Estamos iniciando agora uma série de artigos que irăo nos dar uma introduçăo passo-a-passo de como criar um banco de dados utilizando o Oracle 9i. Iremos iniciar com a criaçăo de scripts, analisando os parâmetros e, posteriormente, finalizar com a implementaçăo de um pequeno sistema, criando as tabelas e suas restriçőes. Espero que essa leitura lhe seja agradável e principalmente útil para o seu dia-a-dia.
Criando um banco de dados Oracle
A criaçăo de um banco de dados Oracle necessita de tręs operaçőes básicas:
- Criaçăo das informaçőes sobre a estrutura do BD, informaçőes essas que ficam armazenadas no dicionário de dados;
- Criaçăo e inicializaçăo do arquivo de controle (Control File) e dos arquivos de reconstruçăo do banco (Redo Log Files), para que se possa colocar o BD no ar;
- Criaçăo dos arquivos de dados (Data Files), ou seja, os locais onde os dados gravados no BD serăo efetivamente armazenados.
A instruçăo usada para a criaçăo do BD é CREATE DATABASE. O banco de dados pode ser criado através de dois caminhos:
- Utilizando-se o Database Configuration Assistant (DBCA), que é um assistente gráfico;
- Criaçăo manual do BD através de um script.
Utilizaremos uma mescla dos dois métodos citados – primeiro, vamos manipular o DBCA, que irá gerar um script de criaçăo do BD. Com o script em măos, poderemos analisá-lo e efetuar as alteraçőes necessárias.
O Database Configuration Assistant (DBCA) permite criar um BD Oracle, configurar opçőes para um BD existente, excluir um BD e gerenciar gabaritos (templates) de BD.
Podemos utilizar o DBCA de tręs modos: Interativo (Interactive - minha escolha), que é o padrăo; Somente Progresso (Progress Only) que é um modo tipicamente usado por outras ferramentas como o Oracle Universal Installer, o Enterprise Manager Configuration Assistant entre outros; e finalmente o modo Silencioso (Silent), onde temos apenas a linha de comando onde săo especificados os parâmetros.
Criando um BD utilizando o DBCA
Inicie o DBCA, através do menu “Iniciar” do Windows em “Configuration and Migration Tools” (ou digite dbca na linha de comando UNIX). Na tela de boas-vindas, clique em “Próximo” para iniciarmos a criaçăo do BD. Esse processo será executado através de 08 etapas, que descreveremos a seguir.
Operaçőes
Neste passo, escolhemos o tipo de operaçăo que desejamos executar. Existem 04 opçőes (Figura 1).
- Criar um banco de dados.
- Configurar opçőes em um banco de dados. Utilize esta opçăo caso o BD já tenha sido criado e exista a necessidade de ajustar os parâmetros do mesmo;
- Deletar um banco de dados.
- Gerenciar Gabaritos (Templates). Esta opçăo é interessante quando existe uma necessidade constante de se criar BDs. Um exemplo é o caso dos consultores, que estăo em vários clientes efetuando esta operaçăo. A partir do gabarito criado, basta configurar alguns parâmetros de acordo com a realidade de cada cliente e o processo pode ser concluído.

Selecione a primeira opçăo e clique em 'próximo'.
Gabaritos de banco de dados
Existem gabaritos pré-definidos pela própria Oracle para auxiliar o processo de criaçăo do BD (Figura 2).

Selecione a opçăo 'New Database' e clique em 'próximo'.
Identificaçăo do banco de dados
Temos que definir dois parâmetros fundamentais que săo os responsáveis pela identificaçăo do BD:
- Nome do banco de dados global (Global Database Name): é o nome pelo qual o BD será exclusivamente identificado, inclusive em uma rede, utilizando o formato “nome.domínio”;
- SID (Oracle System Identifier), nome que identifica a instância, ou estrutura em memória criada pelo Oracle para interagir com o BD.
Um mesmo BD Oracle pode possuir várias instâncias interagindo com a mesma estrutura de armazenamento. É o caso de uma configuraçăo em Cluster (ver Nota 1), onde uma única estrutura em disco interage com várias estruturas em memória, uma em cada nó do cluster, porém cada instância terá seu SID exclusivo (Figura 3.

