Nesta primeira parte do artigo conheceremos algumas definiçőes introdutórias na área de mineraçăo de dados.
Na análise do grande volume de dados presente nas organizaçőes nos dias atuais. Esta quantidade ultrapassou a capacidade humana de interpretar e compreender tanta informaçăo. Para isso, é importante conhecer e saber como utilizar técnicas de mineraçăo de dados.
Com o avanço das tecnologias, presenciamos um enorme crescimento na capacidade das pessoas em gerar e coletar dados, sejam esses dados administrados pelo governo, pela comunidade ou pelas entidades de pesquisa. Esse grande volume de dados vem ultrapassando a capacidade humana de interpretar e compreender tanta informaçăo.
O enorme crescimento das empresas e a forte concorręncia entre elas instiga a busca por um melhor aproveitamento das informaçőes, fazendo com que a necessidade de novas ferramentas e técnicas para manipulaçăo e armazenagem de dados sejam criadas. Nesse contexto, as empresas tęm, ao seu alcance, uma enorme oportunidade para compreender, por meio de seu próprio repositório de dados, o andamento de seus negócios, visando melhorar a competitividade no mercado.
Isso impulsionou o desenvolvimento do processo para a descoberta de conhecimento em base de dados – KDD (Knowledge Discovery in Database), que é baseado na busca, análise e interpretaçăo de padrőes úteis, retirados de grandes bases de dados. Vários estudos estăo sendo realizados nesta área, a fim de aprimorar este processo e tornar sua aplicaçăo mais acessível, compreensível e eficaz, garantindo que a retirada de informaçőes seja feita de forma consistente.
Com isso, surge na década de 80, a Data Mining, também chamada de Mineraçăo de Dados, que é uma das etapas principais dentro do Processo de Descoberta de Conhecimento, originada de áreas como Estatística, Inteligęncia Artificial e Banco de Dados. A técnica é usada para transformar grandes volumes de dados em informaçőes significativas para o planejamento, a gestăo e a tomada de decisăo.
A mineraçăo de dados está sendo cada vez mais aplicada nas mais diversas áreas. Na medicina para prever paciente com maior probabilidade de contrair uma doença específica, com base nos dados históricos dos pacientes. Na telecomunicaçăo, para identificar fraudes em ligaçőes telefônicas, dentre um enorme número de ligaçőes efetuadas pelos clientes. No mercado financeiro, para prever as açőes que estarăo em alta na bolsa de valores, em funçăo do histórico de preços das açőes e valores de índices financeiros.
Embora as aplicaçőes mais comuns de mineraçăo de dados se refiram a clientes, compras e vendas, esta área é ampla e tem sido aplicada no setor educacional. As instituiçőes de ensino tiveram, nos últimos tempos, uma ampliaçăo, tanto de cursos, quanto de vagas. Desta forma, os responsáveis precisam ter a preocupaçăo de acompanhar a permanęncia desses alunos nos cursos ofertados. Para que o índice de conclusăo de cursos aumente é necessário identificar os fatores que levaram ao insucesso dos estudantes. A mineraçăo de dados trouxe uma grande contribuiçăo para esse quesito, pois através de informaçőes escondidas em bases de dados, é possível descobrir os principais fatores que influenciam a conclusăo, a evasăo, ou até mesmo o tempo médio para concluir um curso. Obtendo esse relatório geral dos problemas encontrados nas escolas, os responsáveis podem realizar medidas efetivas para melhorar o ensino em suas instituiçőes e, consequentemente, em todo o país.
A aplicaçăo do KDD e, especificamente da etapa de Data Mining, pode ser de enorme importância para todas as áreas que necessitem retirar informaçőes de uma base forte e concreta de dados. Com isso, ao aplicar a técnica em uma base de dados institucional, é possível retirar das mesmas informaçőes relevantes para tomada de decisőes que ajudam na soluçăo de um problema, ou aperfeiçoamento de técnicas já usadas para administrar recursos de qualquer ordem.
Nesta primeira parte do artigo conheceremos algumas definiçőes introdutórias na área de mineraçăo de dados.
