Este artigo tem como objetivo apresentar o uso da linguagem T-SQL. Serăo discutidos alguns recursos que podem ser utilizados no desenvolvimento de consultas e manipulaçăo de dados usando a ferramenta SQL Server no banco de dados AdventureWorks2012. Veremos tipos de dados, funçőes de data, string, tipos de joins, operadores cross apply e outer apply, pivot e unpivot, sub consultas, windows functions, índices, níveis de isolamento, trigger, view, procedure, function, CTE, merge e alguns complementos do T-SQL. A discussăo desse tema é útil para qualquer desenvolvedor Transact-SQL que queira aprimorar seus conhecimentos ou que tenha interesse em trabalhar com consultas avançadas em T-SQL. Entender como o T-SQL funciona pode ajudar a criar consultas melhores e facilitar a sua compreensăo de como corrigir uma consulta que năo retorna os resultados desejados.
A linguagem Transact-SQL é uma extensăo ao padrăo SQL-92, sendo a linguagem utilizada por desenvolvedores na construçăo de aplicaçőes que manipulam dados mantidos no SQL Server. Seus comandos podem ser classificados em quatro grupos, de acordo com sua funçăo: DML (Linguagem de Manipulaçăo de Dados), DDL (Linguagem de Definiçăo de Dados), DCL (Linguagem de Controle de Dados) e DTL (Linguagem de Transaçăo de Dados). Além dessas categorias, podemos ter também uma relacionada ŕ consulta dos dados (DQL – Linguagem de Consulta de Dados), que possui apenas o comando SELECT. Entretanto, é mais comum encontrar esse comando como parte da DML em conjunto com os demais comandos de manipulaçăo: INSERT, UPDATE e DELETE.
Esse subconjunto apoia a criaçăo de objetos no banco de dados, alteraçăo na estrutura da base de dados ou a remoçăo do banco de dados. Seus principais comandos săo:
Esse subconjunto é utilizado para realizar consultas, inclusőes, alteraçőes e exclusőes de dados. Seus principais comandos săo:
Esse subconjunto da linguagem SQL é responsável por controlar os aspectos de autorizaçăo de dados e a utilizaçăo de licenças por usuários. Săo conhecidos como comandos DCL (Data Control Language):
Relacionado: Introduçăo ao T-SQL
Esse subconjunto da linguagem SQL é responsável por gerenciar transaçőes executadas no banco. Seus principais comandos săo:
Outro conceito essencial e presente nos SGBDs é a integridade de dados. Ele diz respeito a uma série de restriçőes impostas pelos SGBDs para garantir que os dados nunca saiam de um estado consistente para um inconsistente. Existem diferentes tipos de mecanismos de integridade implementados pelos SGBDs. A integridade de entidade garante que cada linha em uma tabela é um registro exclusivamente identificável. Vocę pode aplicar a integridade de entidade para uma tabela especificando uma restriçăo PRIMARY KEY. Por exemplo, a coluna ProductID da tabela produtos é uma chave primária para a tabela.
A integridade referencial, definida através da restriçăo FOREIGN KEY, assegura que as relaçőes entre tabelas permanecem preservadas ao longo do tempo. Já a integridade de domínio garante que os valores de dados dentro de um banco seguem regras definidas para valores: alcance e formato. Um banco de dados pode impor essas regras usando uma variedade de técnicas, incluindo restriçőes CHECK, UNIQUE e restriçőes padrăo. Essas serăo as restriçőes apresentadas nesse artigo, mas precisamos estar cientes de que existem outras opçőes disponíveis para impor a integridade de domínio.
A lista a seguir fornece alguns exemplos de restriçőes de integridade de domínio:
Há diferentes tipos de dados no SQL Server: de sistema e de usuários (User-Defined Types - UDTs) ou SQL Common Language Runtime (CLR). A seguir temos uma amostra dos tipos disponíveis no SQL Server:
String:
Inteiros:
Tipos numéricos aproximados
Data e Hora
O comando IDENTITY é utilizado para determinar que uma coluna da tabela será automaticamente incrementada quando um valor novo é inserido (esse campo năo aceita valores nulos). Todas as tabelas possuem uma coluna ou um conjunto de colunas que identificam a linha: a primary key.
Também conhecido como GUID (Identificador global exclusivo), o tipo uniqueidentifier é armazenado como um valor binário de 16 bytes e para chamá-lo vocę precisa usar a funçăo NEWID(). A principal vantagem do uso de GUIDs é que eles săo exclusivos em todo o espaço e tempo. A grande desvantagem de usá-los é que eles săo grandes, sendo um dos maiores tipos de dados do SQL Server, entăo usá-los tornará o índice mais lento. Esse é um exemplo de um GUID formatado: B85E62C3-DC56-40C0-852A-49F759AC68FB. Já esse é um exemplo de um GUID binário: 0xff19966f868b11d0b42d00c04fc964ff
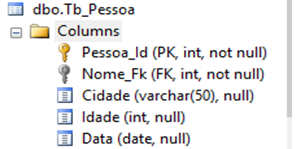
O principal objetivo de uma restriçăo é fazer cumprir uma regra no banco de dados, por exemplo, para garantir que os dados inseridos sejam válidos e que obedeçam ŕs regras de negócio. Na linguagem T-SQL temos cinco constraints. A Listagem 1 apresenta um script que exemplifica o uso das cinco na mesma tabela e, na Figura 1, o resultado é exibido:
CREATE TABLE Tb_Pessoa
(
Pessoa_Id INT PRIMARY KEY,
Nome_Fk INT FOREIGN KEY REFERENCES Tb_Pessoa (Pessoa_Id) NOT NULL,
Cidade VARCHAR (50) UNIQUE,
Idade INT CHECK (Idade >18),
Data DATE DEFAULT GETDATE ()
)
O SQL Server possui dois tipos básicos para armazenar e trabalhar com datas: datetime e smalldatetime. A diferença é que o tipo datetime armazena até centésimos de segundos e o smalldatetime até segundos. O datetime aceita datas até no mínimo 01/01/1753, abaixo disso ele gerará erro. Já o smalldatetime armazena datas de até no mínimo 01/01/1900.
