



Atençăo: por essa ediçăo ser muito antiga năo há arquivo PDF para download. Os artigos dessa ediçăo estăo disponíveis somente através do formato HTML.
Atualmente, quando estamos falando sobre banco de dados, ou lendo sobre o assunto em revistas
ou livros, sempre nos deparamos com o termo “Cliente-Servidor”. Este é tăo utilizado que os menos experientes acabam se confundindo ao deparar com produtos como Dbase Client-Server ou Delphi Client-Server.
Client-Server, é um modelo de processamento onde as tarefas ficam distribuídas entre o servidor e o cliente. O aparecimento desse processamento foi longo e demorado. Vamos acompanhar a evoluçăo das arquiteturas existentes, pois acredito que esta será a melhor forma do entendimento real sobre o conceito e do seu objetivo:
O primeiro modelo de processamento implementado foi a arquitetura de processamento centralizada. Neste contexto, havia um computador central (Main-frame) que armazenava todos os dados e aplicaçőes, e que era responsável por todo o processamento.Os usuários utilizavam as aplicaçőes através de um “Terminal Burro”. O terminal cliente era chamado desta forma pois năo tinha nenhum
poder de processamento, funcionava apenas com um monitor de vídeo e um teclado. Esta arquitetura pode ser facilmente visualizada na figura 1.
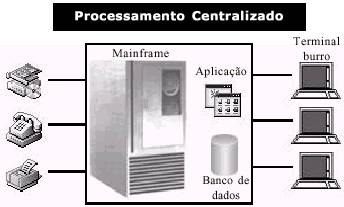
Fgura 1 - Modelo Processamento Centralizado
Obviamente, o processador centralizado tem vantagens e desvantagens. Pelo lado positivo, a manutençăo era bem simples, pois com um computador centralizado, era mais prático de gerenciar
tarefas como backup, manutençăo ou upgrades. O custo com periféricos adicionais, como impressoras e discos rígidos , era bastante reduzido, pois todos compartilhavam das unidades do servidor. Em contrapartida, logo percebe-se uma desvantagem: Quanto maior o número de funcionários que precisariam acessar o Mainframe, maior a potęncia necessária para que este pudesse atender de forma eficaz o fluxo dos negócios da empresa. Como poucas empresas controlavam o mercado de mainframes, o custo para um upgrade no mesmo era bastante alto.
O aparecimento dos computadores pessoais na década de 80, mudou para sempre o modelo de processamento corporativo. O PC (Personal Computer), juntamente com o Sistema Operacional ‘MS-DOS’, rapidamente predominou nas empresas, terminando com o monopólio que um dia os mainframes tiveram sobre os dados corporativos.
Este acontecimento já era esperado e foi inevitável. Entre as principais razőes para a escolha de um
computador de mesa, vemos: os computadores pessoais eram muito baratos e fáceis de usar, e ainda forneciam a potęncia de processamento e o desempenho que só estavam disponíveis nos carros e complicados mainframes. Outro ponto positivo é que eram inúmeras as aplicaçőes para PCs, como processadores de texto, planilhas eletrônicas, banco de dados locais, entre outros. Caso
o usuário năo encontrasse uma aplicaçăo que atendesse as suas necessidades, poderia utilizar uma ferramenta de desenvolvimento para construí-la, em uma linguagem fácil e de alto nível como
Clipper ou COBOL.
Estas mudanças representaram uma modificaçăo na arquitetura centralizada, e passamos a ter um modelo de computaçăo pessoal e desconectada.
Este modelo pode ser claramente visualizado
na figura 2.
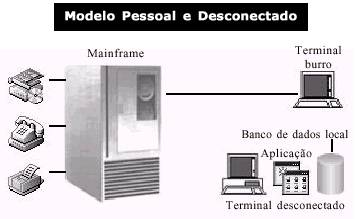
Figura 2 - Modelo Pessoal e Desconectado
Neste modelo, ao invés da empresa manter um engenheiro com alto salário para gerenciar e configurar o Mainframe, cada usuário controlava um computador pessoal, configurando o ambiente ao seu gosto, e sendo responsável pelo backup e segurança de seus dados. Todavia, mais uma vez descobriu- se que este năo era o método ideal, pois apresentava tantos problemas quanto vantagens, quando comparado
ŕ arquitetura centralizada. A principal diferença é que os dados que estavam prontamente disponíveis para todos na empresa, agora estavam distribuídos entre o Mainframe e as estaçőes de trabalho
pessoais. Os ganhos na relaçăo custo/desempenho eram anulados pela perda de produtividade dos grupos de trabalho que precisam acessar as informaçőes espalhadas pela empresa. Além de năo compartilhar dados, os PCs também năo compartilhavam os periféricos e outros recursos dispendiosos, que agora precisavam ser duplicados.
É claro que este modelo năo durou muito, e foi apenas uma fase de transiçăo para o modelo de processamento baseado em rede/servidor de arquivos.
Isto era óbvio: havia a necessidade dos PCs compartilharem os dados e os periféricos ou os usuários teriam que abandonar o uso dos pequenos computadores de mesa. Este modelo, também conhecido
como LAN, pode ser visualizado
na figura 3.
