O Oracle GoldenGate proporciona a aquisiçăo, distribuiçăo e entrega de dados em tempo real e com baixo impacto através de sistemas heterogęneos. Assim, ele oferece integraçăo com tecnologias e aplicaçőes Oracle, suporte para sistemas heterogęneos adicionais, e alto desempenho. O Oracle GoldenGate transporta transaçőes confirmadas com integridade transacional e mínimo impacto sobre sua infraestrutura existente.
Em que situaçăo o tema é útil
Para iniciar o aprendizado sobre como administrar, configurar e manter o sistema de replicaçăo GoldenGate, ou mesmo decidir se ele deve ser utilizado em uma implementaçăo baseando-se em suas funcionalidades, recursos, limitaçőes e ferramentas de administraçăo. A escolha do sistema de replicaçăo é parte importantíssima na estratégia de implementaçăo de alta disponibilidade de uma aplicaçăo de missăo critica.
Resumo DevMan
Este artigo apresenta como devemos proceder para configurar o Oracle GoldenGate de forma que ele seja utilizado como a soluçăo de replicaçăo de um banco de dados. Será demonstrado como o administrador de banco de dados pode instalar, iniciar e configurar o GoldenGate. Serăo entăo demonstradas as principais tarefas necessárias para a verificaçăo do correto funcionamento do GoldenGate.
A replicaçăo de dados é muito utilizada nos bancos de dados relacionais, principalmente para garantir alta disponibilidade em sistemas críticos e, em segundo lugar, para prover escalabilidade horizontal (onde a carga é distribuída entre outros servidores). A replicaçăo trata do envio dos dados alterados de um servidor para outro e os principais SGBDs (Sistemas Gerenciadores de Bancos de Dados) do mercado possuem esta funcionalidade.
Em julho de 2009, a Oracle Corporation, célebre devoradora de pequenas, médias e grandes empresas, adquiriu a GoldenGate, uma companhia com uma soluçăo de replicaçăo heterogęnea. Desde entăo, a Oracle passou a encorajar seus clientes a utilizar o GoldenGate ao invés do Streams, sua antiga plataforma de replicaçăo heterogęnea.
A capacidade de executar replicaçăo heterogęnea significa que dados podem ser replicados entre versőes do Oracle Database diferentes (por exemplo, entre Oracle 10gR2 e 11gR2), entre sistemas operacionais diferentes (por exemplo, entre AIX e Windows), entre arquiteturas diferentes (por exemplo, entre Intel Itanium e SPARC), e no caso do GoldenGate, até entre SGBDs diferentes, como entre o Oracle e o DB2. Na verdade, o Oracle Database nem precisa estar envolvido na soluçăo, o GoldenGate pode ser utilizado para replicaçăo entre dois servidores Microsoft SQL Server, por exemplo.
Um grande uso da replicaçăo heterogęnea, além dos já mencionados, é possibilitar a migraçăo entre versőes, sistemas operacionais, arquiteturas ou SGBDs diferentes com um tempo mínimo de parada, pois năo é preciso ter o sistema indisponível durante uma lenta operaçăo de Backup e Restore: apenas "vira-se a chave" para que a aplicaçăo passe a utilizar o novo servidor, que foi constantemente atualizado. Desta forma, um cliente que comprou um AIX em uma máquina nova e muito poderosa, pode migrar seu banco de dados que atualmente está em um antigo servidor Intel de 32 bits com um tempo de indisponibilidade muito pequeno, mesmo tradando-se de um banco de dados na casa de Terabytes.
Topologias de replicaçăo
Além de oferecer a flexibilidade entre a origem e o destino dos dados, o GoldenGate permite que a topologia da replicaçăo seja feita de muitas formas diferentes:
- Unidirecional: esta é a forma mais tradicional e utilizada de replicaçăo, onde um servidor envia dados para outro servidor, e este apenas os recebe. Além de prover alta disponibilidade, este tipo de replicaçăo pode ser utilizada para criar um servidor exclusivo para extraçăo de relatórios pesados, que se fossem executados no servidor principal afetariam um sistema onde o desempenho é crítico;
- Bidirecional: nesta modalidade, cada servidor envia os dados que alterou para o outro, como se fosse um cluster. Mas ao contrário de um cluster, os possíveis conflitos de dados (por exemplo, criar uma Nota Fiscal número 42 em um servidor, ao mesmo tempo em que, por coincidęncia, criar no outro) devem ser tratados no nível da aplicaçăo. Este tipo de replicaçăo é mais utilizado para alta disponibilidade;
- Ponto a ponto (em inglęs, peer-to-peer): neste tipo de replicaçăo, todos os servidores enviam dados para todos os outros servidores em uma extensăo do modelo bidirecional. Da mesma forma, provę um cluster lógico, com a mesma necessidade de tratamento de conflitos. Este modelo atende melhor questőes de alta disponibilidade e escalabilidade horizontal;
- Difusăo (em inglęs, broadcast): neste modelo, um único servidor de produçăo é utilizado pela aplicaçăo e seus dados săo replicados para uma grande quantidade de servidores, para por exemplo, serem utilizados para extraçăo de relatórios. Uma ideia para utilizaçăo deste modelo é uma matriz de uma empresa replicando seus dados para todas suas filiais, apenas para consulta;
- Consolidaçăo (em inglęs, consolidation): este modelo é o oposto da Difusăo, mais utilizado para atender a necessidade da criaçăo de um grande repositório de dados (data warehouse), por exemplo, de todos os principais bancos de uma empresa, para que informaçőes relevantes ao negócio possam ser extraídas dessa massa de dados;
- Em cascata (em inglęs, cascading): neste modelo de replicaçăo, uma combinaçăo entre o Unidirecional e a Difusăo, o servidor principal primeiro envia os dados para um servidor replicado, e este entăo envia para uma grande quantidade de servidores. Este método pode ser útil para se evitar um possível impacto na produçăo de replicar dados para uma grande quantidade de servidores.