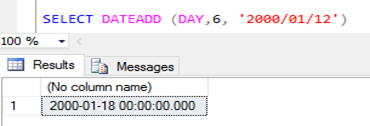
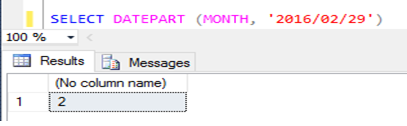
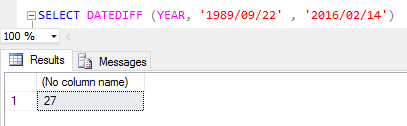
As principais funçőes de data no SQL Server săo: DATEPART, DATEADD e DATEDIFF. Elas trabalham referenciando unidades de data, que săo: Year (ano), Month (męs) e Day (dia). O DATEADD retorna a data através da soma do número especificado, como mostra a Figura 2. Já o DATEPART retorna a parte especificada de uma data, como mostra a Figura 3. Por fim, o DATEDIFF retorna o cálculo da diferença entre as datas especificadas, como mostra a Figura 4.
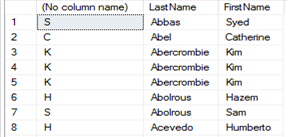
Existem várias funçőes no T-SQL que auxiliam na manipulaçăo de strings, mas conheceremos aqui as mais importantes. Para iniciar, a funçăo SUBSTRING() recupera a posiçăo da palavra ou uma parte de uma expressăo de caracteres, binários, texto ou imagem. O código a seguir apresenta um exemplo de uso e a Figura 5 mostra o resultado de sua execuçăo:
SELECT SUBSTRING(FirstName, 1, 1), LastName, FirstName
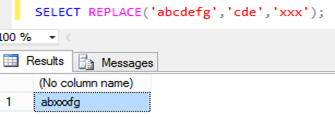
FROM Person.Person;A funçăo REPLACE() é capaz de localizar uma determinada expressăo em uma string e, ao encontrá-la, realiza a substituiçăo por outra expressăo conforme definido nos parâmetros, como mostra a Figura 6.
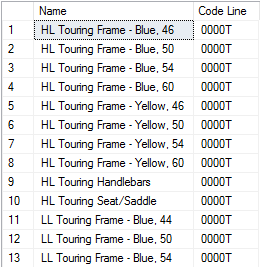
A funçăo REPLICATE() realiza a repetiçăo de caracteres referentes ao número de vezes definido em um de seus parâmetros. O exemplo apresentado na Listagem 2 reproduz um caractere 0 quatro vezes na frente de uma linha de produçăo de código. A Figura 7 apresenta o resultado de sua execuçăo.
SELECT Name,
Replicate ( "0", 4) + [ProductLine] AS "Code Line"
FROM [Production].[Product]
WHERE [ProductLine] = "T"
ORDER BY [Name];
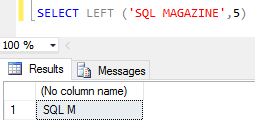
Já a funçăo LEFT() retorna a parte da esquerda de uma cadeia de caracteres, dependendo do número de caracteres especificado levando em consideraçăo os espaços, como mostra o exemplo da Figura 8. Observe que no exemplo, o número 5 especificado corresponde ŕ quantidade de caracteres que deverá ser retornada na consulta na parte esquerda.
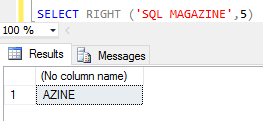
A funçăo RIGHT() trabalha de forma semelhante ao LEFT, porém retorna a parte da direita de uma cadeia de caracteres levando em consideraçăo os espaços, como mostra o exemplo da Figura 9. Nesse exemplo, o número 5 especificado corresponde ŕ quantidade de caracteres que deverá ser retornada na consulta na parte direita.
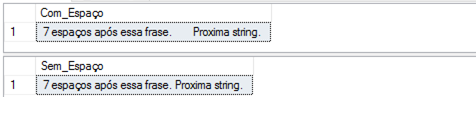
Já a funçăo RTRIM() retorna uma expressăo de caracteres depois de remover espaços em branco ŕ direita. A Listagem 3 apresenta um exemplo de seu uso e a Figura 10 mostra o resultado de sua execuçăo. Em complemento, a funçăo LTRIM() retorna uma expressăo de caracteres depois de remover espaços em branco ŕ esquerda.
DECLARE @STRING_TRIM VARCHAR(60);
SET @STRING_TRIM = " 7 espaços após essa frase.";
SELECT @STRING_TRIM + "Proxima string." AS Com_Espaço;
SELECT LTRIM (@STRING_TRIM) + " Proxima string." AS Sem_Espaço;
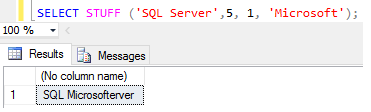
A funçăo STUFF() insere ou substitui uma cadeia de caracteres dentro de um campo texto. Para isso, ela especifica a posiçăo do primeiro e último caracteres da cadeia que serăo substituídos e, em seguida, efetua a exclusăo da cadeia e insere a nova, como mostra o exemplo da Figura 11. Nesse exemplo, definimos que na 5Ş posiçăo da frase “SQL Server” será inserida a palavra Microsoft.
