Recursos especiais neste artigo:
Conteķdo sobre boas prŠticas, Artigo no estilo Curso Online
Neste artigo colocaremos a m„o na massa com um tutorial prŠtico onde o leitor poderŠ explorar todo o potencial do Splunk para monitoramento da TI de uma empresa com base em dados de mŠquina. Extrair valor de logs e fazer com que a infraestrutura de uma empresa tenha menos problemas com downtime, por exemplo, s„o alguns dos pontos que fazem do Splunk uma plataforma ķnica no mundo.
Em que situaÁ„o o tema ť ķtil
Imagine que vocÍ precisa
de uma ferramenta para consolidar logs de vŠrias mŠquinas servidoras em uma sů
e, atravťs de uma interface prŠtica, analisar os problemas que vÍm acontecendo
relacionados com a compra de um produto em sua plataforma de e-commerce. Ou
mesmo, imagine ter vŠrios servidores Linux/Unix/Windows remotos, sendo
necessŠrio consolidar todos os logs dos ativos de TI para investigaÁ„o de erros
ou atť ameaÁas de seguranÁa. A possibilidade de investigar problemas e
responder a eventos que impactam o funcionamento do seu ambiente fazem do
Splunk uma plataforma de Big Data ideal para anŠlise de toda a sua
infraestrutura de TI.
N„o basta somente querer monitorar o ambiente e obter respostas em tempo real, ť necessŠrio que o departamento de TI das empresas tenha as pessoas certas e a ferramenta de coleta e anŠlise de informaÁ„o mais adequada para que o trabalho seja realizado. Muitas s„o as empresas que tÍm interesse em entrar para o mundo da anŠlise de dados e ter suas decisűes baseadas em nķmeros ou fatos, e ť isso que o Splunk pode entregar, desde que a equipe de TI dÍ ao pessoal de negůcios o apoio necessŠrio para coletar os dados certos, disponibilizar um software para que analistas de infraestrutura possam analisar dados e extrair de lŠ, do Big Data, as respostas ŗs perguntas do dia a dia. O mais interessante ť que com o Splunk ť possŪvel conseguir respostas em segundos ao invťs de dias, o que acontece com empresas que ainda tocam grandes Data Warehouses.
Analisar atravťs de grŠficos os pacotes que trafegam em redes, roteadores e switches, ou ainda fazer o monitoramento de servidores Windows, Unix e Linux, ť parte do que o Splunk lhe darŠ possibilidade de fazer com poucos cliques. Deste modo, demonstraremos neste artigo algumas das funcionalidades do Splunk na prŠtica.
Iniciando o Splunk
O primeiro passo para iniciarmos com o Splunk ť acessar o site do produto e fazer o download da plataforma. Quando estiver na tela de download, perceba que vocÍ poderŠ selecionar o arquivo a ser baixado de acordo com a arquitetura da mŠquina, 32 ou 64 bits, e com o sistema operacional que esta roda. Mais a frente ser„o listados os sistemas operacionais suportados, mas, neste momento, selecione e baixe o arquivo adequado e faÁa a instalaÁ„o do Splunk. Para sistemas operacionais Microsoft, a instalaÁ„o segue o modelo NNF (Next-Next-Finish), enquanto que para SOs Unix-like, basta descompactar o arquivo ďtar.gzĒ ou ď.zipĒ no diretůrio /opt.
Feita a instalaÁ„o, precisamos ent„o iniciar o Splunk e trocar as credenciais que vÍm configuradas por padr„o (usuŠrio admin e senha changeme). Para usuŠrios de Windows, ť mais fŠcil iniciar os serviÁos do Splunk (Splunkd e Splunkweb) a partir do painel de serviÁos. No Mac ou Linux, ť necessŠrio utilizar a linha de comando para iniciar, parar, reiniciar ou checar o status atual dos serviÁos do Splunk, o que ť demonstrado nas Listagens 1 e 2.
