


Este artigo trata de como planejar e executar as configuraþ§es necessßrias para montar uma estrutura de alta disponibilidade para serviþos, quer sejam de Internet ou nÒo, utilizando GNU/Linux.
Para que serve:
Serve para garantir que os serviþos (banco de dados, servidores web etc.) estejam disponÝveis para uso pelos Clientes mesmo quando da ocorrÛncia de problemas graves, tais como instabilidade ou falhas de hardware.
Em que situaþÒo o tema Ú ·til:
Quando vocÛ for responsßvel por manter um serviþo que nÒo pode parar (24 h e 7 d) e/ou o mesmo tiver um alto n·mero de acessos e vocÛ desejar minimizar os impactos que uma manutenþÒo ou problema de hardware venha causar.
No ambiente atual, a demanda para que os serviþos estejam disponÝveis 24x7 Ú maior e cada vez mais presente em todos os segmentos, da ind·stria ao varejo. Se antes era um requisito existente ou recurso disponÝvel apenas para grandes ambientes, por conta de seu custo, hoje jß Ú possÝvel tornß-lo acessÝvel para uma audiÛncia muito maior atravÚs de ferramentas open source.
Neste contexto, este artigo apresentarß como implementar um ambiente de alta disponibilidade utilizando apenas soluþ§es open source. Contudo, antes de apresentarmos as ferramentas que estÒo Ó nossa disposiþÒo, Ú preciso introduzir alguns termos comuns na ßrea e esclarecer os limites da soluþÒo proposta.
Alta disponibilidade e escalabilidade
A alta disponibilidade e escalabilidade sÒo requisitos desejßveis em qualquer sistema, e apesar de serem vistas com frequÛncia juntas, as soluþ§es que visam prover alta disponibilidade nÒo implicam em escalabilidade e vice-versa. Para fins deste artigo, podemos definir que:
ò Alta disponibilidade Ú a capacidade de um sistema/servidor estar disponÝvel por grandes perÝodos de tempo;
ò Escalabilidade Ú a capacidade de oferecer serviþos com qualidade aceitßvel mesmo com uma demanda crescente.
Este artigo abordarß apenas o primeiro item, uma vez que o segundo requer um conhecimento muito mais especÝfico da aplicaþÒo que se deseja atender.
Paralisaþ§es
Uma vez que um serviþo Ú colocado Ó disposiþÒo dos usußrios, uma pressÒo, antes inexistente, se manifesta: o serviþo deve estar disponÝvel sempre que necessßrio!
Infelizmente, em qualquer ambiente temos que conviver com eventos que atuam para impedir o objetivo acima de ser satisfeito. Estes eventos sÒo as paralisaþ§es dos servidores/serviþos.
Para minimizarmos seus impactos temos que entender os tipos de paralisaþ§es. Estas podem ser divididas em duas categorias:
ò NÒo planejadas: sÒo o resultado de falhas aleat¾rias (imprevisÝveis) dos sistemas, associadas a componentes de hardware ou software. Como exemplo, temos discos rÝgidos com defeitos fÝsicos, mem¾rias com erros, fontes de alimentaþÒo queimadas, entre outros;
ò Planejadas (ou manutenþ§es): associadas a paralisaþ§es agendadas para promover a atualizaþÒo de hardware ou software. Costumam oferecer menor impacto ao neg¾cio por normalmente serem realizadas em momentos de menor trßfego.
No caso das paralisaþ§es nÒo planejadas, vocÛ pode ter uma postura preventiva, trocando, por exemplo, componentes antes do tempo mÚdio do aparecimento de problemas. Entretanto, tal atitude nÒo Ú uma garantia de que o componente nÒo apresentarß problemas antes dessa data.
Mas qual o impacto de uma paralisaþÒo? Apesar de nÒo ser fßcil quantificar o prejuÝzo de uma paralisaþÒo, Ú possÝvel realizar um simples exercÝcio para se entender o potencial que um problema pode alcanþar.
Suponha que vocÛ tenha um servidor que demora 5 minutos para completar o processo de reinicializaþÒo. Se ele Ú responsßvel por atender a 100 requisiþ§es por segundo, isso significa que teremos 5 minutos x 60 segundos x 100 requisiþ§es por segundo = 30.000 requisiþ§es nÒo atendidas!
NÝveis de disponibilidade
Apesar do desejo de termos uma disponibilidade de 100%, este valor nÒo Ú realizßvel na prßtica. Por conta disso, precisamos definir qual o nÝvel de disponibilidade, conhecido como SLA (Service Level Agreement û que define os nÝveis aceitßveis para um serviþo), antes de desenharmos a nossa soluþÒo.
