Vou contar uma história, imagine que temos em um colégio uma classe de vários alunos e o professor precisar realizar uma tarefa de busca por boletins que tenham nota igual a 10. O professor entăo decide atribuir esse trabalho aos seus alunos com o objetivo agilizar a conclusăo dessa busca extensa, pois existem dezenas de boletins a serem vistos. Săo divididos entre os alunos alguns pacotes contendo diversos boletins para analise, em pouco tempo os alunos mais velozes já terminaram o trabalho, mas existem os mais lentos que provavelmente estăo com dificuldade de leitura ou podem ter sido impactados por uma distribuiçăo incorreta na quantidade de boletins nos pacotes, ou seja, alguns podem ter recebido a mais do que outros. Enquanto isso o professor está esperando pelo retorno dos pacotes de forma sincronizada por todos os alunos para poder dar a tarefa como concluída.
A analogia acima demonstra de forma simples a ideia do funcionamento do paralelismo, a tarefa é quebrada em pedaços e espalhada entre múltiplos alunos para obter uma conclusăo mais rápida, ou seja, otimizando a tarefa, caso contrário apenas um aluno seria demandando de todo o trabalho e exigiria um esforço enorme, além de demorar a concluir. Através da história inicial conseguimos perceber que o uso paralelismo é bom, mas existem ressalvas e quem vai servir de termômetro para definirmos o melhor comportamento do paralelismo no ambiente SQL Server será o Wait Type CXPacket.
Paralelismo
O paralelismo no SQL Server é um recurso que tem o objetivo de reduzir o tempo de processamento das consultas e para isso as elas săo divididas em vários pedaços menores chamados de Task, em seguida cada Task é atribuída a uma Worker Thread que executará parte da consulta. A Worker Thread é uma abstraçăo que representa uma única Thread do sistema operacional. Após essa divisăo cada Thread que faz parte deste trabalho será executada em um Scheduler diferente, ou seja, em um núcleo do processador lógico específico. A quantidade de Schedulers que envolve os processadores que serăo utilizados para execuçăo das tarefas é chamado de DOP - Degree of Parallelism.
A divisăo de tarefas e sincronizaçăo ao final das execuçőes em paralelo é feita por operadores que chamamos de Exchange Operators. Antes do fim da execuçăo da Task pela Thread, essa tarefa fica aguardando para ser sincronizada com as demais e assim retornar os dados da consulta para o usuário. Enquanto a consulta espera pela sincronizaçăo, é possível notar na DMV sys.dm_exec_requests ou sys.dm_os_waiting_tasks o famoso Wait Type CXPacket, ele representa essa sincronizaçăo feita pelos Exchange Operators.
Internamente
Os Exchange Operators tem dois subcomponentes chamados de Produtora e Consumidora. Quando os registros passam através dos operadores de paralelismo (Distribute Streams, Repartition Streams e Gather Streams), também conhecidos como Exchanges, eles criam os pacotes, chamados de Packets. Uma Thread Produtora enche os pacotes com dados e os envia através dos operadores do paralelismo e depois a Thread Consumidora recebe esse pacote. Uma espera (Wait) relacionada ao CXPacket ocorre quando a Thread consumidora quer receber o pacote, mas năo existe pacote pronto ainda ou quando a Thread produtora quer enviar um pacote, mas o Buffer do CXPacket está cheio.
Novamente consultando a DMV sys.dm_os_waiting_tasks quando está presente o Wait Type CXPacket, a coluna Resource_description mostra algumas informaçőes relevantes. Primeiramente, quando é visto o valor e_waitPipeGetRow significa que existe uma Thread consumidora está aguardando para receber o pacote e caso apareça, o valor e_waitPipeNewRow significa que a Thread produtora é quem está aguardando para passar o pacote através dos operadores do paralelismo.
Ao verificar o plano de execuçăo podemos ver algumas informaçőes detalhadas, por exemplo, no operador Repartition Streams é possível observar que em uma das últimas linhas de informaçăo é apresentado o campo Node ID com valor igual a 5. Esse é o ID do operador do paralelismo e basicamente indica que a sub-árvore que está por baixo dele está sendo executado. Através da coluna Resource_description da DMV sys.dm_os_waiting_tasks é possível também ver essa informaçăo do Node ID. Veja exemplo na Figura 1.
