


Em que situaçăo o tema é útil
Muitos dos cases de
sucesso do mercado nacional e/ou internacional ainda tęm uma postura reativa em
relaçăo ŕ TI para suporte aos negócios (produtos e serviços) que tais empresas
entregam. O Splunk é um software que permite que a organizaçăo passe a ter uma
visăo mais proativa com base nas informaçőes que elas nem sabem que possuem
(Big Data) e, na maioria das vezes, informaçőes que podem trazer, além de
melhor suporte ŕ decisăo, mais inteligęncia competitiva para manter os negócios
de maneira mais confiável por parte da TI. Assim, tem-se maior visibilidade
operacional em relaçăo ŕ capacidade instalada, além da informaçăo necessária
para manter as estratégias de crescimento da empresa em tempo real.
Splunk: Monitorando o ambiente de
TI – Parte 1
O Splunk é uma ferramenta
que permite coletar, indexar e analisar a informaçăo gerada pelo negócio,
também conhecida pelo nome de dados de máquina. A partir da coleta e da
indexaçăo de toda a informaçăo de syslog de uma máquina, por exemplo, é
possível determinar vários problemas que a TI năo fazia nem ideia de que
ocorriam com o ambiente. Com isso, várias análises poderăo ser realizadas,
desde a implementaçăo de um sistema de alertas com base em uma quantidade x de
erros ou ocorręncia de determinado evento, até a apresentaçăo de gráficos que
refletem indicadores de performance do negócio, em tempo real. Tudo isso de
maneira muito fácil é rápida, o que possibilita que a organizaçăo, ou mesmo os
departamentos envolvidos, possam tomar determinadas decisőes baseadas em fatos,
sem o uso da intuiçăo.
Săo muitos os controles e métricas que normalmente săo criados para monitorar os elementos críticos que compőem o ambiente de TI de pequenas, médias e grandes empresas. Tais elementos fazem parte de um grande stack de suporte ŕs operaçőes de negócio: sistemas OLTP, bancos de dados, sistemas de entrada e saída de dados e aqueles de apoio e suporte ŕ decisăo.
Obviamente, esses săo elementos básicos, mas ainda podemos abrir o leque ou mesmo fazer um drill-down e abordar os servidores de aplicaçăo como o WebSphere, servidores web como o Apache e/ou Tomcat, ou ainda bancos de dados como Oracle, MySQL, SQL Server e sistemas desenvolvidos em Java, .NET e qualquer outra linguagem. Outros elementos compőem o que é tido como serviço networking, que é composto por vários outros pedaços como firewall, roteadores e switches, além dos vários servidores que săo controladores de domínio, DNS, servidores de impressăo e vários outros que precisam ser monitorados em tempo real para, por exemplo, saber se estăo online e servindo aos funcionários.
A grande questăo é que todos estes pontos tęm os seus controles e, na maioria das vezes, as práticas năo permitem uma análise real do que está acontecendo por debaixo de todos aqueles aparatos, uma análise completa no que diz respeito ŕ saúde dos serviços de TI que suportam o negócio.
Na maioria das vezes, quando um problema acontece, ele passa por todos os profissionais do departamento de TI e acaba no conhecido jogo de empurra entre as áreas – isso realmente acontece. Infelizmente năo existe uma ferramenta gráfica que colete a informaçăo para que se possa fazer uma análise mais detalhada sem que essa situaçăo aconteça.
Por causa disso, geralmente acontece o seguinte: alguém nota alguma instabilidade no ambiente e a comunica. É quando o gerente de área toma conhecimento da situaçăo e aciona, além de pessoal interno, uma consultoria ou mesmo uma auditoria de sistemas para dar conta do problema. Nestes casos e em muitos outros, o tempo dos profissionais envolvidos na resoluçăo reativa dos problemas toma grande parte dos recursos que a empresa poderia empregar para tornar a TI mais proativa e menos reativa. Reagir a um problema é trabalhar para colocar um sistema de volta ŕs operaçőes normais após um crash de algum dos elementos de TI já citados; ou seja, o problema já aconteceu e nesse momento a empresa parou de oferecer determinado serviço para o seu cliente.
