Dentre as estratégias de otimizaçăo para bancos de dados os índices săo os mais usados e atuam diretamente no sequenciamento dos dados mapeados, criando links para as linhas das tabelas e aumentando a performance das consultas. Um problema comum ao usar índices é achar que só precisamos espalhar vários deles pelas tabelas e teremos alta performance automaticamente. Este artigo trata de desmistificar o assunto, esclarecendo as diferenças entre dois tipos de índices: clusterizados e năo-clusterizados, além de compreender como e quando adotá-los em seus projetos, seus prós e contras, etc. Vocę também verá exemplos práticos com medidores de performance para avaliar quem se sai melhor em cada situaçăo.
Os índices săo estruturas usadas para armazenar de forma eficiente dados de uma ou mais colunas de tabelas e/ou views para que possam ser recuperados mais rapidamente quando consultas forem feitas ŕs mesmas.
Existem vários tipos de índices para os bancos de dados, como hash, columnstore, xml, etc. Neste artigo trataremos de explicar os dois mais usados: índices clusterizados e năo-clusterizados. Usaremos o SQL Server para construir os exemplos do artigo; o leitor poderá encontrar uma relaçăo dos demais tipos na URL disponibilizada na seçăo Links.
Um índice clusterizado determina a ordem em que as linhas de uma tabela săo armazenadas no disco. Se uma tabela tem um índice clusterizado, no momento de um INSERT as linhas dessa tabela serăo armazenadas em disco na ordem exata do mesmo índice. Por exemplo, suponha que temos uma tabela chamada “Livro” que tem uma coluna de chave primária “livroID” e que criamos um índice clusterizado para essa mesma coluna. Ao fazer isso, todas as linhas dentro da tabela Livro serăo fisicamente ordenadas (no disco atual em que estăo inseridas) através dos valores que estăo na coluna livroID.
Isso implicará em um ganho enorme na performance das pesquisas, pois as colunas da tabela estarăo ordenadas na mesma ordem dos índices clusterizados por intermédio do modelo de armazenamento usado por esse tipo de índice.
Já os índices năo-clusterizados năo fazem esse trabalho de ordenaçăo dos dados tal qual é feito com os índices clusterizados. Em outras palavras, enquanto os índices clusterizados ordenam fisicamente tanto as linhas da tabela quanto os próprios índices e mantęm os mesmos próximos uns aos outros; os năo-clusterizados ordenam somente o índice em si, e năo as linhas (que săo salvas sempre de forma aleatória no disco).
Numa tabela, quando é definida uma chave primária, um índice clusterizado é criado automaticamente pelo banco para a mesma. E o que ele faz basicamente é ordenar as informaçőes pela coluna de chave daquele índice em disco.
Vejamos um exemplo mais próximo da realidade, considere uma tabela de CEP (CEP, Endereço, Bairro, Cidade, etc.) com uma enorme quantidade de dados e que será muito pouco atualizada. Essa tabela será usada por um sistema onde um usuário informa o CEP num campo da tela e os outros campos de endereço devem ser carregados automaticamente após um Enter.
O primeiro critério para avaliar se a nossa tabela precisa de um índice é analisar quais colunas recebem mais consultas, portanto a coluna CEP. Para melhorar a performance nas pesquisas, o DBA tem como opçăo mais viável a criaçăo de um índice nessa coluna. Vejamos as duas realidades caso ele optasse por índices clusterizados e năo-clusterizados:
Portanto, como a coluna CEP sofrerá poucas ou nenhuma atualizaçăo, a melhor estratégia é criar um índice clusterizado para a mesma. Todavia, se a coluna sofresse muitas atualizaçőes, criar um índice clusterizado poderia invalidar o custo x benefício que vimos, com mais sobrecarga e menos performance. Neste caso, o leitor deve analisar os cenários e, através de testes de desempenho e stress, avaliar qual a melhor alternativa. Mais adiante faremos uma análise comparativa entre o uso de ambos os índices num exemplo prático, com medidores de desempenho para que vocę entenda melhor as diferenças entre os mesmos.
