Esse tema é útil em situaçőes onde se tem uma grande
quantidade de dados que precisam ser armazenados de forma distribuída, sendo
necessário extrair, manipular ou carregar parte dessas informaçőes de forma
rápida e confiável, podendo fazę-lo de forma simples através de um mecanismo de
pesquisa baseado em SQL.
Vemos uma quantidade cada vez maior de informaçăo sendo gerada, seja através do avanço das mídias sociais e serviços de internet, de uma crescente demanda por conteúdos cada vez mais diversificados ou ainda por pesquisas e exploraçőes feitas no ramo da cięncia.
O fato é que, dependendo do tipo da necessidade envolvida, se faz necessário o armazenamento de uma quantidade de informaçăo tăo grande e complexa, da ordem de muitos terabytes, que se torna inviável tentar manipulá-la com ferramentas tradicionais.
Esse grande conjunto de dados, conhecido como "big data", e a dificuldade em lidar com essas informaçőes acontece, em vários casos, năo só pelo volume de dados armazenados, mas também por outros critérios como a velocidade com que esses dados chegam para serem armazenados, o tempo no qual eles devem ser processados, além dos tipos de dados que devem ser tratados e armazenados, sejam eles logs de aplicaçăo, imagens, áudios, vídeos etc.
Um grande problema quando se fala em big data se refere a como esses dados serăo manipulados de forma eficaz. Como serăo feitos a captura, o armazenamento, o processamento, a análise e apresentaçăo dos dados?
Uma forma de se resolver parte desse problema é através de processamento paralelo, onde os dados săo divididos em porçőes menores e distribuídos para serem processados. Para algo do tipo, é necessária uma plataforma robusta e escalável, com várias máquinas, para se conseguir realizar a tarefa.
Isso sem contar a necessidade da replicaçăo dos dados para se evitar rupturas e perdas de informaçăo.
Ainda é necessário que as informaçőes sejam processadas de forma independente (em cada máquina em separado) ou, caso contrário, pode haver um gargalo na rede e consequentemente um comprometimento de toda a plataforma.
Depois das informaçőes processadas e armazenadas, precisaremos analisar e apresentar esses dados de forma eficiente.
Nesse cenário complexo, temos algumas ferramentas que podem nos auxiliar. É o caso do conjunto de ferramentas da Apache relacionado ao big data que formam o ecossistema do Hadoop.
O Hadoop, por sua vez, é um software open source desenvolvido para armazenamento e processamento de uma grande quantidade de dados de forma distribuída.
Arquitetura do Hadoop
O Hadoop utiliza um sistema de arquivos distribuído, conhecido como HDFS (Hadoop Distributed File System), que foi inspirado no sistema de arquivos do Google (Google file system).
O HDFS tem muitas semelhanças com outros sistemas distribuídos, no entanto apresenta características próprias como, por exemplo, ser tolerante a falhas e projetado para hardwares de baixo custo, além de possuir alta disponibilidade de acesso e ser perfeito para aplicaçőes com um grande conjunto de dados.
O Hadoop divide os arquivos em grandes blocos de memória (64MB ou 128MB) e distribui os blocos entre os nós do cluster. Para processar os dados recebidos, o Hadoop os processa remotamente através de cada nó.
O HDFS possui dois tipos de nós: master, conhecido também como namenode, e os workers, ou datanodes. O master armazena as informaçőes da distribuiçăo de arquivos e metadados. Já os workers armazenam os dados propriamente ditos.
Essa técnica permite que os dados sejam processados de forma mais rápida e eficiente, por ser distribuída, do que outras formas como, por exemplo, um processamento local das informaçőes.
O framework do Hadoop é composto pelos seguintes módulos (Figura 1):
· Hadoop Common - libs e utilitários necessários aos outros módulos do Hadoop;
· Hadoop Distributed File System (HDFS) - sistema de arquivos distribuídos;
· Hadoop MapReduce - processador de dados em larga escala
· Hadoop YARN - gerenciador de recursos e processador das tarefas de MapReduce.
O MapReduce é um modelo computacional que decompőe jobs (tarefas) de manipulaçăo de uma grande quantidade de dados em tarefas individuais (aqui chamadas de tasks) para serem executadas em paralelo através de um cluster de servidores.
O modelo de MapReduce foi desenvolvido pelo Google. Ele está associado a duas operaçőes fundamentais de transformaçăo de dados, map e reduce. A operaçăo de map converte elementos de uma coleçăo de uma forma para outra. Nesse caso, uma entrada de pares “chave-valor” é convertida para uma coleçăo “zero para muitos”, aonde vários valores com a mesma chave săo agregados.