Recursos do banco de dados
Somente nos é apresentada caso escolhamos o gabarito New Database (2ş Etapa), pois ele nos permite adicionar recursos opcionais ao nosso BD como:
- Oracle Spatial: um SGBD estendido para gerenciar dados espaciais. Bastante utilizado em aplicaçőes como geoprocessamento;
- Oracle Ultra Search: fornece um recurso de pesquisa na Web, reúne e indexa todos os documentos, incluindo sites, bancos de dados, arquivos, listas de mala direta, portais e várias fontes definidas pelo usuário;
- Oracle Data Mining: possibilita o desenvolvimento de aplicaçőes de business intelligence;
- Oracle OLAP: fornece um conjunto completo de funçőes analíticas, bastante difundidas na utilizaçăo em data warehouse no auxílio ŕ tomada de decisőes;
- Example Schemas: um pequeno banco de dados de exemplo;
E nos recursos padrăo temos:
- Oracle JVM: máquina virtual JAVA (Java Virtual Machine), que permitirá a aplicaçăo de muitas funcionalidades em JAVA;
- Oracle Intermedia: adiciona suporte multimídia que permite que o Oracle9i gerencie textos, documentos, imagens, áudio, vídeo, etc;
- Oracle Text: utiliza o padrăo SQL para indexar, procurar e analisar textos e documentos armazenados no BD, em arquivos ou na Web;
- Oracle XML DB: é uma característica do BD que permite uma alta performance na utilizaçăo do modelo de dados XML.
Nesse artigo năo utilizaremos nenhum recurso adicional por serem específicos a cada necessidade. Assim, retire qualquer seleçăo existente em qualquer item, inclusive os itens presentes em “Recursos-padrăo de banco de dados”, e clique em “Próximo”. (Figura 4).

Opçőes de conexăo de banco de dados
O Oracle oferece duas opçőes de como as seçőes se conectarăo ao BD (Figura 5): Servidor Dedicado (Dedicated Server) ou Servidor Compartilhado (Shared Server).
No primeiro, será colocado no ar um serviço exclusivo ŕ conexăo (Server Process), ou seja, cada usuário conectado ao BD terá um serviço ŕ sua disposiçăo. Assim, mesmo que năo haja nenhuma requisiçăo, o serviço estará disponível apenas ao usuário e no momento das requisiçőes ao BD năo haverá concorręncia. Já no servidor compartilhado, um mesmo processo atenderá a várias conexőes, ou seja, vários usuários conectados utilizarăo o mesmo serviço no BD. Com isso, as requisiçőes desses usuários terăo que aguardar em uma fila de execuçăo até que sua requisiçăo seja atendida. Esses serviços compartilhados a vários usuários săo os chamados “despachantes” (dispatchers) e é possível configurar vários despachantes para atender a um número limitado de usuários. É óbvio que um servidor compartilhado compromete a performance do sistema. Por esse motivo é muito importante identificar a real necessidade da conexăo em ser dedicada ou compartilhada. Em um sistema com poucos usuários e com transaçőes muito intensas, é interessante configurar o BD para o modo Servidor Dedicado, ganhando performance. Já um caso em que haja um número elevado de usuários, porém sem um taxa elevada de transaçőes, deve-se utilizar o modo Servidor Compartilhado para que năo se corra o risco de uma sobrecarga de conexőes no BD. O Oracle possibilita ainda uma configuraçăo heterogęnea, em que algumas conexőes estarăo em modo dedicado e outras (as que requisitam pouco o sistema) em modo compartilhado. Seria o caso, por exemplo, de um período de fechamento de folha de pagamento, em que a quantidade de transaçőes efetuadas por aqueles usuários é intensa e eles năo podem ficar aguardando em fila de espera. Neste caso, configura-se os usuários deste departamento em modo Servidor Dedicado enquanto o restante da empresa compartilha os serviços no modo Servidor Compartilhado.
No nosso caso, utilizaremos o modo Servidor Dedicado, pois se presume que o leitor esteja acompanhando para efetuar estudos em uma máquina Stand Alone onde năo é necessária a utilizaçăo do modo Servidor Compartilhado.