Os índices clusterizados tęm como principal vantagem a performance nas pesquisas: elas săo mais rápidas em relaçăo aos năo-clusterizados. Isso se deve ao fato de as informaçőes daquele índice e sua coluna respectiva estarem ordenadas e próximas na memória física do banco. A principal desvantagem é o “custo” de novas escritas em disco que isso trará para o mesmo. Por exemplo, se uma linha em específico tiver seu valor atualizado (UPDATE) em uma de suas colunas de índice (clusterizados), o banco de dados irá mover a linha inteira para que a tabela continue a ser ordenada na mesma ordem da coluna de índice clusterizado. Imagine quantas vezes isso poderá ser feito em um sistema que atualiza muitos dados na referida tabela. Uma opçăo pode ser năo usar o índice clusterizado nesse caso, mas o problema retorna quando a mesma tabela também passar a receber muitas pesquisas.
Para manter a organizaçăo o banco de dados precisará sempre rearranjar as linhas quando um UPDATE for efetuado. Isso trará consequęncias diretas na performance da base inteira e deve ser algo planejado antes.
Tanto os índices clusterizados quanto os năo-clusterizados podem ser exclusivos. Isso significa que duas linhas năo podem ter o mesmo valor que a chave de índice. Caso contrário, o índice năo será exclusivo e várias linhas poderăo compartilhar o mesmo valor de chave. Além disso, para cada tabela podemos ter apenas um índice clusterizado, ao passo que essa restriçăo năo se aplica aos năo-clusterizados. Essa limitaçăo caracteriza mais um ponto a ser avaliado com cuidado quando do uso dessas estruturas em suas tabelas.
É possível ainda criar índices clusterizados e năo-clusterizados em tabelas no SQL Server usando o SQL Server Management Studio ou o Transact-SQL.
Para exemplificar na prática, vamos criar uma implementaçăo comparativa e analisar a diferença em performance no uso dos dois tipos de índices. Para isso, é necessário que o leitor já tenha o SQL Server – 2005 ou superior - instalado na sua máquina (cuja instalaçăo năo fará parte do escopo deste artigo), além de baixado o arquivo do banco de exemplo que a Microsoft disponibiliza no seu site oficial; utilizaremos a base chamada AdventureWorks2012 (vide seçăo Links) para facilitar os testes e năo termos de criar um exemplo do zero. Certifique-se de baixar a versăo correspondente ao seu SQL Server, no nosso exemplo usaremos a versăo 2014.
Saiba mais Curso de SQL ServerDescompacte o arquivo e importe-o na ferramenta do SQL. Os índices săo criados automaticamente quando se é definida uma constraintdo tipo Primary Key (chave primária) para uma ou mais colunas. Assim, o banco assume que estas colunas que formam a chave primária de uma tabela podem ser também usadas para definir seu índice clusterizado. Em outras palavras, se no momento da criaçăo da chave năo forem definidos detalhes, será automaticamente criado um índice clusterizado sobre a(s) mesma(s) coluna(s).
A Primary Key é um conceito lógico que se destina a melhorar a implementaçăo do modelo do banco de dados, enquanto que o índice clusterizado é um conceito físico para organizar as páginas de dados de uma tabela. Por isso, lembre-se que se tivermos muitas instruçőes de INSERT, UPDATE e DELETE, é recomendado năo usar esse tipo de índice para năo perder desempenho organizando os dados a cada atualizaçăo.
Saiba mais: Guia Completo de SQL Server
A criaçăo de um índice clusterizado pode ser feita tanto no desenvolvimento da tabela quanto via T-SQL’s (extensăo do SQL proprietária da Microsoft e Sybase). Vejamos entăo como seria essa aplicaçăo a partir de uma T-SQL, de acordo com a Listagem 1.
Listagem 1. Criando uma tabela com índice clusterizado via T-SQL.
USE AdventureWorks2012;
GO
-- Criaçăo da tabela de testes.
CREATE TABLE dbo.TesteDevmedia
(Coluna1 int NOT NULL,
Coluna2 nchar(10) NULL,
Coluna3 nvarchar(50) NULL);
GO
-- Criaçăo do índice clusterizado chamado de IX_TesteDevmedia_Coluna1
-- na tabela dbo.TesteDevmedia usando a coluna1.