Listagem 1. Iniciando o Splunk na linha de comando com MAC.
# Mac Ė iniciando o Splunk pela primeira vez
localhost:~wbianchi$ splunk start --accept-license
Splunk> See your world. Maybe wish you hadn't.
Checking prerequisites...
Checking http port [8000]: open
Checking mgmt port [8089]: open
Checking configuration...
Done.
Checking index directory...
Validated databases:
_audit _blocksignature _internal _thefishbucket history main summary
Done.
Success.
Checking conf files for typos...
All preliminary checks passed.
Starting splunk server daemon (splunkd)...
Done.
Starting splunkweb...
Done.
If you get stuck, we're here to help.
Look for answers here: http://docs.splunk.com/Documentation/Splunk
The Splunk web interface is at http://localhost:8000Listagem 2. Iniciando o Splunk na linha de comando com Linux-Unix.
# Linux Ė iniciando o Splunk pela primeira vez
root@localhost:~# /opt/splunk/bin/splunk start --accept-license
splunkd 3997 was not running.
Stopping splunk helpers...
Done.
Stopped helpers.
Removing stale pid file... done.
Splunk> Be an IT superhero. Go home early.
Checking prerequisites...
Checking http port [8000]: open
Checking mgmt port [8090]: open
Checking configuration...
Done.
Checking index directory...
Validated databases: _audit _blocksignature
_internal _thefishbucket history main summary
Done.
Success.
Checking conf files for typos...
All preliminary checks passed.
Starting splunk server daemon (splunkd)...
Done.
Starting splunkweb...
Done.
If you get stuck, we're here to help.
Look for answers here: http://docs.splunk.com/Documentation/Splunk
The Splunk web interface is at http://localhost:8000Note que tanto no Linux quanto no Mac utilizamos a flag --accept-license para aceitar a licenÁa e evitar que todo o texto da licenÁa seja exibido no terminal. Ao final da saŪda do comando de start, perceba que jŠ ť informado o endereÁo para ser acessado via browser para ent„o fazermos o primeiro login em nossa instalaÁ„o do Splunk. Para verificar se o processo ou serviÁo estŠ realmente ativo, utilize a opÁ„o status, como exibido na Listagem 3.
… interessante, em qualquer tipo de sistema operacional que for utilizado, configurar o diretůrio ďBinĒ (splunk/bin) da instalaÁ„o do Splunk na variŠvel PATH para que se tenha mais agilidade ao trabalhar com a plataforma na linha de comando. Vale ressaltar que muito do que faremos com a interface web (SplunkWeb) podemos fazer via linha de comando.
Listagem 3. Exibindo o status atual da inst‚ncia do Splunk.
localhost:~ wbianchi$ splunk status
splunkd is running (PID: 1132).
splunk helpers are running
(PIDs: 1168 1169 1177 1178 1179 1180 1361).
splunkweb is running (PID: 1148).Apůs o primeiro login no Splunk, o usuŠrio serŠ convidado a trocar a senha atual do usuŠrio admin para uma senha mais segura. Inicialmente a senha ť ďchangemeĒ, como jŠ informado, mas uma vez acessado vocÍ poderŠ colocar aquela que desejar. Apůs efetuar a troca da senha, seu browser serŠ levado ŗ tela de welcome. Na parte inferior da pŠgina, o usuŠrio jŠ poderŠ clicar em ďdefault appĒ para fazer as primeiras configuraÁűes, como colocar o seu nome em vez de utilizar o nome Administrador, definir o timezone no qual vocÍ estŠ inserido e definir, dentre os aplicativos padr„o Splunk, qual serŠ aquele que serŠ aberto apůs fazer login com o seu usuŠrio.
Apůs fazer as alteraÁűes, clique em logout e efetue login novamente para verificar se o nome que vocÍ configurou jŠ foi adotado pelo Splunk. Este aparecerŠ no menu superior, na parte direita da tela.
