = c.task_address
CROSS APPLY sys.dm_exec_sql_text(c.sql_handle) AS s2 
Figura 9. Retorno da consulta com os Schedulers para cada Query em execuþÒo.
A soluþÒo mais fßcil a ser pensada para problemas com pressÒo de CPU provavelmente serß adicionar mais CPU ao servidor, mas essa pode nÒo ser a melhor soluþÒo. Otimizar consultas pesadas tambÚm pode ajudar muito a reduzir o n·mero de Runnable_task_count. Por exemplo, se vocÛ tem um desempenho ruim com seus Ýndices nas consultas, adicionar mais CPU nÒo vai resolver nada.
Uma vez que vocÛ jß otimizou o seu ambiente e mesmo assim continua encontrando o valor maior que zero para o Runnable_task_count, agora sim terß um bom argumento para adicionar mais CPU. Lembre-se que a escolha da quantidade de CPU Ú uma decisÒo que o DBA deve fazer baseado em uma Baseline e os resultados capturados desde entÒo.
Existem outras maneiras de identificar pressÒo de CPU, como a utilizaþÒo do Performance Monitor, SQL Profiler e outros, mas utilizar DVMs pode ser a escolha mais rßpida e leve dependendo da situaþÒo.







