Para o leitor que já está familiarizado com JavaScript, Node.js é só mais um curto passo ao aprendizado. Neste artigo veremos desde conceitos de configuraçăo, ambiente, características, posicionamento atual, até o as vantagens da programaçăo assíncrona, foco central que discute como implementar um bom código que evite a criaçăo do famoso anti-patter callback-hell do JavaScript.
Guia do artigo:
Tudo na web se trata de consumismo e produçăo de conteúdo. Ler ou escrever blogs, assistir ou enviar vídeos, ver ou publicar fotos, ouvir músicas e assim por diante.
Isso fazemos naturalmente todos os dias na internet. E cada vez mais aumenta a necessidade dessa interaçăo entre os usuários com os diversos serviços da web.
De fato, o mundo inteiro quer interagir mais e mais na internet, seja através de conversas com amigos em chats, jogando games online, atualizando constantemente suas redes sociais ou participando de sistemas colaborativos.
Esses tipos de aplicaçőes requerem um poder de processamento extremamente veloz para que seja eficaz a interaçăo em tempo real entre cliente e servidor.
E mais, isto precisa acontecer em uma escala massiva, suportando de centenas a milhőes de usuários.
Entăo o que nós, desenvolvedores, precisamos fazer? Precisamos criar uma comunicaçăo em tempo real entre cliente e servidor — que seja rápida, atenda muitos usuários ao mesmo tempo e utilize recursos de I/O (dispositivos de entrada e saída) de forma eficiente. Qualquer pessoa com experięncia em desenvolvimento web sabe que a versăo atual do HTTP 1.1 năo foi projetada para suportar tais requisitos.
E pior, infelizmente existem aplicaçőes que adotam de forma incorreta o uso deste protocolo, implementando soluçőes workaround ("Gambiarras") que requisitam constantemente o servidor de forma assíncrona, geralmente aplicando a técnica de long-polling.
Para sistemas trabalharem em tempo real, servidores precisam enviar e receber dados utilizando comunicaçăo bidirecional, ao invés de utilizar intensamente request/response do HTTP aplicando Ajax. E também temos que manter esse tipo comunicaçăo de forma leve e rápida para permitir escalabilidade em uma aplicaçăo.
Os sistemas para web desenvolvidos sobre plataformas como .NET, Java, PHP, Ruby ou Python possuem uma característica em comum: eles paralisam um processamento enquanto utilizam um I/O no servidor. Essa paralisaçăo é conhecida como modelo blocking-thread.
Para entender melhor esse conceito, vamos a um exemplo: temos uma aplicaçăo web e nela cada processo é uma requisiçăo feita pelo usuário.
Com o decorrer da aplicaçăo, novos usuários irăo acessá-la, gerando múltiplos processos no servidor. Um sistema de arquitetura bloqueante vai enfileirar cada requisiçăo que săo realizadas ao mesmo tempo e depois ele vai processando, uma a uma.
Este modelo năo permite múltiplos processamentos ao mesmo tempo. Enquanto uma requisiçăo é processada, as demais ficam em espera, ou seja, a aplicaçăo bloqueia os demais processos de fazer I/O no servidor, mantendo-os em um pequeno período de tempo numa fila de requisiçőes ociosas.
Esta é uma arquitetura clássica, existente em diversos sistemas web e que possui um design ineficiente. É gasta grande parte do tempo mantendo requisiçőes em uma fila ociosa enquanto é executado I/O para apenas uma requisiçăo. Para exemplificar melhor, tarefas de I/O săo tarefas de enviar e-mail, consultar o banco de dados, leitura de arquivos em disco.
E essas tarefas bloqueiam o sistema inteiro enquanto năo săo finalizadas. Com o aumento de usuários acessando o sistema, a frequęncia de gargalos será maior, surgindo a necessidade de se fazer uma escalabilidade vertical (upgrade dos servidores) ou escalabilidade horizontal (inclusăo de novos servidores trabalhando para um load balancer). Ambos os tipos se tornam custosos, quando se fala em gastos com infraestrutura.
O ideal seria buscar novas tecnologias que façam bom uso dos servidores existentes, que permitam o uso intenso e máximo do processamento atual.
Foi baseado neste problema que, no final de 2009, Ryan Dahl, e mais 14 colaboradores, criaram o Node.js. Esta tecnologia possui um modelo inovador: sua arquitetura é totalmente non-blocking thread (năo-bloqueante) que apresenta uma boa performance com consumo de memória e utiliza ao máximo e de forma eficiente o poder de processamento dos servidores, principalmente em sistemas que produzem uma alta carga de processamento.
Sistemas criados com Node.js estăo livres de aguardarem por muito tempo o resultado de seus processos, e mais importante, năo sofrem dead-locks, pelo simples fato de trabalharem em single-thread. Além dessas vantagens, desenvolver sistemas nessa plataforma é super simples e prático.
O Node.js é uma plataforma altamente escalável e de baixo nível, logo, vocę terá a possibilidade de programar diretamente com diversos protocolos de rede e internet ou utilizar bibliotecas que acessam recursos do sistema operacional. Para programar em Node.js basta dominar a linguagem JavaScript. Ele utiliza a engine Javascript V8, a mesma utilizada no navegador Google Chrome.
Suas aplicaçőes serăo single-thread, ou seja, cada aplicaçăo terá instância de uma única thread por processo iniciado. Se vocę está acostumado a trabalhar com programaçăo multithread, por exemplo, Java ou .NET, infelizmente năo será possível com Node.js, mas saiba que existem outras maneiras de se criar um sistema que com processamento paralelo.
Por exemplo, vocę pode utilizar uma biblioteca nativa chamada de clusters, que é um módulo que permite implementar uma rede de processos de sua aplicaçăo, vocę cria N processos de sua aplicaçăo e uma delas se encarrega de balancear a carga, permitindo processamentos paralelos um único servidor. Outra maneira é adotar a programaçăo assíncrona nas tarefas se seu servidor.