Rotineiramente, o profissional precisa analisar vários logs utilizando um editor de textos, ou mesmo via terminal em tela preta, e tomar nota dos vários registros após consultar vários arquivos. Este processo de investigaçăo de informaçăo ou busca pela ocorręncia de um evento em vários arquivos de log pode consumir muito tempo e pessoal dedicado a realizar esse tipo de trabalho, que acaba por obter um resultado mais por inferęncia do que algo que realmente seja uma verdade com fatos a serem exibidos. Tais arquivos de log fazem parte de um conceito que é muito discutido nos dias atuais, que é o Big Data, dados que as empresas só descobrem que possuem quando precisam acessá-los, na maioria das vezes, em momentos de downtime dos sistemas (o conceito de Big Data será discutido em uma próxima oportunidade).
No entanto, hoje as empresas já estăo mais atentas em relaçăo a estes tipos de dados, procurando utilizá-los em prol da criaçăo ou da extraçăo de inteligęncia operacional e, assim, saltar em competitividade na frente de seus concorrentes. Dessa forma, alcançam mais visibilidade nos negócios e obtęm serviços com mais uptime e com equipes mais resilientes, podendo escalar menos os problemas que ocorrem no dia a dia.
Considerando o citado cenário, vamos apresentar neste artigo uma ferramenta que está revolucionando a maneira de monitorar em tempo real a TI e os negócios e ainda relacionar os dados de máquinas (ver Nota DevMan 1) gerados por devices (routers e switches), sistemas operacionais, serviços de network e vários outros pontos com dados obtidos dos negócios.
O Splunk é uma Plataforma Universal de Dados de Máquina desenvolvida por uma empresa de nome Splunk, Inc., localizada na cidade de Săo Francisco, no estado da Califórnia, EUA, que fez o IPO (veja Nota DevMan 2) há pouco tempo (Abril de 2012) e que se mantém em um crescimento enorme a cada ano. O conceito do produto é fácil de entender: basta que vocę adicione todas as fontes de dados – como logs de aplicaçőes/softwares, logs de segurança, de sistemas operacionais, logs de operaçőes de billing, logs de acesso a servidor web, logs de bancos de dados, logs gerados por roteadores e/ou switches e várias outras fontes de dados, năo importa onde elas estejam –, e inicie a coleta e a indexaçăo de tal informaçăo.
O processo usualmente referido como IPO (do inglęs Initial Public Offering) é o evento que marca a primeira venda de açőes de uma empresa no mercado de açőes. Seu principal propósito para empresas novas/pequenas é levantar capital pela sociedade para utilizar como investimento para expansăo, porém também ocorre em empresas/corporaçőes maiores por motivos de alavancagem. Após este processo, a empresa que incorre se torna uma companhia de capital aberto e passa a ser reconhecida como Sociedade Anônima ou S.A.
Com as fontes de dados configuradas, os dados serăo indexados de forma contínua, e sobre estes dados o administrador de sistemas, DBA, analista de sistemas e/ou gestor de área poderăo facilmente criar alertas e gráficos para monitoramento em tempo real dos elementos do ambiente de TI. A granularidade do monitoramento vai da necessidade dos profissionais envolvidos, pois o Splunk é capaz desde meramente monitorar um arquivo de log de forma contínua, até mesmo pesquisar toda a movimentaçăo de um usuário por todos os elementos da TI, correlacionando os vários eventos por vários arquivos de log.
A ideia é justamente obter em minutos o que é feito normalmente em horas, baseando-se em pesquisa textual, centralizaçăo da informaçăo e dados de máquina, sendo que ainda é possível contar com uma arquitetura de escala linear, o que veremos no próximo tópico.
Conhecendo o Splunk
O Splunk é o mecanismo de coleta, indexaçăo e reconhecimento automático de padrőes de informaçăo considerada como dado de máquina. Dado de máquina é tudo aquilo que é gerado para manter os serviços que săo oferecidos pela TI de uma organizaçăo funcionando satisfatoriamente. Qualquer arquivo de log, seja ele um log gerado por um firewall IronPort, um BlueCoat, ou mesmo um log de alerta do Oracle ou o log de erro do MySQL, ou ainda os logs de acesso e erros do Apache, todos estes também contęm dados de máquina que podem ser coletados e indexados de forma contínua pelo Splunk para fornecer análise do ambiente em tempo real. A Figura 1 mostra alguns exemplos de fontes de dados.