CREATE CLUSTERED INDEX IX_TesteDevmedia_Coluna1
ON dbo.TesteDevmedia (Coluna1);
GOPara entender melhor o cenário de testes, o dividiremos em tręs passos: consultaremos primeiro coluna “LastName” da tabela Person.Person sem nenhum índice criado, com um índice năo-clusterizado e, por último, com um índice clusterizado. Adicionalmente, faremos as mesmas consultas, porém envolvendo duas colunas (LastName e FirstName) de índice ao mesmo tempo, dessa forma o leitor poderá ver como os mesmos se comportam em cenários de índices mais complexos.
Mas antes disso, precisamos efetuar uma cópia da tabela Person.Person, apenas para que năo precisemos alterar a estrutura da original caso vocę necessite efetuar testes futuros. Para isso, execute o script da Listagem 2 que verificará, primeiramente, se a tabela já existe na base (excluindo-a caso positivo) e depois criará a cópia.
Listagem 2. Script para clonar tabela de Person.Person.
USE AdventureWorks2012;
GO
IF EXISTS (SELECT * FROM sys.tables WHERE OBJECT_ID = OBJECT_ID('Person.Person_Teste'))
DROP TABLE Person.Person_Teste;
GO
SELECT * INTO Person.Person_Teste FROM Person.Person;
GONo SQL Server, para clonar uma tabela, basta usar o comando de sintaxe SELECT * INTO NOVA_TABELA FROM TABELA_A_SER_COPIADA, assim o SQL extrairá toda a estrutura física e dados na nova tabela. Mas para que isso funcione, a nova tabela năo pode existir ainda (razăo pela qual fazemos a checagem inicial na listagem).
Além disso, antes de executarmos a consulta para o primeiro caso de teste (sem índices), precisamos nos assegurar que nenhum índice de nenhum tipo esteja associado ŕs colunas de nome. Para tanto, execute o código da Listagem 3 que se encarregará de varrer a tabela de índices e remover o de nome “Name_Index”, que é o que daremos para o nosso futuro índice. A segunda parte da listagem também trata de remover o índice năo-clusterizado “IX_Person_LastName_FirstName_MiddleName” que já existe na base por padrăo e engloba as tręs colunas de nome da tabela Person_Teste.
Listagem 3. Código utilizado para saber se o(s) índice(s) já existe(m).
IF EXISTS (SELECT * FROM sys.indexes WHERE OBJECT_ID = OBJECT_ID('Person.Person_Teste') AND name = 'Name_Index')
DROP INDEX Person.Person_Teste.Name_Index;
IF EXISTS (SELECT * FROM sys.indexes WHERE OBJECT_ID = OBJECT_ID('Person.Person_Teste')
AND name = 'IX_Person_LastName_FirstName_MiddleName')
DROP INDEX Person.Person_Teste.IX_Person_LastName_FirstName_MiddleName; Agora que passamos pelo primeiro passo, o próximo será habilitarmos a impressăo de dados estatísticos via TSQL no SQL Server Management Studio, como segue:
SET STATISTICS io ON
SET STATISTICS time ON
GOEsse TSQL basicamente diz ao SQL Server que queremos que as nossas consultas retornem as informaçőes de desempenho como parte da saída. Como usaremos o recurso de Table Scan do SQL Server para exibir as informaçőes estatísticas de cada consulta, bem como o desempenho das mesmas, é preciso que vocę habilite a opçăo no Management Studio clicando no ícone demonstrado na Figura 1.