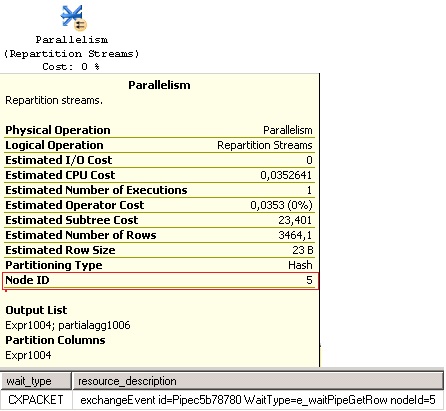
Figura 1. Exemplo do Node ID no plano de execuçăo e na consulta da DMV.
Cost Threshold for Parallelism
Para saber quando uma consulta no SQL Server poderá se beneficiar do paralelismo em sua execuçăo existe a configuraçăo do Cost Threshold for Parallelism, que atribui um delimitador para determinar quando a consulta deve ser paralelizada. O valor utilizado para definir o Cost Threshold for Parallelism é baseado no custo estimado do plano de execuçăo da consulta, que é medido em segundos e baseado no cruzamento de informaçőes aproximadas de CPU e IO para que o otimizador consiga determinar a melhor forma de executar a consulta em um hardware específico. Veja exemplo na Figura 2.
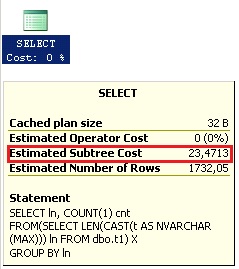
Figura 2. Exemplo do custo estimado do plano de execuçăo da consulta.
Continuando na analogia inicial, o Cost Threshold for Parallelism pode ser comparado a quantidade de boletins que será necessário serem feito a análise, se existirem apenas 30 boletins provavelmente năo fara sentido gastar tempo distribuindo entre os alunos esse trabalho e ao final ainda esperar a entrega sincronizada de todos, talvez seja melhor que o próprio professor faça esse trabalho, pois săo apenas poucos boletins para analisar.
O valor padrăo definido para o Cost Threshold for Parallelism é 5, ou seja, para que o SQL Server possa utilizar o paralelismo na consulta este valor deve ser alcançado. Como foi dito, o custo estimado da consulta é medido em segundos e o interessante é que já se foram os tempos em que o custo de determinada consulta podia ser medido utilizando essa métrica, hoje em dia isso năo tem menor sentido, até por que o SQL Server năo sabe o quăo rápido é o seu Storage ou a CPU, sendo assim, é uma questăo de aproximaçăo abstrata. O valor padrăo de 5 segundos foi configurado desta maneira nos anos 90’, quando os computadores tinham apenas processadores com um núcleo e os discos muito menos eficientes, nada comparado a hoje que temos uma grande quantidade de memória e discos SSD, por exemplo. Veja exemplo na Figura 3.
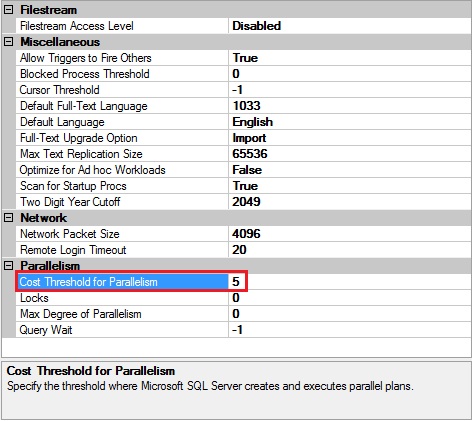
Figura 3. Exemplo da configuraçăo do Cost Threshold for Parallelism na instância.
Uma dúvida comum é se realmente deve ser ajustado ou năo o valor do Cost Threshold for Parallelism. A equipe do SQLSkills elaborou a consulta abaixo que pesquisa nos planos de execuçăo em Cache e busca os custos associados aos planos de execuçăo correntes que utilizaram o paralelismo, ou seja, dessa forma é possível ver o custo estimado da consulta e determinar se elas estăo lá desnecessariamente ou năo. Veja o código na Listagem 1 e o exemplo do resultado na Figura 4.