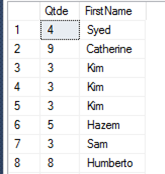
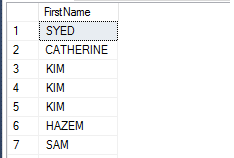
A funçăo LEN() retorna a quantidade de caracteres da cadeia especificada, eliminando os espaços em branco ŕ direita, diferente da funçăo datalenght() que conta o número de bytes. O código a seguir apresenta um exemplo de seu uso e a Figura 12 traz o resultado de sua execuçăo.
SELECT TOP 10
LEN(FirstName) Qtde, PrimeiroNome
FROM [Person].[Person]
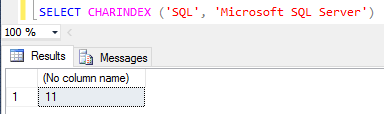
As funçőes CHARINDEX e PATINDEX retornam ŕ posiçăo inicial de um padrăo que vocę especifica. A diferença entre elas está no fato de que a PATINDEX permite usar caracteres curingas. Ambas as funçőes usam dois argumentos. Com PATINDEX incluímos o sinal “%” antes e depois do teste padrăo. Caso estejamos ŕ procura de um padrăo como o primeiro ou os últimos caracteres em uma coluna, devemos omitir o primeiro “%” ou o último “%”. Para CHARINDEX, o padrăo năo pode incluir caractere curinga. O segundo argumento é uma expressăo de caracteres, geralmente um nome de coluna. A Figura 13 mostra um exemplo de uso que retorna o início da posiçăo da string “SQL” na frase “Microsoft SQL Server”.
Essa chamada retornará a localizaçăo da cadeia “SQL”, começando na sequęncia de “Microsoft SQL Server”. Nesse caso, a funçăo CHARINDEX retornará o número 11, que como vocę pode ver, é a posiçăo inicial de “S” na cadeia “Microsoft SQL Server”.
Agora temos o seguinte comando CHARINDEX:
SELECT CHARINDEX ("7.0", "Microsoft SQL Server 2000")Para esse exemplo, o resultado será zero porque a string procurada năo pode ser identificada no texto.
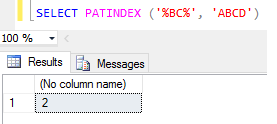
A funçăo PATINDEX retorna a posiçăo inicial do padrăo dentro da sequęncia pesquisada, como mostra a Figura 14. Em nosso exemplo, o resultado da chamada da funçăo PATINDEX é 2. Observe que o sinal % é um caractere universal (caractere curinga).Existem quatro tipos de caractere curinga disponíveis no SQL Server:
Por fim, a funçăo UPPER() retorna os dados da string em maiúsculo. O código a seguir apresenta um exemplo de seu uso e a Figura 15 traz o resultado de sua execuçăo:
SELECT TOP 10
UPPER(FirstName) FirstName
FROM [Person].[Person]
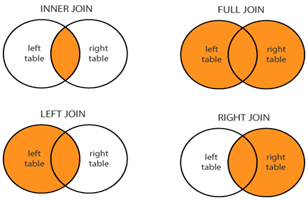
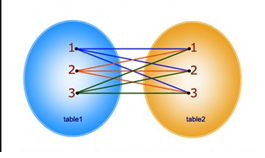
O uso de junçőes permite consultar dados de duas ou mais tabelas com base em suas relaçőes. Existem diferentes tipos de junçăo que podem ser utilizados em consultas SQL. A Figura 16 ilustra a diferença entre eles.
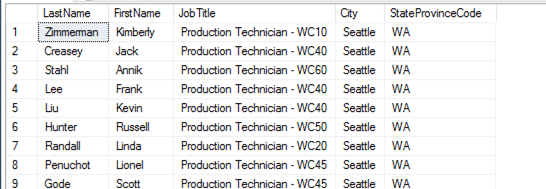
Um INNER JOIN seleciona todas as linhas de ambas as tabelas, desde que haja uma correspondęncia entre as colunas delas. Ele retorna dados apenas quando as duas tabelas possuem chaves correspondentes na cláusula ON do JOIN. Esse tipo de JOIN é usado quando se quer recuperar dados em mais de uma tabela através da igualdade de suas foreign keys. Na Listagem 4 é realizada uma consulta aos funcionários que săo de Seattle. A Figura 17 apresenta o resultado da consulta.
SELECT p.LastName, p.FirstName, e.JobTitle, a.City, sp.StateProvinceCode
FROM HumanResources.Employee e
INNER JOIN Person.Person p
ON p.BusinessEntityID = e.BusinessEntityID
INNER JOIN Person.BusinessEntityAddress bea
ON bea.BusinessEntityID = e.BusinessEntityID
INNER JOIN Person.Address a
ON a.AddressID = bea.AddressID
INNER JOIN Person.StateProvince sp
ON sp.StateProvinceID = a.StateProvinceID
WHERE a.City = "Seattle"
Com LEFT JOIN todos os dados da tabela ŕ esquerda săo retornados. Na tabela ŕ direita, os dados correspondentes săo retornados, além de valores NULL. Já o RIGHT JOIN retorna todos os dados da tabela ŕ direita e, da tabela ŕ esquerda, apenas aqueles que possuem correspondęncia săo retornados, além de valores NULL (onde existe um registro na tabela ŕ direita, mas năo na tabela ŕ esquerda).
O FULL OUTER JOIN, conhecido como OUTER JOIN ou simplesmente FULL JOIN, retorna todos os registros. Por fim, temos o CROSS JOIN (método implícito), que efetua um produto cartesiano das tabelas e, por isso mesmo, năo tem a cláusula ON. Esse comando năo permite especificar uma condiçăo para a junçăo, dessa forma, o resultado será uma combinaçăo de todas as linhas de ambas as tabelas, como mostra a Figura 18.
