Em 1999 foi publicado o atual padrăo SQL, conhecido como SQL:1999 ou SQL3, e uma nova versăo já está prevista para este ano. Neste artigo apresentaremos uma descriçăo resumida dos recursos incluídos no SQL:1999.
Histórico do SQL
A tecnologia de bancos de dados relacional se baseia na teoria de conjuntos e foi proposta pelo matemático Edgar F. Codd, no início da década de 1970, enquanto ele trabalhava para a IBM. Essa tecnologia é uma das mais bem sucedidas na área da computaçăo e deu a Codd, em 1981, o equivalente ao Pręmio Nobel nesta área, o ACM Turing Award.
A teoria relacional foi amplamente aceita e logo suplantou os modelos de dados em rede e hierárquico. Surgiram novos SGBDs, onde os usuários visualizam seus dados como tabelas bidimensionais ou relaçőes (daí o nome relacional). Um desses SGBDs relacionais, o System R, foi desenvolvido pela IBM e utilizava uma linguagem de consulta denominada SEQUEL. Essa linguagem é conhecida como a ancestral do SQL.
Em 1984, apenas 20% dos gerenciadores de bancos de dados seguiam o modelo relacional. Em 1990, já contabilizavam 80% do market-share. Com a consolidaçăo da tecnologia relacional, o comitę ANSI H2 se tornou responsável, ao longo dos anos, pela definiçăo de um padrăo para uma linguagem de consulta a SGBDs relacionais. O primeiro padrăo foi publicado em 1986 e por conta disso acabou denominado SQL-86. Entre 1986 e 1989 outras características foram adicionadas, dando origem ao SQL-89. Tręs anos depois foi lançado o SQL-92.
Com o passar do tempo, as exigęncias das aplicaçőes começaram a exceder a capacidade dos SGBDs relacionais. Na metade dos anos 80 surgiu um novo modelo de dados, onde, ao invés de tabela, o conceito principal é o de classe. Era a orientaçăo a objetos entrando no mundo dos bancos de dados. A teoria desse modelo ganhou importância e, no início da década de 90, havia diversos SGBDs orientados a objetos comerciais. Alguns exemplos săo: ORION (MOC), OPENOODB (Texas Instruments), Iris (HP), GEMSTONE (GEMSTONE Systems), ONTOS (Ontos), Objectivity (Objectivity Inc.), ARDENT (ARDENT software) e POET (POET Software).
Em 1991 foi formado um grupo para padronizar as funcionalidades dos bancos de dados orientados a objetos (BDOOs), o ODMG (Object Database Management Group). O consórcio é constituído por fabricantes de SGBDs e empresas que trabalham na criaçăo de padrőes para esse segmento. Dentre outras coisas, o ODMG definiu um modelo de dados e uma nova linguagem de consulta.
O modelo de dados, denominado ODL (Object Definition Language), define estruturas arbitrariamente complexas (classes). Nesse modelo, os atributos de um objeto podem conter tipos de dados estruturados, ao contrário do modelo relacional, onde as tabelas só podem armazenar itens atômicos. A ODL também define a herança entre classes. Se for utilizada uma linguagem OO para construçăo do sistema, o uso deste modelo permite um mapeamento mais direto entre a aplicaçăo e o banco de dados.
A linguagem de consulta definida pelo ODMG se baseou fortemente no padrăo SQL-92 e foi chamada de OQL (Object Query Language). Entre os principais recursos, a OQL permite recuperar e manipular objetos armazenados e possui extensőes para identidade de objetos, objetos complexos, expressőes de caminho, métodos e herança.
Algumas pessoas pensaram que os bancos de dados orientados a objetos (BDOOs) suplantariam a tecnologia relacional de Codd. Afinal, esse novo conceito estava em perfeita sintonia com o paradigma da orientaçăo a objetos que, no contexto das linguagens de programaçăo, vinha ganhando mais força. No entanto, a reaçăo dos principais fabricantes de SGBDs relacionais da época foi incorporar características OO em seus produtos. Pode-se dizer que esses sistemas sofreram uma espécie de metamorfose, adotando o conceito objeto-relacional, nome dado ao modelo relacional adicionado de características da orientaçăo a objetos. Atualmente, os BDOOs săo pouco utilizados. Há pouca ou nenhuma dúvida que os SGBDs objeto-relacionais (SGBDORs) venceram a batalha. Dois dos principais representantes dessa geraçăo de SGBDORs săo o Oracle 9i e o DB2 Universal Server.