Para isso, serăo apresentados a partir de agora os conceitos relacionados ao processo de descoberta de conhecimento em bases de dados (KDD), com ęnfase na etapa de mineraçăo de dados. Será destacado também as ferramentas que servirăo de apoio ao processo de descoberta de conhecimento em bases de dados, tais como Weka, Data Warehouses, Data Marts, e DTS.
Dados, informaçăo e conhecimento săo um conjunto que tem sido um importante fator de competitividade, aumento da produtividade e da qualidade em diferentes tipos de organizaçőes.
Os dados tratados isoladamente representam um ou mais itens que năo podem transmitir mensagens úteis. Para que estes dados se tornem úteis, passando alguma informaçăo, é necessário que as pessoas atuem sobre eles.
A informaçăo săo os dados tratados, que se forem devidamente processados săo providos de um determinado significado e contexto para o sistema. A informaçăo é um fluxo de mensagens e por meio dela năo só se extrai, como também se constrói o conhecimento.
O conhecimento, além de ter um significado, também possui uma aplicaçăo. Constitui um saber, produz ideias e experięncias que as informaçőes por si só năo seriam capazes de mostrar.
A extraçăo de conhecimento em bases de dados - Knowledge Discovery in Databases (KDD) teve início nos anos 70, tendo como objetivo adquirir conhecimento das bases de dados acumuladas. O termo foi formalizado em 1989, englobando recursos de reconhecimento de padrőes, estatística, máquinas de aprendizado e métodos de visualizaçăo. Uma das definiçőes mais populares foi proposta em 1996, por um grupo de pesquisadores: “KDD é um processo, de várias etapas, năo trivial, interativo e iterativo, para identificaçăo de padrőes compreensíveis, válidos, novos e potencialmente úteis a partir de grandes conjuntos de dados.”
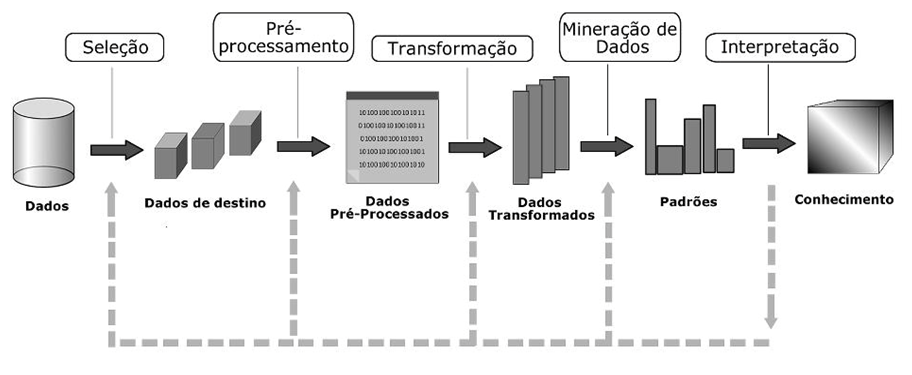
O KDD é usado na área financeira, telefonia, franquia de Fast-Food, açăo social, educaçăo, área médica, área financeira, arrecadaçăo de impostos, área de seguros, área de produçăo e diversos outros tipos de bancos de dados. A Figura 1 mostra detalhadamente as etapas de KDD da fonte de dados inicial até o processo de extraçăo de conhecimento.
O processo de KDD pode ser dividido em tręs etapas operacionais: pré-processamento, mineraçăo de dados e pós-processamento.
Uma breve descriçăo destas etapas é apresentada a seguir:
A etapa de pré-processamento compreende a obtençăo, organizaçăo e tratamento dos dados. Inicia-se a seleçăo dos dados, ou seja, a partir de um critério definido pelo especialista do domínio faz-se a seleçăo de um conjunto de dados considerados importantes para a organizaçăo. Na maioria das vezes, os dados para análise encontram-se em um formato inadequado para realizaçăo do processo de KDD. Para solucionar esse problema é necessário aplicar métodos de tratamento para fazer a limpeza dos mesmos.
As principais funçőes de pré-processamento dos dados săo:
O processo será visto na próxima seçăo deste artigo.