Esse será o assunto mais abordado durante o decorrer deste artigo, pelo qual explicaremos diversos cenários e exemplos práticos de como săo executadas em paralelo, funçőes em assíncronas năo-bloqueante.
Node.js é orientado a eventos. Ele segue a mesma filosofia de orientaçăo de eventos do JavaScript de browser; a única diferença săo os eventos, ou seja, năo existem eventos de click do mouse, keyup do teclado ou qualquer evento de componentes do HTML.
Na verdade, trabalhamos com eventos de I/O como, por exemplo, o evento connect de um banco de dados, um open de um arquivo, um data de um streaming de dados e muitos outros.
O Event-Loop é o agente responsável por escutar e emitir eventos. Na prática, ele é basicamente um loop infinito que a cada iteraçăo verifica em sua fila de listening de eventos se um determinado evento foi disparado. Quando ocorre, é emitido um evento. Ele o executa e envia para fila de executados.
Quando um evento está em execuçăo, nós podemos programar qualquer lógica dentro dele e isso tudo acontece graças ao mecanismo de callback de funçăo do JavaScript.
Esta técnica que permite trabalhar em cima do design event-driven com Node.js. Ele foi inspirado pelos frameworks Event Machine do Ruby e Twisted do Python. Porém, o Event-loop do Node.js é mais performático por que seu mecanismo é nativamente executado de forma năo-bloqueante.
Isso faz dele um grande diferencial em relaçăo aos seus concorrentes que realizam chamadas bloqueantes para iniciar seus respectivos loops de eventos.
JavaScript everywhere: Praticamente o Node.js usa JavaScript como linguagem de programaçăo server-side. Essa característica permite que vocę reduza e muito sua curva de aprendizado, afinal a linguagem é a mesma do JavaScript client-side, seu desafio nesta plataforma será de aprender a fundo como funciona a programaçăo assíncrona para se tirar maior proveito dessa técnica em sua aplicaçăo.
Outra vantagem de se trabalhar com JavaScript é que vocę poderá manter um projeto de fácil manutençăo. Vocę terá facilidade em procurar profissionais para seus projetos, e vai gastar menos tempo estudando uma nova linguagem server-side. Uma vantagem técnica do JavaScript comparador com outras linguagens de back-end é que vocę năo irá utilizar mais aqueles frameworks de serializaçăo de objetos JSON (JavaScript Object Notation), afinal o JSON client-side é o mesmo no server-side, há também casos de aplicaçőes usando banco de dados orientado a documentos (por exemplo: MongoDB ou CouchDB) e neste caso toda manipulaçăo dos dados săo realizadas através de objetos JSON também.
Comunidade ativa: Esse é um dos pontos mais fortes do Node.js. Atualmente existem várias comunidades no mundo inteiro trabalhando muito para esta plataforma, seja divulgando posts e tutoriais, palestrando em eventos e principalmente publicando e mantendo +70000 módulos no site NPM (Node Package Manager). Aqui no Brasil temos dois grupos bem ativos no Google Groups temos o NodeBR e no Facebook tem o grupo Node.js Brasil (ver seçăo Links).
Ótimos salários: Desenvolvedores Node.js geralmente recebem bons salários. Isso ocorre pelo fato de que infelizmente no Brasil ainda existem poucas empresas adotando essa tecnologia. Isso faz com que empresas que necessitem dessa tecnologia paguem salários na média ou acima da média para manterem esses desenvolvedores em seus projetos.
Outro caso interessante săo as empresas que contratam estagiários ou programadores juniores que tenham ao menos conhecimentos básicos de JavaScript, com o objetivo de treiná-los para trabalhar com Node.js. Neste caso, năo espere um alto salário e sim um amplo conhecimento preenchendo o seu currículo.
Ready for real-time: O Node.js ficou popular graças aos seus frameworks de interaçăo real-time entre cliente e servidor. O SockJS, Socket.IO, Engine.IO săo alguns exemplos disso. Eles săo compatíveis com o recente protocolo WebSockets e permitem trafegar dados através de uma única conexăo bidirecional, tratando todas as mensagens através de eventos JavaScript.
Big players: LinkedIn, Wallmart, Groupon, Microsoft e Paypal săo algumas das empresas usando Node.js atualmente, no Brasil conheço algumas empresas por exemplo: Agendor, Sappos, Neoassist e tem mais um monte de outras empresas e projetos (veja na seçăo Links).
Saiba mais Série Programe com o Node.jsUm chat é o mais típico exemplo de aplicaçăo multi-usuário em tempo real. Desde IRC até muitos protocolos proprietários e abertos sobre portas năo-padrăo, até mesmo a habilidade de implementar tudo hoje no Noje.js com websockets rodando sobre a mesma porta padrăo 80.
A aplicaçăo de chat é realmente é um ótimo exemplo de ser usada com Noje.js: é leve, tem alto tráfico de dados, porém exige pouco processamento/computaçăo e que executa dentre vários dispositivos.
Além de tudo, é bem simples, ótimo para os desenvolvedores que estăo iniciando o aprendizado na tecnologia, cobrindo a maior parte dos paradigmas usados pela linguagem. Basicamente, uma aplicaçăo desse tipo funciona dentro de um domínio de website já pronto onde as pessoas podem ir e efetuar a troca de mensagens entre si conectados por uma estrutura de programaçăo e redes. No lado do servidor, temos uma aplicaçăo simples que implementa duas coisas:
· Uma requisiçăo GET que serve a página web contendo ambas mensagem e botăo de enviar para inicializar uma nova entrada de mensagem;
· Websockets que escutam por novas mensagens emitidas pelos seus clientes.
No lado cliente nós temos uma página HTML com uma série de handlers configurados, um para o botăo de Envio, que seleciona a mensagem e a envia para o websocket, e outro que escuta por mensagens que estăo chegando no cliente. Obviamente, este é um modelo simples e básico, mas que baseia os demais em variância ŕs suas complexidades.