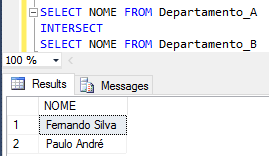
O comando INTERSECT funciona como o operador AND, selecionando apenas o valor presente nas duas tabelas. Ele retorna todas as linhas presentes tanto no resultado da consulta1 como na consulta2. As linhas duplicadas săo eliminadas por padrăo.
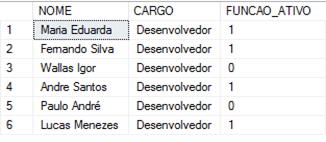
Já o comando EXCEPT retorna somente as linhas, a partir da primeira instruçăo, que năo existem na segunda instruçăo. Ele retorna todas as linhas que estăo no resultado da consulta1, mas năo no resultado da consulta2. Observe as duas tabelas Departamento_A (Figura 19) e Departamento_B (Figura 20) e logo em seguida o resultado dos dois comandos na Figura 21.
Existem algumas regras que precisam ser observadas ao combinarmos os resultados de consultas que usam EXCEPT ou INTERSECT. Por exemplo, a quantidade e a ordem das colunas devem ser iguais nas consultas consideradas. Além disso, tem-se que os tipos de dados devem ser compatíveis nas colunas consideradas. Por exemplo, năo poderíamos fazer o seguinte: consultar no Departamento_A o NOME e CARGO e năo os considerar também na tabela Departamento_B. Ao fazer isso, teríamos um erro indicando que “deve existir um número igual de expressőes em suas listas de destino. ”.
Muitas vezes vocę se depara com a tarefa de comparar duas ou mais tabelas ou resultados da consulta para determinar qual informaçăo é a mesma e qual năo é. Uma das formas mais comuns para fazer essa comparaçăo é usar o UNION ou UNION ALL. O UNION faz a uniăo de duas ou mais tabelas. Essa instruçăo efetivamente faz um SELECT DISTINCT, no qual năo serăo retornados valores repetidos. Já o UNION ALL retorna todos os valores das duas ou mais tabelas, sendo que a diferença em relaçăo ao UNION é que se tivermos dois ou mais valores repetidos, eles serăo retornados.
Cast é uma funçăo do padrăo ANSI e Convert é uma funçăo do engine do SQL Server (T-SQL). Ambas convertem explicitamente uma expressăo de um tipo de dados em outro. CAST é uma variante sintática de CONVERT. No CONVERT, se o comprimento năo for especificado, o padrăo será de 30 caracteres. Para ambos, temos dois tipos de conversăo:
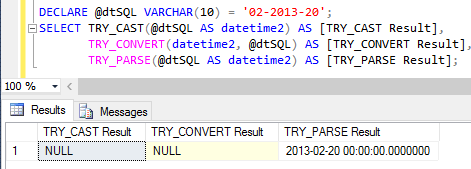
A funcionalidade básica de ambas as funçőes é a mesma: verificar se um valor fornecido em um tipo de dados pode ser convertido e efetuar a conversăo para outro tipo de dados. Caso a conversăo falhe, será retornado o valor NULL. A Figura 25 apresenta um exemplo utilizando as funçőes no qual năo foi possível converter a data 02-2013-20 por um erro no formato, retornando entăo null. Entretanto, o uso do try_parse permitiu realizar a operaçăo com sucesso.
Windows Functions săo formas de obter diferentes perspectivas sobre um conjunto de dados sem ter que fazer chamadas repetidas ao servidor. Elas foram implementadas para solucionar problemas já mapeados e difíceis de serem solucionados, começando a partir do SQL Server 2005. Atualmente temos diversas Windows Functions implementadas.
Elas săo funçőes para serem trabalhadas com um conjunto de linhas que săo definidas por uma cláusula OVER. Essa cláusula possibilita trabalhar com totais, agrupamentos, ordenaçőes, cálculos complexos dentre outros. Os tipos de Windows Functions săo:
As funçőes de agregaçăo executam um cálculo em um conjunto de valores, sendo que elas computam um único resultado para várias linhas de entrada. As funçőes agregadas normalmente săo usadas com a cláusula GROUP BY (utilizado para agrupar seu resultado por uma ou mais colunas) e, com exceçăo do COUNT, as funçőes ignoram valores nulos.
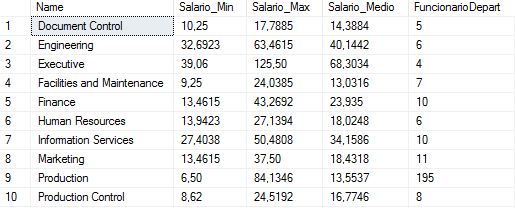
A Listagem 5 utiliza as funçőes MIN, MAX, AVG e COUNT com a cláusula OVER para fornecer valores agregados para cada departamento na tabela HumanResources.Department. A Figura 26 apresenta os resultados obtidos.
SELECT DISTINCT Name,
MIN(Rate) OVER (PARTITION BY edh.DepartmentID) AS Salario_Min,
MAX(Rate) OVER (PARTITION BY edh.DepartmentID) AS Salario_Max,
AVG(Rate) OVER (PARTITION BY edh.DepartmentID) AS Salario_Medio,,
COUNT(edh.BusinessEntityID) OVER (PARTITION BY edh.DepartmentID)
AS FuncionarioDepart
FROM HumanResources.EmployeePayHistory AS eph
JOIN HumanResources.EmployeeDepartmentHistory AS edh
ON eph.BusinessEntityID = edh.BusinessEntityID
JOIN HumanResources.Department AS d
ON d.DepartmentID = edh.DepartmentID
WHERE edh.EndDate IS NULL
ORDER BY Name;
Como o próprio nome diz, funçőes de classificaçăo permitem classificar as linhas no conjunto de resultados com base em valores especificados nelas. O SQL Server suporta quatro funçőes de classificaçăo:
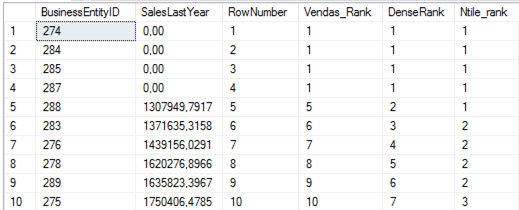
Todas as funçőes de classificaçăo começam com o número 1 ao atribuir valores e classificam os dados com base na coluna especificada na cláusula ORDER BY. Assim, com a cláusula ORDER BY, identificamos a coluna sobre a qual deseja basear o ranking. Também podemos especificar se as linhas devem ser classificadas em ordem crescente ou decrescente. A Listagem 6 apresenta um exemplo e, em seguida, a Figura 27 apresenta o seu resultado.