Parâmetros de inicializaçăo
Nesta etapa é essencial o conhecimento do modelo de dados, modelo do negócio e recursos de hardware, pois os parâmetros de inicializaçăo serăo definidos tomando por base a suposiçăo de como o BD irá se comportar. A medida em que o BD trabalha em ambiente de produçăo é que serăo feitos os ajustes finos.
É a partir desta etapa que começamos a configurar os parâmetros que serăo adotados pelo BD em sua inicializaçăo. Os parâmetros de inicializaçăo săo os responsáveis pela alocaçăo das várias áreas de memória para a instância, conjuntos de caracteres, dimensionamento de blocos, localizaçăo dos arquivos de parâmetro e rastreamento e arquivamento dos logs.
Configuraçăo de memória
Define qual será o tamanho da SGA (System Global Área – Área Global do Sistema). Está será a responsável direta pela interaçăo das aplicaçőes com o BD (Figura 6).
Na opçăo “Típico”, define-se apenas a porcentagem que o Oracle alocará em relaçăo ao total de memória física disponível. A distribuiçăo entre as várias áreas será definida pelo próprio Oracle.
Já a opçăo “Personalizado” permite um controle total sobre as áreas de memória utilizadas. Porém năo podemos esquecer de que o total de memória física disponível deve possuir uma porçăo reservada ao sistema operacional e aplicativos existentes. Nossa opçăo será esta e consideremos que está sendo utilizada uma estaçăo de testes Pentium 4 com 256 Mb de memória RAM. As opçőes possíveis de serem configuradas aqui săo:
- Shared Poll: é uma parte da SGA composta por duas subáreas principais: a Library Cache, responsável pelo armazenamento das instruçőes SQL e PL/SQL para utilizaçőes futuras sem a necessidade de leitura em disco; Dictionary Cache, onde săo armazenadas as instruçőes SQL que consultam o dicionário de dados. Em nosso exemplo utilizaremos 56 Mb para diminuir a necessidade de uma nova compilaçăo de instruçăo. Este procedimento aumenta a performance do BD.
- Buffer Cache: é a área da SGA que armazena uma cópia dos blocos de dados lidos em disco. Numa próxima requisiçăo da mesma informaçăo, năo será mais necessário o acesso a disco, obtendo um ganho de performance na consulta. Configuraremos com 24 Mb.
- Java Pool: nesta área săo armazenadas as instruçőes em Java que săo requisitadas ao BD para posterior reutilizaçăo. Caso o BD năo tenha interface com aplicaçőes em Java deve-se manter esse valor em zero.
- Large Pool: área opcional da SGA que será utilizada em aplicaçőes específicas. Por esse motivo, deixaremos este valor em zero.
- PGA (Program Global Área): regiăo da memória que contém informaçőes de dados e controle do processo servidor. É uma memória năo compartilhada que é criada pelo Oracle somente quando um processo servidor é iniciado, ou seja, quando uma conexăo de usuário é estabelecida. Nossa configuraçăo ficará com 24 Mb.

Conjunto de caracteres
A opçăo padrăo (default) utilizará o conjunto de caracteres definido no sistema operacional do computador em que está sendo instalado o BD. Entretanto, é importante conhecer qual o conjunto de caracteres que a aplicaçăo enviará ao BD para năo termos surpresas. No nosso caso utilizaremos o padrăo (Figura 7).