Usualmente iniciamos estimando o tempo mßximo desejßvel de parada (downtime) durante um ano de operaþÒo medido em minutos, e encontramos qual a classe de disponibilidade que satisfaz o requisito utilizando a seguinte f¾rmula:
D = (1 - R) x 365 x 24 x 60 Onde D Ú o tempo mßximo de parada em minutos e R Ú a razÒo entre o tempo disponÝvel e o indisponÝvel. No mercado Ú comum encontrarmos os nÝveis conforme a Tabela 1.
|
Disponibilidade (%) |
Tempo de parada no ano |
|||
|
99 |
3,65 dias |
|||
|
99,9 |
8,76 horas |
|||
|
99,99 |
52,6 minutos |
|||
|
99,999 |
5,26 minutos |
|||
|
99,9999 |
30 segundos |
|||
Tabela 1. NÝveis de disponibilidade
Como atingir a alta disponibilidade?
Uma das maneiras de se atingir a alta disponibilidade estß em se desenvolver ou utilizar sistemas tolerantes a falhas. Nestes sistemas, a falha de um componente nÒo afeta a operaþÒo, pois Ú compensada por outro de maneira transparente e automßtica.
Se considerarmos apenas o contexto de hardware, os sistemas tolerantes a falhas, normalmente proprietßrios, possuem partes redundantes, ou seja, componentes adicionais que sÒo acionados quando o principal apresenta falha. Nesta categoria encontramos CPUs, mem¾ria, disco, fontes de alimentaþÒo e refrigeraþÒo.
Por sua caracterÝstica proprietßria, os sistemas tolerantes a falhas possuem custos elevados, o que impede a sua adoþÒo fora de ambientes nos quais recursos de pessoal tÚcnico ou financeiros sejam abundantes. Ou pelo menos impedia atÚ o lanþamento de projetos como o Linux HA (Linux High Availability û Ú um conjunto de ferramentas disponÝveis para ambiente GNU/Linux).
Com o Linux HA temos acesso a soluþ§es, via software, para alcanþar os nÝveis de disponibilidade sem trazer os altos custos de soluþ§es proprietßrias.
Construindo a soluþÒo de disponibilidade
Para a construþÒo de nossa soluþÒo nos basearemos na redundÔncia de componentes comuns (commodity hardware û hardware comum encontrado no mercado) e de software para detectar a falha e promover a recuperaþÒo automßtica.
Neste artigo assumiremos um ambiente exemplo como visto na Figura 1. Em nosso ambiente temos um servidor WWW, que serve os arquivos e aplicativos de nossa empresa para o mundo.

Figura 1. Servidor WWW.
Obviamente, como temos apenas um servidor, qualquer mau funcionamento nele que acarrete uma paralisaþÒo, programada ou nÒo, irß impedir que os usußrios acessem os aplicativos lß hospedados.
A primeira abordagem que podemos assumir Ú duplicar o hardware e de alguma maneira sincronizar o conte·do de ambos os servidores. Na Figura 2 podemos ver tal abordagem utilizando uma ferramenta comum no ambiente Unix, o rsync.
O rsync Ú uma ferramenta que permite sincronizar o conte·do de disco (partiþ§es, arquivos, etc.) remotamente e de maneira eficiente. Ele s¾ leva as mudanþas que aconteceram entre uma sincronizaþÒo e outra. Assim, se vocÛ faz uma sincronizaþÒo a cada cinco minutos, ele s¾ leva as mudanþas ocorridas nesse perÝodo, em vez de copiar todo o conte·do novamente.
Dessa forma, se seu site estß configurado para apontar para o IP A e o servidor apresenta problema, vocÛ pode reconfigurar a mßquina reserva para usar o mesmo IP e assim seus usußrios voltarÒo a acessar o conte·do û pelo menos o que existia atÚ a ·ltima sincronizaþÒo (ver Figura 3).
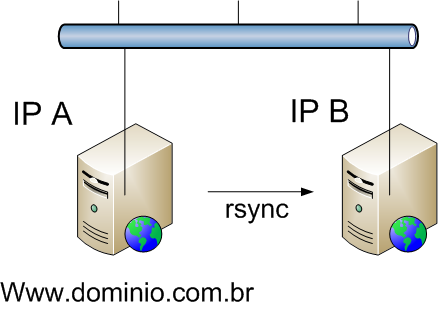
Figura 2. RedundÔncia com o rsync.
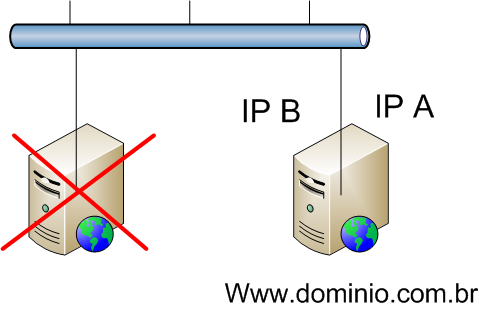
Figura 3. Servidor backup em aþÒo.