SELECT
BusinessEntityID,
SalesLastYear,
ROW_NUMBER () OVER (ORDER BY SalesLastYear ASC) AS RowNumber,
RANK () OVER (ORDER BY SalesLastYear ASC) AS Vendas_Rank,
DENSE_RANK () OVER (ORDER BY SalesLastYear ASC) AS DenseRank,
NTILE (4) OVER (ORDER BY SalesLastYear ASC) AS Ntile_rank
FROM Sales.SalesPerson;
A cláusula OFFSET-FETCH fornece uma opçăo para buscar apenas uma janela ou página de resultados do conjunto de resultados. Ela pode ser usada somente com a cláusula ORDER BY e considera as seguintes opçőes:
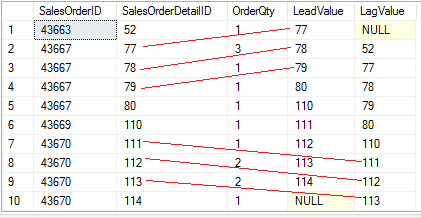
Na Listagem 7, LEAD e LAG acessam dados de uma linha subsequente e linha anterior filtrando pela coluna SalesOrderId com os ids 43670, 43669, 43667, 43663. A Figura 28 apresenta o resultado. Para o conjunto de resultados retornados, é muito claro que a funçăo LEAD retorna o valor da linha seguinte e a funçăo LAG retorna o valor que foi encontrado na linha anterior.
SELECT s.SalesOrderID , s.SalesOrderDetailID , s.OrderQty ,
LEAD ( SalesOrderDetailID ) OVER ( ORDER BY SalesOrderDetailID
) LeadValue ,
LAG ( SalesOrderDetailID ) OVER ( ORDER BY SalesOrderDetailID
) LagValue
FROM Sales.SalesOrderDetail s
WHERE SalesOrderID IN ( 43670 , 43669 , 43667 , 43663 )
ORDER BY s.SalesOrderID , s.SalesOrderDetailID , s.OrderQty
Na cláusula CASE, se o resultado for verdade, entăo o valor definido na expressăo é o resultado obtido. Caso seja falso, o processo se repetirá em todas as cláusulas WHEN seguintes. Se o resultado de nenhuma condiçăo WHEN for verdadeiro, entăo o valor da expressăo CASE será o valor do resultado na cláusula ELSE. Se a cláusula ELSE for omitida e nenhuma condiçăo for satisfeita, o resultado será nulo.
A cláusula IIF é uma forma abreviada de se usar a expressăo CASE. De forma semelhante, se a expressăo for verdadeira retorna, é retornado um valor, se for falsa, retorna outro especificado.
Sub consultas săo bastante úteis para construir consultas complexas e para obter resultados que antes pareciam impossíveis. Uma sub consulta é uma consulta aninhada em uma instruçăo SELECT, INSERT, UPDATE ou DELETE.
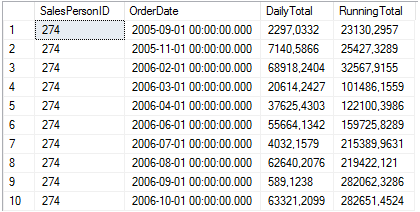
As subquerys devem sempre ser informadas entre paręnteses, pois assim o SQL Server consegue saber que estamos nos referindo a uma subquery. Quando possível, devemos utilizar um JOIN ao invés de uma subquery, pois o otimizador de consultas do SGBD pode executar algumas operaçőes a mais quando se utiliza subqueries, prejudicando o seu desempenho. Na Listagem 8 temos tręs selects operando em uma sub consulta que ao fina retornará as colunas SalesPersonID, OrderDate, DailyTotal, especificadas no primeiro select. A Figura 29 apresenta o resultado obtido.
SELECT
SH3.SalesPersonID,
SH3.OrderDate,
SH3.DailyTotal,
SUM(SH4.DailyTotal) RunningTotal
FROM
(SELECT SH1.SalesPersonID, SH1.OrderDate,
SUM(SH1.TotalDue) DailyTotal
FROM Sales.SalesOrderHeader SH1
WHERE SH1.SalesPersonID IS NOT NULL
GROUP BY SH1.SalesPersonID,
SH1.OrderDate) SH3
INNER JOIN
(SELECT SH2.SalesPersonID, SH2.OrderDate,
SUM(SH2.TotalDue) DailyTotal
FROM Sales.SalesOrderHeader SH2
WHERE SH2.SalesPersonID IS NOT NULL
GROUP BY SH2.SalesPersonID,
SH2.OrderDate) SH4
ON SH3.SalesPersonID = SH4.SalesPersonID
AND SH3.OrderDate > SH4.OrderDate
GROUP BY SH3.SalesPersonID,
SH3.OrderDate,
SH3.DailyTotal
ORDER BY SH3.SalesPersonID,
SH3.OrderDate
Pivot é um operador relacional criado a partir do SQL SERVER 2005, sendo um mecanismo que transforma linhas em colunas. Essa cláusula permite reestruturar dados de uma estrutura de dados normalizada para um formato diferente, e assim exibir as informaçőes que vocę precisa de uma maneira mais legível aos olhos do usuário que requisitou as informaçőes.
