


Conhecer a terminologia e os conceitos envolvidos em soluÁıes de storage È essencial para todo profissional que administra aplicaÁıes que delas dependem (bancos de dados, e-mail, servidor de arquivos, dentre outras).
De uma dÈcada para c·, o storage corporativo se tornou cada vez mais presente na infraestrutura de TI das empresas. … um equipamento fundamental para quem deseja disponibilidade e alto desempenho. O problema È que, por se tratar de uma tecnologia relativamente recente, e que poucos profissionais, particularmente em inÌcio de carreira, tÍm a oportunidade de conhecer de perto, acaba se criando um mito em torno do assunto, o que sÛ contribui para a falta de informaÁ„o. E porque È importante conhecer o storage? Porque o volume de dados vem crescendo em um ritmo vertiginoso, e nada indica que essa tendÍncia v· mudar nos prÛximos anos. Para lidar com volumes de dados multi-terabyte, o armazenamento local (disco interno) simplesmente n„o È uma opÁ„o. Fora isso, conforme o volume de dados aumenta, em muitos casos a demanda por desempenho aumenta, logo È necess·rio um equipamento que tenha os recursos e a robustez necess·ria para suportar essa demanda.
Com base em tudo o que foi citado, este artigo se propıe a desmistificar o storage ao abordar os principais assuntos relacionados de forma clara e objetiva. A ideia n„o È que o leitor se transforme em um especialista em storage da noite para o dia, mas sim que o conte˙do exposto aqui sirva de ponto de partida para um aprendizado mais profundo, sem deixar de lado a necessidade do saber pr·tico para o dia a dia.
ConfiguraÁ„o FÌsica
Neste tÛpico mostraremos os componentes de hardware mais comuns em uma soluÁ„o de storage, bem como um exemplo de arquitetura tÌpica de SAN.
Hardware
Como usu·rios finais de um storage corporativo, vemos apenas os discos acessÌveis por um servidor. Para nÛs e para o servidor È transparente se esse disco È local ou se faz parte de uma SAN (Storage Area Network). A seguir, descrevemos os equipamentos necess·rios para que uma soluÁ„o desse tipo funcione corretamente.
Storage
O storage È um equipamento que permite a instalaÁ„o de uma grande quantidade de discos de tipos diversos (veja o BOX 1) e possui formas de conectividade para permitir o acesso por diversos servidores. O storage È tipicamente composto por:
∑ Controladoras ou storage processors (Figura 1), que gerenciam toda a configuraÁ„o do equipamento, a conectividade externa, o acesso aos discos e ao cache de dados. Normalmente h· mais de uma, para redund‚ncia em caso de falha;
∑ Gavetas ou Drive enclosures (Figura 2), que s„o os acessÛrios que recebem os discos.
Os equipamentos mais sofisticados s„o construÌdos de forma modular, de modo que È possÌvel a expans„o pela adiÁ„o de mais controladoras ou drive enclosures posteriormente. Na Figura 3 È possÌvel ver um storage completo com seus mÛdulos montado em rack.

Figura 1. Storage Processor.

Figura 2. Drive Enclosure.

Figura 3. Storage montado em rack, vis„o frontal.
Os equipamentos atuais suportam o que h· de mais moderno em tecnologia de disco. Internamente os discos de tecnologia tradicional (placas giratÛrias com cabeÁas de leitura) s„o bastante similares. Eles diferem no tipo de conex„o e na velocidade de rotaÁ„o. Quanto maior a rotaÁ„o, maior o desempenho. A seguir, temos uma breve descriÁ„o dos tipos mais comuns:
FC (Fiber Channel): S„o discos de alto desempenho, com opÁıes de 10.000 e 15.000 RPM, muito utilizados em equipamentos de grande porte. Atualmente s„o oferecidos em tamanhos diversos, que podem variar de 146 GB a 2 TB;
SAS (Serial Attached SCSI): S„o discos de alto desempenho que utilizam a conex„o SAS de 6 Gbps, com opÁıes de 10.000 e 15.000 RPM, muito utilizados em equipamentos de pequeno a grande porte. Atualmente s„o oferecidos em tamanhos de 300, 450 e 600 GB;
NL-SAS (Near-Line SAS): S„o discos de baixo custo que utilizam a conex„o SAS. Normalmente com velocidade de 7.200 RPM, s„o utilizados para dados que n„o possuem alta demanda de acesso, como dados histÛricos, por exemplo. Atualmente s„o oferecidos em tamanhos de 1 a 3 TB;
SATA (Serial ATA): S„o discos de baixo custo que utilizam a conex„o SATA (Serial ATA) de 3 Gbps. S„o encontrados em equipamentos um pouco mais antigos e possuem funÁ„o similar ý dos discos NL-SAS;
SSD (Solid State Disk): S„o discos baseados em memÛria flash, que oferecem o melhor desempenho entre todos os tipos mencionados acima, por n„o possuÌrem partes mÛveis. … uma tecnologia recente e bastante promissora, e por isso, ainda muito cara para uso em larga escala. S„o utilizados em aplicaÁıes onde o m·ximo desempenho È essencial.