Embora o Node.js realmente brilhe com aplicaçőes em tempo real, é natural ter que expor os dados a partir de um objeto de banco de dados (MongoDB, por exemplo). Dados JSON armazenados permitem que o Node.js funcione sem a diferença de impedância e conversăo de dados.
Por exemplo, se vocę estiver usando Rails, vocę deve converter JSON para modelos binários e em seguida, expô-los de volta como JSON sobre o HTTP quando os dados săo consumidos por frameworks como o Backbone.js, Angular.js, etc., ou mesmo por simples chamadas jQuery Ajax.
Com o Node.js, vocę pode simplesmente expor seus objetos JSON com uma API REST para o cliente a consumir. Além disso, vocę năo precisa se preocupar com a conversăo entre JSON e tudo aquilo que for ler ou escrever em seu banco de dados (se estiver usando MongoDB). Em suma, vocę pode evitar a necessidade de múltiplas conversőes usando um formato de serializaçăo de dados uniforme em todo o cliente e servidor de banco de dados.
Se vocę está recebendo uma grande quantidade de dados simultâneos, o banco de dados pode se tornar um gargalo. O Node.js pode facilmente lidar com as próprias conexőes simultâneas. Mas porque o acesso a bancos de dados é uma operaçăo bloqueante, nos depararemos certamente com problemas. A soluçăo é reconhecer o comportamento do cliente antes de os dados serem realmente gravados na base de dados.
Com essa abordagem, o sistema mantém a sua capacidade de resposta sob uma carga pesada, o que é particularmente útil quando o cliente năo precisa de confirmaçăo firme de uma gravaçăo de dados bem-sucedida.
Exemplos típicos incluem: o registro ou gravaçăo de dados de rastreamento de usuário, com processamento em lotes e năo utilizados até mais tarde; bem como operaçőes que năo precisam ser refletidas instantaneamente (como a atualizaçăo de um count 'Likes' no Facebook), onde a consistęncia eventual (tantas vezes usada no mundo NoSQL) é aceitável.
Os dados săo colocados em fila por algum tipo de cache ou enfileiramento de mensagens de infraestrutura (por exemplo, RabbitMQ, ZeroMQ) e digerido por um processo de banco de dados separado em lotes e escrita, ou computaçăo intensiva de serviços de processamento de back-end, escrito em uma plataforma de melhor desempenho para tais tarefas. Comportamento semelhante pode ser implementado com outras linguagens/frameworks, mas năo no mesmo hardware, com o mesmo alto rendimento mantido.
Em plataformas mais tradicionais da web, solicitaçőes e respostas HTTP săo tratadas como eventos isolados; na verdade, eles săo realmente streams. Esta observaçăo pode ser utilizada no Node.js para construir alguns recursos interessantes.
Por exemplo, é possível processar arquivos enquanto eles ainda estăo sendo carregados, uma vez que os dados vęm no meio de um stream e podemos processá-los de forma online. Isso poderia ser feito para áudio em tempo real ou codificaçăo de vídeo e proxy entre as diferentes fontes de dados.
O Node.js é facilmente utilizado como um proxy do lado do servidor, onde ele pode lidar com uma grande quantidade de conexőes simultâneas de uma maneira non-blocking.
É especialmente útil para proxys de diferentes serviços com diferentes tempos de resposta ou a coleta de dados a partir de vários pontos de origem.
Considere como exemplo um aplicativo que do lado do servidor se comunica com recursos de terceiros, puxando dados de diferentes fontes ou armazenando ativos como imagens e vídeos para serviços em nuvem de terceiros.
Embora existam servidores proxy dedicados, utilizando Node.js, ao invés, pode ser útil se a sua infraestrutura de proxy é inexistente ou se vocę precisa de uma soluçăo para o desenvolvimento local. Por isso, vocę pode construir um aplicativo do lado do cliente com um servidor de desenvolvimento Node.js para ativos e solicitaçőes de proxy/Stubbing API, enquanto em produçăo vocę lidaria com tais interaçőes com um serviço dedicado de proxy (nginx, HAProxy, etc.).
Outro caso de uso comum, em que o Node com websockets se encaixa perfeitamente é o rastreamento de visitantes do site e visualizaçăo de suas interaçőes em tempo real.
Vocę poderia reunir estatísticas em tempo real a partir de seu usuário, ou mesmo movę-lo para o próximo nível através da introduçăo de interaçőes específicas com seus visitantes, abrindo um canal de comunicaçăo quando chegam a um ponto específico no seu filtro.
Imagine como é possível melhorar um dado negócio, se for possível saber o que os visitantes estavam fazendo em tempo real, se for possível visualizar suas interaçőes. Com o tempo real, nos dois sentidos bases de Node.js, agora é possível.
Agora, vamos visitar o lado da infraestrutura das coisas. Imagine, por exemplo, um provedor de SaaS que quer oferecer a seus usuários uma página de serviço de monitoramento (por exemplo, página de status do GitHub). Com o evento de circuito Node.js, podemos criar um poderoso painel baseado na web que verifica os estados dos serviços de forma assíncrona e envia dados para os clientes que usam websockets.
Tanto interna quanto os status dos serviços públicos podem ser relatados ao vivo e em tempo real, utilizando esta tecnologia.
Indo um pouco além com essa ideia e tentando imaginar um Centro de Operaçőes de Rede (NOC) aplicaçőes de monitoramento em um operador de telecomunicaçőes, nuvem/rede/provedor de hospedagem, ou alguma instituiçăo financeira, todos executados na pilha web aberta apoiada pelo Node.js e websockets em vez de Java e/ou Java Applets, como foi visto por muito tempo.
Para configurar um ambiente Node.js, independente de qual sistema operacional, as dicas serăo as mesmas. Somente alguns procedimentos serăo diferentes para cada sistema, principalmente para o Windows, mas năo será nada grave.