A etapa de pós-processamento compreende a visualizaçăo, análise e interpretaçăo da etapa de mineraçăo. Nessa etapa, o analista/especialista em KDD verifica os resultados obtidos na etapa anterior e faz uma análise para a transformaçăo do conhecimento em novas alternativas de uso de informaçőes. Os padrőes extraídos podem ser simplificados, avaliados, visualizados ou simplesmente documentados para o usuário final.
Um ponto importante a se destacar no pós-processamento é que o especialista no domínio da aplicaçăo representa a pessoa ou o grupo de pessoas que conhece o assunto em que deverá ser realizada a aplicaçăo de KDD. Em geral, pertencem a esta classe analistas de negócio interessados em identificar novos conhecimentos que possam ser utilizados em sua área de atuaçăo. Costumam deter o chamado conhecimento prévio sobre o problema (background knowledge). As informaçőes prestadas pelas pessoas deste grupo săo de fundamental importância no processo de KDD, pois influenciam desde a definiçăo dos objetivos do processo até a avaliaçăo dos resultados.
Data Mining é a etapa do KDD que consiste na aplicaçăo de algoritmos específicos que extraem padrőes a partir dos dados. Originalmente, essa técnica deriva das áreas de estatística, inteligęncia artificial e banco de dados, e tem como objetivo explorar grande quantidade de dados na busca de padrőes consistentes.
Historicamente, a mineraçăo de dados surgiu com a evoluçăo dos bancos de dados, em meados dos anos 80 em diante, quando as organizaçőes conseguiram armazenar grandes quantidades de dados. Nos anos 90 percebeu-se que esses dados estavam sendo subutilizados e, com isso, surgiu a ideia de usá-los de forma estratégica para a descoberta de novas informaçőes. Essa, porém, năo era uma tarefa fácil. As empresas tęm bancos com trilhőes de registros, com centenas de atributos, que devem ser analisados simultaneamente. Com isso, surgiu a técnica que recebeu o nome de mineraçăo de dados.
As técnicas da mineraçăo de dados passaram a ser usadas como exploraçăo desses dados, por vários motivos:
Com a mineraçăo de dados, podem ser realizadas algumas tarefas, como:
A tarefa de associaçăo tem a finalidade de identificar quais atributos estăo relacionados, e formar regras a partir dessas informaçőes para que sejam utilizadas por um analista para geraçăo de novos conhecimentos. As regras săo representadas pela notaçăo: SE atributo X ENTĂO atributo Y, onde X e Y săo conjuntos de valores (sintomas de um paciente, artigos comprados por um cliente, entre outros). O objeto desta técnica é representar, com determinado grau de confiança, uma relaçăo existente entre o antecedente e o consequente de uma regra de associaçăo, ou seja, a regra contém no antecedente um subconjunto de atributos e seus valores e no consequente um subconjunto de atributos que decorrem do antecedente.
Um exemplo: em um supermercado, uma regra de associaçăo pode ser do tipo “50% dos clientes que compram păo também compram leite”.
Produto=Păo 100 ==> produto=leite 50 conf:(0.50)
Este símbolo ==> faz a divisăo entre o antecedente e o consequente. O número que aparece antes do símbolo ==> indica o suporte da regra. O número que aparece no final da regra indica quantas vezes o consequente aparece para cada ocorręncia do antecedente. E o número final, entre paręnteses, é o valor da confiança, ou seja, em 100 compras em que o leite aparece, em 50 o păo é levado junto, entăo 50/100=0,5, representando 50% de confiança.
Descobrir regras de associaçăo entre produtos comprados em uma mesma compra pode ser útil para induzir a comprar mais, melhorar a organizaçăo das prateleiras, facilitar (ou dificultar) as compras do usuário.
Algoritmos de associaçăo podem ser utilizados como suporte ŕ tomada de decisăo. Esses algoritmos năo pretendem apenas satisfazer um único objetivo específico. Através de uma fonte de dados, um gestor pode analisar o que caracteriza um bom cliente, determinar os produtos que certo tipo de cliente pode comprar, identificar produtos que influenciam a venda de outros produto ou, apenas, caracterizar os seus grupos de clientes.
O algoritmo Apriori é um dos algoritmos mais usados para buscas em regras de associaçăo.