Colocando a m„o na massa
Como jŠ abordado neste artigo, o Splunk ť uma plataforma universal de dados de mŠquina que possibilita a coleta e a indexaÁ„o dos dados, estejam eles onde estiverem. … possŪvel coletar desde dados locais atť dados localizados remotamente, como em uma mesma LAN ou WAN. Se os dados n„o estiverem na mŠquina local onde estŠ instalado o Splunk, podemos instalar o Universal Forwarder para coletar os dados e enviŠ-los automaticamente para uma instalaÁ„o ou inst‚ncia de Splunk central. Isso ajuda a centralizar o monitoramento a partir da anŠlise dos dados de todos os softwares que suportam os serviÁos oferecidos pela TI de uma empresa, independentemente de onde estiverem tais softwares.
Em um cenŠrio mais simplista, ou seja, ďcomeÁando pelo comeÁoĒ, nesta parte do artigo teremos uma prŠtica pela qual buscaremos explicar a indexaÁ„o de dados com o Splunk. Vamos criar um Ūndice exclusivo onde ser„o indexados os dados, buscar uma fonte de dados, investigar e buscar por ocorrÍncias nos dados, criar painťis com relatůrios e grŠficos e finalizar com a criaÁ„o de alertas. Isso nos darŠ um overview geral das capacidades tťcnicas para se trabalhar com o Splunk, alťm de passarmos pelas principais features que o produto oferece. Para criaÁ„o deste cenŠrio, o leitor precisarŠ fazer o download dos arquivos de logs de exemplo que est„o compressos em um zip chamado Sampledata.zip, disponŪvel na documentaÁ„o online do Splunk (veja a seÁ„o Links). Apůs baixar o arquivo, posicione-o em um diretůrio de fŠcil acesso para trabalharmos com ele dentro do Splunk.
Conhecendo e criando um novo Ūndice
Como citamos anteriormente, e precisamos somente recordar neste tůpico, o Splunk armazena os dados de mŠquina coletados em buckets que fazem parte de Ūndices. Estes Ūndices s„o mantidos pelo průprio Splunk em uma estrutura denominada MapReduce, que paraleliza as consultas aos dados fazendo com que a performance seja muito superior a muitos sistema de armazenamento de informaÁ„o existentes.
Por padr„o o Splunk apresentarŠ alguns Ūndices para armazenamento de metadados criados automaticamente no processo de instalaÁ„o. Os Ūndices padrűes do Splunk para armazenamento de metadados e dados s„o os seguintes:
∑ summary: Ūndice interno utilizado para armazenar consultas que manipulam grandes volumes de dados. O resultado ť armazenado nesse Ūndice para auxiliar na recuperaÁ„o dos dados quando a mesma consulta for executada pela segunda vez. Se comprarmos com um banco de dados, seria este um sistema de cache de resultados vinculado ŗs consultas, ora denominado Summary Indexing. Os arquivos do Ūndice de sumŠrio est„o localizados em $SPLUNK_HOME/var/lib/splunk/summary;
∑ _internal: de longe, um dos Ūndices mais interessantes do Splunk, pois fornece vŠrias possibilidades, como verificar as mťtricas de processamento, a atual fila de consultas, violaÁűes de licenÁas, informaÁűes de DEBUG, etc. Os arquivos do Ūndice _internal est„o localizados em $SPLUNK_HOME/ var/lib/splunk/_internaldb;
∑ _audit: este Ūndice contťm informaÁűes sobre auditoria de processos, histůrico de alteraÁűes no sistema de arquivos e um histůrico de consultas do Splunk. Os arquivos deste Ūndice est„o localizados em $SPLUNK_HOME/var/lib/splunk/audit;
∑ _thefishbucket: Ūndice que contťm informaÁűes sobre os arquivos que vÍm sendo acessados pelo Splunk para escrita de dados e leitura dos mesmos. Este Ūndice estŠ localizado em $SPLUNK_HOME/var/lib/splunk/fishbucket;
∑ main: Ūndice padr„o para onde v„o todos os dados quando o administrador ou usuŠrio Splunk n„o especifica um Ūndice exclusivo para uma nova fonte de dados (especificar um Ūndice exclusivo para cada nova fonte de dados adicionada ao Splunk ť parte do manual de boas prŠticas). … tambťm chamado de defaultdb (no sistema de arquivos) e estŠ localizado em $SPLUNK_HOME/var/lib/splunk/defaultdb/db.
