Os backups realizam o controle do tamanho dos logs de transaçăo e asseguram que, em casos de desastres, seremos capazes de restaurar o banco de dados para algum ponto salvo antes da ocorręncia do desastre. Esses backups de log de transaçőes serăo realizados lado a lado com o backup do banco de dados completo (arquivo de dados). Já em casos que năo haja a necessidade desses backups ou estejamos trabalhando com sistemas de testes, onde năo precisamos realizar restauraçőes a pontos antos anteriores ou mesmo resolvermos nossos problemas apenas com o último backup completo do banco de dados, entăo este é o caso de operarmos com banco de dados em modo simples de backup. A partir deste momento trataremos a relaçăo a alguns dos principais pontos referentes a recuperaçőes e aos backups.
A importância dos backups de nossos bancos de dados
A partir deste momento passemos a considerar, por exemplo, a situaçăo em que ocorre uma quebra (“uma falha”) do banco de dados SQL Server, onde, talvez devido a uma falha de hardware, os arquivos de dados correntes (MDF e arquivos de FDN), assim como os arquivos de log de transaçőes (o arquivo LDF), passam a năo ser mais acessíveis.
Considerando esta situaçăo, no pior dos cenários possíveis, se năo houverem backups desses arquivos existentes em outros lugares (de preferęncia lugares diferentes), entăo iremos sofrer 100% de perda dos dados. Para garantirmos a possibilidade de recuperarmos o banco de dados e restaurarmos os dados dele de igual forma ao que era antes da quebra ou bem próximo a isso, nós como DBA’s precisamos fazer backups regulares de tanto dos dados quanto dos arquivos de log. Com base nisso, podemos afirmar que existem tręs tipos principais de backup que podemos realizar, vejamos a seguir entăo com relaçăo a eles:
- Backups completos – neste caso, fazemos backup de todos os dados no banco de dados. Neste momento fazemos uma cópia dos arquivos MDF para um determinado banco de dados.
- Backups de banco de dados diferencial – neste caso fazemos uma cópia de todos os dados que foram alterados desde o último backup completo.
- Backups do log de transaçőes – neste caso, fazemos uma cópia de todos os registros de log inseridos no log de transaçőes desde o backup do último log de transaçăo (ou de um ponto de verificaçăo do banco de dados, se estiver trabalhando em modo de recuperaçăo simples). Quando um backup do log é feito, o log geralmente fica truncado para que o espaço no arquivo possa ser reutilizado, embora alguns fatores possam atrasar esta operaçăo.
Quando nos referimos ao termo “completo”, imaginamos que este tipo de backup realiza o backup total (de tudo, tanto dos dados como do conteúdo dos logs de transaçăo). Năo é bem isso que acontece. Tanto os backups completos (FULL) como o diferencial, só fazem backup dos dados, embora eles também façam backups suficientes do log de transaçőes para permitir a recuperaçăo dos dados de backup, e daí, reproduzir as alteraçőes feitas enquanto o backup estava em andamento. No entanto, em termos práticos, um backup completo năo realiza backup do log de transaçőes, e por isso năo resulta em truncamento do log de transaçőes. Apenas um backup da transaçăo de log pode resultar em truncamento do log, e dessa forma, realizar o backup do log é a única maneira correta de controle com relaçăo ao tamanho dos arquivos de log em sistemas de produçăo.
Muitas vezes é possível em bancos de dados grandes que săo organizados em vários grupos de arquivos, realizarmos backups completos e diferenciais em grupos de arquivos individuais ou mesmo em arquivos que se encontram nesses grupos de arquivos, sem a necessidade de buscar em todo o banco de dados. A seguir apresentaremos os modelos de recuperaçăo que săo mais utilizados.
