Clique aqui para ler esse artigo em PDF.![]()

Clique aqui para ler todos os artigos desta ediçăo
Dúvidas frequentes sobre Banco de Dados
Cesar Blumm e Miguel Rodrigues Fornari
SGBDs săo utilizados há mais de trinta anos por diversas empresas. Ao longo deste tempo de uso, diversas dúvidas tornaram-se comuns, por exemplo, há diferença na utilizaçăo de VARCHAR e CHAR? Uma delas será mais rápida? De tăo comuns, é fácil encontrar em manuais e livros da área as respostas. Mas, será que estas respostas já năo estăo ultrapassadas frente ao avanço de software e hardware?
Neste artigo nós procuramos verificar se algumas respostas, frente ŕ evoluçăo da tecnologia, ainda săo verdadeiras, ou se devem ser alteradas. As perguntas analisadas foram:
· O que utilizar: VARCHAR ou CHAR?
· A existęncia de índices ajuda na execuçăo de um ORDER BY?
· Deve-se desligar os índices durante cargas de dados em uma tabela?
· A ordem das tabelas na cláusula FROM altera o tempo de resposta?
· É interessante manter as tabelas ordenadas no disco?
Para responder a cada uma destas cinco perguntas, um conjunto de testes foi realizado, medindo o tempo de resposta em tręs diferentes SGBDs: Oracle 10g (e ŕs vezes 9i), MS SQL Server 2000 e Firebird 1.5.2. Todas as operaçőes foram realizadas no mesmo servidor, ativando apenas um dos SGBDs por vez para evitar interferęncias. O servidor sempre esteve dedicado a realizar uma única consulta, sem sofrer interferęncia de usuários concorrentes. Os SGBDs estavam em sua configuraçăo default, exceto quando registrado o contrário.
Etapas no processamento de uma consulta
Antes de apresentarmos nossas respostas ŕs perguntas, é importante explicar, mesmo que brevemente, como funciona o processamento de um consulta. A Figura 1 ilustra o processo.
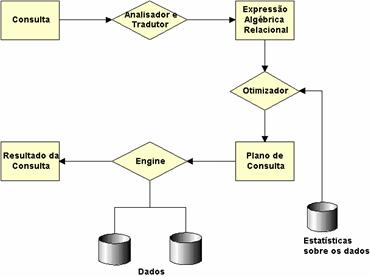
Figura 1. Etapas no processamento de uma consulta.
O usuário submete uma consulta em SQL. A primeira etapa, realizada pelo analisador, verifica a correçăo da consulta e a transforma em uma árvore de operaçőes básicas, mantida internamente em uma estrutura de dados específica. Se houver erros, o processo é interrompido e o erro retornado ao usuário. Na segunda etapa, o otimizador de consultas escolhe a melhor seqüęncia para realizar as operaçőes básicas e, entre os algoritmos possíveis para uma determinada operaçăo, o melhor deles. A ordem de execuçăo das operaçőes e o algoritmo selecionado para cada uma delas compőem o plano de consulta que, enfim, é realizado pelo engine do SGBD. Finalmente, a resposta da consulta pode ser enviada ao usuário.
Neste processo, o otimizador desempenha o papel central. Há dois tipos de otimizaçőes:
· otimizaçăo baseada em regras heurísticas. Estas regras estăo incorporadas ao Oracle. Em geral, elas produzem bons resultados, mas năo há comprovaçăo para garantir sua correçăo em todas as consultas;
· otimizaçăo baseada em estatísticas. Nesta opçăo, o otimizador utiliza algumas fórmulas para calcular o custo (tempo de processamento + tempo de acesso aos dados em disco) de várias opçőes possíveis, e escolher a opçăo que apresentar o menor custo estimado. Os dados estatísticos, como número de linhas em cada tabela e número de diferentes valores de cada atributo săo mantidos no dicionário de dados do SGBD.
Alguns SGBDs utilizam apenas um dos métodos, outros permitem que o DBA escolha o método de otimizaçăo que apresentar melhores resultados.
Tendo entendido como pode ser realizado o processamento de uma consulta, vamos agora analisar as perguntas formuladas no início desta matéria.
Pergunta 1: O que utilizar, VARCHAR ou CHAR?
A resposta mais comum afirma que atributos VARCHAR reduzem o espaço de armazenamento, porém atributos CHAR reduzem o tempo de resposta.
Para obter a resposta, foram criadas tabelas com diferentes tipos de atributos e número de registros. A estrutura básica das tabelas pode ser vista na Tabela 1. Há uma versăo com todos os campos alfanuméricos mapeados para CHAR, e outra com eles mapeados para VARCHAR. A cardinalidade das tabelas variou entre 50.000 (tabela pequena), 300.000 (tabela média) e 900.000 (tabela grande) registros.
|
Coluna |
Tipo |
|
Chave |
Alfanumérico(06) |
|
CampoCheio |
Alfanumérico(40) |
|
CampoVazio |
Alfanumérico(40) |
|
CampoMeio |
Alfanumérico(40) |
|
CampoData |
Data |
|
CampoInteiro |
Inteiro |
|
CampoDecimal |
Decimal(9,2) |
Tabela 1. Definiçăo das tabelas VARCHAR e CHAR.
A partir dos dados armazenados, foram realizadas diversas e repetidas vezes consultas por campos de índice, por campos comuns, utilizando a cláusula LIKE do SQL e por intervalo de registros, sempre aferindo os tempos para cada consulta realizada. Após as consultas, foram excluídas todas as linhas com o comando DELETE do SQL.
A primeira parte da resposta a esta pergunta afirma que tabelas com campo VARCHAR devem ocupar menos espaço em disco que as tabelas com campo CHAR.
Porém, no Firebird, é interessante notar que as tabelas CHAR estăo ocupando menos espaço na área de dados do que as tabelas VARCHAR. Ou seja, a resposta esta errada! Já na área de índices, as duas ocupam o mesmo espaço.
Resultados obtidos
A Tabela 2 mostra o espaço ocupado em disco, em Kb, para manter as duas versőes da tabela, no Firebird. É interessante notar que as tabelas CHAR estăo ocupando menos espaço na área de dados do que as tabelas VARCHAR.
|
Descriçăo |
VARCHAR: Tamanho em Kb |
CHAR: Tamanho em Kb |
VARIAÇĂO: Área de Dados |
|
Tabela pequena |
6.152 |
6.352 |
3,25% |
|
Tabela média |
... |