Listagem 1. Consulta para análise da melhor configuraçăo para o Cost Threshold for Parallelism.
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
WITH XMLNAMESPACES
(DEFAULT 'http://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
query_plan AS CompleteQueryPlan,
n.value('(@StatementText)[1]', 'VARCHAR(4000)') AS StatementText,
n.value('(@StatementOptmLevel)[1]', 'VARCHAR(25)') AS StatementOptimizationLevel,
n.value('(@StatementSubTreeCost)[1]', 'VARCHAR(128)') AS StatementSubTreeCost,
n.query('.') AS ParallelSubTreeXML,
ecp.usecounts,
ecp.size_in_bytes
FROM sys.dm_exec_cached_plans AS ecp
CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS eqp
CROSS APPLY query_plan.nodes('/ShowPlanXML/BatchSequence/Batch/Statements/StmtSimple') AS qn(n)
WHERE n.query('.').exist('//RelOp[@PhysicalOp="Parallelism"]') = 1

Figura 4. Exemplo do resultado da consulta.
Devemos analisar o valor da coluna Usecounts que conta a quantidade de vezes que aquele plano de Cache foi executado, dessa forma é possível verificar alguma falta de índice associado ŕs consultas com maior custo na coluna StatementSubTreeCost e tentar otimizá-las para que năo necessitem do paralelismo em suas próximas execuçőes. Entretanto existem consultas com custos relativamente altos que năo săo possíveis de otimizar para reduzir o custo na intençăo de ficar a baixo da margem do Cost Threshold for Parallelism, a decisăo nesse caso deve ser optar por alterar o valor padrăo.
Max Degree of Parallelism
O comportamento do paralelismo no ambiente do SQL Server pode ser alterado para tentar conseguir uma execuçăo mais rápida nas consultas ou para evitar a sobrecarga no servidor, para isso temos a opçăo do Max Degree of Parallelism que determina o número máximo de núcleos da CPU que podem participar da execuçăo da consulta. O valor padrăo é 0, ou seja, permite o uso de todos os núcleos disponíveis nos processadores. Veja exemplo na Figura 5.
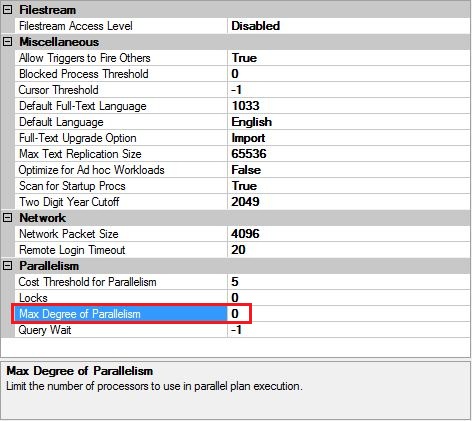
Figura 5. Exemplo da configuraçăo do Max Degree of Parallelism na instância.
A Query Hint MaxDop também pode ser utilizada para parametrizar ao nível de consulta a quantidade de núcleos do processador a serem utilizados. Essa opçăo subscreve o Max Degree of Parallelism configurado ao nível de instância. Veja exemplo nas Figuras 6 e 7.
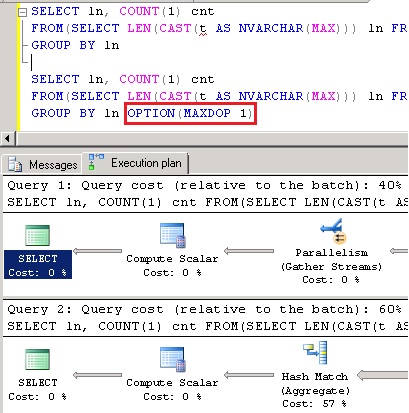
Figura 6. Exemplo do uso da Query Hint MaxDop na consulta.

Figura 7. Exemplo do uso da Query Hint MaxDop no processo de Index Rebuild.