O primeiro passo é acessar seu site oficial (ver seçăo Links). Em seguida, clique em Install para baixar automaticamente a última versăo compatível com seu sistema operacional (isto é se seu sistema é Windows ou MacOS).
Caso vocę use Linux recomendo que leia em detalhes a Wiki do repositório Node.js (ver na seçăo Links), pois lá é explicado as principais instruçőes sobre como instalá-lo através de um package manager de uma distribuiçăo Linux.
Agora instale-o e caso năo ocorra problemas, basta abrir seu terminal ou prompt de comandos e digite o seguinte comando para ver as respectivas versőes do Node.js e NPM que foram instaladas:
node -v && npm -vA última versăo estável que está sendo utilizada neste artigo é Node v0.10.31 e NPM 1.4.23.
Para configurar o ambiente de desenvolvimento basta adicionar a variável de ambiente NODE_ENV no sistema operacional. Em sistemas Linux ou MacOS, basta acessar com um editor de texto qualquer e em modo super user (sudo) o arquivo .bash_profile ou .bashrc e no final do arquivo adicione a seguinte linha de comando:
export NODE_ENV=’development’
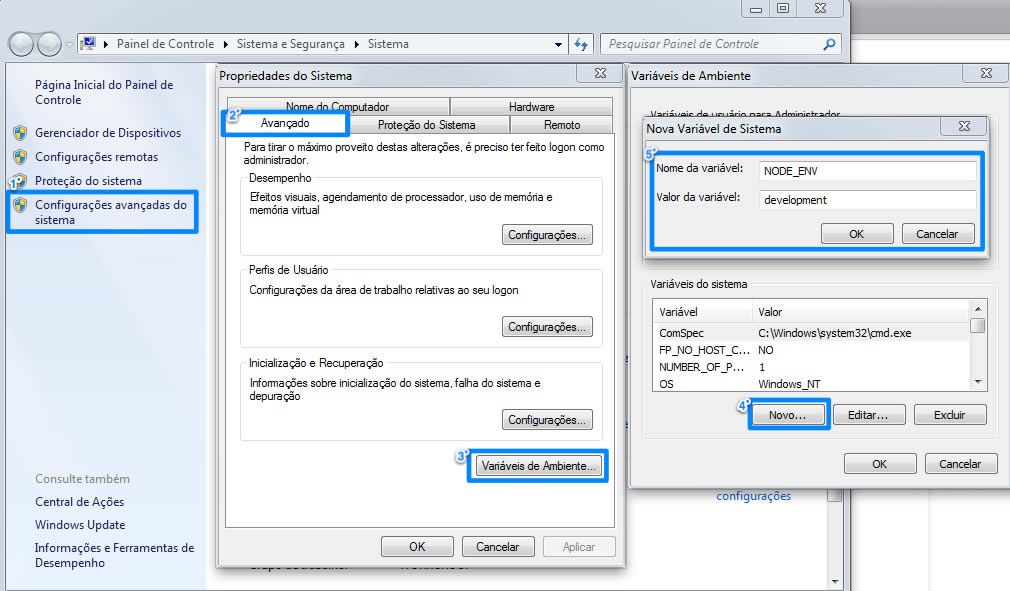
Clique com botăo direito no ícone Meu Computador e selecione a opçăo Propriedades e no lado esquerdo da janela clique no link Configuraçőes avançadas do sistema. Na janela seguinte, acesse a aba Avançado e clique no botăo Variáveis de Ambiente….
Agora no campo Variáveis do sistema clique no botăo Novo… e no campo nome da variável digite NODE_ENV e no campo valor da variável digite development, tal como demonstrado na Figura 1. Após finalizar essa tarefa, reinicie seu computador para carregar essa variável automaticamente no sistema operacional.
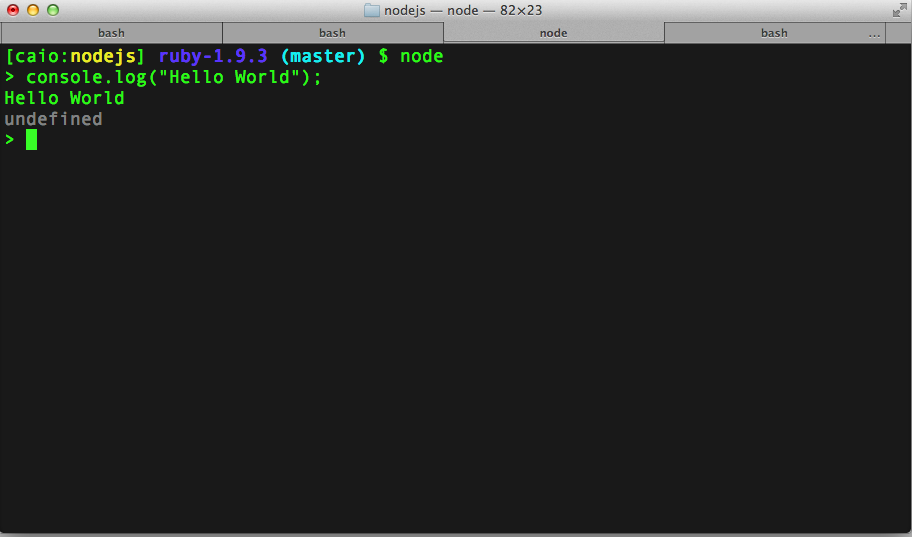
Para testarmos o ambiente, executaremos o nosso primeiro programa de Hello World. Abra seu terminal ou prompt de comando e execute o comando node. Este comando vai acessar o modo REPL (Read-Eval-Print-Loop) que permite executar códigos JavaScriptdiretamente pela tela preta. Agora digite console.log(“Hello World”) e tecle ENTER para executá-lo na hora (Figura 2).
Assim como o RubyGems do Ruby ou o Maven do Java, o Node.js também possui seu próprio gerenciador de pacotes, ele se chama NPM. Ele se tornou tăo popular pela comunidade, que foi a partir da versăo 0.6.X que foi integrado no instalador do Node.js, tornando-se o gerenciador padrăo desta plataforma.