Dimensionamento dos blocos
O Oracle gerencia o espaço de armazenamento nos arquivos de dados (Data Files) em unidades chamadas de blocos de dados (Data Block). Esta é a menor unidade de armazenamento usado pelo BD, em contraponto ao nível físico, nível do sistema operacional em que os dados săo armazenados em bytes. Cada sistema operacional possui seu próprio tamanho de bloco (Block Size), por esse motivo, o Oracle solicita os dados em múltiplos do data block Oracle. Ou seja, independentemente do sistema operacional utilizado, as informaçőes serăo armazenados em unidade de bloco Oracle e năo em unidades de bloco do sistema operacional. Esse procedimento garante uma independęncia do BD em relaçăo ao sistema operacional.
Manteremos o valor sugerido pelo DBCA, pois somente nos casos específicos, em que armazenamos arquivos no BD, imagens, por exemplo, é que iremos utilizar tamanhos de bloco diferenciados (Figura 8).
O Oracle permite que seja criada uma Tablespace com tamanho de bloco diferente do padrăo.
Outro parâmetro que devemos configurar nesta tela é o tamanho de área de classificaçăo (Sort Área Size). Ele é a quantia máxima, em bytes, que é utilizado da PGA para as tarefas de ordenaçăo. Em algumas operaçőes, como importaçăo de um banco de dados, o aumento deste valor fará com que o processo de importaçăo seja mais rápido, considerando que, para cada índice criado, haverá uma ordenaçăo. Já no BD em produçăo, este valor năo necessita ser tăo elevado, pois as ordenaçőes năo săo tăo freqüentes. Por esse motivo, utilizaremos o valor definido pelo próprio DBCA, que já foi calculado considerando o valor configurado para a PGA.

Arquivos de parâmetro e rastreamento
A inicializaçăo do BD utiliza o arquivo de parâmetros de inicializaçăo (pfile – parameter file), também conhecido como init.ora, para a adoçăo dos parâmetros do BD. O pfile é um arquivo texto que pode ser editado através de qualquer editor de texto năo formatado. Caso seja feita alguma alteraçăo neste arquivo após a inicializaçăo do BD, o mesmo deverá ser finalizado (Shutdown) e inicializado (Startup) forçando novamente a utilizaçăo do pfile. Caso o BD năo encontre um pfile, automaticamente será utilizado como parâmetro de inicializaçăo o arquivo de parâmetros de inicializaçăo do servidor (spfile – server parameter file), que é um arquivo binário e utilizado para armazenar as alteraçőes de configuraçăo realizadas dinamicamente. Porém, nem todos os parâmetros podem ser alterados dinamicamente. Para esses casos, deve-se utilizar o pfile. Também é possível recriar um pfile tomando como base o spfile. A opçăo selecionada “Create server parameter file (spfile)” criará o spfile automaticamente após a inicializaçăo do BD.
Cada BD criado possui processos que săo executados em segundo plano, sem a percepçăo dos usuários ou até mesmo do DBA. Quando um processo detecta um erro interno, ele gera uma informaçăo e a armazena em um arquivo de rastreamento (trace file) associado a ele. Essas informaçőes podem auxiliar na abertura de um chamado de suporte técnico junto a Oracle e até mesmo servir como guia para ajustes finos (tuning) na instância ou mesmo em aplicaçőes que interagem com o BD. Deixaremos selecionada a opçăo de criaçăo do spfile e manteremos as opçőes sugeridas pelo DBCA para nomes de arquivo e localizaçăo dos mesmos (Figura 9).

Log de arquivamento (Archived Redo Log)
É possível armazenar os grupos de Redos (que serăo vistos na próxima etapa) que já tenham sido totalmente preenchidos, em um ou mais destinos off-line (Figura 10). Os arquivos gerados por esse armazenamento săo conhecidos como Archived Redo Log ou simplesmente Archive Log. Em outras palavras, pode-se dizer que todas as instruçőes SQL executadas no BD serăo armazenadas em arquivos físicos para uso posterior caso necessário. Essas necessidades podem ser:
- Recuperaçăo do BD (Recover Database);
- Atualizaçăo de um BD em estado de prontidăo (Standby Database);
- Obter informaçőes do histórico do BD através do utilitário LogMiner.
É importante considerar que como os Archive Logs săo arquivos armazenados fisicamente, deverá haver estrutura em disco suficiente para armazenar estes arquivos, caso contrário o BD travará por falta de espaço. Esta estrutura em disco deverá ser multiplicada pelo número de destinos configurados, caso se opte pela redundância de informaçőes por segurança.