Modelos de recuperaçăo de bancos de dados
As operaçőes de backup e recuperaçăo de um banco de dados SQL Serverocorrem dentro do contexto do modelo de recuperaçăo do banco de dados existente. Um modelo de recuperaçăo é uma propriedade do banco de dados que determina a necessidade ou năo de precisarmos (ou mesmo se será possível) fazer backup do log de transaçőes e como as operaçőes serăo registradas. Há também algumas diferenças com relaçăo ŕs operaçőes de restauraçăo que estăo disponíveis. Em operaçőes gerais, um banco de dados estará operando em modo de recuperaçăo simples ou FULL e as distinçőes mais importantes entre os dois săo as que apresentamos a seguir:
- SIMPLES – neste modelo, o log de transaçőes é utilizado apenas para a recuperaçăo do banco de dados e para as operaçőes de reversăo (rollback). Ele é automaticamente truncado durante os checkpoints periódicos. Ele năo pode ser restaurado e devido a esse fator, ele năo pode ser usado para restaurar o banco de dados para um estado existente em algum momento no passado.
- FULL (Completo) – neste modelo, as operaçőes de log năo săo truncadas automaticamente durante os checkpoints periódicos e devido a isso, eles podem ser copiados e usados para a restauraçăo dos dados para um ponto anterior no tempo, bem como para a recuperaçăo do banco de dados e rollbacks. Neste ponto o arquivo de log só será truncado quando ocorrer backups de log.
Além desses dois modelos que săo mais utilizados, temos também um terceiro modelo, que é p BULK_LOGGED, no qual determinadas operaçőes que normalmente geram uma grande quantidade de escrita para o log de transaçőes executarmos menos registros a fim de năo sobrecarregarmos o log de transaçőes. Alguns exemplos de operaçőes que podem ser registradas que incluem importaçăo em massa săo as operaçőes de SELECT/INTO e algumas operaçőes de índices, assim como índices de recriaçăo (rebuild).
De maneira geral, um banco de dados em execuçăo no modo de recuperaçăo FULL pode ser temporariamente alterado para o modo BULK_LOGGED, a fim de essas operaçőes sejam executadas com uma quantidade mínima de registros, em seguida, podemos voltar para o modelo FULL novamente. No caso de querermos realizar operaçőes permanentemente utilizando o modelo BULK_LOGGED năo seria um caminho viável para minimizarmos o tamanho dos logs de transaçăo. Discutiremos isso com mais detalhes em Gerenciando o log no modelo de recuperaçăo BULK_LOGGED.
Como saber o modelo de recuperaçăo correto?
É quase que impossível numa operaçăo de backup um arquivo ou outro ser perdido no processo. Mas com relaçăo a escolha do modo de backup, se será utilizando o modo de recuperaçăo completa ou no modo simples, é importante que definamos o seguinte: qual a quantidade de dados que estamos dispostos a perder??
Vejamos pelo seguinte ângulo, com o modo de recuperaçăo simples, os backups completos (FULL) e diferenciais săo possíveis. Vamos entăo exemplificar um pouco esse ponto. Digamos que nós confiamos única e exclusivamente em backups completos, desta forma, realizamos todas as manhăs ŕs 3:00 um backup, e o servidor sofre um acidente crítico ŕs 2:00 da manhă. Neste caso, seríamos capazes de restaurar o backup do banco de dados completo que foi realizado ŕs 3:00 da manhă anterior e teríamos perdido todos os outros registros no decorrer das últimas horas antes do incidente.
Contudo, é
possível executarmos backups diferenciais
entre os backups completos, para a reduçăo da quantidade de dados que possam estar em
risco, em caso de falhas graves de sistema. Todos os backups săo
processos intensivos de I/O (entrada/saída), mas isso é bem verdade para o modelo de backup
FULL, e em menor medida diferencial. Neste caso, eles săo bem suscetíveis a afetar o
desempenho dos bancos de dados, e devido
a isso, năo devem ser executados durante
períodos em que os usuários estejam acessando o banco de dados. Em termos práticos, caso
estejamos trabalhando em modo de recuperaçăo simples, a sua
exposiçăo ao risco de perda de
dados vai ser da ordem de várias horas.
quando temos um banco de dados que contenha dados críticos de
negócio de uma empresa e se nesse caso, preferirmos medir a “perda” de dados em
minutos ao invés de ser em horas. Com certeza, a opçăo que devemos escolher é
com relaçăo a utilizaçăo do modo de backup FULL. Neste
modo teremos que fazer um backup do
banco de dados FULL, seguido por
uma série de backups do log de transaçőes frequentes, e tendo outro
backup FULL, e assim por diante, criando um ciclo de
transaçőes a serem realizada.