O Unpivot é um operador relacional, atuando ao contrário da operaçăo pivot. É um mecanismo que transforma colunas em linhas. O código apresentado na Listagem 9 retorna uma tabela de duas colunas que possui apenas quatro linhas.
SELECT DaysToManufacture,
AVG(StandardCost) AS Custo_medio
FROM Production.Product
GROUP BY DaysToManufacture;
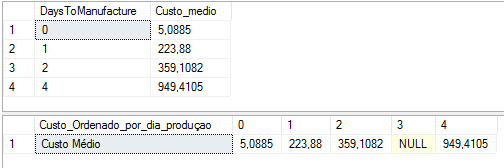
Já o código da Listagem 10 exibe o mesmo resultado, mas dessa vez os valores DaysToManufacture serăo títulos de coluna. Uma coluna é criada para tręs dias[3], embora os resultados sejam NULL. A Figura 30 apresenta o resultado.
SELECT "Custo Médio" AS Custo_Ordenado_por_dia_produçao,
[0], [1], [2], [3], [4]
FROM
(SELECT DaysToManufacture, StandardCost
FROM Production.Product) AS Tabela_fonte
PIVOT
(
AVG(StandardCost)
FOR DaysToManufacture IN ([0], [1], [2], [3], [4])
) AS TabelaPivot;
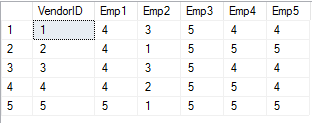
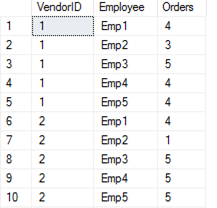
Agora suponha que exista uma tabela no banco de dados armazenada como pivot, como mostra a Figura 31 e que desejamos girar os campos da coluna Emp1, Emp2, Emp3, Emp4, Emp5 para linhas. A coluna que conterá os valores de coluna que vocę está girando será chamada de Employee e a coluna que conterá os valores que atualmente residem nas colunas que estăo sendo giradas será chamada de Orders, como mostra a Listagem 11 e, em seguida, o resultado na Figura 32.
SELECT VendorID, Employee, Orders
FROM
(SELECT VendorID, Emp1, Emp2, Emp3, Emp4, Emp5
FROM #pvt) p
UNPIVOT
(Orders FOR Employee IN
(Emp1, Emp2, Emp3, Emp4, Emp5)
)AS "unpivot";
O operador APPLY permite unir duas tabelas ou expressőes SQL. Ele possui duas variantes, CROSS APPLY e OUTER APPLY. O CROSS APPLY é equivalente ŕ expressăo INNER JOIN, porém sem a cláusula ON. Já o OUTER APPLY é equivalente ŕ expressăo LEFT JOIN. Com INNER JOIN, năo teríamos como inserir o HAVING, nem realizar GROUP BY, fazendo com que o banco de dados realize várias consultas ou sub consultas exigindo mais tempo de construçăo.
A maioria das consultas que empregam CROSS APPLY pode ser reescrita usando um INNER JOIN. Contudo, o CROSS APPLY pode render melhor plano de execuçăo e melhor desempenho.
Agora expandiremos um pouco o tema Group By, discutindo o Rollup, Cube e Grouping Sets. O operador GROUPING SETS pode gerar o mesmo conjunto de resultados gerados por uma operaçăo simples de GROUP BY, ROLLUP ou CUBE. Quando todos os agrupamentos gerados pelo uso de operadores ROLLUP ou CUBE năo săo necessários, poderá ser usado o GROUPING SETS para especificar somente os agrupamentos que quisermos usar.
Os operadores ROLLUP, CUBE ou GROUPING SETS podem gerar o mesmo conjunto de resultados como ao usar UNION ALL para combinar agrupamentos de consultas individuais; entretanto, o uso de um operador GROUP BY normalmente é mais eficiente. O GROUPING SETS permite especificar mais de uma opçăo GROUP BY no mesmo conjunto de registros. O operador ROLLUP é utilizada para calcular o valor agregado para cada nível de uma hierarquia.
Para acessar dados dentro das tabelas, há dois modos que o SQL Server trabalha: o Table Scan e os índices. No table Scan é realizada uma varredura física, linha a linha, até encontrar a informaçăo solicitada. Já o índice cria atalhos para acesso aos dados de forma que o desempenho da operaçăo seja otimizado.
No SQL Server temos dois tipos de índices: clusterizados e năo clusterizados. O tipo clusterizado é um índice gerado na própria estrutura de armazenamento dos dados. Esse índice fará com que os dados da sua tabela fiquem organizados fisicamente na sequęncia. Por isso, em uma tabela pode haver apenas um índice cluster, sendo que sua principal vantagem é a performance obtida nas pesquisas, que normalmente săo mais rápidas em comparaçăo com o năo-clusterizado. O índice clusterizado é criado automaticamente em colunas definida como PRIMAKY KEY.
Já o índice năo clusterizado é um índice criado em uma estrutura separada dos dados físicos. Săo criadas páginas de índices que irăo conter os apontadores para os registros físicos. Eles săo eficientes quando precisamos ter várias maneiras de pesquisar os dados dentro de uma tabela. Por exemplo, em uma tabela que contém os livros de uma livraria, armazenamos o nome do livro, o ISBN, o autor e a editora. Quando pesquisamos um livro, poderemos pesquisar por qualquer uma dessas colunas, nesse caso, precisaremos ter índices para cada uma das colunas, entăo criaremos índices non-clustered associados a elas.