Os SGBDORs se livraram de uma das principais limitaçőes do modelo relacional: a primeira forma normal (1FN). Na prática, a 1FN limita o conteúdo de qualquer campo a armazenar somente valores atômicos. Em um SGBDOR, um campo pode armazenar um valor estruturado.
De forma geral, um SGBDOR possui capacidade de gerenciar tanto dados relacionais quanto objetos, sendo ideal para manipular dados de aplicaçőes como CAD/CAM (Computer Aided Design/Computer Aided Manufacturing) e Multimídia.
Com o passar do tempo, os fornecedores de SGBDORs passaram a incluir diversas extensőes, cada um com sua implementaçăo, que possuíam o mesmo objetivo. O comitę ANSI H2 surgiu novamente em cena, com a ajuda de um comitę ISO (ISO/IEC JTC 1/SC 32/WG 3), para definir uma nova linguagem padrăo.
A estratégia adotada pelo comitę foi estender a SQL, já que o modelo objeto-relacional é uma extensăo do modelo relacional. A definiçăo de extensőes ao padrăo SQL-92 começou logo após seu lançamento e recebeu o codinome SQL-3. A partir de 1999, ano de sua publicaçăo, o novo padrăo passou a ser chamado oficialmente de SQL:1999. O SQL:1999 foi desenvolvido com o intuito de manter a compatibilidade com os bancos de dados e as aplicaçőes que utilizavam a SQL-92.
A figura 1 resume toda a saga da evoluçăo das linguagens de consulta até o surgimento do SQL:1999.
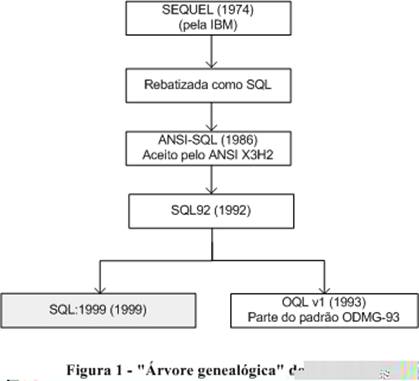
Atualmente, o comitę ANSI/ISO está trabalhando em uma nova versăo do SQL, cujo codinome é SQL:2003, com publicaçăo prevista para julho deste ano. No entanto, algumas pessoas utilizam o nome SQL-200n, prevendo um possível adiamento neste lançamento.
Apogeu e Queda do Padrăo SQL?
Segundo Michael Gorman, presidente da WISCorp e secretário do comitę HANSI/ISO, a existęncia de padrőes e mecanismos para verificar sua conformidade, na era digital, é de grande importância. Padrőes săo essenciais na indústria de software para evitar que grandes corporaçőes cometam abusos.
Para que um padrăo tenha sucesso, săo necessários basicamente tręs requisitos: existir uma comunidade significativa de empresas do segmento que o aceitam; as especificaçőes devem estar publicamente disponíveis e em contínuo aperfeiçoamento e adaptaçăo e, por último, existir testes de conformidade ao padrăo, que devem ser impostos aos produtos.
Até a versăo SQL-92, a linguagem seguia ŕ risca os requisitos acima. O SQL contava com aproximadamente 15 anos de pesquisa e desenvolvimento pela IBM e outras corporaçőes. Foi homologado em 1986 pelo ANSI e em 1988 pela ISO. Grandes empresas como Oracle, Informix, IBM e Sybase, aderiram ao padrăo. O SQL original (1986) sofreu duas grandes extensőes até chegar ao SQL-92, sendo que cada uma dessas extensőes era compatível com as anteriores. Além disso, de 1980 até 1996, todos os SGBDs que diziam estar em conformidade com o SQL tinham que ser submetidos a uma bateria de testes de conformidade pelo NITS (National Institute of Standards and Technology) antes que pudessem ser vendidos para agęncias federais dos EUA.
O papel do NITS foi fundamental para o crescimento e difusăo do SQL, năo só nos EUA mas em todo o mundo. Para que pudessem vender para os órgăos federais americanos os fabricantes de SGBDs tinham, necessariamente, que adequar seus produtos aos testes de conformidade do NITS. Esse teste acirrou a competiçăo, diminuiu os preços e fez com que a qualidade dos gerenciadores aumentasse.
No entanto, em dezembro de 1996, a infra-estrutura do NITS para realizaçăo de testes de conformidade foi desmantelada por uma decisăo inexplicável de algum burocrata norte-americano. Como resultado, o que se vę săo os fornecedores de SGBDs direcionando o desenvolvimento para produtos que năo estăo em completa conformidade com o SQL:1999. Em 1998, os principais fabricantes de SGBDs declararam, em uma das reuniőes do X3H2 (grupo de padronizaçăo do SQL), que năo tinham mais interesse em manter uma padronizaçăo.