Switch
Os switches (Figura 4) tÍm o papel de implementar a conectividade entre os servidores e o storage. Normalmente È utilizado mais de um, tambÈm por questıes de redund‚ncia.
A conex„o com os servidores È feita a partir de cabos, cujo tipo varia de acordo com o switch utilizado. Os tipos mais comuns atualmente s„o:
∑ Fiber Channel (FC), que utiliza fibra Ûtica para o tr·fego de dados, e que suporta desde dist‚ncias pequenas (atÈ 100m, chamada ìshortwaveî) atÈ grandes dist‚ncias (atÈ 50 km, chamada ìlongwaveî). Conexıes FC utilizam um tipo de switch especial comumente chamado de ìSAN switchî;
∑ iSCSI (Internet SCSI), que utiliza switches de rede comuns e cabos de rede UTP (par tranÁado) ou fibra Ûtica.
As conexıes FC podem operar em velocidades que variam de 1 a 16 Gbps, sendo que as mais comuns atualmente s„o de 4 e 8 Gbps. As conexıes iSCSI dependem da infraestrutura de rede, e podem utilizar conexıes de 1 ou 10 Gbps, dependendo do switch de rede utilizado.
O fato de a tecnologia iSCSI utilizar switches de rede comuns traz uma grande vantagem em termos de custo, pelo fato desta infraestrutura j· existir nas empresas, mas normalmente com desempenho inferior aos switches FC (Fiber Channel), devido ao fato de trafegar comandos SCSI sobre o protocolo TCP/IP, o que tem um impacto significativo. Switches FC È a escolha comum em soluÁıes que demandam alto desempenho.
As conexıes FC e iSCSI de 10 Gbps, que utilizam fibras Ûticas como meio, necessitam de transceivers (conversores de mÌdia) para cada porta de conex„o. Esses conversores (veja a Figura 5) se chamam GBIC (Gigabit Interface Converter), e servem para converter o sinal da fibra (luz) para o sinal eletrÙnico do switch e vice-versa. Na Figura 6 È possÌvel ver um exemplo de conector de fibra Ûtica, utilizado para conex„o com GBICs.
… comum se utilizar o termo ìfabricî para descrever o switch SAN.

Figura 4. Switch SAN. Repare nas portas vazias, prontas para receber as GBICs.

Figura 5. GBIC ñ Gigabit Interface Converter

Figura 6. Conector de fibra Ûtica
HBA (Host Bus Adapter)
HBA (Figura 7) È a placa que instalamos nos servidores para permitir a conectividade com a SAN. Normalmente possuem duas portas (para redund‚ncia) eexistem modelos especÌficos para conexıes FC e iSCSI (no caso do iSCSI, podem ser utilizadas atÈ placas de rede comuns).
A HBA utilizada em conexıes FC possui um identificador ˙nico chamado WWN (World Wide Name), que possui papel similar a um endereÁo MAC de uma placa de rede. Esse identificador È utilizado nas configuraÁıes realizadas nos switches SAN para identificar as conexıes de cada servidor.

Figura 7. HBA ñ Host Bus Adapter.
Todos esses equipamentos se comunicam utilizando os comandos do protocolo SCSI (Small Computer System Interface), criado nos anos 80 e que originou diversos conectores, que comeÁaram a cair em desuso com a chegada do SAS (que significa Serial Attached SCSI, uma evoluÁ„o dos padrıes anteriores). Os conectores SCSI se foram, mas o protocolo permaneceu.
Arquitetura FÌsica TÌpica
Um disco tradicional funciona dentro do servidor, com dist‚ncias de cabos pequenas (10-20 cm) e com cabeamento e conectores protegidos pelo gabinete. Quando falamos de SAN, os equipamentos muitas vezes est„o em racks separados, e ýs vezes atÈ em prÈdios separados, o que traz um fator de risco adicional ý soluÁ„o. Por esse motivo a redund‚ncia È fundamental em uma soluÁ„o de storage.
No diagrama apresentado na Figura 8 podemos ver uma arquitetura tÌpica de SAN: um storage com duas controladoras que possuem duas portas cada, dois switches SAN e alguns servidores. Cada controladora passa por cada um dos switches, e cada porta das placas HBA dos servidores tambÈm v„o para switches separados. Dessa forma, se um switch,uma controladora ou uma porta de HBA falhar, o sistema inteiro continua a funcionar.