Os Ūndices internos do Splunk que tÍm nomes que iniciam com underline s„o Ūndices que armazenam informaÁűes de processamento do průprio Splunk, tais como auditoria de processos, histůrico de consultas, histůrico de alertas e violaÁűes de licenÁas. JŠ o Ūndice main, que tambťm ť criado no momento da instalaÁ„o, ť o Ūndice padr„o do Splunk para dados de usuŠrio.
… interessante criar um novo Ūndice sempre que um tipo de informaÁ„o diferente for adicionado ao Splunk. Os Ūndices s„o como apontadores para os dados que est„o armazenados em estruturas denominadas buckets, e estes, por sua vez, est„o organizados sobre o disco da mŠquina onde roda o Splunk.
Para criarmos um novo Ūndice, de maneira simplificada, podemos seguir por duas vias: pelo Splunk Manager ou pela linha de comando (ver Listagem 4).
Listagem 4. Criando um novo Ūndice na linha de comando.
root@splunk01:~# splunk add index splunkbr # commando simples
Index "splunkbr" added.Veja os passos para criaÁ„o do Ūndice via Splunk Manager:
1. FaÁa login no Splunk com o usuŠrio admin e a senha que configurou;
2. Acesse o menu Manager no canto superior direito;
3. Acesse o link Indexes, no agrupamento de menus Data;
4. Na tela que s„o listados todos os Ūndices que sua inst‚ncia Splunk possui, clique em New;
5. No campo Index name, informe o nome splunkbr;
6. Clique em Save.
Apůs clicar em Save, o browser serŠ retornado ŗ lista de Ūndices que a inst‚ncia Splunk possui. Nesse momento podemos verificar que o nosso Ūndice foi realmente criado, uma vez que ť parte da lista exibida na tela atual. Outra forma de listar o Ūndice criado ť via linha de comando, o que pode ser verificado na Listagem 5.
Listagem 5. Listando o Ūndice que acabamos de criar.
root@splunk01:/# $SPLUNK_HOME/bin/splunk list index | grep splunkbr
splunkbr
/opt/splunk/var/lib/splunk/splunkbr/db
/opt/splunk/var/lib/splunk/splunkbr/db
/opt/splunk/var/lib/splunk/splunkbr/dbNo tůpico anterior, foi solicitado ao leitor que fizesse o download de um arquivo contendo vŠrios logs. Nesse arquivo existem logs de trÍs servidores Apache e logs de uma inst‚ncia MySQL. O processo de adiÁ„o de dados ao nosso Splunk ent„o se inicia quando, a partir da Home do Splunk, clicamos em Add Data e selecionamos a opÁ„o Files & Directories. A opÁ„o Skip Preview poderŠ ser selecionada, seguindo com Upload and Index a file, jŠ que temos arquivos estŠticos. … nessa tela que vamos selecionar o Ūndice que serŠ utilizado para armazenar tais dados. Os passos para adicionar dados ao Splunk est„o descritos a seguir:
1. Na Home do Splunk, clique em Add Data;
2. Clique na opÁ„o Files & Directories;
3. Clique em Next na opÁ„o Consume any files on this Splunk Server;
4. Marque Skip Preview e Continue;
5. Na tela seguinte, selecione a opÁ„o Upload and index a file;
6. Clique no bot„o Browse para selecionar o arquivo ďSampledata.zipĒ;
7. Clique em More settings;
8. No campo Set host, selecione o valor ďregex on pathĒ;
9. No campo Regular expression, informe a seguinte express„o regular, de acordo com o sistema operacional que estŠ trabalhando:
Linux: Sampledata.zip:./([^/]+)/
Windows: Sampledata.zip:.\\([^/]+)/
10. Em Set the destination index, selecione splunkbr, que ť o Ūndice que criamos.
11. Clique em Save.
A tela seguinte, logo apůs clicar em Save, jŠ lhe darŠ a opÁ„o de iniciar as buscas por dados que est„o, nesse momento, sendo indexados pelo Splunk. Alťm disso, a Search App, que ť o aplicativo padr„o do Splunk, nos darŠ um sumŠrio de todos os eventos e padrűes jŠ indexados e encontrados, respectivamente, pelo Splunk. Clique no link Start Searching e vamos em frente.
Search App e a SPL (Search Processing Language)
Por meio da Search App, o administrador do Splunk jŠ conseguirŠ ter um sumŠrio do que estŠ sendo indexado no Splunk. ņ primeira vista jŠ ť possŪvel avistar um campo de busca que ť reconhecidamente um Google para o lado interno da TI, no qual vocÍ pergunta por determinados termos e o Splunk lhe trarŠ todos os eventos que tenham aquela dada string.
Esta App conta com trÍs Šreas de sumŠrio muito importantes, que s„o Source, que se refere ao arquivo que foi ou estŠ sendo indexado (path + arquivo), o sourcetype, que ť o tipo de informaÁ„o que o Splunk estŠ indexando e foi identificada pelo průprio Splunk, e hosts, que ť nome do host onde reside o arquivo que estŠ sendo indexado pelo Splunk. Estes trÍs fields estar„o presentes em qualquer fonte de dados que for indexada no Splunk, sendo que eles tambťm podem ser utilizados para efetuar buscas.
Um exemplo interessante para ser explorado nesse momento ť justamente o de clicar sobre o link apache1.splunk.com, localizado em hosts. Apůs clicar, o Splunk iniciarŠ uma busca pelos eventos que tenham sido originados pelo host apache1.splunk.com, e exatamente 9.199 linhas devem ser retornadas.
Percebam que, agora, no campo de busca, temos uma consulta por host igual ao nome do host que clicamos no sumŠrio hosts. Perceba tambťm que do lado esquerdo da tela surgiram os fields, estruturas que armazenam as informaÁűes que foram identificadas no processo de indexaÁ„o e tambťm de consulta (a cada consulta pode ser que um novo field seja descoberto!).
Os fields podem ser utilizados para buscar dados. Por exemplo, digamos que, nesse contexto, em que estamos trabalhando com dados de mŠquina que se referem aos logs de acesso do Apache, o administrador queira saber se existem erros de status 503 acontecendo durante a operaÁ„o. Se percorrermos os fields atualmente descobertos pelo Splunk, serŠ fŠcil achŠ-lo. Se ele jŠ foi descoberto pelo Splunk, podemos simplesmente escrever uma consulta conforme a Listagem 6.
Listagem 6. Consulta por erro de status 503 em um servidor Apache.
host="apache1.splunk.com" status=503
15 matching eventsVale salientar que existe um AND implŪcito entre a primeira e a segunda clŠusula da consulta da Listagem 6, ou seja, queremos recuperar o host igual a apache1.splunk.com onde tambťm haja status igual a 503. Nesse ponto, podemos ainda explorar um pouco mais a Search App para criar uma consulta que nos dÍ uma posiÁ„o da quantidade de erros de status 503 (Service Unavailable) que vÍm acontecendo em todos os hosts nos quais o Splunk vem coletando os logs do Apache e os indexando. Para isso, precisamos modificar a consulta da Listagem 6 e colocŠ-la conforme a Listagem 7, onde utilizamos o comando stats e apontamos que queremos buscar dados somente no Ūndice que criamos, o splunkbr (lembra?).