Isto simplificou a vida dos desenvolvedores na época, pois fez com que diversos projetos se convergissem para esta plataforma até os dias de hoje. Utilizar o NPM é muito fácil, entăo vejamos os comandos principais para que vocę tenha noçőes de como usá-los:
Todo projeto Node.js é chamado de módulo, mas o que é um módulo? No decorrer da leitura, perceba que vamos discutir muito sobre o termo módulo, biblioteca e framework, e, na prática, eles possuem o mesmo significado.
O termo módulo surgiu do conceito de que o JavaScript trabalha com uma arquitetura modular. E todo módulo é acompanhado de um arquivo descritor, conhecido pelo nome de package.json.
Este arquivo é essencial para um projeto Node.js. Um package.json mal escrito pode causar bugs ou impedir o funcionamento correto do seu módulo, pois ele possui alguns atributos chaves que săo compreendidos pelo Node.js e NPM.
Na Listagem 1 temos um package.json que contém os principais atributos para descrever um módulo.
Listagem 1. Formato de um package.json.
{
"name": "meu-primero-node-app",
"description": "Meu primeiro app Node.js",
"author": "Caio <caio@email.com>",
"version": "1.2.3",
"private": true,
"dependencies": {
"modulo-1": "1.0.0",
"modulo-2": "~1.0.0",
"modulo-3": ">=1.0.0"
},
"devDependencies": {
"modulo-4": "*"
}
}Com esses atributos, vocę já descreve o mínimo possível o que será sua aplicaçăo. O atributo name é o principal. Com ele, vocę descreve o nome do projeto, nome pelo qual seu módulo será chamado via funçăo require('meu-primeiro-node-app'). Em description, descrevemos o que será este módulo. Ele deve ser escrito de forma curta e clara, fornecendo um resumo do módulo.
O author é um atributo para informar o nome e e-mail do autor. Utilize o formato Nome <email> para que sites como npm reconheça corretamente esses dados. Outro atributo principal é o version, com o qual definimos a versăo atual do módulo. É extremamente recomendado que tenha este atributo, se năo será impossível instalar o módulo via comando npm.
O atributo private é um booleano, e determina se o projeto terá código aberto ou privado para download no npm.
Os módulos no Node.js trabalham com tręs níveis de versionamento. Por exemplo, a versăo 1.2.3 está dividida nos níveis: Major (1), Minor (2) e Patch (3).
Repare que no campo dependencies foram incluídos 4 módulos, sendo que cada um utilizou uma forma diferente de definir a versăo do projeto. O primeiro, o modulo-1, somente será incluído sua versăo fixa, a 1.0.0. Utilize este tipo versăo para instalar dependęncias cuja atualizaçőes possam quebrar o projeto pelo simples fato de que certas funcionalidades foram removidas e ainda as utilizamos na aplicaçăo.
O segundo módulo já possui uma certa flexibilidade de update. Ele utiliza o caractere "~" que faz atualizaçőes a nível de patch (1.0.x). Geralmente essas atualizaçőes săo seguras, trazendo apenas melhorias ou correçőes de bugs.
O modulo-3 atualiza versőes que sejam maior ou igual a 1.0.0 em todos os níveis de versăo. Em muitos casos, utilizar ">=" pode ser perigoso, porque a dependęncia pode ser atualizada a nível major ou minor, contendo grandes modificaçőes que podem quebrar um sistema em produçăo, comprometendo seu funcionamento e exigindo que vocę atualize todo código até voltar ao normal.
O último, o modulo-4, utiliza o caractere "*"; este sempre pegará a última versăo do módulo em qualquer nível. Ele também pode causar problemas nas atualizaçőes e tem o mesmo comportamento do versionamento do modulo-3.
Geralmente ele é utilizado em devDependencies, que săo dependęncias focadas para testes ou de uso exclusivo para ambiente de desenvolvimento, e as atualizaçőes dos módulos năo prejudicam o comportamento do sistema que já está no ar.
Assim como no browser, utilizamos o mesmo JavaScript no Node.js. Ele também utiliza escopos locais e globais de variáveis. A única diferença é na forma como săo implementados os escopos de variáveis globais. No browser, as variáveis globais săo criadas da forma como pode ser vista na Listagem 2.
Listagem 2. Variáveis globais no client-side.
window.hoje = new Date();
alert(window.hoje);Em qualquer browser, a palavra-chave window permite criar variáveis globais que săo acessadas em qualquer lugar. Já no Node.js, utilizamos a palavra-chave global para aplicar essa mesma técnica (Listagem 3).
Listagem 3. Variáveis globais no server-side do Node.js.
global.hoje = new Date();
console.log(global.hoje);Ao utilizar global mantemos uma variável global, acessível em qualquer parte do projeto sem a necessidade de chamá-la via require ou passá-la por parâmetro em uma funçăo. Esse conceito de variável global é existente na maioria das linguagens de programaçăo, assim como sua utilizaçăo, portanto é recomendado trabalhar com o mínimo possível de variáveis globais para evitar futuros gargalos de memória na aplicaçăo.
O Node.js utiliza nativamente o padrăo CommonJS para organizaçăo e carregamento de módulos. Na prática, diversas funçőes deste padrăo serăo utilizadas com frequęncia em um projeto Node.js. A funçăo require('nome-do-modulo') é um exemplo disso, ela carrega um módulo. E para criar um código modular, carregável pela funçăo require, utilizam-se as variáveis globais: exports ou module.exports.
Veja nas listagens a seguir dois exemplos de módulos para Node.js. Primeiro, crie o código hello.js (Listagem 4) e depois crie o código human.js (Listagem 5).
