


Explorando técnicas e tecnologias para persistęncia de dados
Conheça as tręs principais escolas para o acesso e a persistęncia de dados, e as vantagens e desvantagens de cada uma, enfocando o estado-da-arte
Um dos principais problemas do desenvolvimento de software, nos últimos 15 anos, quando começou a popularizaçăo da Orientaçăo a Objetos, tem sido a compatibilizaçăo entre este paradigma e o dos bancos de dados relacionais. Já conhecemos bem a história: objetos versus tabelas; herança versus joins, encapsulamento versus projeçăo, e assim por diante.
O problema é resumido pela Figura 1, onde vemos uma aplicaçăo OO escrita em Java acessando um SGBD relacional. A "Interface BDR" é a interface natural, ou "nativa", do SGBD. Para bancos relacionais, essa interface é uma combinaçăo entre SQL e estruturas de dados e protocolos de rede otimizados para executar comandos SQL e transferir dados tabulares. O JDBC é um exemplo de API modelada segundo os requisitos destas estruturas e protocolos.
A aplicaçăo OO precisará de uma camada de "mapeamento objeto-relacional", que traduz estruturas e operaçőes do mundo OO para o mundo relacional. Embora o termo "mapeamento" seja mais usado com ferramentas que fazem isso automaticamente, toda vez que vocę escreve, por exemplo, um código JDBC que executa um SELECT ... FROM CLIENTE e extrai os resultados retornados para seus objetos Cliente, está fazendo mapeamento objeto-relacional, só que ŕ măo.
Escrever esse código ŕ măo é obviamente trabalhoso, entăo qual é a soluçăo para combinar uma linguagem OO com um SGBD? Muitos desenvolvedores Java que utilizam ferramentas como o Hibernate, JDO, ou a nova JPA do EJB 3.0, podem considerar este problema já resolvido. A resposta estaria nas já citadas ferramentas de mapeamento objeto-relacional (ORM). Todavia, esta resposta se baseia em tręs pressupostos que podem năo ser verdadeiros para todos os desenvolvedores e todos os projetos:
1. Uma "grande unificaçăo OO" é melhor que misturar paradigmas;
2. Todos os SGBDs acessados săo estritamente relacionais;
3. Ferramentas ORM acessam os dados da forma mais eficiente e produtiva.
Neste artigo, vamos explorar a questăo do acesso a SGBDs, revisando diversas escolas de pensamento, e examinando as principais alternativas tanto em Java quanto em algumas outras linguagens e plataformas. Nosso plano é o de informar o leitor sobre todo o panorama das técnicas de acesso a dados. O objetivo é ajudá-lo a navegar pela multidăo de ferramentas e tecnologias que competem pela fidelidade dos desenvolvedores.
Escola 1: Bancos OO
A primeira escola que abordaremos é a dos puristas OO – abandonar o paradigma relacional e utilizar bancos de dados OO puros ou, pelo menos BDs híbridos OO/relacionais. Neste caso, o banco de dados fala a língua dos objetos e tudo está resolvido, a favor do paradigma orientado a objetos.
Um banco puramente OO armazena dados organizados em hierarquias de classes, năo
Além da simplicidade (ex.: năo ter que especificar nenhum mapeamento), temos também um desempenho potencialmente superior, pois năo precisamos executar uma camada adicional de código de mapeamento. E tudo o mais sendo igual, quanto menos código vocę precisar para determinada tarefa, menos CPU estará gastando.
SGBDOOs e o padrăo JDO
Um grande problema dos SGBDOOs, tradicionalmente, era a falta de padrőes. Até há alguns anos, a regra era linguagens de consultas e APIs proprietárias e diferentes de um BDOO para outro. Ou seja, no lugar daquela caixinha "Interface BDOO" da Figura 2, poderíamos ler "API proprietária e năo-portável". Algo especialmente ruim na comunidade Java, que valoriza a padronizaçăo e a portabilidade.
Por exemplo, com o banco db4o (que tem uma versăo GPL), teremos código como o da Listagem 1 (baseada no exemplo "Formula 1" do tutorial deste banco). A classe ObjectContainer representa a conexăo com a base de dados. Para localizar todos os objetos Pilot com um nome específico, criamos um objeto deste tipo (um POJO) setando somente o nome, e usamos o método ObjectContainer.get(Object), que faz uma "pesquisa baseada em exemplo". A classe ObjectSet representa o resultado de uma consulta, e ObjectContainer.delete(Object) remove o objeto. Năo há como ser muito mais simples que isso. O problema é que as classes com.db4o.* constituem uma API totalmente proprietária. Se vocę mudar, por exemplo, para o banco de dados Caché, terá que revisar todo o seu código para utilizar a API com.intersys.* deste outro SGBDOO.
Listagem 1. Exemplo de API de SGBDOO proprietária (db4o for Java).
public static void deleteFirstPilotByName (ObjectContainer db) {
ObjectSet result = db.get(new Pilot("Michael Schumacher"));
Pilot found = (Pilot)result.next();
db.delete(found);
}
Mas a soluçăo para essa questăo da portabilidade veio com a norma ODMG 3.0 do Object Data Management Group[1], que normatiza o modelo de dados, a linguagem de consultas e a persistęncia de objetos
A arquitetura da JDO permite que uma implementaçăo adequada desta API possa fazer o papel da "Interface BDOO" da Figura 2, acessando o SGBD de forma direta (dispensando JDBC ou SQL). Por outro lado, quem utilizar JDO com um SGBD relacional cairá novamente na Figura 1, com o runtime JDO se encarregando do complexo mapeamento entre objetos e tabelas, e sendo implementado sobre SQL e JDBC.
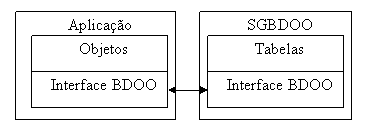
Figura 2. Cenário ideal de uso de SGBOO.
A situaçăo seria melhor se o JDO tivesse vencido a "guerra" das APIs de persistęncia automática para Java, mas esta foi vencida pelo Hibernate e por outras inovaçőes hoje presentes no Java EE 5 (como configuraçăo via anotaçőes). O resultado é a JPA, que tende a se tornar o novo padrăo dominante (veja o tópico "A Java Persistence API"). O mundo do desenvolvimento Java é amplo o bastante para comportar diversas soluçőes de persistęncia, e o JDO sem dúvida continua tendo bom suporte e um futuro tranqüilo para quem o adotar. Mas a tecnologia está de certa forma na "segunda divisăo" – ex.: todos os principais IDEs para Java já possuem ou estăo preparando suporte integrado e completo ŕ JPA, mas o suporte para o JDO é inferior (ou inexistente) e năo há perspectiva que atinja o mesmo nível do oferecido para JPA.
O projeto JSR220-ORM da Fundaçăo Eclipse começou com planos de suportar tanto a API de persistęncia do entăo futuro EJB 3.0 quanto a JDO 2.0, mas após o sucesso da JPA ficar evidente, abandonou a JDO até segundo aviso.


Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.