Listagem 7. Consulta por erro de status 503 nos servidores Apache.
index=splunkbr status=503 | stats count by host
15 matching events Apůs rodar a consulta da Listagem 7, podemos perceber que estamos chamando o Ūndice criado anteriormente com a presenÁa do sinal pipe ď|Ē, que funciona como no Linux/Unix, direcionando o resultado da primeira consulta para a segunda. Nos resultados da consulta, vemos que somente o Apache do servidor apache1.splunk.com tem problemas com status 503 (Service Unavailable), o que nos coloca em uma posiÁ„o mais proativa em relaÁ„o aos problemas que possam estar acontecendo com este software, naquele servidor. Neste ponto vale lembrar o que no primeiro artigo discutŪamos sobre os profissionais que por uma ou vŠrias horas estariam engajados em achar os problemas decorrentes de uma parada nos serviÁos de tecnologia nos arquivos de logs, ou melhor, nos arquivos de logs dos vŠrios softwares espalhados por vŠrios servidores.
Com o Splunk ť possŪvel centralizar toda a informaÁ„o de vŠrias mŠquinas e obter as respostas para perguntas como: ďdesde quando nosso serviÁo tem falhado?Ē ou ďquantas vezes nosso serviÁo falhou hoje?Ē.
O Time Range Picker, localizado ao final do campo de busca, permite ao usuŠrio da Search App ajustar o intervalo de tempo sobre o qual se deseja fazer as pesquisas e investigaÁűes. … possŪvel buscar dados em vŠrios intervalos prť-definidos, sendo que o usuŠrio ainda poderŠ personalizar o intervalo no qual busca por informaÁűes, clicando em custom e selecionando dados de um perŪodo especŪfico. Para listar os perŪodos suportados pela ferramenta, basta clicar no bot„o do Time Range Picker. Na Listagem 8 realizamos uma busca agrupando os status pela quantidade que cada um deles ocorreu ao longo do arquivo de log de acesso do servidor Web Apache. Perceba que, como temos trÍs servidores Apache sendo monitorados, os erros de todos eles s„o agrupados em um sů resultado. A Figura 1 apresenta o resultado da consulta da Listagem 8.
Listagem 8. Consulta por ocorrÍncia de status nos logs dos servidores Apache monitorados.
index=splunkbr
| stats count by status
| rename status as ReqStatus
| rename count as ReqQtd
| sort ĖReqQtd
Figura 1. Resultado da consulta da Listagem 7.
Na consulta da Listagem 8, como pode ser observado, utilizamos o comando rename para criar um apelido para as colunas do resultado.
Um livro com a referÍncia completa da linguagem de consulta utilizada no Splunk, de nome SPL ou Search Processing Language, pode ser baixado gratuitamente. Veja o endereÁo para isso na seÁ„o Links.
Outro exemplo interessante de comando que pode ser utilizado em consultas a dados no Splunk, ainda quando buscamos agrupar dados, ť o top. Este comando agrupa as ocorrÍncias de um determinado dado (em nosso exemplo utilizaremos o campo status) de acordo com o contexto atual e nos traz uma coluna adicional que informa o percentual de ocorrÍncia de cada status. A coluna percent ť adicionada automaticamente ao resultado. Veja na Listagem 9 um exemplo da utilizaÁ„o do comando top, e na Figura 2 o seu resultado.
Listagem 9. Consulta com o comando top.
index=splunkbr
| top status
| sort Ėstatus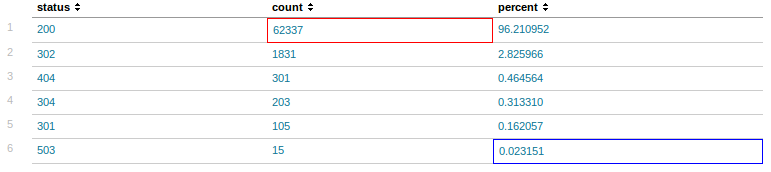
Figura 2. Resultado da consulta da Listagem 8.