Definiçőes necessárias:
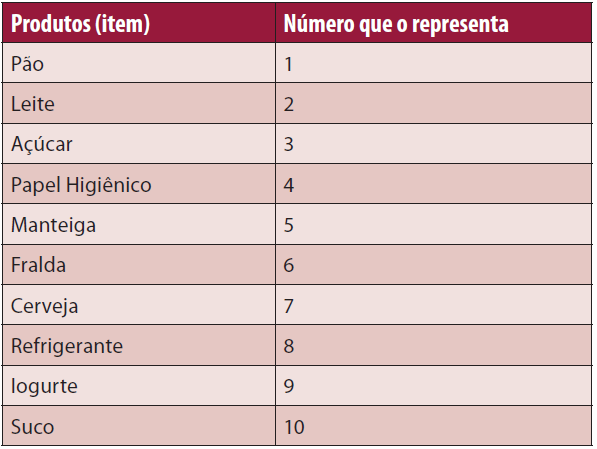
Para entender o algoritmo, imagine uma situaçăo em que um gerente de um supermercado está interessado em conhecer os hábitos de compra de seus clientes. Por exemplo, quais os produtos que os clientes costumam comprar ao mesmo tempo, a cada vez que vęm ao supermercado. Com isso, ele poderá planejar melhor os catálogos do supermercado, os folhetos de promoçőes de produtos, as campanhas de publicidade, além de organizar melhor a localizaçăo dos produtos nas prateleiras do supermercado colocando próximos os itens frequentemente comprados juntos além de encorajar os clientes a comprar tais produtos conjuntamente. Esse gerente dispőe de uma mina de dados, que é o banco de dados de transaçőes efetuadas pelos clientes. A cada compra de um cliente, săo registrados neste banco todos os itens comprados. Para facilitar a representaçăo dos produtos na tabela, vamos associar um número a cada produto do supermercado, como a da Tabela 1.
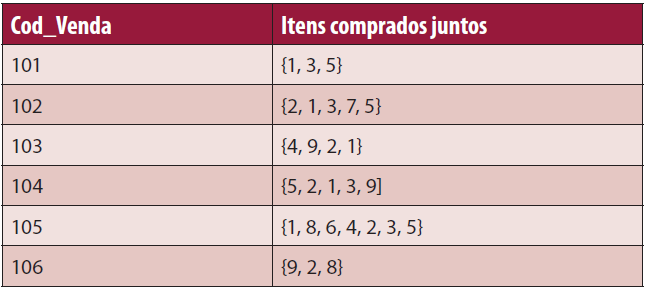
Cada conjunto de itens comprados pelo cliente numa única transaçăo é chamado de Itemset. Um itemset com k elementos é chamado de k-itemset. Suponha que o gerente decide que um itemset que aparece em pelo menos 50% de todas as compras registradas será considerado frequente. Por exemplo, se o banco de dados que ele dispőe é o ilustrado na Tabela 2, entăo o itemset {1,3} é considerado frequente, pois aparece em mais de 60% das transaçőes. Suporte de um itemset é definido como sendo a porcentagem de transaçőes onde este itemset aparece.
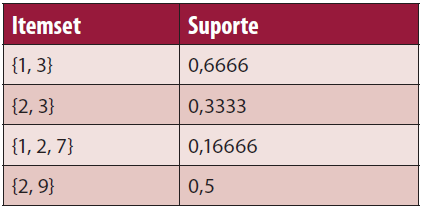
A Tabela 3 contabiliza os suportes de diversos itemsets com relaçăo ao banco de dados de transaçőes da Tabela 2.
O que identifica uma transaçăo năo é o identificador do cliente, mas sim o indicador da transaçăo Cod_Vendas. O ItemSet {1,3} aparece em quatro transaçőes no exemplo do banco de dados da Tabela 2, esse banco possui no total seis registros de vendas, entăo calculamos o valor do suporte em 4/6 = 0,6666.
Se a exigęncia mínima do gerente para um itemset ser considerado frequente seja 50%, entăo os itemsets da Tabela 3 que serăo considerados frequentes săo: {1, 3}, {2, 9}.