A soluþÒo anterior funciona em alguns ambientes, mas possui muitos limitantes para a realidade pretendida:
ò A sincronizaþÒo Ú peri¾dica. Com isso, todos os dados atualizados entre uma sincronizaþÒo e outra sÒo perdidos em caso de falha; ou seja, se o servidor de backup sincroniza a cada 1 hora e o principal ficar inacessÝvel nesse intervalo, vocÛ colocarß o servidor de backup com dados incompletos em seu lugar;
ò A configuraþÒo Ú manual. A troca do IP do servidor backup e inicializaþÒo dos serviþos Ú manual. Isso representa um tempo para recuperaþÒo elevado.
Tais restriþ§es nos impendem de alcanþar nÝveis de SLA aceitßveis para a maioria das necessidades. Dessa forma, precisamos utilizar outra abordagem que partirß do mesmo princÝpio (redundÔncia de hardware), mas se valerß de dois componentes do Linux HA: DRBD (Distributed Replicated Block Device) e o Heartbeat para resolver as limitaþ§es vistas com a proposta do rsync.
O DRBD se apresenta para o sistema operacional como um sistema de blocos, assim como um disco rÝgido. A diferenþa Ú que quando o sistema operacional manda escrever nesse dispositivo ele o faz via rede em um dispositivo remoto. DaÝ o seu carßter distribuÝdo. Por se apresentar como um sistema de blocos ele Ú transparente para o sistema operacional, que acredita estar gravando localmente como em qualquer dispositivo.
O Heartbeat, por sua vez, Ú o nosso agente de monitoramento. Ele fica monitorando os elementos que irÒo compor nossa soluþÒo e ao detectar que o elemento considerado ativo (primßrio) nÒo estß respondendo, ele se encarrega de promover o elemento passivo (secundßrio) de maneira que o mesmo assuma todos os serviþos do elemento ativo.
Nossa meta Ú criar um ambiente que permita em atÚ 30 segundos detectar a falha e automaticamente possibilitar que o servidor backup assuma os serviþos oferecidos pelo servidor principal.
Anatomia da soluþÒo
Neste artigo iremos montar um ambiente de alta disponibilidade para um servidor Web. Nossa soluþÒo, vista na Figura 4, Ú composta de quatro componentes:
1. Um servidor primßrio û sistema operacional Linux, com duas interfaces de rede e responsßvel inicialmente por prover o serviþo de Web atravÚs do Apache;
2. Um servidor secundßrio û sistema operacional Linux, com duas interfaces de rede;
3. Um barramento de rede principal ou p·blico û Ú o barramento de rede pelo qual os Clientes irÒo acessar o servidor;
4. Um barramento de rede secundßrio ou privado û Ú o barramento interno, utilizado apenas para a sincronizaþÒo (replicaþÒo) dos dados do servidor primßrio para o secundßrio.
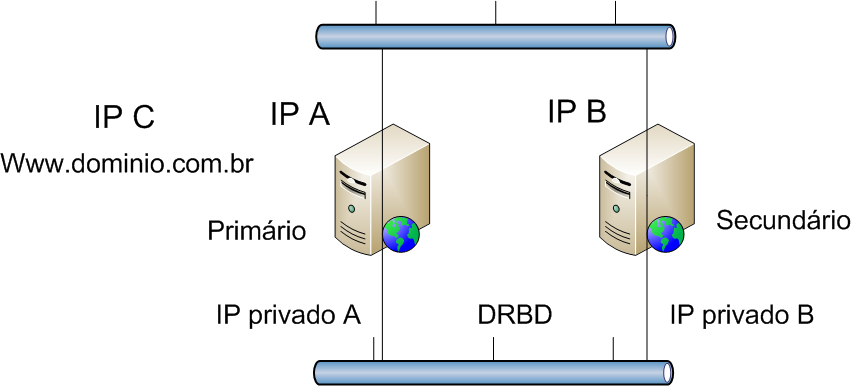
Figura 4. SoluþÒo com DRBD+Heartbeat
Na soluþÒo usando o DRBD+Hearbeat resolvemos as duas restriþ§es citadas anteriormente (ver Figuras 2 e 3):
ò SincronizaþÒo dos dados transparente. Por se comportar como um disco convencional para o sistema operacional (DRBD), toda e qualquer operaþÒo de escrita Ú transmitida para o ponto secundßrio automaticamente e de maneira sÝncrona;
ò ConfiguraþÒo automßtica. O Hearbeat ao perceber que o ponto primßrio nÒo estß operante, faz com que o n¾ secundßrio assuma o seu papel realizando configuraþ§es, como de IP, de forma automßtica.
