ustify>

Clique aqui para ler todos os artigos desta ediçăo
Gerenciando um cluster PostgreSQL com PGCluster
Uma forma simples e prática de gerenciar bancos de dados PostgreSQL
Na sua forma mais básica, um cluster é um sistema que compreende dois ou mais computadores ou sistemas (denominados nós) onde trabalham em conjunto para executar aplicaçőes ou realizar outras tarefas de tal forma que os usuários que os utilizam tenham a impressăo que somente um único sistema responde para eles (computador virtual). Este conceito é denominado transparęncia do sistema. Como características fundamentais para a construçăo destas plataformas incluem-se elevaçăo da confiança, distribuiçăo de carga e performance.
PGCluster é um sistema síncrono de replicaçăo de composiçăo multi-master para PostgreSQL. Devido ao fato do sistema de replicaçăo ser um sistema síncrono, atrasos năo irăo ocorrer na duplicaçăo de dados entre os servidores de armazenamento. Em um servidor de composiçăo multi-master, dois ou mais servidores de armazenamento podem ser acessados simultaneamente por um usuário.
Nesse artigo serăo mostradas as possibilidades de uso do PGCluster como gerenciador de cluster bem como vantagens e desvantagens de cada possibilidade, o funcionamento interno, sua arquitetura, maneiras de configuraçăo e procedimento de recuperaçăo de dados.
Replicaçăo de dados
O objetivo de um mecanismo de replicaçăo de dados é permitir a manutençăo de várias cópias de um mesmo dado em vários servidores de banco de dados (SGBD). Os principais benefícios da replicaçăo de dados săo:
· redundância, o que torna o sistema menos sensível ŕs falhas;
· possibilidade de balanceamento de carga do sistema, já que o acesso pode ser distribuído entre as réplicas;
· e finalmente, ter-se um backup on-line dos dados, já que todas as réplicas estariam sincronizadas.
Existem basicamente dois tipos de replicaçăo: a replicaçăo assíncrona e a síncrona. Na replicaçăo assíncrona (armazena e faz a replicaçăo), a cópia dos dados fica fora de sincronia entre os bancos de dados. Se um banco é alterado, a alteraçăo será propagada e aplicada para outro(s) banco(s) num segundo passo, dentro de uma transaçăo separada sendo que esta poderá ocorrer segundos, minutos, horas ou até dias depois. A cópia poderá ficar temporariamente fora de sincronia, mas quando a sincronizaçăo ocorrer, os dados convergirăo para os locais especificados.
Na replicaçăo síncrona, todas as cópias ou replicaçőes de dados serăo feitas no instante da sincronizaçăo e consistęncia. Se alguma cópia do banco é alterada, essa alteraçăo será imediatamente aplicada a todos os outros bancos dentro da transaçăo. Os servidores replicados cooperam usando estratégias sincronizadas e protocolos especializados de réplica para manter os conjuntos de dados replicados coerentes. A replicaçăo síncrona é apropriada em aplicaçőes comerciais onde a consistęncia exata das informaçőes é de extrema importância. Esse é o tipo de replicaçăo abordada pelo PGCluster.
Na próxima seçăo será apresentado, em mais detalhes, como funciona o PGCluster e o processo interno de replicaçăo.
PGCluster
O PGCluster é um sistema de replicaçăo síncrona de composiçăo multi-master, e que pode trabalhar de duas maneiras principais: compartilhamento de acesso e alta disponibilidade.
No caso do compartilhamento de acesso, a partir da combinaçăo de servidores de armazenamento e servidor de replicaçăo pode-se criar um sistema onde será possível minimizar a carga do acesso e fazer consultas de maneira distribuída pelo cluster. Com a adiçăo de um balanceador de carga (servidor responsável por distribuir a carga de acesso ao cluster), o PGCluster configura um sistema de alta disponibilidade. O balanceador de carga e o servidor de replicaçăo separam um nó que ocasionalmente falhe e continuam a servir com o restante do sistema. Assim que a máquina que falhou for restabelecida, os dados săo copiados para ela automaticamente. O mesmo acontece com um novo nó que venha a se integrar ao sistema.
Arquitetura geral do sistema
A query de uma transaçăo é replicada de dois modos: normal e confiável. A diferença entre os dois é que no modo normal uma resposta é enviada ao front-end (aplicaçăo que gerou a alteraçăo no banco) após a execuçăo da query no servidor de armazenamento ao qual a mesma foi destinada. Já no modo confiável, a resposta é enviada após a query ter sido executada em todos os servidores de armazenamento, ou seja, após a modificaçăo ter sido replicada para todos os nós envolvidos. Graficamente, a diferença entre os dois modos é evidenciada pelas Figuras 1 e 2.
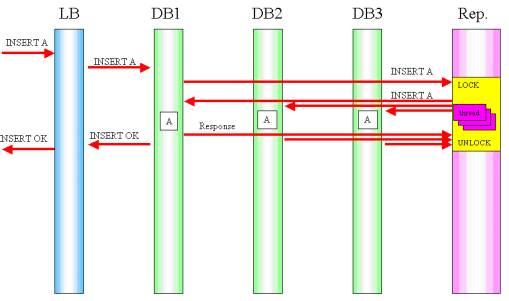
Figura 1. Fluxo das transaçőes da replicaçăo (Modo Normal).
A Figura 1 mostra os servidores que formam o cluster. Balanceador de carga (LB), servidores de armazenamento (DB1, DB2 e DB3), e servidor de replicaçăo (Rep). Nesse fluxo, a solicitaçăo de alteraçăo do banco é enviada inicialmente ao balanceador de carga, que direciona para o servidor de armazenamento com menos carga (com base no número de sessőes abertas e em andamento). Entăo, o servidor de replicaçăo envia a alteraçăo para todos os outros servidores de armazenamento.
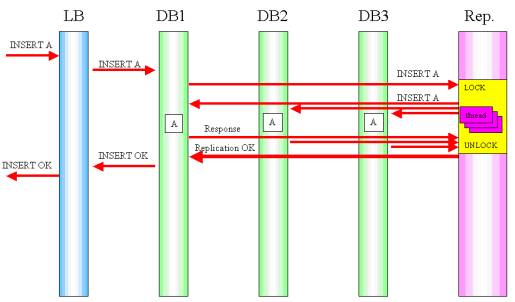
Figura 2. Fluxo das transaçőes da replicaçăo (Modo Confiável).
De maneira similar, na Figura 2, o modo de replicaçăo confiável segue o mesmo fluxo, porém só envia a resposta após a alteraçăo ter sido replicada em todos os servidores de armazenamento do cluster.
...