Faremos agora uma busca pelo sobrenome (LastName) de uma pessoa dentro da base de exemplo e veremos o “esforço” com o qual a informaçăo será retornada sem a utilizaçăo de índices. A seguir temos o nosso código para busca dos dados de uma pessoa em específico no banco:
SELECT *
FROM Person.Person_Teste where LastName = 'Brown';
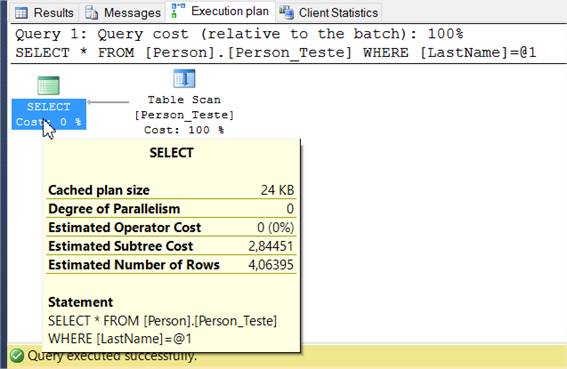
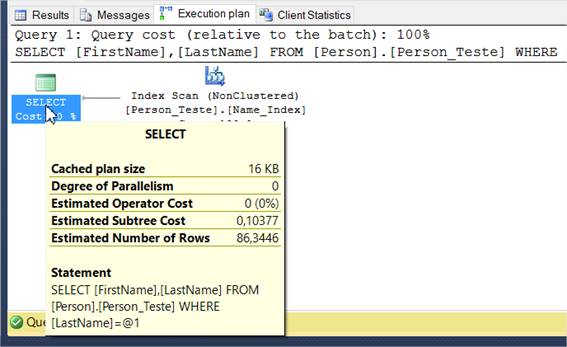
GOA execuçăo trará um resultado de 92 linhas de um total de 19.972 linhas na tabela. Agora, basta acessar a aba “Execution plan” ao lado da aba “Results” e vocę verá algo semelhante ao que temos na Figura 2.
Como podemos ver na figura, essa query teve um “custo estimado de subárvore” de 2.84451. Esse valor representa o custo total do otimizador do SQL para executar năo só essa query, mas todas as operaçőes que a precederam na mesma subárvore. Quanto menor esse número, menor a intensidade da execuçăo da referida query para o banco.
Agora, para efetuar o mesmo teste, porém com um índice năo-clusterizado, precisamos criar explicitamente um novo envolvendo a coluna usada na pesquisa. Crie, portanto, o índice tal como mostra a Listagem 4.
Listagem 4. Criaçăo do índice năo-clusterizado ‘Name_Index’.
USE AdventureWorks2012;
GO
CREATE NONCLUSTERED INDEX Name_Index
ON Person.Person_Teste (LastName);
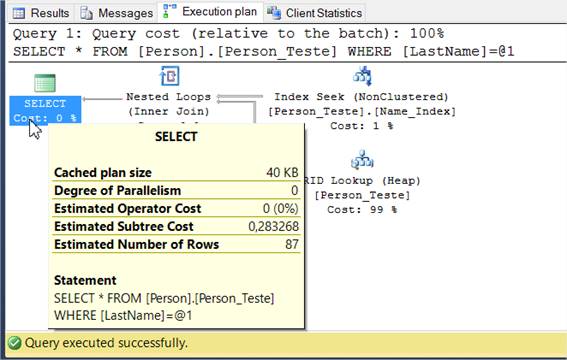
GO Após isso, basta realizar uma nova consulta com base no mesmo script de SELECT com as mesmas informaçőes usadas para a coluna de LastName e verificar o resultado na aba “Execution plan”, tal como mostra a Figura 3. Veja que o custo caiu para 0.283268, isto é, uma reduçăo mínima, principalmente por estarmos lidando com uma base năo tăo populosa assim, mas já é o suficiente para mostrar o ganho em qualquer tipo de consulta realizada com esse tipo de índice.
Para fazer o mesmo teste com um índice clusterizado, precisamos nos assegurar de remover o que criamos na listagem anterior, bem como criar o novo com a nova sintaxe. Para isso, execute o script contido na Listagem 5.
Listagem 5. Criaçăo do índice clusterizado ‘Name_Index’.