Todas as consultas realizadas neste tůpico, exibidas nas Listagens 6 a 9, ainda podem ser executadas na linha de comando, chamando o programa client splunk e executando a consulta, como exibido na Listagem 10. As clŠusulas search e rtsearch podem ser utilizadas para se consultar utilizando a CLI e representam respectivamente uma busca simples e uma busca por dados em tempo real.
Listagem 10. Consultando dados utilizando a linha de comando.
$ splunk search Ďindex=_internal | stats countí
#
Preview of: index=_internal | stats count
count
------
562490Criando Dashboards
Este ť um dos pontos mŠximos da entrega de valor do Splunk. Apůs entrar com as consultas, aquelas que praticamos nas listagens anteriores, o administrador terŠ a oportunidade de gerar relatůrios baseados em grŠficos para tornar o processo de anŠlise dos dados ainda mais inteligŪvel.
Tudo comeÁa na Search App, onde, apůs escrever uma consulta e visualizar os resultados, teremos a possibilidade de visualizar dois botűes, ambos localizados logo abaixo do campo de busca, sendo um deles denominado Create. Ao clicar neste bot„o ser„o verificadas algumas opÁűes de criaÁ„o de objetos Splunk, como Dashboard Panel, Alert, Report, entre outros.
Nesse momento, jŠ passada a busca de dados, vamos nos ater aos relatůrios que criaremos em forma de grŠficos. O processo aqui ť simples. Uma vez que a consulta ť escrita e os resultados jŠ estejam sendo exibidos na Šrea de resultados, basta clicar no bot„o Create e, em seguida, em Dashboard Panel. Assim que um novo Dashboard Panel ť criado, ele pode contar com vŠrios grŠficos, os quais o administrador do Splunk poderŠ separar por Šreas da empresa. Estes grŠficos tambťm s„o conhecidos por painťis.
Imaginemos ent„o que precisamos exibir um grŠfico em cima dos resultados da consulta da Listagem 8, aquela que exibe a quantidade de erros de status 503 dos servidores Apache que estamos monitorando. Como estamos utilizando os dados de exemplo que baixamos da documentaÁ„o online do Splunk, estamos consultando os mesmos dados. Voltando ao Splunk, execute os passos a seguir para geraÁ„o do primeiro Dashboard Panel que conterŠ um grŠfico baseado na consulta da Listagem 8:
1. Entre com a consulta da Listagem 8 no campo de busca de dados, na Search App;
2. Apůs executar a consulta, clique no bot„o Create, localizado no canto direito da tela, logo abaixo do final do campo de busca;
3. Nesta primeira tela, informe o nome da consulta ďErrorByHostĒ no campo Name. Feito isso, clique em Next;
4. Selecione a opÁ„o New dashboard Name e informe o nome ďMyFirstDashboardĒ. Novamente, clique em Next;
5. Na terceira tela do Wizard, altere o campo Visualization para Column e clique em Next mais uma vez;
6. Na quarta e ķltima tela, teremos a oportunidade de clicar sobre o link com o nome que demos ao nosso painel de grŠficos no passo 4, MyFirstDashboard, e ent„o visualizŠ-lo. Veja na Figura 3 como ficou este painel.

Figura 3. Painel de grŠficos e o grŠfico que criamos com a consulta da Listagem 8.
Este processo de criaÁ„o de grŠficos que reportam respostas a perguntas internas ou externas de uma empresa com base nos dados de mŠquina pode ser realizado da forma como fizemos ou ainda salvando as consultas e adicionando-as aos painťis. Mas para que este artigo n„o fique t„o longo e/ou cansativo, tal processo serŠ mostrado em um průximo artigo.