Listagem 4. Criando um módulo com module.exports.
module.exports = function(msg) {
console.log(msg);
};Listagem 5. Criando um módulo com exports.
exports.hello = function(msg) {
console.log(msg);
};A diferença entre o hello.js e o human.js está na maneira como eles serăo carregados. Em hello.js carregamos uma única funçăo modular, e em human.js é carregado um objeto com funçőes modulares. Essa é a grande diferença entre eles. Para entender melhor na prática, crie o código app.js para carregar esses módulos:
var hello = require('./hello');
var human = require('./human');
hello('Olá pessoal!');
human.hello('Olá galera!');
Tenha certeza de que esses módulos hello.js, human.js e app.js estăo na mesma pasta, e em seguida, rode o comando:
node app.js
E entăo, o que aconteceu? O resultado foi praticamente o mesmo: o app.js carregou os módulos hello.js e human.js via funçăo require(), em seguida foi executada a funçăo hello("Olá pessoal!”) que imprimiu a mensagem "Olá pessoal!" e, por último, o objeto human executou sua funçăo human.hello('Olá galera!').
Um detalhe final é que também é possível criar um objeto com funçăo modular usando module.exports, apenas faça com que o módulo retorne um objeto com funçőes públicas, semelhante ao código da Listagem 6.
Listagem 6. Emulando o comportamento das funçőes exports usando module.exports.
module.exports = function() {
return {
hello: function(msg) {
console.log(msg);
}
};
};E assim vocę terá um módulo com mesmo comportamento do human.hello(“olá").
Agora vamos para a última parte do nosso artigo. Agora que já temos uma base sobre o que é e como usar o Node.js, vamos focar em aprender boas práticas sobre funçőes assíncronas. Afinal este é o paradigma principal desta plataforma, e é muito importante dominar esses conceitos para se tirar melhor proveito desta tecnologia, assim como entender como funciona funçőes assíncronas.
O código a seguir exemplifica as diferenças entre uma funçăo síncrona e assíncrona em relaçăo ŕ linha do tempo na qual elas săo executadas. Basicamente, criaremos um loop de cinco iteraçőes, sendo que a cada iteraçăo será criado um arquivo texto com o mesmo conteúdo "Hello Node.js!". Primeiro vamos começar com o código síncrono. Crie o arquivo text_sync.js com o código da Listagem 7.
Listagem 7. Escrevendo arquivo de texto de forma síncrona.
var fs = require('fs');
for(var i = 1; i <= 5; i++) {
var file = "sync-txt" + i + ".txt";
fs.writeFileSync(file, "Hello Node.js!");
console.log("Criando arquivo: " + file);
}Agora vamos criar o arquivo text_async.js, com seu respectivo código, diferente apenas na forma de chamar a funçăo fs.writeFileSync, que será a versăo assíncrona fs.writeFile, pelo qual seu retorno de sucesso acontece através da execuçăo de uma funçăo de callback existente no terceiro argumento da funçăo (Listagem 8).
Listagem 8. Escrevendo arquivo de texto de forma assíncrona.
var fs = require('fs');
for(var i = 1; i <= 5; i++) {
var file = "async-txt" + i + ".txt";
fs.writeFile(file, "Hello Node.js!", function(err, out) {
console.log("Criando arquivo: " + file);
});
}Execute os comandos node text_sync.js e depois node text_async.js. Se forem gerados 10 arquivos no mesmo diretório do código-fonte, entăo deu tudo certo. Mas a execuçăo de ambos foi tăo rápida que năo foi possível visualizar as diferenças entre o text_async.js e o text_sync.js.
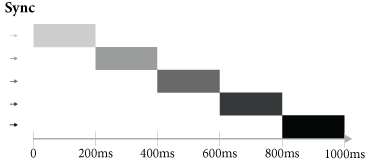
Para entender melhor as diferenças, veja os gráficos hipotéticos a seguir que ocorrem quando executamos esses módulos. O text_sync.js, por ser um código síncrono, invocou chamadas de I/O bloqueantes e gerou o gráfico da Figura 3.
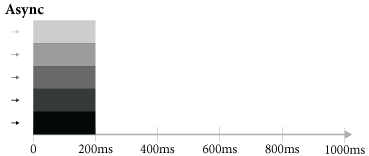
Repare no tempo de execuçăo, o text_sync.js hipoteticamente demorou 1000 milissegundos, isto é, 200 milissegundos para cada escrita de arquivo. Já em text_async.js foram criados os arquivos de forma totalmente assíncrona, ou seja, as chamadas de I/O eramnăo-bloqueantes, e isso permitiu escreverarquivos em paralelo, como naFigura 4.
Isto fez com que o tempo de execuçăo levasse hipoteticamente 200 milissegundos, afinal foi invocada cinco vezes, em paralelo, a funçăo fs.writeFile, e isso maximizou o uso de processamento e I/O e minimizou o tempo de execuçăo.
Só para finalizar esse gráfico é apenas hipotético, e foi usado para exemplificar como funciona o assincronismo do Node.js, nem sempre um conjunto de funçőes assíncronas văo executar em paralelo de forma tăo perfeita como foi apresentado nesses gráficos.
Por mais que as funçőes assíncronas possam executar em paralelo várias tarefas, elas jamais serăo consideradas uma Thread (por exemplo as Threads do Java). A diferença é que Threads săo manipuláveis pelo desenvolvedor, ou seja, vocę pode pausar a execuçăo de uma Thread ou fazę-la esperar o término de uma outra Thread para ser executada.
Chamadas assíncronas apenas invocam suas funçőes em e vocę năo controla elas, apenas trabalha com seus retornos através de uma funçăo callback.
Pode parecer vantajoso ter o controle sobre a execuçăo de Threads a favor de um sistema que executa tarefas em paralelo, mas pouco conhecimento sobre eles pode transformar seu sistema em um caos de travamentos de dead-locks, afinal elas săo executadas de forma bloqueante.
Este é o grande diferencial das chamadas assíncronas, elas executam em paralelo suas funçőes sem travar processamento das outras e, principalmente, sem bloquear a aplicaçăo.