Com essa opçăo, podemos em teoria, restaurar o backup mais recente, válido e completo (em conjunto com o backup diferencial mais recente, se tivermos), seguido pela cadeia de backups de arquivos de log disponíveis, desde o último backup completo ou mesmo diferencial. Entăo, durante o processo de recuperaçăo, todas as açőes registradas nos arquivos de log do backup serăo lançados e comitados, a fim de restaurarmos o banco de dados para um ponto, o mais próximo do momento do desastre.
Como abordado anteriormente, a questăo principal aqui é com relaçăo a quantidade de dados que estamos dispostos a perder ou mesmo a carga de trabalho que ocorrerá nos servidores, para que a partir disso, tenhamos noçăo do tipo de backup que devemos utilizar. Em aplicaçőes financeiras, por exemplo, a tolerância ŕ perda de dados tende a zero, entăo nesse tipo de caso, devemos realizar backups de log a cada 10 minutos talvez, ou com uma maior frequęncia. No nosso exemplo anterior, isto significa que podemos restaurar o backup completo das 03:00 e depois aplicarmos cada um dos arquivos de log existentes, em seguida, supondo que tenhamos uma cadeia de log completa que se estenda desde o backup completo que estamos usando como base para a restauraçăo do banco de dados até a tomada realizada ŕs 02:45, ou seja, 15 minutos antes do acidente. Na verdade, se o registro atual ainda estiver acessível após o acidente, o que nos permitiria realizarmos um backup do log, poderíamos ser capazes de minimizar a perda de dados para bem próximo de zero. Claro que, com a recuperaçăo completa vem um custo de manutençăo muito maior, em termos de esforço extra de criaçăo e monitoramento dos trabalhos necessários para executarmos os backups do log de transaçőes com mais frequęncia, os recursos de I/O que os backups exigem, mesmo que por um período curto de tempo, e o espaço em disco necessário para armazenagem de um grande número de arquivos de backup. Com base nisso, as devidas consideraçőes devem ser tomadas, a nível empresarial, antes mesmo de escolhermos o modo de recuperaçăo apropriado para um determinado banco de dados.
Agora que definimos esse ponto, vejamos entăo como podemos definir e alternar entre os modelos de recuperaçăo. Estaremos apresentando essa definiçăo de acordo com a Listagem 1. Estaremos usando a nossa base de dados criada no artigo anterior com algumas modificaçőes necessárias neste nosso exemplo.
Listagem 1. Definiçăo e alternância entre os modelos de recuperaçăo.
USE master;
-- setando o modelo de recuperaçăo para FULL (completo)
ALTER DATABASE TestDB
SET RECOVERY FULL;
-- setando o modelo de recuperaçăo para SIMPLE(simples)
ALTER DATABASE TestDB
SET RECOVERY SIMPLE;
-- setando o modelo de recuperaçăo para BULK_LOGGED
ALTER DATABASE TestDB
SET RECOVERY BULK_LOGGED;Quando criamos uma base de dados, esta assume o padrăo de recuperaçăo especificado no modelo para o banco de dados. Normalmente, este modelo de recuperaçăo default é o FULL, mas em diferentes ediçőes do SQL Server este padrăo pode diferente. Com base nisso, podemos descobrir o modelo de recuperaçăo de um determinado usando o script presente na Listagem 2.
Listagem 2. Script para saber o modelo de recuperaçăo adotado.