Criando alertas
Para finalizar a apresentaÁ„o do produto, precisamos abordar os alertas, que s„o, na vis„o de muitos dos clientes que o Splunk tem no mundo, um tůpico de bastante import‚ncia, uma vez que se trata da facilidade que o Splunk apresenta de alertar usuŠrios a partir do envio de e-mails, execuÁ„o de scripts ou, ainda, na recente vers„o 5.0 do Splunk, o envio de relatůrios personalizados no formato PDF. Este recurso ť muito valioso, pois, numa situaÁ„o em que seu supervisor precisa de um relatůrio de estoque ou da quantidade de transaÁűes realizadas em um sistema todas as manh„s e tardes, por exemplo, basta escrever uma consulta para recuperar os dados que ele precisa visualizar e, em seguida, criar um alerta sobre tal consulta, programando o envio deste alerta no formato PDF diretamente para o e-mail do seu supervisor.
Da mesma maneira como criamos um painel de grŠficos ou Dashboard Panel, a partir do mesmo menu temos a oportunidade de criar os alertas, que seguem o mesmo padr„o de criaÁ„o. Apůs escrevermos a consulta da Listagem 6, a qual nos traz as ocorrÍncias do erro de status 503 no servidor apache1.splunk.com, criaremos um grŠfico para nos alertar sempre que um erro dessa natureza for retornado como resultado da consulta.
Ao escrever a consulta no campo de busca, atente-se ŗs sugestűes que s„o disponibilizadas pelo Splunk logo abaixo deste campo. Apůs executar a consulta e visualizar os resultados, clique no bot„o Create e selecione a opÁ„o Alert. Feito isto, um Wizard serŠ aberto e iniciaremos a implementaÁ„o de um alerta, cujo processo ť apresentado a seguir:
1. Na primeira tela do Wizard, dÍ o nome ďMyFirstAlertĒ ao seu alerta e clique em Next;
2. Na segunda tela, teremos a oportunidade de configurar o envio de e-mail (marcando a opÁ„o Send email) e rodar um script, que deverŠ estar armazenado em $SPLUNK_HOME/bin/scripts/ (marcando a opÁ„o Run a script). Feito isto, preencha o campo com um script teste chamado ďecho.shĒ e clique em Next;
3. Na terceira tela, clique em Finish.
Terminados esses passos, o seu primeiro alerta sobre a anŠlise dos dados retornados pela consulta da Listagem 6 estarŠ criado. Um ponto interessante ť que, caso esse erro aconteÁa muito em produÁ„o, vocÍ ainda poderŠ utilizar a opÁ„o throttling para adormecer os alertas por x segundos, minutos ou, ainda, horas, para que o problema possa ser resolvido e a caixa de e-mails do pessoal n„o vire mais um problema. Ao disparar e-mails como alertas podemos ainda enviar os resultados de uma consulta anexados nos formatos ď.pdfĒ ou ď.csvĒ, ou ainda colocar a consulta e o resultado no corpo do e-mail (inline).
Conclus„o
Neste artigo sobre o Splunk, foi feito um overview geral da soluÁ„o Splunk para o monitoramento de TI de uma organizaÁ„o, independentemente do seu tamanho: pequena mťdia ou grande. O Splunk ť uma soluÁ„o que oferece um framework com vŠrios tipos de soluÁűes e que ainda suporta o desenvolvimento de novas Apps sem necessidade de ferramenta terceira adicional. Ainda, oferece uma API chamada REST, que permite que as linguagens PHP, Python, Java e JavaScript sejam utilizadas para a criaÁ„o de extensűes do Splunk Ė seja para um tratamento adicional dos dados, seja para implementaÁ„o de novos templates para deixar o Splunk com a cara da sua empresa.
Exploring
Splunk
http://www.splunk.com/goto/book
DocumentaÁ„o do
Splunk
http://docs.splunk.com/Documentation
Download do
arquivo de logs (Sampledata.zip)
http://tinyurl.com/bgmkod3
Site oficial
Splunk em portuguÍs
http://pt.splunk.com
Splunk
Processing Language Book
http://www.splunk.com/goto/book