CXPacket
O CXPacket é um dos Wait Types mais controversos, no sentido em que muitas pessoas interpretam errado o seu papel. Ele pode ser categorizado como um Wait Type de sincronizaçăo por que é exatamente o que ele faz, sincroniza os trabalhos de paralelismo existente numa consulta, sendo assim, caso ele esteja presente é por que existe uma execuçăo de consulta sendo paralelizada e năo necessariamente problemas de gargalo.
Análise Inicial
Antes de qualquer açăo no servidor algumas perguntas devem ser respondidas caso o Wait Type CXPacket apareça:
Eram esperadas consultas utilizando paralelismo no ambiente?
Processos de manutençăo como um Index Rebuild ou um DBCC CheckDB podem utilizar do paralelismo, mas normalmente năo devem ser encontrados muitos CXPackets, mas caso esteja, com certeza deve ser considerado que existe algo em execuçăo no SQL Server.
Os Wait Times estăo altos?
Se tem a presença de CXPacket mas os Wait Times estăo baixos, provavelmente năo será nada. Agora se existem altos Wait Times para o CXPacket significa que longas consultas estăo em execuçăo utilizando paralelismo. Quando ocorre esse cenário de altos Wait Times será necessário verificar as outras tarefas que podem estar envolvidas na consulta paralelizada para tentar entender o que pode estar acontecendo no ambiente, como por exemplo, um Wait Type PageIOLatch_SH junto ao CXPacket pode indicar que foi feito um Table Scan por um índice ineficiente.
Através da DMV sys.dm_exec_requests e sys.dm_os_waiting_tasks é possível acompanhar os Wait Times durante a execuçăo das consultas paralelizadas. Veja exemplo nas Figuras 8 e 9.
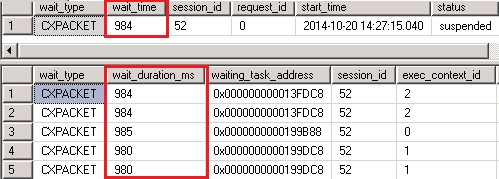
Figura 8. Exemplo do retorno das DMVs.

Figura 9. Exemplo de Wait Types diferentes no retorno da DMV.
Uma vez que foram respondidas as perguntas acima, entăo o que fazer?
Talvez năo seja necessário fazer nada, se é esperado que sua aplicaçăo disparasse consultas que utilizem paralelismo, năo é visto altos Wait Times e năo está acontecendo problemas de desempenho, provavelmente năo há o que se preocupar.
Piores Práticas
Uma das práticas mais comuns e contraditórias é ao se deparar com paralelismo consumindo todo o recurso de CPU do servidor alterar imediatamente a opçăo do Max Degree of Parallelism para 1, ou seja, apenas um núcleo do processador pode ser utilizado na execuçăo, năo utilizando o paralelismo independentemente do quăo grande é o custo da consulta.
Essa alteraçăo imediata tem como objetivo de tentar evitar a sobrecarga do servidor, minimizando os picos de CPU que săo comuns durante o paralelismo, mas o efeito pode acabar sendo o inverso, como por exemplo, em operaçőes manutençăo como, Index Rebuild e DBCC CheckDB que se beneficiam do paralelismo e fatalmente serăo prejudicadas.
Observando a DMV sys.dm_exec_requests no momento da execuçăo de uma consulta com o Max Degree of Parallelism igual a 1 năo veremos o CXPacket, mas bem provável que estará em seu lugar o Wait Type SOS_Scheduler_Yield. A presença desse Wait Type significa que a consulta poderia concluir mais rapidamente se tivesse mais recurso de CPU, mas năo necessariamente representa que o seu servidor precisa de mais recurso de CPU e sim a consulta.
Melhores Práticas
Ainda relacionado ŕ configuraçăo do Max Degree of Parallelism, a Microsoft tem documentado as diretrizes para o uso dessa configuraçăo em todas as versőes do SQL Server para que seja usado como modelo base em seu ambiente, afinal o uso do valor padrăo năo é a melhor recomendaçăo.