Uma regra de associaçăo é uma expressăo da forma A -> B, onde A e B săo itemsets. Por exemplo, {păo, leite} -> {café} é uma regra de associaçăo. Essa regra tem como ideia, que pessoas que compram păo e leite tendem a comprar café também, isto é, se alguém compra păo e leite entăo também compra café. Repare que esta regra é diferente da regra {café}->{păo,leite}.
A toda regra de associaçăo A -> B associamos um grau de confiança, denotado por conf(A -> B). Este grau de confiança é a porcentagem das transaçőes que suportam B dentre todas as transaçőes que suportam A, isto é: conf(A -> B) = número de transaçőes que suportam (A U B) número de transaçőes que suportam A.
Para escolher uma ferramenta de descoberta de conhecimento, deve-se observar as seguintes características:
Com base nas características citadas acima, algumas ferramentas foram pesquisadas, tais como Clementine, Enterprise Miner e Weka. A ferramenta Weka, que será apresentada a seguir, possui interface gráfica amigável, possibilita a utilizaçăo de recursos via API’s, é distribuída gratuitamente (característica que as outras ferramentas citadas năo possuem), e é muito citada por diversos autores como uma excelente ferramenta de suporte ŕ mineraçăo de dados.
Desenvolvido por um grupo de pesquisadores na universidade de Waikato (Nova Zelândia), em 1993, este software herdou seu nome da ave WEKA (Gallirallus australis). Inicialmente, os pesquisadores desenvolveram um software que visava a investigaçăo de técnicas de aprendizagem de máquina. Sua aplicaçăo inicial direcionou-se para agricultura, área base na economia da Nova Zelândia. Posteriormente, a ferramenta Weka permitiu que fossem implementados algoritmos de mineraçăo de dados na linguagem C e TCL/TK. Em 1997, o código foi reescrito na linguagem JAVA e foram adicionados alguns algoritmos de modelagem de dados. Este software também é desenvolvido sob licença GNU (General Public Licence) e é facilmente usado por iniciantes pela sua interface gráfica. Grande parte dos seus recursos pode ser acessível pela sua GUI para interaçăo com os arquivos de dados e capaz de produzir resultados visuais no formato de tabelas e curvas, e através de API`s os demais recursos podem ser utilizados na programaçăo.
Tem como principal característica ser portável; dessa forma, pode ser executado nas mais variadas plataformas e aproveitando os benefícios de uma linguagem orientada a objetos. Além disso, é de domínio público disponível para download em Weka 3: Machine Learning Software in Java.
A ferramenta Weka tem como formato nativo o tipo ARFF (arquivo de atributo-relaçăo), que consiste em duas partes. Na primeira estăo os atributos nos quais devem ser definidos os tipos ou valores que eles podem representar, estes valores devem ser separados por vírgulas e entre “{}”. Na segunda parte encontramos os registros a serem minerados com os valores dos atributos, para cada instância, separados por vírgulas. Caso ocorra ausęncia de um registro, deve-se atribuir em seu lugar o símbolo “?”.
Com isso, a ferramenta Weka permite o uso de planilhas eletrônicas e banco de dados, os quais permitem exportar os dados em um arquivo onde as vírgulas săo os separadores. É necessário apenas carregar o arquivo em um editor de texto e adicionar o nome do conjunto de dados usando @relation+nome do conjunto de dados, para cada atributo usa @attribute, e após colocar uma linha com @data e logo em seguida os dados em si, salva-se entăo o arquivo com extensăo arff.
O arquivo ARRF é o padrăo Weka, porém, o software interpreta também outros formatos de arquivos como CSV, C4.5 E C4.5 codificado, Database, JSON, LibSVM, Matlab, SVMlight, XRFF.
A ferramenta WEKA é formada por um conjunto de implementaçőes de algoritmos de diversas técnicas de mineraçăo de dados, tais como: Apriori, FPGrowth, PredictiveApriori, Tertius (métodos de associaçăo); EM, Cobweb, SimpleKMeans, DBScan, CLOPE (métodos de agrupamento); Regressăo linear, Geradores de árvores modelo, Regressăo local de pesos, Aprendizado baseado em instância, Tabela de decisăo, Perceptron multicamadas (Métodos para prediçăo numérica); Árvore de decisăo induzida, Regras de aprendizagem, Naive Bayes, Tabelas de decisăo, Regressăo local de pesos, Aprendizado baseado em instância, Regressăo lógica, Perceptron, Comitę de perceotrons, SVM (métodos de classificaçăo).