É fundamental que o seu código Node.js invoque o mínimo possível de funçőes bloqueantes. Toda funçăo síncrona impedirá, naquele instante, que o Node.js continue executando os demais códigos até que aquela funçăo seja finalizada.
Por exemplo, se essa funçăo fizer um I/O em disco, ele vai bloquear o sistema inteiro, deixando o processador ocioso enquanto ele utiliza outros recursos do servidor, como por exemplo leitura em disco, utilizaçăo da rede etc. Sempre que puder, utilize funçőes assíncronas para aproveitar essa característica principal do Node.js.
Caso vocę ainda năo esteja convencido sobre as vantagens do processamento assíncrono vou lhe mostrar como e quando utilizar bibliotecas assíncronas năo-bloqueantes através de um teste prático.
Para exemplificar melhor, os códigos adiante representam um benchmark comparando o tempo de bloqueio de execuçăo assíncrona vs síncrona. Para isso, crie tręs arquivos: processamento.js, leitura_async.js e leitura_sync.js. Criaremos isoladamente o módulo leitura_async.js que será responsável por fazer leitura assíncrona de arquivo grande, tal como na Listagem 9.
Listagem 9. Código de benchmark de tempo de bloqueio em leitura assíncrona.
var fs = require('fs');
var leituraAsync = function(arquivo){
console.log("Fazendo leitura assíncrona");
var inicio = new Date().getTime();
fs.readFile(arquivo);
var fim = new Date().getTime();
console.log("Bloqueio assíncrono: "+(fim - inicio)+ "ms");
};
module.exports = leituraAsync;Em seguida, crie o módulo leitura_sync.js, que realizará leitura síncrona no mesmo arquivo (Listagem 10).
Listagem 10. Código de benchmark de tempo de bloqueio em leitura síncrona.
var fs = require('fs');
var leituraSync = function(arquivo){
console.log("Fazendo leitura síncrona");
var inicio = new Date().getTime();
fs.readFileSync(arquivo);
var fim = new Date().getTime();
console.log("Bloqueio síncrono: "+(fim - inicio)+ "ms");
};
module.exports = leituraSync;Para finalizar, vamos carregar esses módulos dentro do código processamento.js. Basicamente este módulo principal vai fazer download da última versăo do instalador Node.js que tem em média 7 MB de tamanho. Quando o download terminar ele vai enviar o arquivo para os módulos realizarem uma leitura de conteúdo, no término de cada leitura será apresentado o tempo de bloqueio que cada módulo obteve, como observado através da Listagem 11.
Listagem 11. Código de execuçăo do benchmark síncrono vs assíncrono.
var http = require('http');
var fs = require('fs');
var leituraAsync = require('./leitura_async');
var leituraSync = require('./leitura_sync');
var arquivo = "./node.exe";
var stream = fs.createWriteStream(arquivo);
var download = "http://nodejs.org/dist/latest/x64/node.exe";
http.get(download, function(res) {
console.log("Fazendo download do Node.js");
res.on('end', function(){
console.log("Download finalizado!");
console.log("Executando benchmark sync vs async...");
leituraAsync(arquivo);
leituraSync(arquivo);
});
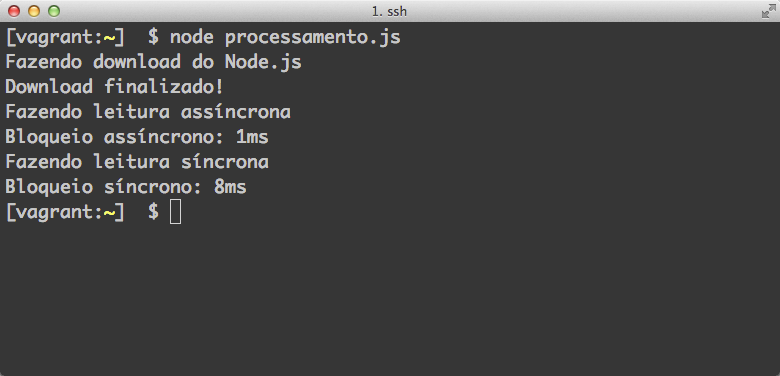
});Rode o comando node processamento.js para executar o benchmark. E agora, ficou clara a diferença entre o modelo bloqueante e o năo-bloqueante? Parece que o módulo leituraAsync executou muito rápido, mas năo quer dizer que o arquivo foi lido. Ele recebe um último parâmetro, que é um callback indicando quando o arquivo foi lido, que năo passamos na invocaçăo que fizemos.
Ao usar o fs.readFileSync(), bastaria fazer var conteudo = fs.readFileSync(). Mas qual é o problema dessa abordagem? Ela bloqueia todo o processamento da aplicaçăo! Somente quando o bloqueio terminar as demais linhas de código serăo executadas, em contra partida o fs.readFile() continua executando qualquer código que năo estiver dentro de seu callback, entăo com isso vocę pode, por exemplo, programar sua aplicaçăo para fazer outras tarefas em paralelo.
A seguir, temos o resultado do benchmark realizado em na máquina que possui as seguintes configuraçőes:
Veja a pequena, porém significante, diferença de tempo entre as duas funçőes de leitura realizada na máquina (Figura 5).
De fato, vimos o quanto é vantajoso e performático trabalhar de forma assíncrona, porém, em certos momentos, inevitavelmente implementaremos diversas funçőes assíncronas, que serăo encadeadas uma na outra através de suas funçőes callback. No código da Listagem 12 vemos um exemplo desse caso.