Na Figura 5 vemos o que acontece quando ocorre a falha do ponto primßrio. O servidor B irß assumir o papel do n¾ primßrio, passando a responder pelo IP C (associado ao serviþo www.dominio.com.br) e iniciarß o servidor Apache localmente.
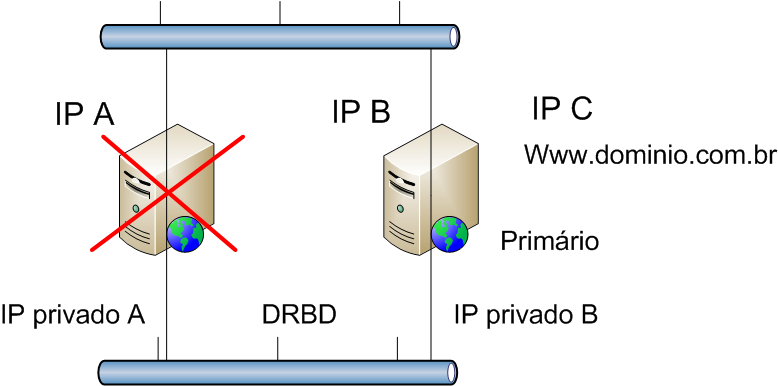
Figura 5. Falha no servidor primßrio.
Configurando o ambiente
Em nosso exemplo estamos montando uma soluþÒo HA para um servidor Web. Usaremos nos dois servidores o sistema operacional Linux com a distribuiþÒo CentOS 5.x, os pacotes do Apache, DRBD e o Heartbeat.
Para baixar estas aplicaþ§es, acesse os endereþos listados no final do artigo na seþÒo Links.
Apesar dos procedimentos de instalaþÒo diferirem quanto Ó distribuiþÒo escolhida, todos os pacotes sÒo encontrados nas distribuiþ§es mais recentes.
Para montar um ambiente, usaremos como exemplo os parÔmetros abaixo:
Servidor A
Interface p·blica: 172.16.117.162 / 255.255.255.0
Interface privada: 192.168.0.2 / 255.255.255.0
Nome: node0
Servidor B
Interface p·blica: 172.16.117.163 / 255.255.255.0
Interface privada: 192.168.0.3 / 255.255.255.0
Nome: node1
IP p·blico do serviþo Web
172.16.117.160
╔ importante que em ambos os servidores o serviþo do Apache esteja configurado para nÒo se iniciar automaticamente. Esse controle serß feito pelo Heartbeat.
Agora realize as etapas descritas a seguir nos dois servidores, salvo onde explicitamente for indicado para realizar apenas no servidor primßrio.
1¬ Etapa: configurando o DRBD
O DRBD Ú responsßvel pela sincronizaþÒo dos dados entre os n¾s. ╔ desta maneira que Ú possÝvel usß-lo sem que as aplicaþ§es que fazem uso daquela partiþÒo tenham que ser modificadas para se beneficiar da replicaþÒo.
O arquivo de configuraþÒo do DRBD padrÒo Ú o /etc/drbd.conf. Usualmente Ú criado um de exemplo no processo de instalaþÒo do pacote. Em nosso exemplo teremos o arquivo apresentado na Listagem 1.
Listagem 1. Arquivo de configuraþÒo do DRBD.
resource apache
{
protocol C;
startup { wfc-timeout 0; degr-wfc-timeout 120; }
disk { on-io-error detach; }
net { cram-hmac-alg "sha1"; shared-secret ôsenha"; }
syncer { rate 10M; }
on node0 {
device /dev/drbd0;
disk /dev/sdb;
address 192.168.0.2:7788;
meta-disk internal;
}
on node1 {
device /dev/drbd0;
disk /dev/sdb;
address 192.168.0.3:7788;
meta-disk internal;
}
}
resource apache Na sequÛncia definimos os n¾s. Abaixo apresentamos um fragmento do mesmo arquivo de configuraþÒo, com foco apenas nos parÔmetros que definem um recurso:
on node0 {
device /dev/drbd0;
disk /dev/sdb;
address 192.168.0.2:7788;
meta-disk internal;
}
on node1 {
device /dev/drbd0;
disk /dev/sdb;
address 192.168.0.3:7788;
meta-disk internal;
} Em nosso caso temos no primeiro n¾ (node0) um dispositivo /dev/drbd0 que Ú mapeado para o disco fÝsico /dev/sdb, e vemos que ele fica escutando no IP 192.168.0.2 na porta 7788.