SELECT name ,
recovery_model_desc
FROM sys.databases
WHERE name = 'TestDB' ;
GOAgora que temos as informaçőes necessárias, vamos criar um novo banco de dados e, em seguida, executaremos o comando que apresentamos através da Listagem 2. No entanto, na verdade, até que um backup FULL seja feito, o banco de dados estará operando no modo de auto-truncado (ou seja, no modo SIMPLE). Estamos utilizando o SQL SERVER 2014 para a realizaçăo de nossos testes e modificaremos o script para popular a tabela, o qual já utilizamos no artigo anterior, para adicionarmos as linhas de código que se encarregarăo de verificar o nosso modo de recuperaçăo, como apresentado pela Listagem 3.
Listagem 3. Criando tabela com registros e verificando o modelo de recuperaçăo utilizado.
/* Passo 1: Criando o banco de dados*/
USE master ;
IF EXISTS ( SELECT name
FROM sys.databases
WHERE name = 'TestDB' )
DROP DATABASE TestDB ;
CREATE DATABASE TestDB ON
(
NAME = TestDB_dat,
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\TestDB.mdf'
) LOG ON
(
NAME = TestDB_log,
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\TestDB.ldf'
) ;
/*Passo 2: Inserindo 500 mil registros */
USE TestDB ;
GO
IF OBJECT_ID('dbo.LogTeste', 'U') IS NOT NULL
DROP TABLE dbo.LogTeste;
-- "ID" possui um range def 1 até 500000 de numeros unicos
-- "Inteiros" possui um range def 1 até 50000 de numeros năo unicos
-- "texto";"AA"-"ZZ" string de 2 caracteres
-- "dinheiro"; 0.0000 to 99.9999 valores monetários
-- "Date" ; >=01/01/2000 and <01/01/2010 datas.
SELECT TOP 500000
ID = IDENTITY( INT,1,1 ),
Inteiros = ABS(CHECKSUM(NEWID())) % 50000 + 1 ,
texto = CHAR(ABS(CHECKSUM(NEWID())) % 26 + 65)
+ CHAR(ABS(CHECKSUM(NEWID())) % 26 + 65) ,
dinheiro = CAST(ABS(CHECKSUM(NEWID())) % 10000 / 100.0 AS MONEY) ,
Date = CAST(RAND(CHECKSUM(NEWID())) * 3653.0 + 36524.0 AS DATETIME)
INTO dbo.LogTeste
FROM sys.all_columns ac1
CROSS JOIN sys.all_columns ac2 ;
-- DBCC SQLPERF(LOGSPACE);
SELECT name ,
recovery_model_desc
FROM sys.databases
WHERE name = 'TestDB' ;
GOComo podemos perceber, de acordo com a Figura 1, estamos com o modo de recuperaçăo FULL. Vejamos agora como está o espaço utilizado pelos registros, forçar um checkpoint e em seguida, verificarmos novamente o uso dos registros. Estaremos vendo isso de acordo com o script presente na Listagem 4.
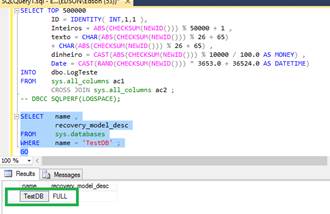
Figura 1. Visualizaçăo do modelo de recuperaçăo.
Listagem 4. Verificaçăo do espaço em uso pelos registros.
DBCC SQLPERF(LOGSPACE);
-- DBCC SQLPERF arquivo de log com cerca de 90% completo
CHECKPOINT
GO
DBCC SQLPERF(LOGSPACE);
-- DBCC SQLPERF arquivo de log com aproximadamente 6% completo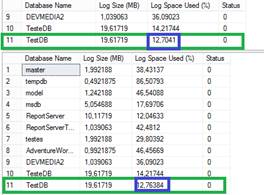
Figura 2. Visualizaçăo do tamanho do registro em uso.
Podemos notar aqui que o arquivo de log é aproximadamente do mesmo tamanho, mas está apresentando agora apenas 6% completo, como mostra a Figura 2. O que vemos aqui é que o log foi truncado e o espaço foi disponibilizado para reutilizaçăo. Embora o banco de dados esteja como modo de recuperaçăo completa, ele năo opera na realidade nesse modo até que o primeiro backup completo seja realizado.