A instruçăo SET TRANSACTION ISOLATION LEVEL está presente no SQL Server já a algum tempo. Os níveis de isolamento săo importantes no contexto em que existem muitas transaçőes acontecendo ao mesmo tempo. Os níveis trabalham os bloqueios nas linhas das tabelas ou nas tabelas para que năo haja falta de consistęncia após o termino de uma transaçăo.
O nível de isolamento read commited é parecido com o read uncommited, a principal diferença é que seu código lerá apenas os dados confirmados ao executar o modo READ COMMITED. Ele especifica que as instruçőes năo podem ler dados modificados que ainda năo foram comitados, e isso impede leituras sujas e năo repetíveis.
Pelo fato dele ler somente as informaçőes realmente escritas no banco de dados, se uma transaçăo estiver trabalhando com a tabela que deseja ler, o SQL esperará liberar a transaçăo para entăo fazer a leitura.
Já o read uncommited (leitura năo confirmada) especifica que as instruçőes podem ler linhas que foram modificadas por outras transaçőes e que ainda năo foram confirmadas. Ele năo oferece nenhuma garantia de isolamento, mas tem o melhor desempenho.
O nível de isolamento repeatable read (leitura repetível) evita leituras sujas e leituras năo repetitivas. Uma leitura suja é uma operaçăo de leitura que ocorre nos dados que foram modificados por uma transaçăo que ainda năo foi consolidada. Uma leitura năo repetitiva pode ocorrer quando os bloqueios de leitura năo săo adquiridos na execuçăo de uma operaçăo de leitura.
Por fim, o nível de isolamento serializable é o mais restritivo de todos. Ele coloca um bloqueio no conjunto de dados impedindo que outros usuários atualizem ou insiram linhas até que a transaçăo seja concluída. Esse nível especifica que todas as transaçőes ocorrem de uma forma completamente isolada. Use esse tipo somente quando necessário, pois ele pode prejudicar o desempenho de seu banco.
Um trigger é um objeto de base de dados que está ligado a uma tabela. Em muitos aspectos, é semelhante a uma procedure (procedimento armazenado).A principal diferença entre um trigger e uma procedure é que o primeiro está ligado a uma tabela e só é acionado quando um INSERT, UPDATE ou DELETE ocorre. Vocę especifica a açăo(s) e a modificaçăo que dispara o gatilho quando ele é criado. Para criar um trigger é utilizado o comando CREATE TRIGGER, para alterar ALTER TRIGGER e para deletar DROP TRIGGER.
Um trigger é classificado em dois tipos: INSTEAD OF, INSTEAD AFTER.
A criaçăo de um trigger envolve duas etapas:
Na criaçăo de um trigger deverăo ser definidos alguns comandos:
A Listagem 12 mostra a sintaxe de criaçăo de um trigger.
CREATE TRIGGER [NOME DO TRIGGER]
ON [NOME DA TABELA]
[FOR/ AFTER/ INSTEAD OF] [INSERT/UPDATE/DELETE]
AS
-- CORPO DO TRIGGER
Views săo tabelas virtuais acessadas frequentemente e que facilitam as consultas no banco de dados. O uso de view é particularmente útil quando se deseja dar o foco a um determinado tipo de informaçăo mantida pelo banco de dados. Imagine um banco de dados corporativo que é acessado por usuários de vários departamentos, as informaçőes que a equipe de vendas manuseia certamente serăo diferentes das do departamento de marketing. Trabalhando com view, é possível oferecer ao usuário apenas as informaçőes que ele necessita, năo importando se săo de uma ou várias tabelas. Isso permite que diferentes usuários vejam as mesmas informaçőes sob uma perspectiva diferente.
Na Listagem 13, vemos uma view criada para facilitar a consulta aos funcionários que săo de Seattle. Dessa forma vocę pode ter informaçőes desses funcionários em uma “tabela virtual”.
CREATE VIEW dbo.SeattleOnly
AS
SELECT p.LastName, p.FirstName, e.JobTitle, a.City, sp.StateProvinceCode
FROM HumanResources.Employee e
INNER JOIN Person.Person p
ON p.BusinessEntityID = e.BusinessEntityID
INNER JOIN Person.BusinessEntityAddress bea
ON bea.BusinessEntityID = e.BusinessEntityID
INNER JOIN Person.Address a
ON a.AddressID = bea.AddressID
INNER JOIN Person.StateProvince sp
ON sp.StateProvinceID = a.StateProvinceID
WHERE a.City = "Seattle"
Procedures săo conjuntos de instruçőes T-SQL executadas dentro de um único plano de execuçăo. Elas podem melhorar a performance (como ela é armazenada dentro do banco, ela é executada rapidamente) e criam mecanismos de segurança nos dados do banco.
Considerando a forma como o SQL Server é utilizado no dia a dia em muitas organizaçőes, é possível afirmar que grande parte do desenvolvimento em T-SQL gira em torno da construçăo de stored procedures. Muitas dessas rotinas săo implementadas com o intuito de produzir resultados dinâmicos, empregando para isso uma consulta SQL simples ou até agrupamentos mais complexos de instruçőes (podendo envolver uma série de cálculos ou mesmo junçőes de dados provenientes de diferentes fontes).
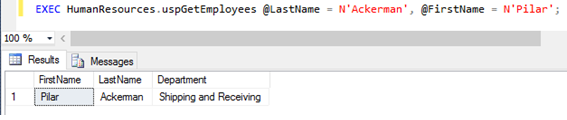
O exemplo apresentado na Listagem 14 cria um procedimento armazenado que retorna informaçőes de um funcionário específico passando os valores para o primeiro nome do empregado e último nome. O resultado de sua execuçăo é apresentado na Figura 33.