Ao observarmos o segundo n¾, vemos que com exceþÒo do IP, que Ú o IP privado do servidor B, as demais configuraþ§es sÒo as mesmas.
Para entendermos o que foi feito Ú preciso explicar que, em nosso exemplo, existe um segundo disco (/dev/sdb) em cada servidor e que criamos em cada n¾ um dispositivo (/dev/drbd0) que gravarß e lerß os dados desse disco.
O nosso sistema operacional irß gravar na partiþÒo drbd0 achando que se trata de um disco fÝsico local (como /dev/sda) e os dados serÒo replicados para o n¾ que estiver em modo secundßrio de forma automßtica. Assim, se houver uma pane no servidor primßrio, o segundo terß uma c¾pia exata dos dados atÚ o momento anterior da pane.
Ap¾s criar o arquivo de configuraþÒo, copie o mesmo manualmente para o segundo servidor (jß que ele Ú idÛntico) e execute como usußrio root o comando a seguir na console dos dois servidores:
drbdadm create-md apache O drbdadm Ú um utilitßrio que Ú instalado com o DRBD e lhe permitirß consultar e alterar o comportamento do n¾, se necessßrio.
Neste ponto, o DRBD irß iniciar o processo de inicializaþÒo do dispositivo /dev/drbd0, conforme a Listagem 2.
Listagem 2. Processo de inicializaþÒo do dispositivo drbd0.
v08 Magic number not found
v07 Magic number not found
About to create a new drbd meta data block on /dev/sdb.
. ==> This might destroy existing data! <==
Do you want to proceed? [need to type 'yes' to confirm] yes
Creating meta data... initialising activity log NOT initialized bitmap (256 KB) New drbd meta data block sucessfully created. O tempo necessßrio para esse procedimento dependerß do tamanho do disco (ou partiþÒo) usado.
Agora vocÛ deve iniciar o serviþo do DRBD com o comando:
service drbd start Se ocorreu tudo bem, ambos os n¾s estarÒo marcados como secundßrios. EntÒo execute o comando abaixo em ambos os servidores:
cat /proc/drbd Ele irß mostrar o status do sistema de controle do DRBD para que vocÛ veja como se encontram os dispositivos criados, qual o papel de cada dispositivo (primßrio/secundßrio) no servidor onde o comando foi executado e se estß sincronizado ou nÒo.
O resultado apresentado na Listagem 3 indica que o dispositivo do DRBD foi criado e que ambos os n¾s estÒo no modo secundßrio.
Listagem 3. O processo de inicializaþÒo do drbd0 foi concluÝdo.
version: 8.0.4 (api:86/proto:86) SVN Revision: 2947 build by buildsvn@c5-i386-build, 2007-07-31 19:17:18
. 0: cs:Connected st:Secondary/Secondary ds:Inconsistent/Inconsistent C r---
. ns:0 nr:0 dw:0 dr:0 al:0 bm:0 lo:0 pe:0 ua:0 ap:0
. resync: used:0/31 hits:0 misses:0 starving:0 dirty:0 changed:0 act_log: used:0/257 hits:0 misses:0 starving:0 dirty:0 changed:0 Agora vocÛ deve escolher um dos dois n¾s para considerar como primßrio. Como ambos neste momento nÒo possuem nenhum conte·do, na prßtica vocÛ pode selecionar qualquer um deles. Para padronizarmos, iremos executar o comando abaixo no node0:
drbdadm -- --overwrite-data-of-peer primary apache O comando irß instruir o servidor onde ele foi executado; em nosso caso node0, que ele deve copiar o conte·do dos blocos do disco do servidor primßrio para o secundßrio.
Como no DRBD n¾s associamos um nome a cada partiþÒo criada, estamos fazendo isso para o resource apache. Caso vocÛ tivesse mais de um resource, vocÛ deveria fazÛ-lo para todos os resources existentes.
Agora, se repetirmos o cat /proc/drbd a partir do node0, devemos ver o resultado exibido na Listagem 4.
Listagem 4. Processo de sincronizaþÒo entre o n¾ primßrio e secundßrio.
0: cs:SyncTarget st:Primary/Secondary ds:Inconsistent/Inconsistent C r---
. ns:0 nr:68608 dw:68608 dr:0 al:0 bm:4 lo:0 pe:0 ua:0 ap:0
. [>...................] sync'ed: 0.9% (8124/8191)M finish: 0:12:05 speed: 11,432 (11,432) K/sec resync:
used:0/31 hits:4283 misses:5 starving:0 dirty:0 changed:5 act_log: used:0/257 hits:0 misses:0 starving:0
dirty:0 changed:0 Neste momento ele indica que estß realizando o processo de sincronizaþÒo entre o servidor primßrio e o secundßrio. No exemplo da Listagem 4 o DRBD se encontra em 0.9% da sincronizaþÒo e estima que necessitarß de mais 12 minutos e 5 segundos para concluir. O tempo real dependerß do tamanho e performance dos discos de cada servidor e da rede.
