


Neste artigo conheceremos as formas de captura de dados existente no SQL Server 2008, através do Change Data Capture. Em seguida, demonstraremos como realizar a captura destes dados, com base em uma tabela contendo dados fictícios.
Para que serve:
Através do Change Data Capture, torna-se possível a criaçăo de um repositório ou histórico de dados, oferecendo a sua organizaçăo criar e manter uma base de conhecimento. Esta base de conhecimento deverá ajudar a estabelecer o nível de importância sobre as informaçőes manipuladas diariamente, fazendo com que os Diretores, Gerentes e Administradores avaliem o quanto esta informaçăo é importante e como ela poderá ajudar na tomada de decisăo a curto ou médio prazo.
Em que situaçăo o tema útil:
A captura de dados é uma técnica útil para ambientes que apresentam processamento diário de informaçőes. Através dos trabalhos de captura de dados, podemos criar uma organizaçăo sobre os dados manipulados, estabelecendo regras de controle e auditoria. Utilizando os recursos existentes no Change Data Capture, torna-se possível automatizar ainda mais as formas de coleta e categorizaçăo de informaçőes.
Com o passar do tempo, o volume de informaçőes armazenadas em uma tabela pode crescer de forma considerável, tornando-se um grande repositório. Este crescimento é provocado pela manipulaçăo de dados, mais precisamente por inserçőes e atualizaçőes que ocorrem constantemente em uma tabela.
Com o objetivo de analisar, identificar e documentar todas as açőes que ocorrem em um banco de dados e suas tabelas, o SQL Server 2008 apresenta uma nova funcionalidade, chamada Change Data Capture ou Captura de dados de alteraçőes.
Neste artigo apresentaremos esta nova funcionalidade, fornecida a partir das versőes Enterprise, Developer e Evaluation.
Entendendo o Change Data Capture
O Change Data Capture é considerado uma das maiores inovaçőes adicionadas ao SQL Server. Através desta funcionalidade torna-se possível realizar dois processos: o primeiro é chamado de captura dos dados alterados em tempo real e o segundo é denominado rastreamento de dados alterados.
O processo de captura de dados baseia-se na utilizaçăo dos comandos de manipulaçăo de dados (INSERT, UPDATE e DELETE), mais conhecidos como comandos DML (Data Manipulation Language). Este processo utiliza um mecanismo de identificaçăo e captura de dados chamado instância de captura de dados de alteraçăo, conforme veremos nos próximos tópicos.
Esta instância possui a finalidade de observar a execuçăo dos comandos DML e, conforme estes comandos săo processados, a instância se encarrega de gerar uma cópia para ser posteriormente armazenada em tabelas utilizadas pelo Change Data Capture.
O processo de rastreamento de dados alterados tem como finalidade pesquisar e informar quais os dados já foram alterados. Através de funçőes e stored procedures o SQL Server consegue obter estas informaçőes.
Com a utilizaçăo do Change Data Capture, o SQL Server cria um ambiente único para a realizaçăo destes dois processos, evitando a utilizaçăo de demais recursos ou técnicas complementares. Este ambiente é composto por diversos componentes específicos, como veremos aqui.
O funcionamento do Change Data Capture
O funcionamento do Change Data Capture pode ser considerado simples, tendo como base a execuçăo de comandos DML. Mas existe outro elemento muito importante que disponibiliza as informaçőes sobre os dados alterados. Este elemento é o Log de Transaçőes ou Transaction Log, existente em qualquer banco de dados, responsável por armazenar informaçőes sobre todos os procedimentos realizados.
A partir do log, o Change Data Capture identifica quais dados foram alterados, repassando estas informaçőes para o processo de captura. Este, por sua vez, repassa este mesmo dado para as tabelas utilizadas para o armazenamento de dados alterados, ou seja, uma cópia do dado é armazenada em tabelas.
Essa sequęncia de atividades é conhecida como Fluxo de Dados Processados, como pode ser visto na Figura 1.