IF EXISTS (SELECT * FROM sys.indexes WHERE OBJECT_ID = OBJECT_ID('Person.Person_Teste') AND name = 'Name_Index')
DROP INDEX Person.Person_Teste.Name_Index;
CREATE CLUSTERED INDEX Name_Index
ON Person.Person_Teste (LastName);
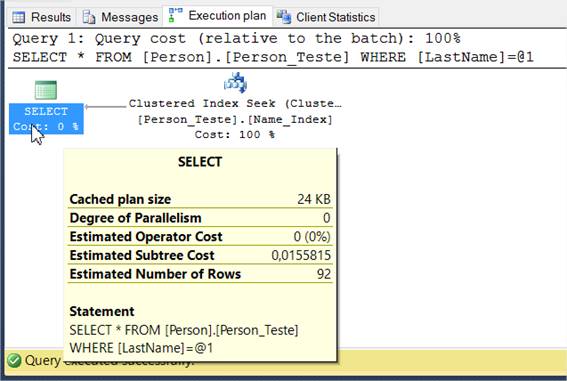
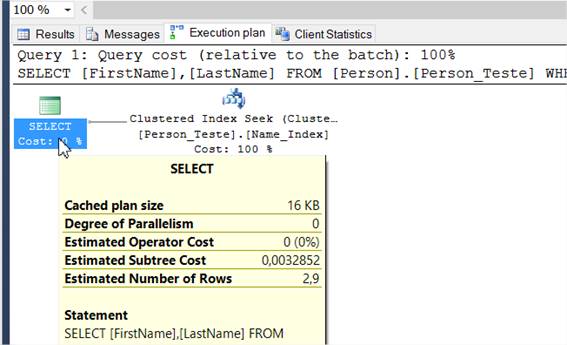
GOApós a execuçăo, rode mais uma vez o SELECT e acesse novamente a aba “Execution plan”. Vocę verá algo semelhante ŕ Figura 4.
Observe o enorme ganho que tivemos, mesmo com um exemplo bem simples e poucos dados na base. O valor de custo que era de 2.84451 caiu para 0.01558. Em termos de tempo final de execuçăo, e levando em consideraçăo uma massa expressiva de dados, teremos um ganho enorme usando a opçăo com índice clusterizado.
Para entender ainda mais como o mecanismo de índices funciona veremos dois exemplos de uso dos dois tipos, porém agora com duas colunas de índice (índice composto). Para isso, execute o script demostrado na Listagem 6.
Listagem 6. Criaçăo do índice năo-clusterizado nas colunas de nome e sobrenome.
IF EXISTS (SELECT * FROM sys.indexes WHERE OBJECT_ID = OBJECT_ID('Person.Person_Teste') AND name = 'Name_Index')
DROP INDEX Person.Person_Teste.Name_Index;
CREATE NONCLUSTERED INDEX Name_Index
ON Person.Person_Teste (FirstName, LastName);
GOApós isso, vamos executar a mesma query (Listagem 7), incluindo agora a coluna de FirstName. Além disso, vamos complicar um pouco mais a consulta incluindo na busca também a coluna de primeiro nome (FirstName), e uma cláusula LIKE na condiçăo para exigir que o banco trabalhe mais para encontrar os resultados.
Listagem 7. Consulta envolvendo as duas colunas de nome, com uma cláusula LIKE.
SELECT FirstName, LastName
FROM Person.Person_Teste
where FirstName like '%Jo%' and LastName = 'Brown';
GOO resultado pode ser visualizado na Figura 5. Para efetuar a comparaçăo com o índice clusterizado composto, execute a query da Listagem 8, reexecute o mesmo SELECT e veja o respectivo resultado na Figura 6.
Listagem 8. Criaçăo do índice clusterizado nas colunas de nome e sobrenome.
IF EXISTS (SELECT * FROM sys.indexes WHERE OBJECT_ID = OBJECT_ID('Person.Person_Teste') AND name = 'Name_Index')
DROP INDEX Person.Person_Teste.Name_Index;
CREATE NONCLUSTERED INDEX Name_Index
ON Person.Person_Teste (FirstName, LastName);
GOHá momentos em que a utilizaçăo de índices clusterizados se torna um prejuízo, isso quando está relacionada ŕs instruçőes de INSERT, UPDATE e DELETE. Em geral, as vantagens de recuperaçăo superam os inconvenientes de manutençăo, tornando um índice clusterizado bem visto pela comunidade de DBA’s.
Além disso, lembre-se que cada tabela de um esquema pode ter vários índices năo-clusterizados ao mesmo tempo, porém somente um clusterizado. Além disso, avalie sempre bem cada caso e verifique se o overhead gerado valerá a pena na performance final da sua base dados, fazendo sempre uso dos mecanismos de mediçăo de performance que vimos no artigo. Até a próxima!

Veja os resultado dos nossos alunos
Conquistas reais de quem está aplicando o método








Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.