Quando o DRBD concluiu o processo de sincronizaþÒo vocÛ ficou com dois dispositivos, um em cada n¾, com o mesmo conte·do de cada bloco do disco fÝsico. Os blocos estÒo, entretanto, sem nenhuma formataþÒo especÝfica. Para poder usar o disco para armazenar o conte·do vocÛ precisa formatar a partiþÒo.
Deste modo, quando o valor estiver em 100%, execute o seguinte comando no node0:
mkfs.ext3 /dev/drbd0 Feito isso, vocÛ jß pode montar a partiþÒo e comeþar a usß-la.
mkdir /mnt/apache
mount /dev/drbd0 /mnt/apache Com isso jß conseguimos resolver metade de nosso objetivo. Tudo que venha a ser escrito em /mnt/apache serß replicado automaticamente no node1.
Para darmos continuidade ao processo, iremos desmontar a partiþÒo /dev/drbd0 recentemente criada. A funþÒo do Heartbeat serß gerenciar e cuidar de montar e desmontar as partiþ§es automaticamente. Para isso, execute:
umount /mnt/apache O pr¾ximo passo Ú configurar o Heartbeat para que monitore o sistema e promova o servidor secundßrio a primßrio, quando necessßrio.
2¬ Etapa: Configurando o Heartbeat
O Heartbeat Ú uma ferramenta de monitoramento bastante versßtil. Para a finalidade de nossa soluþÒo, estaremos interessados em trÛs arquivos de configuraþÒo: /etc/ha.d/authkeys, /etc/ha.d/ha.cf e /etc/ha.d/haresources.
No /etc/ha.d/authkeys vocÛ irß configurar um c¾digo e uma senha que deverÒo ser usados por ambos os n¾s na comunicaþÒo do Heartbeat:
auth 1
1 sha1 senha-do-heartbeat O auth 1 indica o c¾digo a ser usado para identificar os servidores que participarÒo da comunicaþÒo, e na linha seguinte qual a senha a ser usada para garantir que apenas os n¾s participantes possam se identificar.
No /etc/ha.d/ha.cf vocÛ deve configurar os parÔmetros que serÒo usados pelo Heartbeat para monitorar os n¾s e que critÚrios usar para tomar a decisÒo se um n¾ estß operante ou nÒo (Listagem 5).
Listagem 5. ConfiguraþÒo do Heartbeat.
keepalive 1
deadtime 10
warntime 5
initdead 120
udpport 694
ping 172.16.117.1
bcast eth1
auto_failback off
node 172.16.117.162
node 172.16.117.163 Aqui os pontos principais sÒo:
ò deadtime: n·mero de segundos sem comunicaþÒo a partir do qual o n¾ Ú considerado ômortoö;
ò ping: indica qual o endereþo IP que o Heartbeat irß monitorar. Em nosso exemplo estamos monitorando o gateway;
ò bcast: indica qual a interface de rede no qual os pacotes de controle do Heartbeat serÒo enviados;
ò auto_failback: caso um n¾ seja detectado como morto e depois volte Ó atividade ele deve (ou nÒo) ser auto promovido a primßrio. Em nosso caso optamos por avaliar manualmente o evento e decidir qual n¾ deve ser o primßrio em um caso desses;
ò node: indica os IPs da rede p·blica onde o Heartbeat estß instalado.
A parte mais importante para nossa configuraþÒo estß no ·ltimo arquivo (haresources). ╔ nele que indicaremos o que o Heartbeat deverß fazer quando detectar um problema e precisar elevar um n¾ de secundßrio para primßrio e vice-versa:
node0 IPaddr::172.16.117.160/24 drbddisk::apache Filesystem::/dev/drbd0::/mnt/apache::ext3::defaults httpd Em nosso exemplo estamos indicando que o n¾ que estiver como primßrio deverß configurar o IP 172.16.117.160/255.255.255.0, montar a partiþÒo /dev/drbd0 como /mnt/apache e iniciar o serviþo httpd.
No manual do Heartbeat estÒo descritas todas as opþ§es vßlidas, mas Ú importante entender que o processamento desse arquivo acontece na seguinte ordem:
ò Da esquerda para a direita e de cima para baixo. Quando um n¾ estß sendo promovido a primßrio ele inicia executando os comandos nessa sequÛncia;
Ou:
ò Da direita para a esquerda e de baixo para cima. Quando um n¾ estß sendo rebaixado de primßrio para secundßrio ele inicia executando os comandos nessa sequÛncia.
