AN style="FONT-SIZE: 10pt; BACKGROUND: white; COLOR: red; FONT-FAMILY: Verdana; moz-background-clip: -moz-initial; moz-background-origin: -moz-initial; moz-background-inline-policy: -moz-initial">
PAN>

re eles.
Em que situaçăo o tema é útil:
Todas as grandes corporaçőes do mercado de sistemas de geręncia de conteúdo estăo envolvidas no desenvolvimento e disseminaçăo da especificaçăo. Sendo assim, o conhecimento da especificaçăo permite ao desenvolvedor criar aplicativos capazes de se comunicar de maneira uniforme com todos estes sistemas que implementam a API.
Introduçăo a JCR:
A especificaçăo JSR-170 define a API Java Content Repository (JCR), que traz o conceito de repositórios de conteúdo para as aplicaçőes. Repositórios săo uma nova abstraçăo de modelo de persistęncia de dados que substitui a necessidade do uso de sistemas de arquivos e bancos de dados relacionais, disponibilizando um apanhado das melhores funcionalidades destes dois tipos de sistemas. Além disso, repositórios săo extremamente flexíveis quanto ŕ estruturaçăo dos dados que controla, o que é uma abordagem bastante interessante para o desenvolvimento de aplicaçőes voltadas a conteúdo.
Com o crescente número de sistemas de gerenciamento de conteúdo (CMS, sigla para Content Management System), surgiu a necessidade de padronizaçăo na forma de intercâmbio entre estes “silos” de dados. É esta necessidade que a JCR 1.0 (Java Content Repository, também referenciada como Content Repository API) tem por objetivo suprir.
Neste artigo serăo apresentados os detalhes da especificaçăo e sua utilizaçăo será exemplificada com uma aplicaçăo web simples, que utiliza um repositório de conteúdo baseada no Apache Jackrabbit, a implementaçăo de referęncia e de código aberto da especificaçăo JSR-170.
A especificaçăo
A Content Repository API é definida pela especificaçăo JSR-170, cujo expert group é liderado por David Nuescheler, CIO da Day Software, empresa que desenvolve o software Day CRX, que implementa todas as camadas da especificaçăo. Participam também do expert group importantes empresas do mercado de geręncia de conteúdo, como IBM, BEA, Documentum e Oracle.
A necessidade de uma especificaçăo para esta área surgiu quando observou-se a dificuldade na interoperabilidade entre os sistemas de gerenciamento de conteúdo existentes. Mesmo organizando os dados internamente de forma similar, essas instâncias de dados heterogęneas acrescentavam um novo nível de problemas no momento em que se desejava fazer uma substituiçăo de algum desses sistemas, ou quando a tarefa era implementar uma aplicaçăo que agregava dados provenientes de dois ou mais sistemas distintos.
O objetivo
O objetivo da especificaçăo JSR-170 é prover uma interface de programaçăo que seja ao mesmo tempo simples de usar para os programadores e de fácil implementaçăo e adoçăo para os desenvolvedores de repositórios de conteúdo. Ao atingir estas metas, a especificaçăo torna-se difundida entre os desenvolvedores e também um padrăo de fato.
Com o propósito de ser fácil de implementar e adaptar a repositórios de conteúdo já existentes, a Java Content Repository API foi dividida em camadas. A especificaçăo define também os níveis de conformidade para cada camada, podendo uma implementaçăo JCR năo dispor de funcionalidades de todas as camadas. Este conceito será mais bem compreendido após a análise de cada uma das camadas.
As camadas
A primeira camada da especificaçăo define um repositório somente-leitura. Isto inclui funcionalidades de leitura do conteúdo, introspecçăo sobre a definiçăo dos tipos, ou seja, a capacidade de identificar como está estruturado o conteúdo em questăo, o suporte básico a namespaces, a capacidade de exportar o conteúdo para um arquivo XML, e a busca.
A segunda camada introduz os métodos para a escrita de conteúdo no repositório, a atribuiçăo de tipos ao conteúdo, suporte avançado a namespaces e a importaçăo de dados a partir de um arquivo XML.
Finalmente, a terceira camada define as funcionalidades opcionais que um repositório de conteúdo em conformidade com a especificaçăo pode implementar. Săo eles o suporte a transaçőes, controle de versăo de conteúdo, observabilidade (capacidade de executar determinado código no evento de mudança de alguma propriedade do conteúdo), controle de acesso, travamento (“locking”, capacidade de bloquear determinado conteúdo para escrita) e suporte adicional a busca.
A presença de todas estas funcionalidades em um único mecanismo de persistęncia de dados faz do JCR uma alternativa bastante poderosa se comparada a outros mecanismos existentes. Por exemplo, năo é incomum que uma aplicaçăo Java precise persistir seus dados em um banco de dados relacional, onde as informaçőes săo armazenadas de forma tabular, e em um sistema de arquivos, onde é mais conveniente persistir dados binários e onde se pode organizar esta informaçăo de forma hieráriquica (em diretórios e subdiretórios). Neste caso é possível substituir os dois mecanismos apenas por um repositório, onde há a liberdade de estruturaçăo do conteúdo (os dados) de qualquer uma das formas. Outros recursos desses mecanismos de persistęncia também săo cobertos pela especificaçăo, como mostra a Figura 1.
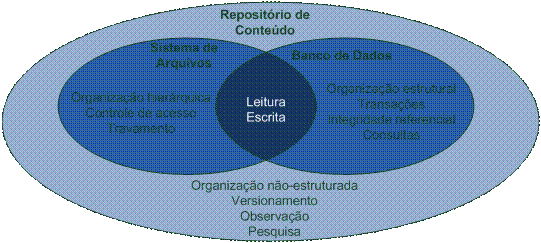
Figura 1. Diagrama de funcionalidades disponíveis em sistemas de arquivos, bancos de dados e repositórios de conteúdo.
A organizaçăo do repositório
Um repositório é composto por um ou mais workspaces, onde cada workspace contém uma árvore de itens. Um item pode ser um nó ou uma propriedade. Cada nó pode ter zero ou mais itens filhos. Em um workspace existe um único nó raiz, o qual năo tem pai. Todos os outros nós tęm um pai. Propriedades tęm um nó pai e năo podem ter itens filhos, isto é, propriedades săo nós-folha em um workspace. Um exemplo de workspace pode ser visto na Figura 2, e um diagrama exemplificando o relacionamento entre itens, nós e propriedades está na Figura 3.
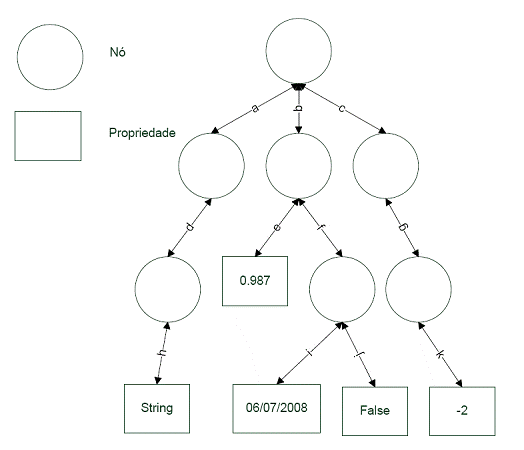 ...
...