Atualmente, o que se percebe é que năo há muita sintonia entre o que está sendo definido pelo comitę ANSI/ISO e o que está sendo implementado nos produtos. Na verdade, há variaçőes significativas entre as funcionalidades dos SGBDORs e o padrăo SQL:1999.
Somado ŕ desativaçăo das atividades de teste de conformidade do NITS, duas outras razőes contribuíram para o cenário atual. A primeira foi o atraso na publicaçăo do SQL:1999. A segunda é a relativa complexidade do SQL:1999 em relaçăo aos padrőes anteriores. Para uma idéia geral, observe o número de páginas de cada versăo:
Padrăo
Número de páginas
SQL86
105
SQL89
120
SQL92
575
SQL:1999
1500+
Atualmente
3000+
Diante desse cenário, a universalidade do SQL que existia até pouco tempo parece ameaçada. Com certeza, a linguagem continuará a ser utilizada por muitos e muitos anos. Mas será que os principais SGBDs continuarăo a seguir o padrăo? Ou uma nova torre de Babel será formada no segmento de banco de dados? A essas perguntas, só o futuro responderá.
Visăo Geral do SQL:1999
No SQL:1999 o conceito fundamental năo foi alterado: a tabela continua sendo o único meio pelo qual os dados săo armazenados. As operaçőes relacionais de seleçăo, projeçăo, junçăo, uniăo e interseçăo săo semelhantes ŕs existentes no SQL-2. Além disso, o SQL:1999 dá suporte aos mesmos tipos de dados básicos que já existiam no padrăo anterior.
O SQL:1999 é constituído de várias seçőes que compőem um núcleo e de uma série de pacotes especificados sobre este núcleo. A lista a seguir apresenta as seçőes atuais. As cinco primeiras foram publicadas em 1999 e pertencem ao SQL:1999. As demais vęm sendo desenvolvidas desde entăo para formar a versăo SQL:200n.
- Parte 1 (SQL/Framework): fornece uma visăo geral do padrăo e apresenta definiçőes e convençőes utilizadas nas demais seçőes (aproximadamente 75 páginas).
- Parte 2 (SQL/Foundation): corresponde ao núcleo. Contém definiçőes que já existiam no SQL/92 e extensőes objeto-relacionais (aproximadamente 1100 páginas).
- Parte 3 (SQL/CLI - Call-Level Interface): especifica uma API para acesso direto ao SGBD. A implementaçăo mais conhecida é a ODBC da Microsoft (aproximadamente 400 páginas).
- Parte 4 (SQL/PSM - Persistent Stored Modules): extensőes ŕ SQL para torná-la uma linguagem procedural.
- Parte 5 (SQL/Bindings): define funçőes para chamada direta através de uma linguagem de programaçăo. Esta seçăo está sendo embutida na Parte 2 (SQL/Foundation).
- Parte 6 (SQL/Transaction): obsoleta.
- Parte 7 (SQL/Temporal): manipulaçăo de dados que representam séries temporais.
- Parte 8: obsoleta.
- Parte 9 (SQL/MED - Management of External Data): gerenciamento de dados externos ao SGBD (emails, documentos HTML, planilhas, vídeos e outros).
- Parte 10 (SQL/OLB - Object Language Bindings): Bindings para linguagens orientadas a objeto, como Java e C++.
- Parte 11 (SQL/Schemata): informaçőes e definiçőes de esquemas.
- Parte 13 (SQL/JRT): rotinas e tipos usando Java.
- Parte 14 (SQL/XML): especificaçőes relacionadas ŕ linguagem XML.
A lista dá uma ideia do grau de complexidade do SQL:1999. Veremos, de forma resumida, suas principais características.