Numa operaçăo de MapReduce, todos os pares săo enviados para uma mesma operaçăo de reduce. Ou seja, a chave e a coleçăo de valores associados ŕquela chave săo passados para uma mesma operaçăo. A operaçăo de reduce converte a coleçăo para um valor como a soma, ou a média de valores da coleçăo, gerando um par “chave-valor” final.
A partir da versăo 2.x, o Hadoop passou a utilizar um novo componente como gerenciador de recursos e processador das tarefas de MapReduce, conhecido como MapReduce 2.0 (MRv2) ou YARN. A ideia por trás do YARN é separar os processos das duas maiores funcionalidades do JobTracker: o gerenciador de recursos e o agendador de tarefas.
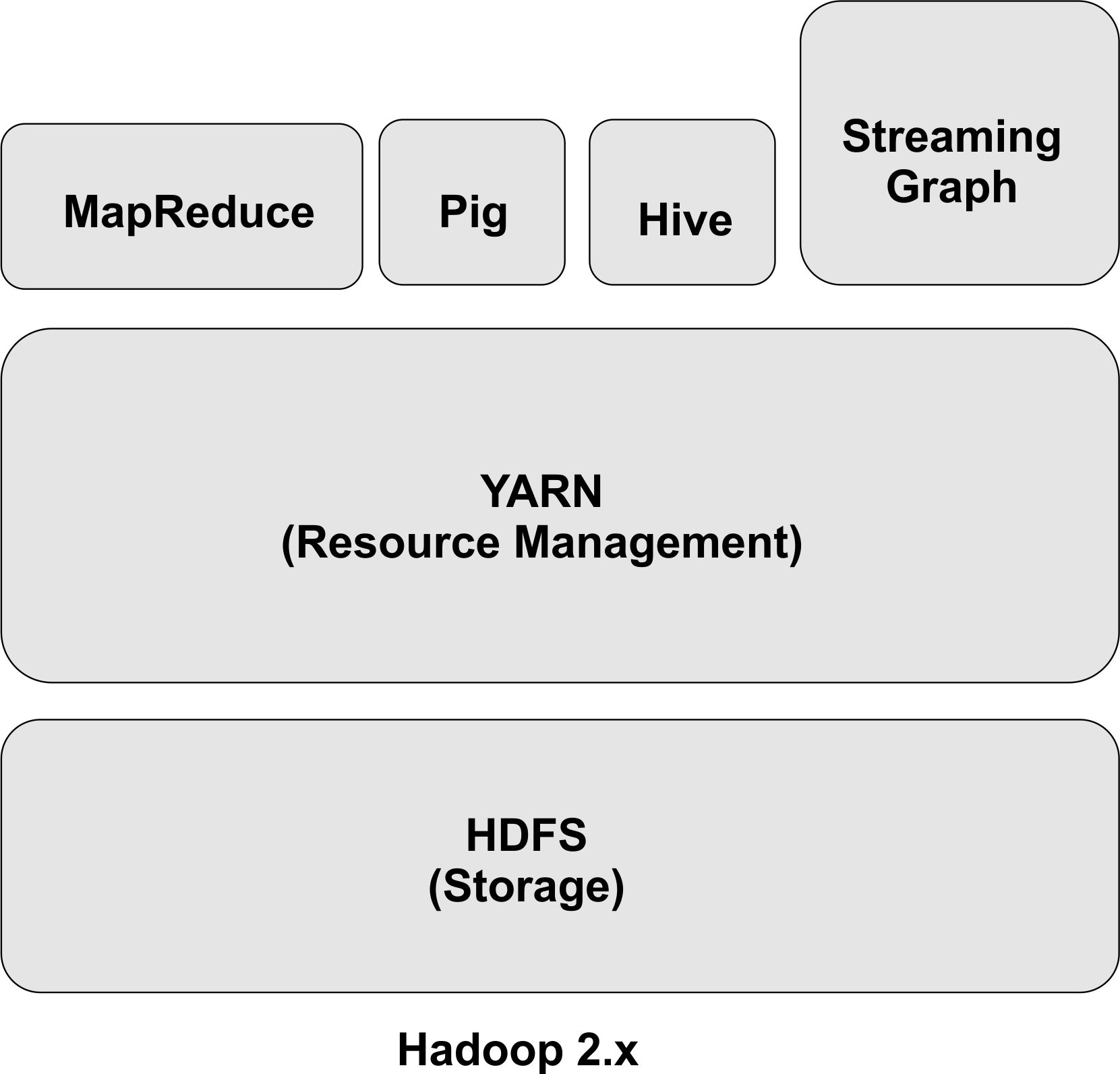
Figura 1. Arquitetura macro do hadoop
Necessidade de uma camada de abstraçăo
- Apache Hiv ...