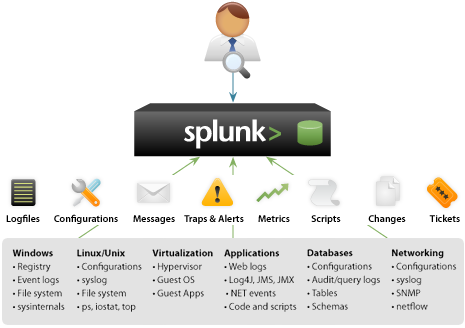
Figura 1. Fontes de dados.
O Splunk năo utiliza conectores, năo utiliza qualquer tipo de bancos de dados por trás e nem impőe limite em relaçăo ao volume de coleta e indexaçăo de informaçăo, já que estamos falando de uma ferramenta de Big Data. Vocę năo precisa se preocupar em desenvolver conectores para coletar e indexar determinados tipos de informaçăo ou mesmo desenvolver um novo pedaço de software sempre que um novo padrăo de informaçăo chegar ao mercado. O Splunk reconhece os padrőes de um arquivo de log automaticamente, faz a sua indexaçăo e armazena a informaçăo organizada em disco com 50% de taxa de compressăo. Os dados săo armazenados no formato key/value e săo gerenciados pelo próprio Splunk, que desde a versăo 4 tem uma versăo otimizada do MapReduce (ver Nota DevMan 3) com várias melhorias em relaçăo ao release do Google de 200
Toda informaçăo é armazenada em buckets, que săo a menor porçăo de dados dentro da estrutura de armazenamento de informaçăo. Tais buckets săo entăo amarrados a índices, que por sua vez săo gerenciados e também mantidos pelo Splunk em disco. O mais interessante é que vocę poderá criar índices sempre que um novo tipo de informaçăo for adicionado para ser coletado e indexado automaticamente pelo Splunk.
Os buckets podem ser ainda dos tipos hot, warm, cold e frozen (veja o subtópico a seguir). Os dados văo se movendo internamente nessa estrutura de acordo com a quantidade e a idade da informaçăo armazenada. Tal estrutura é própria do Splunk e por isso o usuário năo precisa se preocupar em ter um banco de dados para armazenar os dados coletados pela ferramenta, visto que muitas ferramentas no mercado ainda precisam ter um Oracle, SQL Server ou MySQL. No Splunk os dados văo sendo coletados e sua arquitetura acontece em tempo real, de forma que o esquema de dados é desenhado de acordo com a identificaçăo dos padrőes nos eventos dos arquivos configurados.
O Splunk coleta e indexa a informaçăo que o usuário deseja e, assim, reconhece os padrőes dentro dos eventos armazenados em arquivos de logs ou até mesmo, gerados por devices como roteadores e switches. Essa informaçăo, considerada como dados de máquina, é coletada, indexada e armazenada pelo próprio Splunk em um conjunto de arquivos que contém essencialmente dois tipos:
· Arquivos contendo dados de máquina em forma comprimida, conhecidos também como “rawdata”;
· Arquivos de índices que apontam para os arquivos de dados – rawdata – e arquivos de metadados.