Novos Tipos de Dados
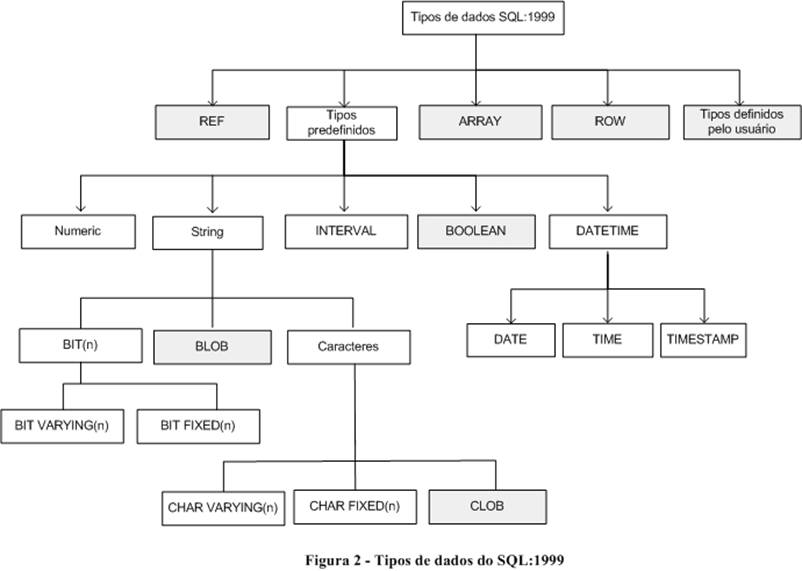
Foram incluídos novos tipos de dados básicos: BOOLEAN, CLOB (Character Large Object), BLOB (Binary Large Object), ARRAY e ROW. Existe também a possibilidade de criar tipos definidos pelo usuário (UDT). A figura 2 apresenta a hierarquia de tipos de dados do SQL:1999. Os retângulos destacados correspondem aos novos tipos.
BLOB e CLOB
Um campo BLOB pode armazenar dados binários, como uma imagem. Um CLOB é estruturalmente similar ao BLOB, com a diferença de armazenar caracteres, como um currículo ou uma coleçăo de artigos.
Em um BLOB/CLOB os operadores ‘>’ e ‘<’ năo podem ser utilizados. Operadores de comparaçăo para esse tipo săo igualdade (‘=’) e desigualdade (‘<>’). BLOBs e CLOBs também năo podem ser utilizados em definiçőes de chaves primárias e chaves estrangeiras ou em cláusulas ORDER BY e GROUP BY.
O SQL:1999 também define o conceito de demarcador (locator). Ele serve como uma referęncia para uma instância de um BLOB/CLOB e evita que todo seu conteúdo seja transferido do banco de dados para a aplicaçăo.
No exemplo a seguir, vemos uma tabela que possui um campo do tipo CLOB que pode armazenar até 25.000 caracteres. Essa tabela também possui um campo BLOB que pode armazenar até 5.000 bytes.
CREATE TABLE Empregado
(nome CHAR VARYING(15),
currículo CLOB(25K) CHARACTER SET BRAZILIAN,
foto BLOB(5K));
BOOLEAN
É o tipo lógico. Possui como domínio de valores o conjunto {TRUE, FALSE, UNKNOWN}. No SQL:1999, expressőes que retornam valores do tipo BOOLEAN săo tratadas como predicados.
ARRAY
O tipo ARRAY representa um vetor unidimensional, ou seja, uma lista contendo uma quantidade variável de elementos do mesmo tipo. Năo săo permitidos vetores multidimensionais (vetor de vetores). O acesso aos elementos de um vetor é feito através da posiçăo ordinal de cada um.
O operador UNNEST é usado na transformaçăo de uma coluna do tipo ARRAY em uma tabela cujas linhas contęm os valores armazenados no vetor.
No exemplo a seguir é definida uma tabela que possui um campo do tipo ARRAY. Esse campo pode armazenar até 20 cadeias de caracteres, cada uma com 30 posiçőes.
CREATE TABLE Cidade
(nome VARCHAR(30),
populaçăo INTEGER,
parques CHAR(30) ARRAY[20]);
-- Utiliza o construtor de array, através do par de colchetes.
INSERT INTO Cidade
VALUES(‘Campo Belo’, 30000, ARRAY[‘Parque da Saudade’, ‘Parque Esmeralda’]);
-- Seleciona o nome da cidade e o nome do primeiro parque.
SELECT nome, parques[1] AS parque FROM Cidade
-- Seleciona o nome da cidade e o nome de cada parque.
SELECT C.nome, P.nome FROM Cidade AS C, UNNEST(C.parques) AS P(nome)
ROW
O tipo ROW define explicitamente uma estrutura dentro de uma coluna. Em essęncia, se trata de uma tabela aninhada dentro de outra tabela (um distanciamento do modelo relacional original, que pressupőe tabelas normalizadas). O tipo ROW é semelhante aos tipos struct e record das linguagens C e Pascal, respectivamente.
O exemplo a seguir define uma tabela para armazenar informaçőes sobre empregados, onde cada empregado possui um nome e um endereço. Essa última informaçăo é modelada como um tipo ROW: um endereço é uma estrutura formada pelos campos logradouro, cidade, UF e CEP. Note que é possível manter diversos níveis de aninhamento, como ilustra a definiçăo do campo CEP. Esse exemplo também mostra que o tipo ROW pode ser nomeado ou năo nomeado (ao contrário do campo CEP, TipoEndereco é um ROW nomeado).