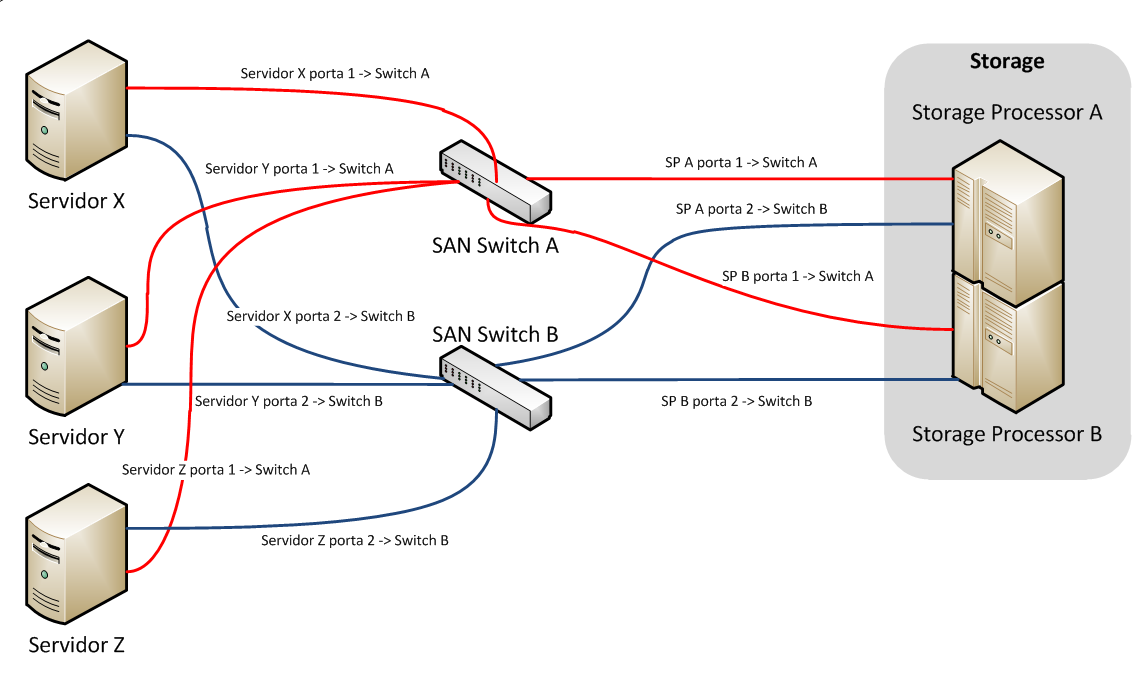
Figura 8. Arquitetura TÌpica de uma SAN
ConfiguraÁ„o lÛgica
Depois de explicar os componentes fÌsicos da soluÁ„o, vamos ý configuraÁ„o lÛgica dos equipamentos.
Uma vez que o storage esteja instalado (processo que normalmente È feito pelo fabricante), os servidores com suas placas HBA, e tudo isso conectado atravÈs de switches SAN, como no desenho da Figura 8, temos duas tarefas importantes:
∑ ConfiguraÁ„o dos discos: È a configuraÁ„o dos discos para permitir que sejam utilizados pelas aplicaÁıes;
∑ ConfiguraÁ„o da conectividade: È a configuraÁ„o que permite que todos os equipamentos se comuniquem entre si, e mais importante, que n„o acessem recursos indevidamente.
ConfiguraÁ„o dos discos ñ O que È RAID ?
Quando pensamos em storage corporativo, 100% das vezes pensamos em RAID. O RAID traz diversas vantagens em relaÁ„o ý configuraÁ„o de um disco stand alone, como por exemplo, seguranÁa e melhor desempenho. Aqui vale uma pausa para discutirmos o que È RAID. O termo RAID significa Redundant Array of Independent Disks, eÈ uma tecnologia que permite o agrupamento lÛgico de discos (array) para obter melhor desempenho, seguranÁa ou custo.O RAID È classificado em nÌveis (levels), que determinam o funcionamento dos discos na configuraÁ„o selecionada, e o tipo de redund‚ncia.
Para determinar o nÌvel de RAID ideal para cada caso sempre devem levar em conta trÍs fatores: custo, desempenho e seguranÁa de dados. Normalmente quando obtÈm o melhor em dois desses fatores, se perde no terceiro. … tudo uma quest„o de escolher o mais apropriado para cada necessidade.