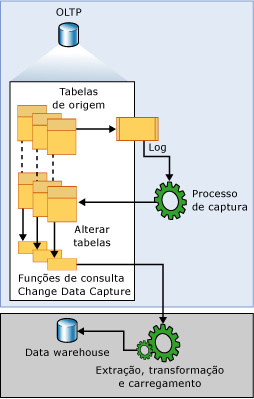
Figura 1. Fluxo de dados realizado durante o processo de captura de dados
Conforme os dados săo inseridos de forma incremental em outras tabelas ou fontes de dados externas (data mart ou data warehouse), o Change Data Capture consegue capturar o volume de informaçőes que está sendo manipulada a partir do log de transaçőes.
Se considerarmos que este processo de captura poderá ser realizado constantemente em nosso ambiente durante um período de tempo, podemos criar alguns indicadores de informaçăo que nos permitem dimensionar:
· Quantidade de linhas de registros processadas;
· Quantidade de inserçőes realizadas;
· Quantidade de atualizaçőes realizadas;
· Volume ou tamanho de dados processados, etc.
Estes indicadores podem ser informaçőes importantes para um administrador de banco de dados tomar diversas decisőes relacionadas ao processamento e consumo de recursos realizadas sobre um banco de dados ou tabela.
O processo de captura se encerra a partir do momento que as funçőes de consulta de dados utilizadas pelo Change Data Capture săo desabilitadas. Através do trabalho realizado pela instância de captura, torna-se possível catalogar e retornar informaçőes sobre os dados alterados. Estas funçőes săo conhecidas como CDC functions.
Além disso, o processo de captura de dados também pode ser aplicado em conjunto com ferramentas e tecnologias ETL durante o processo de inserçăo de dados em tabelas ou fontes de dados externas, como data warehouse ou data marts.
Os recursos utilizados pelo Change Data Capture
Para realizar os processos de captura e rastreamento de dados alterados o SQL Server utiliza alguns recursos para trabalhar com o Change Data Capture. Organizados de acordo com sua funcionalidade, săo eles:
· Tabela de Alteraçăo;
· Instância de Captura de dados;
· Tabela de Origem;
· Change Data Capture Agent.
Tabela de Alteraçăo
A tabela de alteraçăo é associada a uma tabela que está sendo utilizada pelo Change Data Capture. Ela apresenta em sua estrutura algumas particularidades para possibilitar o controle do fluxo de dados ocorrido sobre determinada tabela. Dentre estas particularidades destacamos as cinco primeiras colunas de metadados, onde cada coluna fornece informaçőes adicionais pertinentes ŕs alteraçőes registradas.
As colunas restantes espelham as colunas capturadas sobre a tabela de origem, respeitando o nome e tipo de dados de cada coluna. Cada operaçăo de inserçăo ou exclusăo que é aplicada a uma tabela de origem aparece como uma única linha dentro da tabela de alteraçăo.
As colunas de dados da linha que săo o resultado de uma operaçăo de inserçăo contęm os valores de coluna depois da inserçăo. As colunas de dados da linha que săo o resultado de uma operaçăo de exclusăo contęm valores de coluna antes da exclusăo. Uma operaçăo de atualizaçăo requer uma entrada de linha para identificar os valores da coluna antes da atualizaçăo e uma segunda entrada para identificar os valores da coluna depois da atualizaçăo.
Cada linha em uma tabela de alteraçăo também contém metadados adicionais para permitir a interpretaçăo da atividade de alteraçăo.
· A coluna __$start_lsn identifica o número da seqüęncia do log de confirmaçăo (LSN) que foi atribuído ŕ alteraçăo. O LSN de confirmaçăo năo só identifica alteraçőes que foram confirmadas dentro da mesma transaçăo, mas também ordena essas transaçőes;
· A coluna __$seqval pode ser usada para ordenar mais alteraçőes que acontecem na mesma transaçăo, por exemplo, uma sequęncia de registros que estăo sendo inseridos em uma tabela. Através desta coluna podemos encontrar o número sequencial de inserçőes realizadas;
...
Veja os resultado dos nossos alunos
Conquistas reais de quem está aplicando o método








Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.