CREATE ROW TYPE TipoEndereço
(logradouro CHAR(30),
cidade CHAR(20),
unidadeFederativa CHAR(2),
CEP ROW(prefixo CHAR(5), sufixo CHAR(3));
CREATE TABLE Empregados
(nome CHAR(40),
endereço TipoEndereco);
Os componentes de um campo ROW săo acessados através do operador ‘.’. Veja um exemplo:
INSERT INTO Empregados
VALUES (‘Ana Silva’, (‘Rua XYZ, 28’, ‘Cuiabá’, ‘MT’, (‘22733’, ‘000’)));
SELECT E.nome, E.endereço.cidade FROM Empregados E;
Novos Predicados
Um novo predicado, denominado SIMILAR, é uma extensăo do conhecido LIKE e pode ser utilizado para definir expressőes regulares. Para os amantes do Unix, o predicado é semelhante ao comando GREP.
A expressăo a seguir retorna TRUE se o campo nome estiver preenchido com SQL-86, SQL-89, SQL-82, SQL-99, SQL-1, SQL-2 ou SQL-3.
<p align="left">SELECT *
<p align="left">FROM Livros
<p align="left">WHERE título SIMILAR TO '(SQL-(86|89|92|99))|(SQL(1|2|3))'
No SQL:1999, o predicado DISTINCT também é utilizado para comparar valores NULL. Se duas colunas possuírem o valor NULL, serăo consideradas iguais e DISTINCT retornará FALSE. Como exemplo, temos uma consulta “SELECT B FROM T1 WHERE (A, C) IS DISTINCT FROM (10, NULL)” sobre uma tabela imaginária T1. A tabela T2 corresponde ao resultado da execuçăo. Veja o gráfico a seguir:
| A | B | C |
|---|---|---|
| 10 | Joăo | NULL |
| 11 | Maria | 10 |
| 10 | José | NULL |
| 10 | Ana | 10 |
| Maria |
| Ana |
DISTINCT foi redefinido para complementar a funcionalidade de um predicado já existente no SQL-92, o UNIQUE. Para UNIQUE, dois valores NULL săo sempre considerados diferentes um do outro, o que pode năo ser adequado em algumas situaçőes.
Módulos Persistentes Armazenados
A construçăo de rotinas é uma das grandes extensőes apresentadas pelo SQL:1999. Este recurso, que está sendo definido na seçăo 4 sob o nome de SQL/PSM, torna a SQL uma linguagem computacionalmente completa. Isso é o equivalente ao que temos hoje com as linguagens PL/SQL (Oracle), Transact/SQL (Microsoft SQL Server) e SPL (Informix).
Entre os recursos definidos na SQL/PSM estăo a declaraçăo de variáveis (DECLARE), atribuiçăo de valores (SET), blocos de comandos (BEGIN, END), comandos de repetiçăo (LOOP, FOR, WHILE, REPEAT), comandos condicionais (CASE, IF...THEN), tratamento de erros (SIGNAL, RESIGNAL) e chamada de rotinas (CALL, LEAVE).
Há dois tipos de rotinas: procedimentos e funçőes. A diferença principal é que a funçăo retorna um valor explicitamente; um procedimento pode retornar um valor somente através de um parâmetro de saída. Os procedimentos contęm parâmetros de entrada (IN), parâmetros de saída (OUT) ou parâmetros que săo tanto de entrada quanto de saída (INOUT). Já os parâmetros de funçăo săo sempre de entrada. Além disso, toda funçăo deve declarar o tipo de retorno através da cláusula RETURNS.
Uma rotina possui uma assinatura e um corpo. A assinatura contém o nome da rotina e uma lista, possivelmente vazia, de parâmetros. Parâmetros devem ter um nome e podem ser de qualquer tipo SQL.
O SQL:1999 especifica duas formas para implementaçăo do corpo de uma rotina: através de instruçőes SQL ou através de rotinas externas, codificadas em uma linguagem de programaçăo ŕ parte.
O corpo de uma rotina escrita com SQL consiste em um bloco de comandos delimitados por BEGIN e END. Em rotinas năo săo permitidos comandos DDL (Data Definition Language). Os comandos COMMIT, ROLLBACK, CONNECT e DISCONNECT também năo podem ser usados.