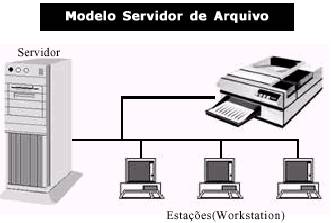
Figura 3 – modelo servidor de arquivo
Como podemos observar ,o servidor de arquivos era o responsável por centralizar os arquivos e os periféricos de toda a rede. A principal diferença para o modelo de Host (Mainframe), é que o servidor de arquivos centraliza apenas os dados e os periféricos, e năo o processamento. As máquinas
clientes eram as responsáveis por processar a informaçăo. Esta arquitetura foi amplamente difundida
e ainda hoje encontramos um grande porcentual de empresas trabalhando desta forma.
Como desvantagens do modelo de servidor de arquivos, encontramos a rápida saturaçăo do uso da
rede. Isto porque quando um cliente
precisa dos dados armazenados no servidor, como o responsável pelo processamento é o próprio cliente, arquivos inteiros ou grande parte săo descarregados pela rede, criando um enorme “gargalo”.
Os problemas de performance e saturaçăo da rede local conduziram ao surgimento do modelo de processamento Cliente/Servidor. Este modelo oferece os benefícios de baixo custo dos PCs, juntamente com o acesso a dados compartilhados e as características de processamento distribuído encontrados
no modelo centralizado. O aparecimento do modelo Cliente/Servidor foi o menos traumático, pois pela primeira vez a arquitetura se modificava sem que necessariamente houvesse uma mudança de Hardware. O modelo Cliente/Servidor encontra-se detalhado na figura 4.
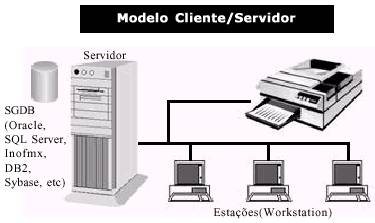
Figura 4 – modelo cliente/servidor
Mas como funciona este novo modelo? Simples – ao invés de termos somente um servidor de arquivos e deixar as máquinas clientes serem responsáveis pela busca e processamento destes dados, podemos ter um Software gerenciador no servidor e este ser o responsável por parte do gerenciamento dos dados. Por exemplo, em um servidor de arquivos, quando o cliente quisesse visualizar as informaçőes de um
cliente específico, todo o arquivo de clientes seria baixado pela rede. No modelo
Cliente/Servidor, o cliente faz uma requisiçăo ao software gerenciador instalado no servidor, e este retorna apenas o que for necessário, otimizando significativamente o processamento através da rede, ou seja, o processamento fica distribuído entre o Software gerenciador (back-end) e o cliente (front-end)
dando origem ao nome Cliente/Servidor.
Entre as principais tarefas realizadas pelo servidor e pelo cliente, encontramos:
No Servidor:
· Gerenciamento de um único banco de dados entre vários usuários simultâneos;
· Controle do acesso ao banco de dados através de senhas e níveis de hierarquia entre os usuários;
· Proteçăo das informaçőes com backups e recuperaçăo;
· Imposiçăo de regras globais de integridade de dados;
No Cliente:
· Apresentaçăo de interface na qual o usuário possa interagir com os dados;
· Execuçăo da lógica da aplicaçăo como cálculo de campos e apresentaçăo de resultados
· em fácil entendimento do usuário, como gráficos e listas selecionáveis;
· Validaçăo da entrada de dados;
· Solicitar e enviar as informaçőes para o servidor;
Os mais populares softwares gerenciadores de dados baseados no modelo Cliente/Servidor săo: Oracle, MS SQL Server, DB/2, Natural, Sybase, entre outros. Dentre as ferramentas de desenvolvimento de front-end, encontramos o Delphi, Visual Basic, Fox Pro, Oracle Forms, C++ Builder, Power Builder,
entre outras.
Este modelo, apesar de reunir um pouco das vantagens de todas as experięncias anteriores, também apresenta desvantagens, apesar de serem menores do que há uma década. A confiabilidade, por exemplo, é menor, quando comparada a um sistema baseado em Host, pois um modelo onde o hardware e o software săo independentes, a heterogeneidade é inevitável. A manutençăo e o gerenciamento de uma rede corporativa, também é bem mais complexa do que nos modelos anteriores, pois o nível de informaçăo e a forma como os dados serăo distribuídos precisam ser bem estudados, para que o modelo possa realmente valer a pena. Este modelo também năo é aplicável a todas as
situaçőes. Obviamente, um sistema de missăo crítica, como reservas de vôo, ou transaçőes bancárias, com centenas ou milhares de terminais espalhados, certamente năo se aplicaria a um gerencia-mento
Cliente/Servidor. Um gerenciamento de dimensăo muito reduzida, como uma vídeo-locadora, também năo seria aplicável, pois teríamos um “canhăo para uma formiga” . Agora, se estiver informatizando
uma empresa de médio ou grande porte, é claro que o uso de um ambiente Cliente/Servidor será a melhor escolha.
Conclusăo
O modelo Cliente/Servidor deve certamente ser analisado dentro do seu projeto, se este for razoavelmente grande ou com possibilidades de crescer. A confiabilidade de um banco de dados
sendo gerenciado é muito maior do que o armazenamento dos dados em arquivos como Paradox ou Dbase. Além do mais, a aplicaçăo pode ser bastante simplificada com a introduçăo deste modelo,
já que boa parte do processamento residirá no servidor, e será transparente para o front-end. Cabe ao Analista/Desenvolvedor optar pelo ferramenta certa e saber se o momento é oportuno para o projeto e para o cliente, principalmente se este nunca foi informatizado antes.
Em ediçőes futuras e em nossa Homepage, estarăo disponíveis mais matérias sobre o assunto, tratando da conexăo e do uso do Delphi como ferramenta
frontend.


Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.