Tais arquivos juntos formam os índices no Splunk, que referenciam um determinado tipo de dado de máquina coletado/indexado e que pode ser utilizado na Search App para busca e análise. Todos os dados indexados săo organizados em buckets, e estes, săo classificados em cinco formas diferentes, com base na idade dos dados. Săo elas:
· Hot: Aqui săo armazenados os eventos mais recentes. Estes buckets estăo abertos para escrita e os novos dados săo sempre escritos neles. Para sistemas 32 bits, hot buckets podem ter até 1GB de tamanho, ao passo que para sistemas 64 bits, podem ter até 10GB de tamanho antes que virem Warm buckets. Por padrăo, os hot buckets podem ser encontrados em $SPLUNK_HOME/var/lib/splunk/defaultdb/db/*. Tal localizaçăo pode ser configurada para que cada tipo de bucket seja armazenado em um disco separado, o que é considerada uma boa prática. Caso um Hot bucket năo atinja 1/10GB, em 90 dias ele será migrado para Warm com base na sua idade;
· Warm: Dentro deste tipo de informaçăo estăo todos os dados que pertencem a buckets maiores que 1/10GB que passaram do estágio de Hot para Warm, processo reconhecido como “rolled data”. A cada bucket que é migrado do estágio Hot para o Warm, um novo diretório é criado (em uma instalaçăo padrăo) em $SPLUNK_HOME/var/lib/splunk/defaultdb/db/*, seguindo uma convençăo especial de nomenclatura. Uma instalaçăo padrăo do Splunk poderá contar com até 300 Warm buckets. Quando for criado o Warm bucket número 301, o mais antigo bucket deste estágio será migrado para Cold;
· Cold: Armazena os buckets que foram migrados de Warm, sendo que podem chegar até 500 GB antes de serem migrados para Frozen. O aspecto da idade dos dados também está presente neste estágio, sendo que, quando determinados buckets atingirem seis anos, eles serăo migrados para Frozen;
· Frozen: por padrăo, o Splunk exclui permanentemente todos os buckets de dados que săo migrados de Cold para Frozen; os dados săo removidos do índice nesse momento. Caso seja necessário arquivar os dados que săo movidos para este estágio, edite o arquivo indexes.conf localizado em $SPLUNK_HOME/etc/system/default e configure o parâmetro coldToFrozenDir para arquivar os novos Frozen buckets, como exibido na Listagem 1.
Listagem 1. Editando o arquivo inputs.conf para configurar o coldToFrozen.
# ediçăo do arquivo $SPLUNK_HOME/etc/system/default/inputs.conf
[<nome_índice>]</nome_índice>
coldToFrozenDir = “/frozenPartition”Também no arquivo indexes.conf, utilize o parâmetro coldToFrozenScript para executar um script que normalmente é chamado para fazer o arquivamento dos dados e alguma outra tarefa que pode ser executada por meio de scripts, o que dá a possibilidade de utilizar a criatividade de forma livre. Veja como fazer esta configuraçăo na Listagem 2.
Listagem 2. Adicionando a parâmetro coldToFrozenScript ao arquivo inputs.conf.
# ediçăo do arquivo $SPLUNK_HOME/etc/system/default/inputs.conf
[<nome_índice>]</nome_índice>
coldToFrozenScript = [$SPLUNK_HOME/bin/] “coldToFrozenExample.py”Por padrăo, o script especificado na Listagem 2, chamado coldToFrozenExample.py, está pronto para ser utilizado e está localizado em $SPLUNK_HOME/bin. O parâmetro coldToFrozenDir tem precedęncia sobre o coldToFrozenScript, portanto cuidado ao colocar as duas funcionalidades ao mesmo tempo;
· Thawed: Se o usuário traduzir para o Portuguęs a palavra Thawed, vai perceber algo até engraçado e que, nesse contexto, faz todo sentido. Literalmente, este estágio trata do descongelamento dos dados ou buckets que foram congelados, ou seja, antes de serem arquivados, eles estavam em um formato de Frozen buckets e agora serăo posicionados no diretório de Thawed buckets, localizado em $SPLUNK_HOME/var/lib/splunk/defaultdb/thaweddb. Após colocar os Frozen buckets como “descongelados” no diretório citado, eles podem ficar lá o tempo que for necessário, e quando năo os quiser mais, basta excluí-los. Uma boa estratégia é criar um script para mover os Frozen buckets para Thawed buckets e eliminá-los de acordo com uma política defendida em um script no nível do SO.
Por padrăo, o Splunk realizará buscas somente nos Hot/Warm/Cold buckets, uma vez que os Frozen buckets săo excluídos por padrăo. O usuário poderá ainda arquivar os Frozen buckets em um disco para fazer o seu restore, caso seja necessário. O comportamento ou política para que buckets sejam considerados antigos e assim passem de um estágio para outro, ou mesmo, as práticas de arquivamento de Frozen buckets, poderăo ser reconfigurados de acordo com os interesses da organizaçăo por meio do arquivo indexes.conf. Neste arquivo, o administrador do Splunk especificará variáveis para configuraçăo de políticas de retençăo de eventos indexados. Veja mais sobre o assunto em http://tinyurl.com/aatf2gr.