Pegando como base a mais atua diretriz para ambientes típicos, é dito que a recomendaçăo que para servidores com mais de 8 núcleos nos processadores é necessário configurar a opçăo Max Degree of Parallelism igual a 8, para menores o valor configurado deve 0, ou seja, utilizando todos os núcleos dos processadores disponíveis. Claro que existem muitas variáveis a serem levadas em consideraçăo para arquiteturas e configuraçőes de ambientes diferentes, como por exemplo, servidores NUMA com HyperThreading ou até quando é utilizado o Affinity Mask. Recomendo a leitura completa da documentaçăo, mas a utilizem apenas como base para encontrar a configuraçăo ideal, sendo que, para isso é necessários testes em ambientes específicos.
A mudança citada nas piores práticas visa solucionar o comum problema de consultas desnecessárias utilizarem o paralelismo em suas execuçőes e gastarem recursos excessivos do servidor. A melhor prática para solucionar esse problema normalmente está na configuraçăo do Cost Threshold for Paralellism que provavelmente está permitindo consultas menores utilizarem o paralelismo. Precisamos elevar esse valor para nos adequarmos a atual realidade de hardware moderno e com certeza o valor padrăo năo representa uma consulta grande, pois para as pequenas năo há a necessidade do uso do paralelismo.
Restriçőes
Assim como existem consultas sendo paralelizadas sem necessidade, também temos as consultas que gostaríamos que fossem paralelizadas, mas isso năo acontece. Assumindo que o custo da consulta é maior que o Cost Threshold for Paralellism, a configuraçăo do Max Degree of Parallelism e da Query Hint MaxDop estăo diferentes de 1, entăo nos deparamos com os inibidores do paralelismo, ou seja, restriçőes do SQL Server para o uso do paralelismo nas execuçőes.
Recursos que forçam o plano de execuçăo inteiro a năo utilizar o paralelismo:
- Todas as UDF (User-defined Functions);
- CLR que utilizam UDF;
- Cursores Dinâmicos;
- Miscellaneous built-ins: Erro_Number(), @@Trancount, Object_ID(), etc.
Recursos forçam parte do plano de execuçăo a năo utilizar o paralelismo, mesmo que outras partes consigam:
- System Table Scan;
- Sequence Function;
- Top;
- Query Recursiva;
- Todas as TVF (Multi Statement Table-Value Function);
Encontrando o Balanço
Sabendo todos esses pontos comentados temos entăo que encontrar o ponto de equilíbrio nas configuraçőes e melhores práticas. Todas as sugestőes a serem comentadas devem ter sua efetividade analisada em um ambiente de testes, a aplicaçăo em produçăo deve ser feita em uma janela de manutençăo, por que quando vocę faz alteraçőes das configuraçőes do comportamento do paralelismo o SQL Server apaga todos os planos de execuçăo que estăo em Cache.
Nosso objetivo será o diminuir o CXPacket, mas năo elimina-lo por completo, pois já vimos que o paralelismo é bom quando aparecem as grandes consultas para serem executadas, como relatórios que vocę quer conclua a execuçăo rápida usando o máximo de CPU.
Inicialmente mudaremos o Cost Threshold for Paralellism para 50, essa é uma indicaçăo do MCM Brent Ozar que encontrou essa medida após efetuar várias analises em diversos ambientes de clientes. Claro que se possível é válido fazer uma análise profunda, para isso comece utilizando a consulta apresentada anteriormente feita pela equipe do SQLSkills. Faça a análise dos planos de execuçăo em Cache buscando as consultas que estăo compiladas com maior custo, garantindo que elas sejam capazes de utilizar o paralelismo e as que precisam ser executadas com apenas um núcleo com o custo menor que o valor do Cost Threshold for Paralellism, dessa forma o valor ideal será encontrado.
Desenvolva bem as consultas para evitar os inibidores do paralelismo, assim năo haverá restriçőes inconvenientes.
Para analisar os impactos da alteraçăo do valor do Max Degree of Parallelism, primeiramente utilize o comando Set Statistics Time On para pegar a média do tempo de respostas das consultas comuns antes e comparar após efetuar a alteraçăo.
Após as mudanças, a próxima semana deve ser monitorado os indicadores de CPU, Waits Types com Wait Times mais altos e planos de execuçăo em Cache, dessa forma será possível observar o CXPacket diminuindo o seu tempo de Wait Time, mas saiba que ele nunca irá desaparecer completamente.