╔ importante que entendamos esta ordem e o porquÛ dela antes de criarmos nosso haresources.
Quando um n¾ estß se ativando e for decidido que ele Ú primßrio, ele irß comeþar criando um alias com o IP indicado. Este IP Ú o nosso IP p·blico associado ao servidor Web www.dominio.com.br. Em seguida ele irß montar a partiþÒo DRBD no diret¾rio que n¾s indicamos e s¾ depois irß inicializar o serviþo do Apache. Ap¾s a inicializaþÒo do Apache, quem tentar acessar o serviþo irß visualizar a pßgina normalmente.
O n¾ secundßrio ficarß monitorando e, atravÚs do DRBD, sincronizando as modificaþ§es na partiþÒo criada.
Agora suponha que aconteþa algo com o n¾ primßrio que o impeþa de se comunicar com o gateway, por exemplo: a porta do switch apresente problema ou o cabo de rede seja desconectado.
O Heartbeat detectarß este problema e ap¾s 10 segundos avisarß ao n¾ secundßrio que ele deve ser promovido. Esse tempo de 10 segundos serve para evitar que pequenas interrupþ§es temporßrias gerem falsos positivos e provoquem a alteraþÒo desnecessßria. Para isso o Heartbeat irß, no atual n¾ primßrio (node0), desligar o serviþo do Apache, desmontar a partiþÒo e remover o alias do IP.
No node1 ele farß exatamente o que fez quando o node0 foi ativado, e desta maneira, em menos de 30 segundos, os usußrios que estivessem acessando o site www.dominio.com.br seriam atendidos pelo novo servidor sem tomar conhecimento da mudanþa ou qualquer intervenþÒo manual.
3¬ Etapa: Testando
Ao chegarmos nessa etapa jß temos todos os componentes responsßveis pela alta disponibilidade configurados. O que precisamos fazer agora Ú realizar ajustes no Apache para que ele trabalhe corretamente com nossa soluþÒo.
Deste modo, antes de efetuarmos os testes, existem dois passos necessßrios:
ò Configurar o Apache para disponibilizar o conte·do da partiþÒo criada e nÒo do lugar padrÒo. Como o Apache por padrÒo utiliza o diret¾rio /var/www/html, Ú necessßrio alterß-lo para o /mnt/apache;
ò Iniciar o Heartbeat em ambos servidores.
Primeiro configure o Apache para usar o /mnt/apache como DocumentRoot. Isso pode ser feito editando o arquivo de configuraþÒo /etc/httpd/conf/httpd.conf. Assim, procure as entradas DocumentRoot e Directory que apontarem para /var/www/html e mude-as para /mnt/apache.
Em seguida inicie o Heartbeat em ambos os n¾s. AtÚ o momento ele estava configurado, mas nÒo estava em uso.
/etc/init.d/heartbeat start Com isso, o Heartbeat irß ler os arquivos de configuraþÒo que apresentamos anteriormente e executar os comandos que criamos no arquivo haresources.
Neste momento, se observarmos no node0 as interfaces de rede atravÚs do comando ifconfig, Ú possÝvel notar que foi criado um alias (eth0:0) para a interface com o IP p·blico, como destaca a Listagem 6.
Listagem 6. Listagem das interfaces de rede e seus endereþos ap¾s o Heartbeat iniciar o node0.
eth0 Link encap:Ethernet HWaddr 00:0C:29:DA:14:35
inet addr:172.16.117.162 Bcast:172.16.117.255 Mask:255.255.255.0
eth0:0 Link encap:Ethernet HWaddr 00:0C:29:DA:14:35
inet addr:172.16.117.160 Bcast:172.16.117.255 Mask:255.255.255.0
eth1 Link encap:Ethernet HWaddr 00:0C:29:DA:14:3F
inet addr:192.168.0.2 Bcast:192.168.0.255 Mask:255.255.255.0 ╔ possÝvel ainda verificar que ele montou a partiþÒo que irß conter o resultado, atravÚs do comando df:
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/drbd0 507696 10549 470936 3% /mnt/apache Em seguida verifique que ele iniciou o serviþo do Apache. Use o comando ps ûaux | grep httpd:
4528 Ss /usr/bin/httpd
4537 S /usr/bin/httpd Se observarmos o log do Heartbeat, podemos ver as operaþ§es sendo executadas e ele fazendo com que os recursos (IP, disco e serviþo) migrem de um n¾ para o outro. O log fica localizado em /var/log/messages (veja a Listagem 7).