Existem v·rios nÌveis de RAID, mas os que foram consagrados pelo uso e, portanto s„o os mais comuns, s„o apresentados a seguir:
∑ 0 (striping): … o nÌvel de RAID que oferece o melhor desempenho e custo, com a contrapartida de n„o oferecer seguranÁa. Os dados s„o distribuÌdos pouco a pouco em cada disco do array, o que faz com que o acesso de leitura e escrita seja muito r·pido, mas em caso de perda de um disco, o array inteiro falha. SÛ È utilizado em situaÁıes particulares onde a seguranÁa de dados n„o È importante (por exemplo, discos tempor·rios para renderizaÁ„o de vÌdeos, que demandam alto desempenho, mas que o processo pode ser reiniciado caso os discos falhem);
∑ 1 (mirroring - espelhamento): Oferece Ûtima relaÁ„o entre desempenho e seguranÁa, com o custo de utilizar no mÌnimo metade do espaÁo total para garantir a redund‚ncia. Todos os dados que s„o gravados em um disco s„o automaticamente gravados em um ou mais discos, o que garante a seguranÁa dos dados caso um disco falhe. Teoricamente, no entanto, È possÌvel utilizar mais de dois discos em RAID 1, o que aumentaria o n˙mero de cÛpias dos dados (um array RAID 1 com trÍs discos, por exemplo, possui o dado original em um disco mais duas cÛpias), mas na pr·tica isso n„o È comum. Normalmente s„o utilizados apenas dois discos para formar um array RAID 1, que tolera a perda de apenas um disco;
∑ 10 (striping de mirror): Funciona como um array RAID 0 construÌdo no topo de dois ou mais arrays RAID 1. Com isso oferece desempenho prÛximo ao do RAID 0 com a redund‚ncia do RAID 1. … o nÌvel mais indicado quando se deseja m·ximo desempenho com seguranÁa, mas È o mais caro de todos: utiliza metade do espaÁo total para redund‚ncia, como no RAID 1, e s„o necess·rios ao menos quatro discos para formar um array RAID 10.
Para este nÌvel de RAID, o mecanismo de toler‚ncia a falhas È um pouco mais complicado. Um array RAID 10 tolera a perda de atÈ um disco por ìarrayî RAID 1, ou seja, se temos seis discos em RAID 10, podemos pensar em trÍs pares de discos em RAID 1 unidos para formar um array RAID 0. Nesse caso, podemos perder atÈ um disco de cada par, mas n„o os dois discos de um mesmo par;
∑ 5 (striping com paridade distribuÌda): Oferece Ûtima relaÁ„o entre custo e seguranÁa, mas o desempenho de escrita È abaixo dos demais devido ao esforÁo de manutenÁ„o dos dados de paridade, que servem para reconstruir o array no caso de falha de um disco. Utiliza normalmente o espaÁo de um disco apenas para manter a redund‚ncia, e s„o necess·rios no mÌnimo trÍs discos para formar um array RAID 5. Tolera a perda de atÈ um disco.
O c·lculo de paridade, que garante a seguranÁa do RAID 5, funciona da seguinte forma: pense em trÍs discos idÍnticos, onde todas as posiÁıes de gravaÁ„o de dados possuem um endereÁo especÌfico que seja comum a todos os discos, ou seja, a terceira posiÁ„o de todos os discos se chama ì3î, por exemplo. Ao gravar um bit em um determinado endereÁo, a controladora RAID faz um c·lculo (XOR, operador lÛgico ìou exclusivoî) entre esse bit e o bit do endereÁo trÍs de um dos discos vizinhos, gerando um terceiro bit, que È o bit de paridade. Esse bit de paridade ser· gravado no endereÁo trÍs de um disco diferente dos dois utilizados para o c·lculo. Isso È realizado para todos os dados que s„o gravados em um array RAID 5, e esse processo È feito de uma forma que a cada dado gravado, a combinaÁ„o de discos utilizados para gerar a paridade e o disco utilizado para grav·-la sejam diferentes. Dessa forma, quando um disco È perdido, È possÌvel reconstruir os seus dados a partir dos dados e bits de paridade dos demais;
∑ 6 (striping com dupla paridade): Similar ao RAID 5, mas grava dois bits de paridade para cada bit gravado. Por isso tem desempenho de escrita fraco, mas tem a grande vantagem de suportar a falha de atÈ dois discos do array.
Para concluir, vale notar que boa parte dos equipamentos atuais de storage suporta a configuraÁ„o de um ou mais discos como hot-spare, que tÍm a funÁ„o de ìestepeî em situaÁıes de falha. Nesses casos, o storage, ao detectar uma falha, pode iniciar um rebuild do array utilizando o disco de spare automaticamente, sem intervenÁ„o humana.
SeleÁ„o do nÌvel de RAID
Para determinar qual nÌvel de RAID devemos utilizar, È preciso pensar em quatro questıes importantes:
∑ Quanto espaÁo È necess·rio?
∑ Qual È o orÁamento?
∑ Qual È a necessidade de seguranÁa?
∑ Qual È a necessidade de desempenho?
Na pr·tica, essas perguntas devem vir antes da compra dos equipamentos, para determinar a configuraÁ„o do equipamento a ser comprado. No entanto, para o nosso exercÌcio mental de n„o especialistas, vale fazÍ-las agora, supondo que temos ao nosso dispor todos os recursos que desejarmos (a realidade normalmente È bem diferente).