Para que possamos ter certeza do modelo de recuperaçăo em uso no momento, executaremos a consulta que estamos apresentando de acordo com a Listagem 5.
Listagem 5. Verificaçăo do real modelo em uso.
SELECT db_name(database_id) AS 'DatabaseName' ,
last_log_backup_lsn
FROM master.sys.database_recovery_status
WHERE database_id = db_id('TestDB') ;
GOAo executarmos este script, vemos no resultado que o último backup realizado aparece como NULL na coluna last_log_backup_lsn, isto quer dizer que na verdade, o banco de dados está atuando no modo auto-truncado, e dessa forma, ele será truncado quando ocorrerem os checkpoints do banco de dados. Ao realizarmos um backup completo, teremos esta coluna preenchida com a informaçăo do registro de log que registrou a operaçăo de backup, e neste momento o banco de dados estará verdadeiramente em modo de recuperaçăo FULL. A partir deste momento, um backup completo do banco de dados năo terá nenhum efeito sobre o log de transaçőes. A única maneira de truncar o log será fazendo seu backup.
Se vocę nunca mudar um banco de dados de modo registrado completo ou em massa para o modo simples, isso vai quebrar a cadeia de log e vocę só vai ser capaz de recuperar o banco de dados até o ponto do último backup do log tomada antes de trocar. Por isso, é recomendado que tome esse backup log imediatamente antes de mudar. Se vocę mudar posteriormente o banco de dados de volta do simples para o modo completo ou em massa registradas, lembre-se que o banco de dados vai realmente continuar operando no modo auto-truncate até executar outro backup completo.
Se alternarmos o modo FULL para o modo BULK_LOGGED, isso năo irá quebrar a cadeia de logs, no entanto, quaisquer operaçőes em massa que forem realizadas enquanto em modo BULK_LOGGED năo serăo totalmente registrados no log de transaçőes e, portanto, năo poderăo ser controlados em uma base de operaçőes, da mesma forma que as operaçőes que estăo totalmente conectadas. Isso nos mostra apenas que uma recuperaçăo de um banco de dados para um determinado checkpoint dentro de uma log de transaçăo que contenha operaçőes em massa năo será possível, o que podemos fazer é recuperar o arquivo de log até o fim.
Bancos de dados Ad-hoc e backups de log de transaçőes podem ser realizados através de scripts de T-SQL simples, através do SQL Server Management Studio. No entanto, para sistemas que estejam em ambiente de produçăo, precisaríamos de uma maneira para automatizarmos esses backups, e verificarmos se os backups săo válidos, e se podem ser utilizados para a restauraçăo dos dados. Dentre as opçőes disponíveis, podemos citar duas que săo bastante eficazes para essa questăo, que săo:
- Utilizaçăo de Scripts T-SQL – podemos escrever os scripts T-SQL personalizados para automatizarmos nossas tarefas de backup, onde, se tivermos um conjunto de scripts de manutençăo, como por exemplo, o que é fornecido pela Ola Hallengren , que é um script bem estabelecido e respeitado. Seus roteiros criam uma variedade de stored procedures, onde cada uma executa uma tarefa específica de manutençăo de banco de dados, incluindo backups e automatixaçăo usando SQL Agents.
- Powershell/SMO scripting – este é ainda mais poderoso e versátil do que scripts T-SQL, mas com uma curva de aprendizado para muitos profissionais na área de banco de dados, o PowerShell pode ser utilizado automatizar praticamente qualquer tarefa de manutençăo.
Além dessas que citamos acima, existem várias ferramentas de terceiros que podem automatizar backups, bem como verificar e monitorar suas operaçőes. Alguns desses exemplos que podemos citar săo o Red Gate SQL, o LiteSpeed da Quest, dentre outros tantos.
Até a próxima!