Data Warehouse (DW) ou armazém de dados é um sistema de computaçăo utilizado para organizar, limpar e estruturar as atividades de uma organizaçăo, sendo úteis para revelar informaçőes estratégicas que podem facilitar a tomada de decisăo. O termo é definido como um depósito de dados orientado por assunto, integrado, năo volátil, variável com o tempo, para apoiar as decisőes da geręncia:
O conceito de armazém de dados surgiu com a necessidade de integrar dados provenientes de diversas origens sem causar impacto sobre as bases operacionais acessadas diariamente dentro da empresa como, por exemplo, sistemas administrativos, controle de estoque, sistemas de expediçăo, entre outros, e também de gerenciar um grande volume de dados.
O Data Warehouse apoia o processo KDD, nele os dados săo tratados de maneira que todos tenham os mesmos formatos, convençőes, entre outras características. Por exemplo: o sexo pode ser descrito de várias maneiras, como "fem", "f", "masc", "m", tais dados săo convertidos para "feminino" e "masculino", mantendo uma base de dados limpa, com dados consistentes.
Um data mart é um data warehouse de menor capacidade e complexidade usado para atender a uma unidade específica de negócios. Portanto, săo tipicamente mais fáceis de construir e manter. Por ser menor, possibilita a análise multidimensional, com os cruzamentos de dados e visőes previamente calculadas, com o objetivo de aumentar a velocidade na consulta das informaçőes.
Os data marts săo subconjuntos de um data warehouse, basicamente deve-se extrair, transformar e integrar os dados pertinentes. Representa dados de um único processo de negócio.
O modelo estrutural é a forma como o data warehouse ou o data mart é construído. Os modelos mais utilizados para a modelagem de um ambiente multidimensional săo:
Os tręs modelos utilizam uma arquitetura composta de uma tabela fato e um conjunto de outras tabelas chamadas dimensőes. O modelo Floco de Neve possui “subtabelas” dimensionais representando uma agregaçăo maior dos dados que săo referenciados unicamente pelas tabelas dimensăo.
O modelo Join Star possui diversas tabelas fatos ligadas ŕs tabelas dimensionais, sendo que uma tabela dimensăo pode ser referenciada por mais de uma tabela fato.
Já o modelo Estrela, que é o mais utilizado, possui uma única tabela fato ligada ŕs várias tabelas dimensionais.
O DTS (Data Transformation Services) é uma ferramenta que apoia a transferęncia e o tratamento dos dados entre a base operacional, e o data mart. Auxilia no processo de importaçăo, transformaçăo e carregamento dos dados, denominado ETL (Extraction, Transformation and Load), facilitando entăo o processo de extraçăo de conhecimento. As fontes de dados que podem fazer parte do data mart săo selecionadas através desta ferramenta. Estes dados săo limpos, transformados e exportados para o repositório. É possível também selecionar as colunas que podem atravessar o processo de mineraçăo.
As técnicas de mineraçăo de dados estăo sendo cada vez mais aplicadas e năo há limite ou área específica. Tem como finalidade a melhoria ou resoluçăo dos problemas e tomadas de decisőes. Alguns exemplos de áreas de aplicaçăo: marketing, vendas, educaçăo, finanças, manufatura, saúde, energia, telefonia, franquia de fast-food, aplicaçőes para o poder judiciário, entre outras.
A seguir alguns exemplos de aplicaçőes práticas do uso do data mining:
Como se pode observar, existem diferentes áreas em que podemos obter os benefícios do uso de técnicas de mineraçăo de dados. No próximo artigo desta série daremos continuidade a esta discussăo com a aplicaçăo prática de técnicas de mineraçăo para a área de dados educacionais.

Veja os resultado dos nossos alunos
Conquistas reais de quem está aplicando o método








Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.