Podemos definir também o formato do nome do arquivo gerado através dos parâmetros:
- %T – Número da thread, preenchido por zero ŕ esquerda;
- %t – Número da thread;
- %S – Número seqüencial do log, preenchido por zero ŕ esquerda;
- %s – Número seqüencial do log.
Armazenamento de BD
Aqui, os recursos de armazenamento em disco deverăo estar muito bem definidos para um bom funcionamento do BD, adquirindo performance e mantendo a confiabilidade em casos de danos. É nesse momento que iremos configurar os arquivos de controle (control file), as tablespaces, os arquivos de dados e os grupos de Redo Log.
Arquivo de controle (Control File)
É um arquivo binário necessário para que o BD seja inicializado e operado normalmente. Ele é alterado constantemente durante o funcionamento do BD e deve estar sempre disponível para leitura e escrita enquanto o BD estiver aberto.
Este arquivo contém informaçőes sobre o BD que săo necessárias para que a instância possa acessá-lo, tanto na inicializaçăo quanto em operaçăo normal. Nem os usuários ou DBA tem acesso a modificar o conteúdo do arquivo de controle, é uma tarefa exclusiva do Oracle. Săo armazenados no arquivo de controle informaçőes sobre:
- O nome do BD;
- Nome e localizaçăo dos arquivos de dados e arquivos de Redo on-line;
- Tablespaces;
- Archive Logs;
- Sincronizaçăo entre arquivos de dados e arquivos de Redo.
Uma boa prática é a utilizaçăo de espelhamento, ou seja, mais de um arquivo de controle em unidades de disco diferentes. Năo se trata de cópia, e sim espelhamento, pois cada um dos arquivos de controle é idęntico e mantido com a mesma alteraçăo simultaneamente. Com isso, a eventual perda de um arquivo de controle năo acarretará em parada do BD e dores de cabeça para o DBA.
A Figura 11 mostra a configuraçăo do arquivo de controle, onde precisamos colocar apenas o nome escolhido para o arquivo (cuja extensăo é .ctl) e definir os nomes e localizaçőes dos espelhos. Em nosso caso, é definido o arquivo de controle como ctrl_SQLMAG_01.ctl no diretório base de instalaçăo do Oracle ({ORACLE_BASE}\oradata\{DBNAME}) e os espelhos (no caso, dois) nas unidades “D:” e “E:”.

Tablespaces
Um BD Oracle é dividido em uma ou mais unidades lógicas de armazenamento chamadas de Tablespaces, que agrupa as estruturas lógicas relacionadas (Figura 12).

Cada BD é dividido logicamente em uma ou mais Tablespaces, que por sua vez pode conter um ou mais arquivos de dados (Data Files, que veremos na próxima etapa) para armazenar fisicamente todos os dados criados na estrutura lógica. A capacidade total de armazenamento da Tablespace será a somatória da capacidade de cada arquivo de dados. Conforme a Figura 12, a Tablespace USERS possui uma capacidade de armazenamento de 4 Mb enquanto a Tablespace SYSTEM possui 2 Mb (1 Mb + 1 Mb) de capacidade. A medida que a capacidade de armazenamento da Tablespace vai se esgotando, pode-se adicionar arquivos de dados ŕ mesma, aumentando assim sua capacidade de armazenamento.

