Neste artigo, apresentaremos desde os primórdios do código Morse e da tabela ASCII, até o nascimento do padrăo Unicode, para explicar como funcionam os sistemas de codificaçăo e seus principais problemas dentro da plataforma Java.
Em que situaçăo o tema é útil:
Quem ainda năo teve problemas de codificaçăo certamente um dia terá. Com base nisso, este artigo visa auxiliar na reduçăo do sofrimento causado por este tipo de problema e ainda diminuir o tempo gasto com soluçőes baseadas em tentativa e erro.
Desvendando os mistérios do Charset:
Este artigo tem como objetivo chamar a atençăo para um tema complicado e que a maior parte dos desenvolvedores acaba dando pouca importância no dia a dia. Para isso vamos apresentar as origens dos sistemas de codificaçăo e uma série de dicas para ajudar a resolver problemas e evitar dores de cabeça no futuro.
Quem nunca passou vergonha na hora de apresentar um software recém-implementado e se surpreendeu com caracteres estranhos, e até misteriosos, tomando o lugar da acentuaçăo das palavras?
Esse tipo de problema é extremamente comum e costuma acompanhar a maior parte dos desenvolvedores de software ao longo de suas vidas profissionais. Entretanto, tentar resolvę-lo na base da tentativa e erro ou ainda recorrendo a outros tipos de cięncias esotéricas pode năo dar certo e ainda prolongar o sofrimento.
Na maior parte das vezes é extremamente simples resolver esse tipo de mal entendido entre diferentes sistemas de codificaçăo, no entanto, como várias partes do software e principalmente de seu ambiente săo afetadas, pode ser traumático encontrar o local exato para efetuar os ajustes.
Neste artigo, vamos a fundo ŕs raízes do problema, apresentando desde os primórdios do código Morse e da tabela ASCII, até o nascimento do padrăo Unicode, para explicar como funcionam os mecanismos de conversăo de caracteres nas profundezas do Java.
Tudo começou com o Código Morse
Em 1836, Samuel F. B. Morse, Joseph Henry e Alfred Vail desenvolveram um importante meio de comunicaçăo, baseado na transmissăo de pulsos elétricos, conhecido como telégrafo. Na época, o sistema de codificaçăo utilizado para transmitir mensagens de maneira rápida e confiável era o código Morse. Este consistia na representaçăo das letras do alfabeto e números por meio de pulsos elétricos longos e curtos, como pode ser visto na Figura 1.
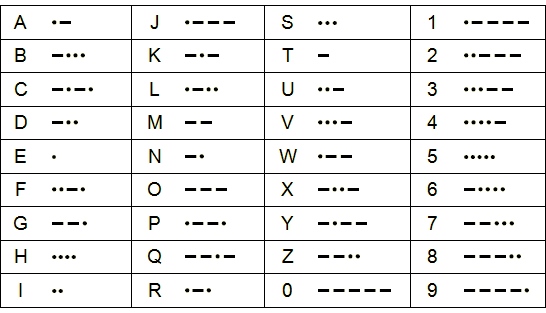
Figura 1. Código Morse com seus pulsos longos e curtos.
Em suas primeiras versőes, o código Morse năo contava com letras minúsculas, acentuadas ou mesmo sinais de pontuaçăo, e foi sendo estendido ao longo do tempo conforme se estabeleciam comunicaçőes entre diferentes idiomas. Muitos anos mais tarde, o mesmo processo de evoluçăo ocorrido com o código Morse foi acontecendo com os sistemas de codificaçăo dos computadores, que veremos a seguir.
Entendendo os sistemas de codificaçăo de caracteres
Um sistema de codificaçăo de caracteres, ou character encoding, consiste em uma forma de associar um determinado conjunto de letras, números e símbolos, a um tipo de representaçăo – números binários, hexadecimais ou mesmo pulsos elétricos – com o objetivo de facilitar a transmissăo e o armazenamento dos dados.
Em 1963, a American Standards Association criou uma tabela de codificaçăo de caracteres chamada ASCII, com o objetivo de padronizar o sistema de codificaçăo utilizado na época, quando era comum que cada fabricante criasse seus próprios sistemas, o que causava incompatibilidade entre diferentes plataformas.
Essa tabela utilizava um conjunto de 7 bits para representar 128 caracteres, o que era suficiente para exibir todas as palavras e símbolos mais utilizados em textos escritos na língua inglesa. Entretanto, para os idiomas latinos, que em geral possuem muitas palavras acentuadas, além de outros tipos de pontuaçăo, o ASCII năo era suficiente. Por esse motivo, a ISO (International Standards Organization) criou várias extensőes (norma 8859) baseadas na tabela ASCII, com 8 bits, para suprir as necessidades de diversos países e idiomas.
Ao todo, existem cerca de 16 variaçőes da codificaçăo ISO-8859, onde uma das mais utilizadas é a ISO-8859-1, ou Latin-1, adotada em boa parte da Europa, África e, principalmente nas Américas, por dar suporte completo aos idiomas portuguęs, espanhol, alemăo, italiano e inglęs.
O nascimento do padrăo Unicode
O Unicode foi criado no fim da década de 80 por Joe Becker da Xerox e Lee Collins da Apple com o objetivo de ser um padrăo de codificaçăo de caracteres mundialmente aceito e que fosse capaz de resolver o problema de incompatibilidade entre os diferentes sistemas de codificaçăo de caracteres utilizados na época.
Somente o idioma japonęs possui tręs sistemas de escrita: Hiragana, Katakana e Kanji. Este último é formado por cerca de 40 mil kanjis, ou ideogramas, que representam ideias, conceitos e que podem ter mais de um significado. Conjuntos de caracteres complexos como este năo poderiam ser representados pelos apenas 8 bits dos sistemas de codificaçăo mais tradicionais, como os da norma ISO-8859.
...