CREATE PROCEDURE HumanResources.uspGetEmployees
@LastName nvarchar(50),
@FirstName nvarchar(50)
AS
SET NOCOUNT ON;
SELECT FirstName, LastName, Department
FROM HumanResources.vEmployeeDepartmentHistory
WHERE FirstName = @FirstName AND LastName = @LastName;
Esse é um bom recurso a se utilizar, pois săo objetos que criam planos de execuçăo e assim dăo melhor performance em suas chamadas. Elas sempre retornam valores e săo usadas como parte de uma expressăo.
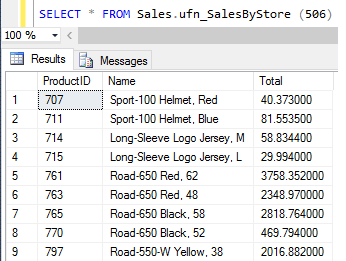
Na Listagem 15 é criada uma funçăo com valor de tabela embutida no banco de dados AdventureWorks2012. A funçăo considera um parâmetro de entrada, um ID cliente (loja), e retorna as colunasProductID, Namee a agregaçăo das vendas do ano, até a data atual, como total para cada produto vendido para a loja. O resultado de sua execuçăo é mostrado na Figura 34.
CREATE FUNCTION Sales.ufn_SalesByStore (@storeid int)
RETURNS TABLE
AS
RETURN
(
SELECT P.ProductID, P.Name, SUM(SD.LineTotal) AS "Total"
FROM Production.Product AS P
JOIN Sales.SalesOrderDetail AS SD ON SD.ProductID = P.ProductID
JOIN Sales.SalesOrderHeader AS SH ON SH.SalesOrderID = SD.SalesOrderID
JOIN Sales.Customer AS C ON SH.CustomerID = C.CustomerID
WHERE C.StoreID = @storeid
GROUP BY P.ProductID, P.Name
);
A CTE (Common Table Expression) é um recurso utilizado desde o SQL Server 2005. Ela pode incluir referęncias em si mesma, e assim se tornar uma expressăo de tabela comum recursiva, sendo possível ter várias definiçőes de consulta de CTE em uma CTE năo recursiva.
Essa cláusula também pode ser usada em uma instruçăo CREATE VIEW como parte da instruçăo SELECT que a define. As CTE podem ser definidas em rotinas definidas pelo usuário, tais como: funçőes, procedures, triggers ou views.
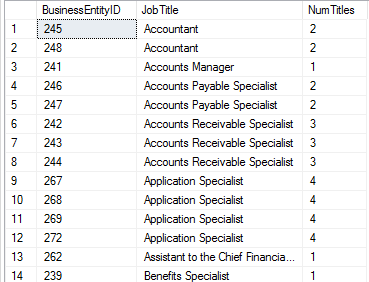
Ela é composta de um nome de expressăo representando a CTE, uma lista de colunas opcionais e uma consulta definindo a CTE. Ela é bem parecida com uma tabela derivada, que năo é armazenada como um objeto e que existe apenas durante a execuçăo da consulta. A Listagem 16 apresenta um exemplo de uso de CTE que recupera a quantidade de cargos para cada id. O resultado de sua execuçăo é apresentado na Figura 35.
WITH ExemploCTE AS
(SELECT JobTitle, COUNT(*) NumTitles
FROM HumanResources.Employee
GROUP BY JobTitle)
SELECT b.BusinessEntityID, b.JobTitle, a.NumTitles
FROM ExemploCTE a INNER JOIN HumanResources.Employee b
ON b.JobTitle = a.JobTitle
A expressăo de tabela comum contém tręs partes principais:
A partir do SQL Server 2008, vocę pode usar o comando MERGE para executar operaçőes de inserçăo, alteraçăo ou exclusăo em uma única instruçăo. Ele basicamente mescla os resultados de uma origem definida com uma tabela de destino com base em uma condiçăo que vocę especificar.
O MERGE funciona basicamente como uma inserçăo, atualizando e excluindo as informaçőes necessárias dentro da mesma solicitaçăo. Para utilizá-lo, especificamos um "Source" conjunto de registros, uma tabela de "Target", e definimos como deve ser a junçăo entre os dois. Entăo especificamos o tipo de modificaçăo de dados que ocorrerá quando os registros entre os dois dados săo combinados ou năo săo correspondidos.
OMERGE é muito útil, especialmente quando se trata de tabelas presentes em data warehouses, que podem ser muito grandes e requerem açőes específicas a serem tomadas quando as linhas estăo ou năo estăo presentes:
Pelo menos uma das tręs cláusulas MATCHED devem ser especificadas, sendo possível especificá-las em qualquer ordem. Devemos estar atentos para o fato de que uma variável năo pode ser atualizada mais de uma vez na mesma cláusula MATCHED.
Inicialmente, deve ser indicado qual tabela será atualizada. Em seguida, definimos a origem dos dados que serăo considerados no processo de merge. Essa etapa é seguida da cláusula ON, através da qual definimos como será realizada a ligaçăo entre as duas tabelas. A Listagem 17 apresenta a sintaxe do Merge.
MERGE tabelaDestino d
USING tabelaOrigem o
ON o.coluna = d.coluna
WHEN MATCHED THEN
DELETE;
O Transact SQL e o SQL Server oferecem as tecnologias e os recursos que as empresas e organizaçőes necessitam para armazenar grandes quantidades de dados, năo deixando de ser útil também até mesmo em pequenas aplicaçőes. O uso de junçőes e funçőes de comparaçăo, conversăo e agrupamento já nos permitem realizar uma série de consultas avançadas. Esses tręs conjuntos somados aos demais conceitos apresentados neste artigo certamente irăo compor um excelente ponto de partida para aqueles que estejam iniciando seus trabalhos no SQL e queiram trabalhar também com a manipulaçăo avançada dos dados armazenados no SGBD. O conhecimento dessa ferramenta e linguagem é essencial para qualquer profissional da área de desenvolvimento de software.


Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.