Cada evento é indexado a partir do seu timestamp e as partes que compőem o evento săo identificadas e adicionadas abaixo de estruturas denominadas fields. Os fields săo estruturas que nomeiam a informaçăo identificada em meio aos eventos e que podem ser utilizados para efetuar buscas por meio do aplicativo padrăo do Splunk, a Search App. Neste aplicativo, ou no aplicativo de busca, é onde o usuário poderá escrever suas próprias consultas para extrair a informaçăo mais valiosa para sua organizaçăo, aquela que responde a perguntas estratégicas.
A Search App é considerada como o Google do lado interno da sua organizaçăo, pois com ela vocę pode buscar por termos como “error” ou “fail” e tem a possibilidade de percorrer todos os logs adicionados ao Splunk e saber exatamente o que está acontecendo com a sua TI. Além disso, o Splunk possui uma linguagem própria de consulta aos dados de máquina indexados denominada SPL, ou Search Processing Language.
Além de armazenar os dados sem precisar de um banco de dados, năo necessitar de conectores, lidar com qualquer volume de dados e ainda possuir um aplicativo que possibilita manipular dados com uma linguagem própria, o Splunk possibilita que o usuário crie os seus próprios relatórios baseados em vários tipos de gráficos (column, line, area, bar, pie, scatter, radial, filter e marker), que podem ser criados a partir da Search App e assim serem salvos em um painel que poderá conter vários gráficos relacionados com um departamento específico. Além dos gráficos, alertas sobre consulta a dados também podem ser criados e dentro destes alertas, o usuário poderá definir o envio de e-mails e a execuçăo de scripts para realizar ilimitadas açőes de correçăo para um problema identificado.
Com isso, o Splunk entrega o que tem defendido como sua missăo, que é “tornar os dados de máquina acessíveis, utilizáveis e valorizados por todos”. Com apenas quatro passos, vocę conseguirá extrair informaçăo inteligente de um emaranhado de dados, nos quais, a olhos nus, o usuário ou uma equipe năo teria tanta facilidade em fazer. Os quatros passos săo:
1. Configurar a fonte de dados;
2. Consultar a informaçăo com a Search App;
3. Criar relatórios com vários tipos de gráficos;
4. Criar alertas sobre a informaçăo retornada pelas consultas.
O Splunk ainda oferece a facilidade de poder facilmente ser integrado com vários outros sistemas. Um exemplo é a integraçăo que pode ser feita com sistemas de controle de SLA (Service Level Agreement ou Acordo de Nível de Serviço), para determinar quais tickets estăo para vencer, quais já venceram e quăo efetivo é o departamento em năo deixar SLAs vencerem. Integrar o Splunk com portais de e-commerce também é uma tarefa simples. O administrador de sistemas poderia facilmente saber quais produtos estăo sendo abandonados no carrinho de compras, ou até mesmo o tempo de entrega de uma requisiçăo de usuário, correlacionando logs de Apache, WebSphere e MySQL.
Os sistemas operacionais suportados săo os seguintes:
· Solaris 9, 10 (x86, SPARC);
· Linux Kernel versăo 2.6.x e superiores (x86: 32 e 64-bit);
· FreeBSD 6.1 (x86: 32-bit), 6.2, 7.x, 8.x (x86: 32 e 64-bit);
· Windows Server 2003/2003 R2;
· Windows Server 2008/2008 R2;
· Windows XP (32-bit);
· Windows Vista (32-bit, 64-bit);
· Windows 7 (32-bit, 64-bit);
· Mac OS X 10.5 e 10.6;
· AIX 5.2, 5.3, e 6.1;
· HP-UX.
Além disso, o Splunk tem como característica ser escalável desde o seu laptop até máquinas maiores em um Data Center. Sendo assim, o administrador Splunk poderá iniciar os testes em laptops e depois migrar aquele ambiente para máquinas maiores. Uma ressalva interessante é que a empresa năo precisará adotar máquinas muito grandes para rodar o Splunk, já que o produto tem escalabilidade horizontal ou linear, ou seja, pode operar bem com várias máquinas pequenas (hardware commodity). E é aí que entram alguns novos conceitos: as tręs funçőes básicas do Splunk, que é a de coletar, indexar e consultar dados de máquina, funçőes estas que podem ser facilmente divididas entre várias máquinas.