Conhecer bem os nÌveis de RAID, ao ponto de sugerir com autoridade qual deve ser utilizado, È fundamental para todo profissional de infraestrutura, atÈ para evitar generalizaÁıes do tipo ìRAID 5 È ruimî ou ìRAID 10 È o melhorî. Cada um È mais apropriado para determinado caso.
Para responder ýs trÍs primeiras perguntas, n„o È preciso um grande esforÁo, e elas est„o intimamente ligadas. No entanto, a resposta ý quest„o do desempenho È a mais complicada e que exige mais atenÁ„o. Na seÁ„o final deste artigo, que fala de workloads e IOPS, podemos ver uma explicaÁ„o detalhada sobre a relaÁ„o entre workload, IOPS e nÌvel RAID, bem como exemplos dessa lÛgica.
Uma vez determinado o nÌvel RAID, podemos criar nosso primeiro array de discos, tambÈm conhecido como RAID group. Esse array deve ser dividido em Logical Units, ou LUNs (LUN no singular). A logical unit È como uma partiÁ„o de disco, sÛ que de fato È a partiÁ„o de um array, que por sua vez È a uni„o de v·rios discos (partiÁ„o da uni„o?!?). Simplificando: os discos s„o unidos fisicamente como um array com a configuraÁ„o de nÌvel RAID, e depois divididos logicamente em LUNs para serem acessados pelos servidores. Uma vez que a LUN seja apresentada ao servidor, este passa a trat·-la como um disco comum, que deve ser formatado para depois ser utilizado.
ConfiguraÁ„o da conectividade
Para que o disco possa ser apresentado ao servidor, existem mais alguns passos a serem realizados, que est„o relacionados ý seguranÁa:
∑ Zoning: È a configuraÁ„o feita no switch SAN que diz quais portas falam com quais. Normalmente È feita de forma que a HBA de um servidor acesse somente a HBA da controladora do storage, de modo a n„o permitir acessos indevidos;
∑ ConfiguraÁ„o de Storage Groups: È a configuraÁ„o feita no storage que diz quais LUNs podem ser acessadas por quais servidores. … a segunda camada de proteÁ„o a acessos indevidos, ao n„o permitir que um servidor acesse um disco que n„o lhe pertence. Aqui vale um parÍntese: em ambientes de cluster, onde dois ou mais servidores precisam acessar um determinado disco, todos os servidores devem fazer parte do mesmo storage group que os discos, e o controle de qual servidor acessa qual disco È feito via software.
O ato de adicionar uma LUN a um storage group existente configura o ato de apresentar o disco para o servidor. A partir deste momento, o disco estar· visÌvel para o sistema operacional.
ConcluÌdas estas tarefas, o storage est· pronto para ser utilizado.
Funcionalidades importantes
ApÛs ler a explicaÁ„o atÈ aqui, deve estar claro que o storage oferece uma sÈrie de vantagens em relaÁ„o a uma configuraÁ„o de disco interno, principalmente na capacidade de implementar soluÁıes de alto desempenho.
AlÈm disso, o storage normalmente possui uma sÈrie de funcionalidades adicionais que s„o menos conhecidas, mas n„o menos importantes, do ponto de vista de gerenciamento. A seguir est„o descritas algumas dessas funcionalidades:
∑ Clone: È a capacidade de clonar os dados de uma determinada LUN. A vantagem do clone em comparaÁ„o a uma cÛpia de arquivos do sistema operacional, È que o clone ocorre inteiro dentro do storage, sem tr·fego pela SAN, e por isso tende a ser muito mais r·pido. … ˙til em migraÁıes de servidores onde se deseja ter um backup completo e r·pido;
∑ Snapshot: È a capacidade de tirar uma ìfotografiaî de uma determinada LUN em uma posiÁ„o no tempo. Snapshots normalmente s„o implementados utilizando uma tÈcnica chamada ìcopy-on-writeî, que somente grava a vers„o antiga dos dados no snapshot conforme estes s„o alterados na LUN original. Dessa forma, o snapshot tem um tamanho bastante pequeno quando criado, e vai crescendo conforme a LUN original È alterada. A funÁ„o mais importante do snapshot È permitir que se restaure o estado dos dados de uma LUN ýquele que existia no momento em que o snapshot foi criado. … ˙til em aplicaÁıes de patches, quando se deseja poder desfazer as alteraÁıes sem restaurar um backup, por exemplo;
∑ Thin provisioning: È a capacidade de alocar uma LUN que possua alocaÁ„o din‚mica, ou seja, podemos criar uma LUN ìthinî de 100 GB, mas ela sÛ ocupar· o espaÁo que estiver em uso pelo servidor, similar aos discos de crescimento din‚mico dos produtos de virtualizaÁ„o. Isso È ˙til quando n„o temos uma estimativa precisa da necessidade de alocaÁ„o de espaÁo para um servidor, e, portanto n„o queremos comprometer uma ·rea do storage desnecessariamente;
∑ Storage Pools e Tiering: È a alternativa aos arrays/RAID groups tradicionais, e que vem ganhando espaÁo ultimamente. Em vez de configurar arrays para cada aplicaÁ„o, selecionando um tipo de disco especÌfico, alguns equipamentos oferecem a opÁ„o de criar um storage pool com muitos, se n„o todos os discos do storage, misturando discos r·pidos e lentos. O storage passa ent„o a analisar a carga submetida e a identificar o perfil de acesso de cada dado. Uma vez identificado o perfil, o storage realoca dados muito acessados para discos mais r·pidos, e dados pouco acessados para discos mais lentos.