O exemplo a seguir apresenta duas rotinas SQL equivalentes: um procedimento e uma funçăo. Ambas recuperam o saldo a partir de um número de conta passado como parâmetro de entrada (IN). A funçăo contém um comando RETURN para retornar o valor calculado. Já o procedimento retorna o valor através de um parâmetro de saída (OUT).
CREATE PROCEDURE ObterSaldo (IN númeroConta INTEGER, OUT s DECIMAL(15,2))
BEGIN
SELECT saldo INTO s FROM ContasBancárias WHERE número = númeroConta;
IF s < 0
THEN SIGNAL saldo_negativo
END IF;
END
CREATE FUNCTION ObterSaldo(númeroConta INTEGER) RETURNS DECIMAL(15,2)
BEGIN
DECLARE s DECIMAL(15,2)
SELECT saldo INTO s FROM ContasBancárias WHERE número = númeroConta;
IF s < 0
THEN SIGNAL saldo_negativo
END IF;
RETURN s; -- retorna o valor calculado.
END
A assinatura de uma rotina externa deve ser declarada no esquema do banco de dados. Nessa definiçăo, a cláusula LANGUAGE identifica a linguagem na qual a rotina foi implementada. A palavra EXTERNAL NAME indica a localizaçăo do código objeto.
Quando uma rotina externa é chamada, o SGBD se encarrega de obter o código objeto, inicializar os parâmetros e executá-la. O exemplo a seguir apresenta algumas declaraçőes de rotinas externas:
CREATE PROCEDURE ObterSaldo(IN númeroConta INT, OUT bal DECIMAL(15,2))
LANGUAGE C
EXTERNAL NAME 'home/bezerra/banco/saldo'
CREATE FUNCTION ObterSaldo(INTEGER) RETURNS DECIMAL(15,2))
LANGUAGE C
EXTERNAL NAME 'home/bezerra/banco/saldo
As funçőes podem ser utilizadas em comandos de seleçăo, tanto na cláusula SELECT quanto na cláusula WHERE. Já os procedimentos săo executados através do comando CALL e normalmente fazem parte de alguma outra rotina. Vejamos dois exemplos:
-- Comando de seleçăo que envolve a chamada da funçăo ObterSaldo.
SELECT númeroConta, ObterSaldo(númeroConta)
FROM ContasBancárias
-- Sintaxe para chamada do procedimento ObterSaldo. Normalmente esta chamada estaria dentro de outra rotina.
CALL ObterSaldo(100, bal);
O SQL:1999 define comandos para remover (DROP) e alterar (ALTER) rotinas. Os direitos de execuçăo das rotinas também podem ser especificados através dos comandos GRANT e REVOKE.
Triggers
O SQL:1999 introduz o conceito de triggers, que săo rotinas atreladas a eventos de modificaçăo (INSERT, UPDATE ou DELETE) de uma tabela. Essa técnica fornece um controle maior sobre os dados, pois as regras de negócio escritas na trigger săo respeitadas por todas as aplicaçőes que utilizam o banco. Outra vantagem é que uma eventual modificaçăo nas regras fica disponível automaticamente para todas essas aplicaçőes. Confira a série “PL/SQL no Oracle”, publicada na SQL Magazine ediçőes 2 e 3, para maiores detalhes sobre triggers.
Aspectos de Orientaçăo a Objetos
O padrăo SQL:1999 adicionou várias características da orientaçăo a objetos ŕ SQL, como definiçăo de tipos abstratos de dados, encapsulamento, identidade de objetos, polimorfismo e herança.
Tipos Definidos pelo Usuário
O SQL:1999 permite o uso de tipos definidos pelo usuário, ou UDT (em inglęs, User Defined Data Type). Um tipo UDT pode ser classificado como distinto ou estruturado.
Um UDT distinto é definido a partir de um tipo básico do SQL. Essa categoria de UDT permite adicionar mais significado aos tipos de dados primários. Veja um exemplo:
CREATE TYPE TipoQuantia AS DECIMAL(9,2) FINAL
Após esse comando, TipoQuantia pode ser utilizado para definir o tipo de um campo em qualquer tabela. Note que TipoQuantia é diferente de DECIMAL(9,2). Uma instância de TipoQuantia năo pode receber valores do tipo DECIMAL(9, 2), a năo ser que uma transformaçăo seja feita com o operador CAST.
Um UDT estruturado possui um comportamento e encapsula uma estrutura de dados interna (normalmente, faz-se referęncia a um UDT estruturado simplesmente como UDT). Um UDT pode representar qualquer entidade dentro do contexto da aplicaçăo, como um mapa, um carro ou um empregado. Um UDT encapsula atributos que descrevem a entidade e especifica métodos associados.