A Tablespace SYSTEM é obrigatória, pois nela está contido o dicionário de dados do BD, necessário para sua inicializaçăo. O restante é configurado de acordo com a necessidade, criando-se Tablespace para dados dos usuários e outra exclusiva para índices, por exemplo. O DBCA já define algumas Tablespaces automaticamente, cabe a nós aceitar as sugestőes ou, remover ou adicionar (botăo “Add”) configurando alguns dos parâmetros do arquivo de dados (Figura 13).
A vantagem de configurar Tablespaces diferentes para objetos diferentes é que podemos definir os arquivos de dados em discos separados, eliminando a concorręncia e mantendo a organizaçăo em nosso BD.
Arquivos de dados (Data Files)
Cada arquivo de dados estará associado a uma única Tablespace em um único BD.
O sistema operacional é responsável por alocar e gerenciar fisicamente os arquivos de dados. Caso o arquivo de dados seja muito grande, o processo de gerenciamento do mesmo sofrerá um acréscimo de tempo, comprometendo assim a performance do sistema.
A opçăo “Status” define se o arquivo de dados estará Online ou Offline, ou seja, se o arquivo estará disponível ou năo para ser gravado. Em nosso caso, como estamos criando o BD, utilizaremos a opçăo Online, já no caso de um BD existente, poderíamos colocar o arquivo de dados Offline para poder efetuar um backup, por exemplo.
Na guia “Geral” (Figura 14), configuramos o nome e localizaçăo do arquivo, seu tamanho inicial e se o sistema operacional irá reutilizar o arquivo (sobrescrevendo-o) caso já exista.

Na guia “Armazenamento” (Figura 15), é definido o modo de crescimento do arquivo de dados através do incremento, e definido também se este arquivo de dados terá um tamanho máximo ou se terá um crescimento ilimitado.
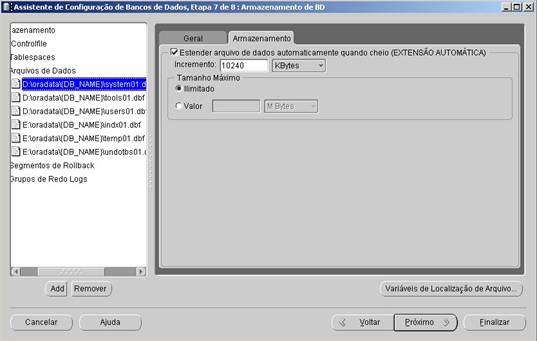
Duas boas práticas na criaçăo/manutençăo do BD săo:
- manter os arquivos de dados com um tamanho máximo de 2GB, o que năo é obrigatório, porém a própria Oracle recomenda, pois alguns sistemas operacionais năo conseguem gerenciar de maneira eficaz os arquivos maiores e também para prover um ganho de performance no acesso a disco. Esta prática tem se mostrado uma constante entre os DBAs;
- armazenar em unidades de disco diferentes os arquivos de dados e de índices, o que também năo é obrigatório, mas eliminará concorręncia de leitura na mesma unidade proporcionando um significativo ganho de performance.
Para isso, basta configurar a localizaçăo de cada arquivo de dados através da guia “Geral”, no campo “Nome”.
Em nosso exemplo, convencionou-se que as tabelas serăo criadas na tablespace USERS e os índices serăo criados na tablespace INDX. Neste caso, o comando CREATE TABLE indicará a tablespace USERS e o comando CREATE INDEX indicará a tablespace INDX.
Segmentos de Rollback