Ambiente OLTP
O ambiente OLTP é caracterizado por um alto volume de pequenas transaçőes idęnticas, que geralmente săo operaçőes rápidas de Select, Insert, Update e Delete.
Diferente de um ambiente de Data Warehouse ou de aplicaçăo de relatório onde intuitivamente o paralelismo irá dividir a consulta em pedaços menores, as pequenas transaçőes OLTP normalmente năo requerem, pois năo queremos que os operadores do paralelismo gastem seus recursos de CPU para uma execuçăo rápida. Para altos volumes de transaçőes OLTP é importante năo desperdiçar recursos de hardware.
Baseado no argumento acima existem alguns especialistas que defendem que para ambientes OLTP a melhor prática é sempre manter a configuraçăo do Max Degree of Parallelism igual a 1, por que podem existir consultas com agregaçăo ou algo do tipo que possam comprometer os recursos que um ambiente OLTP possa precisar. Além disso, geralmente aplicaçőes OLTP bem otimizadas năo văo realizar nenhum paralelismo, a menos que um índice ou estatística esteja faltando, exista alguma clausula ‘where’ incompleta ou a consulta năo é na verdade uma transaçăo OLTP.
Realmente deixar a configuraçăo padrăo para ambiente OLTP năo é a melhor prática, mas também năo é prudente definir como regra obrigatória o uso da configuraçăo como 1, que força o uso de apenas um núcleo do processador na execuçăo, isso pelo fato de o paralelismo ser um recurso do SQL Server e ao configurar dessa maneira sugerida, na realidade o recurso está sendo desabilitado, sendo assim, a melhor prática é encontrar os motivos pelos quais a execuçăo da consulta com a configuraçăo diferente de 1 pode estar afetando o seu servidor, para que somente após isto possa ser tomado a decisăo da melhor configuraçăo a ser feita no ambiente.
Um bom indicador a ser considerado, é avaliar através da DMV sys.dm_exec_requests se em seu ambiente OLTP dedicado é visto o CXPacket por mais de 5 % de todas as esperas de recursos do SQL Server e caso esteja, entăo vocę está provavelmente experimentando um gargalo devido ao paralelismo e pode recorrer a mudanças no Max Degree of Parallelism.
Ambientes OLAP e Relatório
Quando é feito o processamento de um Data Warehouse ou Relatório, a busca é feita em grandes volumes de dados e por um longo período, normalmente é onde o paralelismo faz mais sentido para otimizar o rendimento.
Comparado ao OLTP, o Data Warehouse săo caracterizados por um número pequeno de diferentes grandes transaçőes, além de tipicamente incluírem operaçőes de leitura em massa.
Observaçőes Finais
Para ambientes que săo tanto OLTP quanto OLAP é um desafio, pois o balanço correto tem que ser encontrado entre o valor definido ao Maximum Degree of Parallelism e o Cost Threshold for Parallelism. O recurso Resource Governor é bem útil para esse tipo de cenário, por que podem ser criados diferentes ambientes com configuraçőes específicas do MaxDop.
Existem diversas maneiras de analisar os Wait Types no SQL Server, 2 deles apresentamos através de DMV, mas também é possível utilizar recursos como, rastreamento do Extended Events, contadores de Performance Monitor e até ferramentas de monitoramento como MDW, Activity Monitor.
De forma geral acredito que paralelismo se apresenta como uma clara oportunidade de efetuar Tuning na consulta, por que o servidor em muitos dos casos escolhe por utilizar o paralelismo pelo fato de ele supor que será a maneira mais rápida de retornar os resultados da consulta e com melhorias na mesma, talvez possamos deixar o retorno ainda mais rápido sem a necessidade do uso do paralelismo.
Espero que através deste artigo tenha conseguido esclarecer grande parte das dúvidas relacionadas ao paralelismo e o CXPacket. Claro que esse assunto pode ser abordado muito mais profundamente, mas de forma geral esses conceitos básicos săo suficientes para desmistificar muito sobre o que é dito a respeito de todos os pontos que comentamos.