As LUNs s„o criadas diretamente sobre o storage pool, e vocÍ pode recomendar (repare o termo) em qual camada (ìtierî) de discos aquela LUN deve operar. No final, quem decide onde a LUN vai ficar È o storage, apÛs a an·lise, que tipicamente ocorre uma vez por dia. A ideia aqui È que o storage tem mais condiÁıes do que nÛs de analisar os dados de acesso para decidir onde È melhor colocar cada LUN, e ele tem a capacidade de refazer essa alocaÁ„o todos os dias. Na pr·tica, nem os fabricantes recomendam o uso de pools para aplicaÁıes que exigem m·ximo desempenho, mas para ambientes onde o desempenho n„o È t„o crÌtico, a facilidade de administraÁ„o È bastante compensadora, pois libera o administrador da tarefa de controlar a ocupaÁ„o array por array;
∑ ReplicaÁ„o block-level: È a capacidade de manter uma replicaÁ„o online de LUNs no mesmo storage ou em storages diferentes, atÈ em localidades diferentes, no nÌvel de bloco do disco, sem se importar com o conte˙do. A LUN replicada fica em um estado chamado de ìcrash-consistentî, ou seja, similar ao estado em que um disco fica quando o computador È desligado abruptamente. Contudo, com os file systems modernos (NTFS, ext3, ext4) que possuem journaling, isso normalmente n„o È um problema. Essa funcionalidade È muito ˙til para a criaÁ„o de sites de contingÍncia (disaster recovery). SoluÁıes de replicaÁ„o block-level normalmente precisam de um software opcional instalado no storage, comprado ý parte.
Workloads, IOPS, eficiÍncia de espaÁo e ìcalculadora RAIDî
Normalmente utilizamos a mÈtrica de IOPS (I/Os por segundo) para falar de desempenho, ou mais especificamente de carga de trabalho (workload), quando vamos especificar a necessidade de desempenho de um array de discos para uma determinada aplicaÁ„o, e a partir dessa informaÁ„o realizar o dimensionamento apropriado. Cada tipo de disco possui um valor nominal de IOPS suportado, que somado ao tipo de RAID e ý quantidade de discos do array nos d· uma estimativa de quantos IOPS o array ir· suportar.
Na Tabela 1 podemos ver uma lista de valores tÌpicos de IOPS para modelos comuns de disco, retirada do manual de um equipamento de porte intermedi·rio de um grande fabricante do mercado (considerando I/O randÙmico, pior caso).
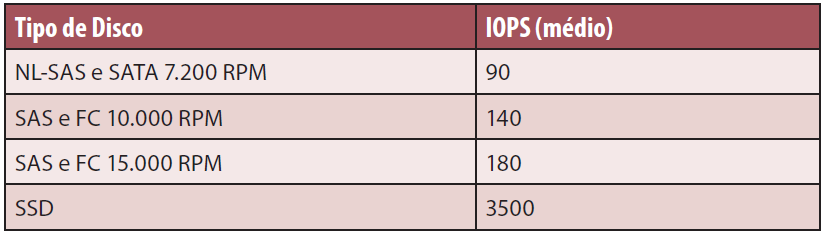
Tabela 1. Valores mÈdios de IOPS por tipo de disco.
Cada nÌvel de RAID, devido ýs suas particularidades de implementaÁ„o, possui determinado fator de impacto de escrita. O fator de impacto funciona como um multiplicador, de modo que para obtermos a quantidade real de escritas que ser„o realizadas no array, È preciso multiplicar a quantidade de escritas realizadas pelo sistema operacional pelo fator de impacto.
Quanto maior o fator de impacto, menor o desempenho de escrita no array. A Tabela 2 mostra os fatores de impacto para os nÌveis de RAID mais comuns.