Os segmentos de Rollback foram descontinuados na versăo 9i, em seu lugar utiliza-se o conceito de Tablespace de UNDO. Permanece a informaçăo apenas a título de compatibilidade com antigas versőes.
Grupos de Redo Log
Todas as operaçőes executadas no BD săo armazenadas em um conjunto de arquivos (on-line Redo Log Files) responsáveis pela restauraçăo destas informaçőes em caso de queda da instância. O Oracle trabalha com, no mínimo, dois grupos de Redo Log. Ŕ medida que as transaçőes văo ocorrendo, estas săo armazenadas em um dos dois grupos de Redo Log (conhecido como arquivo corrente) e quando é alcançada a sua capacidade máxima de armazenamento (no nosso exemplo, 10MB definidos nesta etapa), é feita uma alteraçăo automática do arquivo corrente (switch - motivo pelo qual deve haver no mínimo dois arquivos). Caso haja uma queda da instância, durante sua recuperaçăo será lido o conteúdo dos Redo Logs e aplicadas as transaçőes até que o BD chegue exatamente até o momento em que sofreu o problema.
Vale ressaltar aqui que no momento em que o último grupo de Redo Log é preenchido, é efetuado automaticamente o switch e o primeiro grupo passa a ser sobrescrito. Se năo estivéssemos trabalhando no modo de arquivamento automático (definido na 6ş etapa – Figura 10) năo teríamos mais os dados de recuperaçăo daquele grupo de Redo Log.
No caso dos Redo Logs, as boas práticas săo:
- Utilizar espelhamento dos grupos de Redo Log, ou seja, adicionar membros (locais para criaçăo do arquivo de Redo Log) a cada um dos grupos. Estes membros săo espelhos entre si, contendo o mesmo conteúdo e sendo totalmente sincronizados. Os membros de cada grupo devem ser configurados alocando-os em unidades de disco diferentes. Isto promove segurança pois caso haja algum problema e um membro esteja corrompido, um outro membro (espelho) será utilizado para a recuperaçăo da instância. O espelhamento dos Redo Logs năo é feito através do DBCA, portanto iremos implementar manualmente através da ediçăo dos scripts;
- O ideal é que seja feita a alteraçăo do arquivo corrente (Switch) entre 20 e 30 minutos. Para isso acontecer é necessário um bom conhecimento de como o BD irá se comportar para a organizaçăo, ou seja, é preciso ter uma noçăo da quantidade de transaçőes que irăo ocorrer quando o BD entrar em produçăo, pois o switch é executado automaticamente quando o grupo é preenchido. Esta informaçăo é necessária para especificar o tamanho dos Redo Logs de maneira que năo sejam muito grandes, sofrendo switchs em um prazo muito longo, ou muito pequenos, sofrendo switch em um prazo muito curto. O dia-a-dia do BD vai permitir que o DBA defina estes valores e, apesar de năo ser possível redimensionar o tamanho dos Redo Logs, é possível excluir os atuais e recriá-los com os novos tamanhos definidos com base no comportamento do BD.