Listagem 12. Exemplo de Callback Hell.
var fs = require('fs');
fs.readdir(__dirname, function(erro, contents) {
if (erro) { throw erro; }
contents.forEach(function(content) {
var path = './' + content;
fs.stat(path, function(erro, stat) {
if (erro) { throw erro; }
if (stat.isFile()) {
console.log('%s %d bytes', content, stat.size);
}
});
});
});Reparem na quantidade de callbacks encadeados que existem em nosso código. Detalhe: ele apenas faz uma simples leitura dos arquivos de seu diretório e imprime na tela seu nome e tamanho em bytes. Uma pequena tarefa como essa deveria ter menos encadeamentos, concorda? Agora, imagine como seria a organizaçăo disso para realizar tarefas mais complexas? Praticamente o seu código seria um caos e totalmente difícil de fazer manutençőes.
Por ser assíncrono, vocę perde o controle do que está executando em troca de ganhos com performance, porém, um detalhe importante sobre assincronismo é que, na maioria dos casos, os callbacks bem elaborados possuem como parâmetro uma variável de erro.
Verifique nas documentaçőes sobre sua existęncia e sempre faça o tratamento deles na execuçăo do seu callback: if (erro) { throw erro; }. Isso vai impedir a continuaçăo da execuçăo aleatória quando for identificado um erro.
Uma boa prática de código JavaScript é criar funçőes que expressem seu objetivo e de forma isoladas, salvando em variável e passando-as como callback. Ao invés de criar funçőes anônimas, por exemplo, crie um arquivo chamado callback_heaven.js com o código da Listagem 13.
Listagem 13. Minimizando callback hell declarando funçőes em variáveis.
var fs = require('fs');
var lerDiretorio = function() {
fs.readdir(__dirname, function(erro, diretorio) {
if (erro) return erro;
diretorio.forEach(function(arquivo) {
ler(arquivo);
});
});
};
var ler = function(arquivo) {
var path = './' + arquivo;
fs.stat(path, function(erro, stat) {
if (erro) return erro;
if (stat.isFile()) {
console.log('%s %d bytes', arquivo, stat.size);
}
});
};
lerDiretorio();Veja o quanto melhorou a legibilidade do seu código. Dessa forma deixamos mais semântico e legível o nome das funçőes e diminuímos o número de encadeamentos das funçőes de callback. A boa prática é ter o bom senso de manter no máximo até dois encadeamentos de callbacks. Ao passar disso, significa que está na hora de criar uma funçăo externa para ser passada como parâmetro nos callbacks, em vez de continuar criando um callback hell em seu código.
Muitos recursos interessantes estăo surgindo para a nova especificaçăo JavaScript conhecida por ECMAScript6 ou ES6, o Generators é um deles e seu objetivo principal é minimizar callback hell em seu código. Em resumo Generators é um recurso que permite escrever funçőes assíncronas sem callbacks, utilizando uma sintaxe de código síncrono, retornando valores da funçăo em um array que representa os possíveis parâmetros de uma funçăo callback.
Como esse recurso ainda năo é oficial, somente alguns browsers (últimas versőes do Chrome e Firefox) o utilizam no client-side. Já no server-side temos que habilitar no Node.js, porém somente existe para as versőes instáveis: 0.11.X e possivelmente será oficializada na próxima versăo estável: 0.12.x.
Observaçăo: Para utilizar uma versăo 0.11.X recomendo que faça download
e instalaçăo das versőes Nightlies do Node.js (ver na seçăo Links). Lembrando que năo recomendado
utilizar uma versăo instável em uma aplicaçăo em produçăo.
Com a versăo 0.11.X instalada em sua máquina, basta executar suas aplicaçőes utilizando a flag —harmony, por exemplo:
node --harmony app.jsCom harmony habilitado, podemos usar alguns recursos do ES6, incluindo o Generators. Porém será necessário uma instalar uma biblioteca adicional que permite trabalhar com Generators e também faz algumas magias extras. Para isso instale o módulo suspend. Antes de criarmos os códigos de Callback e Generators, instale o módulo suspend utilizando o seguinte código:
npm install suspend --saveAgora vamos a implementaçăo. A seguir temos dois códigos que fazem a mesma tarefa: ambos criam um arquivo de texto, escreve nele um timestamp e, no fim, excluir o próprio arquivo gerado. O código da Listagem 14 utiliza vários call-backs.
Listagem 14. Outro exemplo de callback hell.
var fs = require("fs");
var time = new Date().getTime();
fs.writeFile("log.txt", time, function(err) {
console.log("Iniciando log");
fs.readFile("log.txt", function(err, text) {
console.log("Timestamp: " + text);
fs.unlink("log.txt", function() {
console.log("Log finalizado");
});
});
});Na Listagem 15 temos a segunda parte do código, que é uma versăo otimizada que implementa Generators para lidar com os call-backs.
Listagem 15. Implementando Generators para minimizar callback hell.
var fs = require('fs');
var suspend = require('suspend');
var resume = suspend.resume;
var time = new Date().getTime();
suspend(function* (){
yield fs.writeFile("log.txt", time, resume());
console.log("Iniciando log");
var text = yield fs.readFile("log.txt", resume());
console.log("Timestamp" + text);
yield fs.unlink("log.txt", resume());
console.log("Log finalizado");
})();Simplesmente o encadeamento de callbacks diminuiu com Generators, e isso deixou seu código mais limpo e menos complexo.
De fato o Node.js é uma excelente opçăo para desenvolvedores front-end conhecerem um pouco sobre back-end sem precisar aprender uma nova linguagem, afinal esta plataforma o mesmo JavaScript client-side, apenas com alguns detalhes diferentes.
Outro detalhe importante é sobre as vantagens das funçőes assíncronas e seu I/O năo-bloqueante. Afinal como vimos em um benchmark, testamos uma açăo de I/O simples que fazia uma leitura de um único arquivo de mais ou menos 7 MB e o tempo de bloqueio foi muito menor do que uma leitura bloqueante.
Agora, imagine esta mesma açăo em larga escala, lendo múltiplos arquivos de 1 GB ao mesmo tempo ou realizando múltiplos I/Os em seu servidor para milhares de usuários, tudo isso sem bloquear a aplicaçăo. Esse é um dos pontos fortes do Node.js!


Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.