


ustify>
Clique aqui para ler todos os artigos desta ediçăo
Conceito
Os índices săo estruturas opcionais associadas a tabelas e ‘clusters’ (Nota 1) que permitem que as consultas SQL sejam executadas mais rapidamente. Assim como o
índice analítico ou remissivo nesta revista lhe ajuda a encontrar mais rapidamente informaçőes, um índice de Oracle fornece um trajeto de acesso mais rápido aos dados da tabela. Vocę pode usar índices sem reescrever nenhuma consulta, os resultados da consultas săo os mesmos, mas vocę os vę mais rapidamente.
Uma tabela ‘cluster’ é um grupo de tabelas que compartilham os mesmos blocos de dados, desde que compartilhem colunas em comum e săo usadas frequentemente em conjunto. Quando vocę cria tabelas ‘cluster’, o Oracle armazena fisicamente todas as colunas para cada tabela nos mesmos blocos de dados. Os índices de tabelas de cluster podem conter várias tabelas ou apenas uma.
O Oracle fornece vários tipos de índices disponibilizando boas alternativas para todos os tipos de sistemas e processamentos no banco de dados. Veremos as diferentes possibilidades a partir de agora.
Este é o índice padrăo que o Oracle tem usado desde que as primeiras versőes. A fim de gerenciar corretamente os blocos, o Oracle controla o alocamento dos ponteiros
dentro de cada bloco dos dados. Uma “árvore de blocos” (analogia ŕ forma com a qual o Oracle aloca os blocos de dados) cresce através da inserçăo de linhas na tabela.
Quando um bloco é preenchido, o mesmo “racha”, a fim de criar novos “galhos”, ou se preferir, blocos de dados. É ai que entra o índice do tipo B-Tree, controlando ponteiros
dentro dos blocos de dados. (Figura 1).
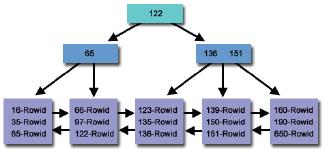
Figura 1. Estrutura de um índice B-Tree.
Portanto, um bloco de índice do Oracle pode conter dois tipos de ponteiros:
• Ponteiro para um outro nó de blocos de dados de índices;
• Ponteiros para linhas específicas da tabelas ou ROWID.
O Oracle controla o alocamento dos ponteiros dentro dos blocos de índice, e esta é a razăo pela qual somos incapazes de especificar um valor de PCTUSED (o ponto inicial
da utilizaçăo da freelist - lista de blocos livres) para índices. Quando examinamos uma estrutura de bloco do índice, percebemos que o número de entradas (de blocos de dados) dentro de cada nó do índice é em funçăo de dois valores:
• O tamanho da chave do índice;
• O tamanho do bloco da tablespace do índice.
O tamanho do bloco afeta o número de chaves de índice de cada nó do próprio índice. Um tamanho de bloco grande reduzirá também o número de “consistent gets”(Nota 2) durante o acesso do índice, melhorando o desempenho para acessos năo seqüenciais nos blocos de dados
Pelo fato do tamanho do bloco afetar o número das chaves dentro de cada bloco de dados do índice, entende-se que o tamanho do bloco terá um grande efeito na estrutura do índice B-Tree. Um bloco de dados de 32k terá mais chaves por bloco, tendo por resultado um índice mais “solto” do que o mesmo índice criado em um tablespace 2k. Hoje, a maioria dos experts em Oracle utiliza o tamanho de bloco múltiplo por fornecer uma maior manuseabilidade e a habilidade de colocar objetos com o tamanho de bloco mais apropriado reduzindo a má utilizaçăo do BUFFER.
Um tamanho de bloco maior significa mais espaço para o armazenamento das chaves nos nós secundários dos índices B-tree, que reduz o “peso” do índice no bloco e melhora o desempenho nas consultas. Em todo o caso, parece estar evidente que o tamanho de bloco afeta a estrutura dos índices B-Tree, que sustenta o argumento de que os blocos dos dados afetam a estrutura do mesmo.
Vocę pode usar um tamanho de bloco grande (16-32K) para conter dados dos índices ou das tabelas que săo o objeto de constantes varreduras.
Nota 2. Consistent Gets no Oracle
É o número das vezes que uma leitura consistente de um bloco foi solicitado pela Buffer Cache. Está é parte da SGA, e retém cópias de blocos dos dados de modo que possam ser alcançado mais rapidamente pelo Oracle do que os lendo do disco.
Chamamos de SGA um grupo de estrutura de memória (Redo Log Buffer, Shared Pool e Database buffer cachę).
O quanto isso poderia ajudar na performance?
Um teste pequeno, mas capaz de responder a essa pergunta, seria utilizar uma consulta em uma base de dados 9i que tenha um tamanho de bloco de dados de 8K, mas com 16K de CACHE habilitado em uma tablespace específica
conforme Listagem 1.
Listagem 1. Consulta simples.
SELECT COUNT(*)
FROM SCOTT.EMP
WHERE EMP_ID BETWEEN 1 AND 40000;
A tabela SCOTT.EMP possui 150.000 linhas e um índice na coluna de PATIENT_ID.
Um EXPLAIN PLAN (plano de execuçăo) da query revela que a mesma faz uma varredura de multi-blocos do índice a fim de produzir o resultado desejado (Listagem 2).
Listagem 2. Plano de execuçăo da consulta.
Execution Plan
-------- -------------- ----------------------------------
SELECT STATEMENT Optimizer=CHOOSE
(Cost=41 Card=1 Bytes=4)
1 0 SORT (AGGREGATE)
...


Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.