Uma característica importante de um UDT é que os seus atributos podem ser, eles próprios, definidos como UDTs. Um UDT pode ser o tipo de uma coluna, um parâmetro em uma rotina ou um tipo de variável. Em resumo, um UDT é bastante semelhante ao conceito de classe, encontrado no paradigma da orientaçăo a objetos.
Para criar um UDT estruturado utiliza-se a seguinte sintaxe:
CREATE TYPE nome
[ UNDER nome-do-supertipo ]
AS ( atrib1 tipo,... )
[ [ NOT ] INSTANTIABLE ]
[ NOT ] FINAL
[ REF opçőes-de-referęncia ]
[ especificaçăo-de-método,... ]
A implementaçăo dos métodos de um UDT estruturado pode ser feita com SQL ou através de uma linguagem de programaçăo. De fato, o método de um UDT é um tipo especial de módulo persistente armazenado.
Cada método deve declarar em sua assinatura o tipo do valor retornado. Os métodos săo invocados como em linguagens de programaçăo OO: através do operador ‘.’. Métodos que possuem uma lista de parâmetros vazia podem ser invocados sem o uso dos paręnteses.
Um UDT pode ser instanciável ou abstrato. Um UDT abstrato permite apenas que seus subtipos sejam instanciados. Por padrăo um UDT é instanciável, possuindo um método construtor automaticamente criado, que deve ser invocado através do operador NEW. Conforme a necessidade, no entanto, vários outros métodos construtores podem ser criados para fornecer diversas possibilidades de inicializaçăo. Cada método construtor possui o mesmo nome do UDT e difere dos demais pela lista de parâmetros. Veja um exemplo na listagem 2.
CREATE TYPE TipoEndereço
(rua CHAR(25),
número INTEGER,
cidade CHAR(20),
unidadeFederativa CHAR(2),
CEP CHAR(10));
CREATE TYPE TipoFoto AS BLOB;
... -- Declaraçőes de outros tipos definidos pelo usuário.
CREATE TYPE TipoImóvel
(proprietário CHAR VARYING(30),
valorBruto TipoQuantia,
quantidadeQuartos INTEGER,
área DECIMAL(5, 2),
localizaçăo TipoEndereço,
fotos TFoto ARRAY[3],
desconto DECIMAL(5, 2),
vendido BOOLEAN,
CONSTRUCTOR TipoImóvel(p CHAR VARYING(30), v TipoQuantia) RETURNS TipoImóvel,
METHOD preço(I Tipoimóvel) RETURNS TipoQuantia);
-- Método construtor que inicializa os atributos proprietário e valorBruto.
-- Exemplo de invocaçăo: SET imóvel = NEW TipoImóvel(‘Joăo da Silva’, 60000)
CREATE CONSTRUCTOR TipoImóvel(p CHAR VARYING(30), v TipoQuantia)
RETURNS TipoImóvel FOR TipoImóvel
BEGIN
SET SELF.proprietário = prop;
SET SELF.valorBruto = valor;
END;
CREATE METHOD preço(I Tipoimóvel) RETURNS TipoQuantia) FOR TipoImóvel
BEGIN
RETURN (I.valorBruto - I.valorBruto * I.desconto);
END;
-- Cria uma tabela a partir do UDT TipoImóvel.
-- A tabela Imóveis possui colunas de mesmo nome e tipo que os atributos de TipoImóvel.
CREATE TABLE Imóveis OF TipoImóvel;
Para cada atributo definido em um UDT o próprio SGBD deve, automaticamente, gerar métodos de seleçăo e modificaçăo equivalentes. O conceito de métodos que manipulam valores de atributos corresponde ŕ implementaçăo do encapsulamento.
Os métodos de leitura retornam o valor do atributo e năo possuem parâmetro. Os métodos de modificaçăo possuem um único parâmetro, com o mesmo tipo do atributo correspondente. Cada método de modificaçăo sempre retorna a instância do UDT que contém o atributo modificado.
Na listagem a seguir vemos assinaturas de métodos automaticamente gerados:
-- Métodos automaticamente gerados para o atributo rua de Tipoendereço.
METHOD rua() RETURNS VARCHAR(25) –- método de seleçăo
METHOD rua(VARCHAR(25)) RETURNS TipoEndereço –- método de modificaçăo
-- Métodos automaticamente gerados para o atributo número de Tipoendereço.
METHOD número() RETURNS INTEGER –- método de seleçăo
METHOD número(INTEGER) RETURNS TipoEndereço –- método de modificaçăo
Para manipular uma tabela definida com UDTs pode-se utilizar os comandos SELECT, INSERT, UPDATE e DELETE. Os paręnteses nos métodos de seleçăo săo de uso opcional. Veja alguns exemplos na listagem 3.