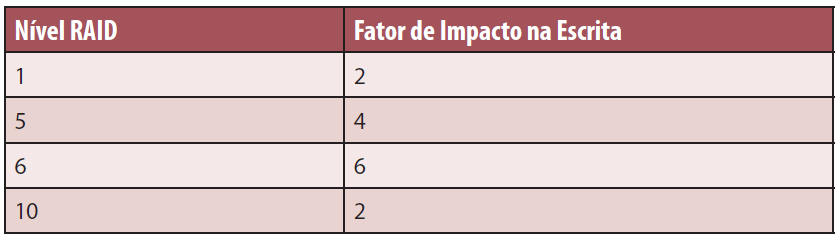
Tabela 2. Fatores de Impacto de Escrita por nÌvel de RAID.
Quando dizemos que o RAID 5 possui impacto 4, isso significa que para cada escrita realizada por uma aplicaÁ„o no servidor, o storage ir· realizar 4 escritas nos discos que compıem o array.
Outra informaÁ„o importante È a eficiÍncia de espaÁo de cada nÌvel de RAID. Precisamos desses valores para determinar qual ser· o espaÁo ˙til do nosso array. Na Tabela 3 podemos ver as fÛrmulas de eficiÍncia de espaÁo para os nÌveis de RAID mais comuns.

Tabela 3. EficiÍncia de EspaÁo por nÌvel de RAID.
Resumindo, para determinar a configuraÁ„o de um array È preciso considerar:
∑ Capacidade de IOPS do tipo de disco selecionado;
∑ DistribuiÁ„o do I/O entre leituras e escritas (percentual de cada), para avaliar o impacto da escolha do nÌvel do RAID;
∑ EficiÍncia do nÌvel do RAID escolhido, para determinar quanto espaÁo ˙til ter· disponÌvel.
Outra informaÁ„o importante È o tipo de I/O realizado pela aplicaÁ„o, se sequencial ou randÙmico. No nosso caso, como estamos utilizando valores de IOPS pensando em acesso randÙmico, que È o pior caso, podemos ignorar essa informaÁ„o (o arquiteto de storage normalmente n„o pode, mas nÛs n„o somos os especialistas aqui).
Tomando como base os n˙meros das Tabelas 1, 2 e 3, podemos pensar em uma sÈrie de c·lculos para nos guiar no dimensionamento de arrays.
Para exercitar os conceitos apresentados, propomos dois exemplos aqui, que demonstram bem a complexidade do assunto storage, e que servir„o como base para o c·lculo de dimensionamento.
Exemplo 1: Dimensione um array de discos em um storage para suportar um banco de dados de 5 TB. Temos a informaÁ„o de que È um banco de dados com grande volume de transaÁıes durante o dia, que em momentos de pico atinge 5.000 IOPS, e que 60% desse acesso È de escrita.
Ao analisar o enunciado do problema, podemos perceber que:
∑ 60% do acesso È de escrita. Assim sendo, n„o faz sentido escolhermos um nÌvel de RAID que penalize muito a escrita, como os nÌveis 5 ou 6. Por se tratar de um banco de dados, podemos supor que h· a necessidade de redund‚ncia, o que faz com que descartemos o nÌvel 0. Nossa escolha nesse caso ser· pelo RAID 10;
∑ Comparando a demanda de IOPS (5.000) com o volume de IOPS mÈdio suportado por um disco r·pido, n„o-SSD (180, de acordo com a Tabela 1), podemos perceber que precisaremos de muitos discos:
5.000 IOPS / 180 IOPS por disco = 27,7 discos
∑ Ao considerarmos que 60% desse acesso È de escrita, e o fator de impacto de escrita do RAID 10 È 2, de acordo com a Tabela 2, temos o seguinte c·lculo:
( ((5000 * 60%) * 2) + (5000 * 40%) ) / 180 = 44,4 discos
Decompondo a fÛrmula, temos que:
60% de 5000 IOPS de escrita = 3000 IOPS
40% de 5000 IOPS de leitura = 2000 IOPS
3000 IOPS de escrita * 2 (fator de impacto de escrita do RAID 10) = 6000 IOPS
Total de IOPS = 6000 + 2000 = 8000 IOPS
8000 (Total de IOPS) /180 (IOPS por disco) = 44,4 discos
Desse exemplo, podemos derivar a seguinte fÛrmula:
D = ( ((iops * w) * i) + (iops * r) ) / iops_avg
Onde:
D: Total de discos a ser utilizado;
iops: Total de IOPS para o qual se deseja dimensionar o array;
i: fator de impacto de escrita para o nÌvel de RAID;
w: percentual de escrita dos IOPS totais;
r: percentual de leitura dos IOPS totais;
iops_avg: IOPS mÈdio do tipo de disco a ser utilizado no array;
ApÛs calcular a quantidade de discos necess·ria, È preciso definir o tamanho do disco a ser utilizado. Ao consultar a Tabela 3 podemos obter a fÛrmula de eficiÍncia de espaÁo do RAID 10, que È x/2, onde x È a capacidade somada de todos os discos. Pelo c·lculo anterior, identificamos que precisamos de 5 TB em 44 discos. Logo, temos:
5000 = 44x/2
ou
x = 10000/44
x = 227 GB por disco
Arredondando o resultado obtido para o prÛximo tamanho comum de disco, temos discos de 300 GB. Para confirmarmos se o nosso c·lculo est· correto, podemos inverter a conta, e com o tamanho de disco proposto, temos:
(300*44)/2 = 6600 GB
Assim, com 44 discos FC ou SAS de 15.000 RPM e 300 GB, conseguimos atender ý demanda do nosso banco de dados com folga.