A máquina que servirá para busca de informaçăo (utilizando a Search App) passará a ser chamada de Search Head; as máquinas que recebem as informaçőes e as armazenam em disco passam a ser chamadas de Indexers; e aquelas que enviam as informaçőes para os Indexers passam a contar com um pequeno agente, que é um software Splunk denominado Universal Forwarder. Este Universal Forwarder, ou somente Forwarder, coletará a informaçăo de interesse nas máquinas onde rodam, por exemplo, o Apache, o Linux e o Oracle, e enviará aquelas informaçőes para os Indexers para serem indexadas e, assim, estarem disponíveis para os Search Heads, onde o usuário entra com as consultas (ufa!). Para vermos melhor como funciona essa arquitetura, observe a Figura 2.
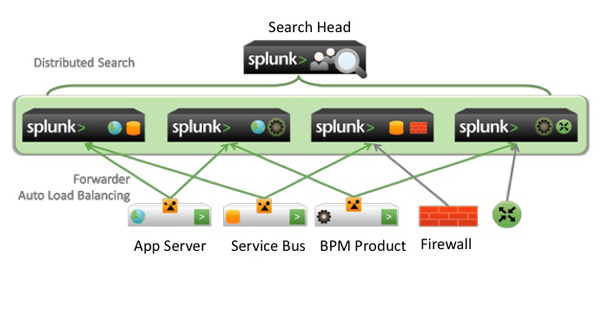
Figura 2. Splunk em tręs camadas, dividindo funçőes.
Para fazer a instalaçăo do Splunk é necessário acessar o site splunk.com e fazer um pequeno cadastro. Assim, além de fazer o download de acordo com a sua plataforma, o usuário já contará com um perfil para acessar o fórum oficial de usuários Splunk, conhecido por Splunk Answers, e também baixar aplicativos no Splunkbase, onde a própria Splunk disponibiliza vários aplicativos desenvolvidos por eles e também aplicativos de terceiros (uma boa oportunidade para quem deseja vender aplicativos para Splunk).
Tais aplicativos podem ser baixados de dentro da sua instalaçăo do Splunk e săo como inteligęncia empacotada para resolver determinado problema de monitoramento. Com um aplicativo, ou somente “app”, como săo chamados, o usuário conseguirá monitorar um IronPort, BigIP e servidores Unix/Linux e Windows em 10 minutos. Saiba mais detalhes sobre a documentaçăo do Splunk na Nota DevMan 4.
Nota DevMan 4. Documentaçăo do Splunk
A documentaçăo do Splunk está disponível online. Caso este seja seu primeiro contato com o produto, recomendamos que faça uma leitura rápida do Splunk Tutorial para entender os principais conceitos e já dar início ŕ sua experięncia com o produto. Após tal leitura, a documentaçăo geral é bem indicada, pois trata dos tópicos com muito mais detalhes. O link para ambos é apresentado na seçăo Links.Conclusăo
Neste artigo vimos algumas características do funcionamento do Splunk, que é uma plataforma universal de dados de máquina que possibilita que a organizaçăo năo só aprenda mais com os dados que já possui, como com os dados que produz no dia a dia de suas operaçőes. Uma vez coletados os dados, o Splunk os armazenará em disco, em buckets, como vimos, e utilizará mecanismos de indexaçăo destes dados para que informaçőes sejam recuperadas com muita rapidez e facilidade. A partir de tais dados armazenados, será possível utilizar a Search App para entăo consolidar relatórios e gráficos para que os membros de cada time dos vários departamentos de uma empresa possam acompanhar a operaçăo em tempo real, o que é o mais interessante.
No próximo artigo, vocę terá a oportunidade de aprofundar um pouco mais no Splunk, ao realizarmos uma exploraçăo mais prática passando pelos principais tópicos como coleta de informaçăo, análise, consulta e implementaçăo de relatórios e gráficos.
Exploring
Splunk
http://www.splunk.com/goto/book
Documentaçăo do
Splunk
http://docs.splunk.com/Documentation
Download do
arquivo de logs (Sampledata.zip)
http://tinyurl.com/bgmkod3
Site oficial
Splunk em portuguęs
http://pt.splunk.com

Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.