Observe na Figura 1 a visualizaçăo gráfica destes tipos de replicaçăo, sendo todos estes cenários possíveis com o GoldenGate. Além de todos estes tipos de replicaçăo, o GoldenGate permite, através de configuraçőes, que os dados sejam filtrados antes de serem transmitidos (replicando só o que importa, economizando recursos de rede), e até mesmo transformados ao serem aplicados no servidor destino (por exemplo, replicando uma tabela com outro nome, ou alterando o conteúdo da coluna de salário de uma tabela de funcionários).
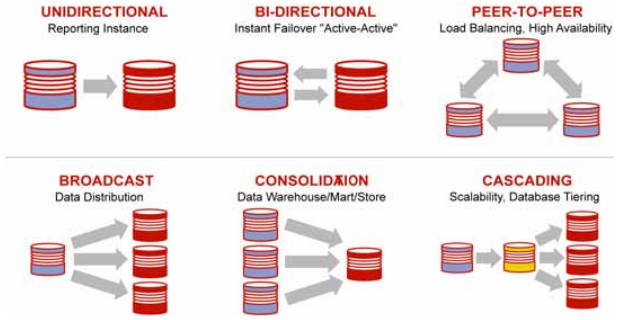
Figura 1. Modelos de replicaçăo de dados.
Neste artigo iremos iniciar a utilizaçăo do GoldenGate por sua forma mais simples; uma replicaçăo unidirecional entre SGBDs, versőes de sistemas operacionais e plataformas iguais. Este é um guia rápido para uma implementaçăo de replicaçăo simples de um único SCHEMA entre dois servidores Linux x86-64 utilizando Oracle Database 11gR2.
Conhecendo o GodenGate
Antes de partirmos para a prática, precisamos conhecer os processos que compőe o GoldenGate. Ele é composto pelos seguintes componentes:
- Extract: é o processo que faz a extraçăo dos dados a partir dos Redo Logs (ver Nota DevMan 1) do Oracle Database. Os dados extraídos săo armazenados nos arquivos Trail, descritos logo abaixo. Se o Extract for configurado de forma a se comunicar diretamente com o servidor destino, ele enviará os arquivos Trail diretamente para este;
- Data Pump: é um subtipo do processo Extract que faz a ponte entre o Extract original do servidor origem, e o Replicat, que recebe os dados no servidor destino. Ele năo é mandatório, mas sem o Data Pump, o Extract teria que se comunicar diretamente com o Replicat, o que pode ser um problema em situaçőes como queda temporária do link de rede, ou um pico de alteraçăo de dados no servidor origem. Ele também é utilizado para fazer filtros e alteraçőes nos dados replicados. Quando o Data Pump é utilizado, é ele que envia os arquivos Trail para o processo Replicat no servidor destino. Este processo năo deve ser confundido com as ferramentas de transporte de dados do Oracle Database também chamadas de Data Pump, que compreendem os programas expdp (para exportaçăo) e impdp (para importaçăo);
- Replicat: é o processo que, sendo executado no servidor destino, lę os arquivos Trail enviados pelo servidor origem (pelo processo Extract ou Data Pump) e aplica as alteraçőes que eles contęm no banco de dados;
- Arquivos Trail: săo os arquivos que contęm os dados extraídos pelo processo Extract e săo enviados para o servidor destino, sendo recebidos e utilizados pelo processo Replicat. Eles existirăo tanto no servidor origem quanto no destino;
- Checkpoints: além dos mecanismos internos de Checkpoint dos bancos de dados origem e destino, utilizados para manter a integridade de suas transaçőes, o GoldenGate possui seu próprio registro de Checkpoint para controle do que já foi aplicado no servidor destino e qual sua ordem de aplicaçăo; ...