A configuraçăo (Figura 16) é feita simplesmente selecionando o grupo e alterando os valores na guia “Geral”. No caso do espelhamento, năo há como configurar através do DBCA. Este procedimento será feito na ediçăo dos scripts de criaçăo do BD.
Opçőes de criaçăo
A última etapa da utilizaçăo do DBCA é justamente a escolha de finalizaçăo do processo de criaçăo do BD.
Pode-se iniciar a criaçăo do BD, utilizar as configuraçőes efetuadas para criar um gabarito, gerar os scripts de criaçăo do banco ou qualquer combinaçăo das tręs opçőes (Figura 17).

No nosso exemplo iremos selecionar apenas a opçăo de geraçăo dos scripts e clicar no botăo finalizar. Após a conclusăo do processo, os scripts estarăo criados (Figura 18) e prontos para a execuçăo ou ediçăo.

Ediçăo dos Scripts de Criaçăo do BD
A partir de agora iremos iniciar a ediçăo dos scripts gerados pelo DBCA (Listagem 1) para adequar alguns parâmetros ŕ nossa realidade. Descreveremos a funçăo de cada arquivo, porém mostraremos apenas os arquivos que irăo sofrer uma alteraçăo para adequarmos ao nosso exemplo.
23/06/2004 - 08:55 - 945 SQLMag.bat
23/06/2004 - 08:55 - 983 CreateDB.sql
23/06/2004 - 08:55 - 731 CreateDBFiles.sql
23/06/2004 - 08:55 - 631 CreateDBCatalog.sql
23/06/2004 - 08:55 - 579 postDBCreation.sql
23/06/2004 - 08:55 - 2.939 init.ora
- Arquivo SQLMag.bat - É o responsável pela criaçăo dos diretórios e chamada de execuçăo dos scripts. Esse é o arquivo que será executado para criar o BD.
- Arquivo CreateDB.sql - O primeiro script que o arquivo SQLMag.bat chamará para execuçăo. É o responsável pela instruçăo >CREATE DATABASE utilizando os parâmetros configurados através do DBCA.
connect SYS/change_on_install as SYSDBA
set echo on
spool C:\oracle\ora92\assistants\dbca\logs\CreateDB.log
startup nomount pfile="C:\oracle\admin\SQL_Mag\scripts\init.ora";
CREATE DATABASE SQL_Mag
MAXINSTANCES 1
MAXLOGHISTORY 1
MAXLOGFILES 5
MAXLOGMEMBERS 3
MAXDATAFILES 100
DATAFILE 'C:\oracle\oradata\SQL_Mag\system01.dbf' SIZE 250M REUSE AUTOEXTEND ON NEXT
10240K MAXSIZE UNLIMITED
EXTENT MANAGEMENT LOCAL
DEFAULT TEMPORARY TABLESPACE TEMP TEMPFILE 'C:\oracle\oradata\SQL_Mag\temp01.dbf'
SIZE 40M REUSE AUTOEXTEND ON NEXT 640K MAXSIZE UNLIMITED
UNDO TABLESPACE "UNDOTBS1" DATAFILE 'C:\oracle\oradata\SQL_Mag\undotbs01.dbf'
SIZE 200M REUSE AUTOEXTEND ON NEXT 5120K MAXSIZE UNLIMITED
CHARACTER SET WE8MSWIN1252
NATIONAL CHARACTER SET AL16UTF16
LOGFILE GROUP 1 ('C:\oracle\oradata\SQL_Mag\redo01a.log', 'D:\oracle\oradata\SQL_Mag\redo01b.log')
SIZE 102400K,
GROUP 2 ('C:\oracle\oradata\SQL_Mag\redo02a.log', 'D:\oracle\oradata\SQL_Mag\redo02b.log')
SIZE 102400K,
GROUP 3 ('C:\oracle\oradata\SQL_Mag\redo03a.log', 'D:\oracle\oradata\SQL_Mag\redo03b.log')
SIZE 102400K;
spool off
exit;
As informaçőes em negrito săo relativas ŕs adiçőes executadas no script. Elas năo săo configuradas pelo DBCA e foram inseridas com objetivo de criar o espelhamento de Redo Logs.
- Arquivo CreateDBFiles.sql - É responsável pela criaçăo das Tablespaces e arquivos de dados “opcionais” criados na 7ş etapa – Figuras 13 e 14. Como năo teremos nada de novo em relaçăo ao que foi criado na etapa 7, o script năo sofrerá alteraçăo.
- Arquivo CreateDBCatalog.sql - É responsável pelas tarefas de criaçăo das visőes (Views) do dicionário de dados, compatibilidade de importaçăo e exportaçăo entre as versőes 7 e posteriores, possibilidade de uso da linguagem
- Arquivo postDBCreation.sql - Finalmente, o ultimo script a ser executado. Responsável pela chamada do script que recompila qualquer eventual módulo PL/SQL inválido, é responsável também em fazer a inicializaçăo do BD e criaçăo do arquivo de configuraçőes do servidor (spfile).
- Arquivo init.ora - Este é o arquivo de parâmetro de configuraçăo (pfile) que o DBCA cria a partir dos valores configurados durante sua execuçăo. Será utilizado na inicializaçăo do BD e também como base para a criaçăo do arquivo de configuraçőes do servidor.
Conclusőes
Neste artigo pudemos entender, na prática, a criaçăo de um banco de dados Oracle 9i. Percebemos que o Oracle possui uma estrutura bastante complexa e, em contrapartida, inúmeros recursos para implementaçăo de segurança, performance e confiabilidade.
Espero que tenha sido bastante útil e năo hesitem em enviar-me e-mail com suas dúvidas e sugestőes, pois terei o maior prazer em elucidar e proporcionar mais e melhores leituras. Até a próxima parte deste artigo!