Exemplo 2: Dimensione um array de discos em um storage para suportar um servidor de arquivos de 10 TB. Temos a informaÁ„o de que È um servidor de arquivos pouco utilizado, com muitos dados histÛricos, que em momentos de pico atinge 500 IOPS, e que 80% desse acesso s„o de leitura.
Ao analisar o enunciado do problema, podemos perceber que:
∑ 80% do acesso s„o de leitura e precisamos de 10 TB ˙teis. Nesse caso, podemos escolher um nÌvel de RAID mais econÙmico, como o 5 ou 6. Para efeito de comparaÁ„o, faremos a conta com os dois;
∑ Se o servidor de arquivos È pouco utilizado, podemos configurar o nosso array com discos mais lentos e baratos. Escolhemos, ent„o, os discos NL-SAS de 7200 RPM, que fazem 90 IOPS cada.
A seguir È apresentado o exemplo de c·lculo para um RAID 5 com discos NL-SAS de 7200 RPM:
Quantidade de IOPS mÈdio do disco NL-SAS 7200 RPM (Tabela 1): 90
Fator de impacto do RAID 5 (Tabela 2): 4
EficiÍncia de espaÁo do RAID 5 (Tabela 3): 1-1/n
Repetindo a fÛrmula do exemplo anterior, temos:
( ((500 * 20%) * 4) + (500 * 80%) ) / 90 = 8,88 discos
Arredondando para o inteiro mais prÛximo, temos 9 discos em RAID 5.
Para determinar o tamanho do disco desejado, utilizamos a fÛrmula de eficiÍncia do RAID 5:
1-(1/9) = 0,89
10 TB (total de espaÁo necess·rio) / 9 discos / 0,89 = 1,25 TB por disco
Agora, faremos o c·lculo considerando o uso de RAID 6 com discos NL-SAS de 7200 RPM:
Quantidade de IOPS mÈdio do disco NL-SAS 7200 RPM (Tabela 1): 90
Fator de impacto do RAID 6 (Tabela 2): 6
EficiÍncia de espaÁo do RAID 6 (Tabela 3): 1-2/n
Repetindo a fÛrmula do exemplo anterior, temos:
( ((500 * 20%) * 6) + (500 * 80%) ) / 90 = 11,11
Arredondando para o inteiro mais prÛximo, temos 11 discos em RAID 6.
Para determinar o tamanho do disco desejado, utilizamos a fÛrmula de eficiÍncia:
1-(2/11) = 0,81
10 TB (total de espaÁo necess·rio)/ 11 discos / 0,81 = 1,12 TB por disco
Nos dois casos, arredondando o resultado para o prÛximo tamanho de disco existente no mercado, temos discos de 1,5 TB. Se optarmos pelo RAID 6, ser„o necess·rios dois discos a mais, porÈm com suporte ý falha de atÈ dois discos, o que pode ser uma vantagem dependendo da import‚ncia dos dados em quest„o.
Conclus„o
Neste artigo foram apresentados os principais componentes envolvidos em uma soluÁ„o de storage corporativo, as principais configuraÁıes necess·rias e foi fornecida uma explicaÁ„o sobre RAID e suas indicaÁıes. AlÈm disso, foram mostrados exemplos de workload e de dimensionamento para volume e desempenho.
… importante reforÁar que sempre devemos confiar o trabalho de configuraÁ„o ao arquiteto ou administrador do storage, que tem a experiÍncia para avaliar todos os par‚metros necess·rios e tomar a melhor decis„o possÌvel. Estes profissionais normalmente precisam levar em consideraÁ„o outros fatores ao desenhar uma soluÁ„o de storage, como o n˙mero Ûtimo de discos por array dependendo do nÌvel de RAID e a quantidade de discos disponÌvel. A quest„o È que, apesar de ser o especialista em storage, nem sempre esse tÈcnico È especialista na sua aplicaÁ„o, e aÌ È importante saber falar a ìlÌnguaî do storage para conseguir estabelecer essa ponte e obter o melhor resultado possÌvel.

Utilizamos cookies para fornecer uma melhor experiÍncia para nossos usu·rios, consulte nossa polÌtica de privacidade.