Listagem 7. O Heartbeat associa o IP 172.16.117.160 ao n¾ ativo.
node0 heartbeat: info: Local Resource acquisition completed.
node0 harc: info: Running /etc/ha.d/rc.d/ip-request-resp ip-request-resp
node0 ip-request-resp: received ip-request-resp IPaddr::172.16.117.160/24 OK yes
node0 ResourceManager: info: Acquiring resource group: node0 IPaddr::172.16.117.160/24 drbddisk::apache
Filesystem::/dev/drbd0::/mnt/apache::ext3::defaults httpd
node0 IPaddr: INFO: Resource is stopped
node0 ResourceManager: info: Running /etc/ha.d/resource.d/IPaddr 172.16.117.160/24 start Na parte em negrito da Listagem 7 vemos que o Heartbeat comeþou a executar os comandos que configuramos no arquivo haresources. Note que o Heartbeat primeiro cria o alias com IP 172.16.117.160.
Listagem 8. O Heartbeat monta a partiþÒo para uso e inicia o Apache.
node0 IPaddr: INFO: Using calculated nic for 172.16.117.160: eth0
node0 IPaddr: INFO: Using calculated netmask for 172.16.117.160: 255.255.255.0
node0 IPaddr: INFO: eval ifconfig eth0:0 172.16.117.160 netmask 255.255.255.0 broadcast 172.16.117.255
node0 IPaddr: INFO: Success
node0 Filesystem: INFO: Resource is stopped
node0 ResourceManager: info: Running /etc/ha.d/resource.d/Filesystem /dev/drbd0 /mnt/apache ext3 defaults start
node0 Filesystem: INFO: Running start for /dev/drbd0 on /mnt/apache
node0 kernel: kjournald starting. Commit interval 5 seconds
kernel: EXT3 FS on drbd0, internal journal
node0 kernel: EXT3-fs: mounted filesystem with ordered data mode.
node0 Filesystem: INFO: Success Na Listagem 8 vemos que o Heartbeat montou a partiþÒo /dev/drbd0 como /mnt/apache. Ainda na Listagem 8, tambÚm notamos que o Heartbeat iniciou o serviþo do Apache para receber as requisiþ§es de pßginas Web.
node0 ResourceManager: info: Running /etc/init.d/httpd start Nesse momento, se vocÛ acessar o endereþo http://172.16.117.160, verß o conte·do que estiver na partiþÒo /mnt/apache.
Para vermos a troca de identidades, ou seja, quem Ú o n¾ primßrio (ativo) e quem Ú o n¾ secundßrio (passivo) basta desconectar o cabo de rede do servidor node0.
Ao fazer isso, o node1 assumirß o papel como n¾ primßrio em poucos segundos. Depois acesse o servidor node1 e veja o conte·do do arquivo /var/log/messages.
Listagem 9. Log do servidor secundßrio no momento que o Heartbeat detecta que o outro n¾ estß inoperante.
node1 heartbeat: info: Link node0:eth1 dead.
node1 ipfail: info: Status update: Node node0 now has status dead
node1 harc: info: Running /etc/ha.d/rc.d/status status
node1 heartbeat: info: No local resources [/usr/share/heartbeat/ResourceManager listkeys node1] to acquire. O log exibido na Listagem 9 ilustra o momento em que node1 detecta que node0 estß inoperante e com isso identifica que precisa se apoderar dos recursos.
Se vocÛ repetir os comandos vistos quando iniciamos o Heartbeat, mas agora no node1, verß que ele assumiu o alias, montou a partiþÒo e iniciou o servidor apache.
ConclusÒo
Ao longo deste artigo vimos como Ú possÝvel configurar dois servidores para prover um serviþo de alta disponibilidade, com tempo de parada inferior a 30 segundos, utilizando-se apenas de hardware convencional e de software livre.
Os conceitos vistos aqui podem ser utilizados essencialmente em qualquer servidor/serviþo. Servidores de arquivo (como Samba ou NFS) e ainda servidores de banco de dados sÒo candidatos ideais e podem ser configurados para trabalhar nessa estrutura com um mÝnimo de esforþo.
A etapa mais importante Ú a de definir as aþ§es que o Heartbeat deverß executar ao iniciar um n¾ primßrio e ao transferir os recursos para o secundßrio. Isso lhe permitirß identificar as modificaþ§es, se houver, nas configuraþ§es dos serviþos a serem oferecidos e atingir padr§es de disponibilidade antes s¾ alcanþßveis com grandes investimentos.
Tudo isso com recursos disponÝveis a qualquer um com uma conexÒo Ó Internet e um pouco de dedicaþÒo.
Linux-HA
www.linux-ha.org
Planet HA
www.planet-ha.org
MySQL com DRBD
www.mysql.com/drbd
DRBD
www.drbd.org


Utilizamos cookies para fornecer uma melhor experiÛncia para nossos usußrios, consulte nossa polÝtica de privacidade.