-- Seleciona o proprietário, a rua e o preço dos imóveis cujo
-- valor bruto é maior que RS 1.000,00 e cujo CEP começa com ‘22733’.
SELECT I.proprietário, I.localizaçăo.rua(), I.preço
FROM Imóveis I
WHERE I.valor > 1000 AND I.localizaçăo.CEP() LIKE “22733%”;
-- Seleciona as fotos do imóvel cujo proprietário se chama “Joăo da Silva”.
SELECT TABLE(fotos) FROM Imóveis WHERE proprietário = ‘Joăo da Silva’;
-- Seleciona a quantidade de fotos
SELECT COUNT(fotos) FROM Imóveis;
INSERT INTO Imóveis
VALUES (1, ‘Maria’, TipoQuantia(50000), 2, 50.3, NEW TipoEndereço(‘Rua do Ouvidor’, 500, ‘Rio de Janeiro’, ‘RJ’, ‘22733-000’), FALSE);
-- A cláusula SET a seguir é equivalente a: localizaçăo.rua(‘Rua da Alfândega’)
UPDATE Imóveis SET localizaçăo.rua = ‘Rua da Alfândega’ WHERE id = 12;
As instâncias de qualquer UDT devem ser armazenadas em tabelas para se tornarem persistentes. Feito isso, os comandos INSERT e UPDATE tradicionais podem ser utilizados.
Observe que UDT e ROW săo conceitos semelhantes. A diferença é que um ROW năo é encapsulado, ou seja, qualquer operador pode ser aplicado aos componentes de uma instância desse tipo. Ao contrário, os atributos de um UDT podem permanecer acessíveis somente através de métodos.
Referęncias (REF)
Outra inovaçăo trazida pelo SQL:1999 é o tipo REF (referęncia), que implementa o conceito de identificador de objetos. Um REF é uma referęncia para uma instância de um tipo ROW ou UDT. Através dele, é possível criar variáveis que referenciam colunas de uma linha ou linhas de uma tabela. O objeto referenciado pode ser acessado através dos operadores “->”. O tipo REF é uma alternativa ao tradicional uso de chaves estrangeiras.
A listagem 4 define um UDT denominado TipoEmpregado que possui um atributo do tipo REF. Nesse caso, cada empregado possui uma referęncia para o seu gerente, que é também um empregado. Repare que esse UDT é utilizado para definir uma tabela de empregados. Há também uma tabela de projetos, nos quais os empregados participam. Cada projeto possui um array de no máximo dez empregados participantes.
CREATE TYPE TipoEmpregado AS
(código INTEGER,
nome CHARACTER VARYING(30),
salário DECIMAL(5,2)
gerente REF(TipoEmpregado)) NOT NULL;
-- Os valores para chave primária da tabela Empregados săo automaticamente gerados.
CREATE TABLE Empregados OF TipoEmpregado
VALUES FOR código ARE SYSTEM GENERATED (PRIMARY KEY código);
CREATE TABLE Projetos
(nome CHAR(20),
líder REF(TipoEmpregado),
grupo REF(TipoEmpregado) ARRAY[10]);
-- Seleciona os empregados e seus gerentes para os empregados que ganham mais de R$ 1.200,00
SELECT E.nome, E.gerente->nome FROM Empregados E WHERE E.salário > 1200;
Subtipos, Subtabelas e Herança
No SQL:1999 a herança está presente no contexto de tipos ou objetos. Por exemplo, um UDT pode ser um subtipo de outro UDT. Em essęncia, os subtipos herdam tanto os atributos quanto os métodos definidos nos seus supertipos. Adicionalmente, os subtipos podem conter novos atributos e métodos.
As instâncias de um subtipo podem ser utilizadas em qualquer situaçăo em que instâncias de um supertipo também podem. Outra característica é que métodos do supertipo podem ser redefinidos pelos subtipos, desde que o subtipo mantenha a mesma assinatura.
Para definir um subtipo, utiliza-se a palavra UNDER. Essa cláusula também define subtabelas, mecanismo que permite a implementaçăo de hierarquias de herança de forma transparente.
A listagem 5 define tipos especiais de pessoas: clientes e empregados. Uma tupla da tabela Empregados possui todos os campos da tabela Pessoas, além de possuir mais dois outros campos: salário e departamento.
CREATE TYPE TipoPessoa AS
(código REF(TipoPessoa) NOT NULL,
nome VARCHAR (40),
endereco VARCHAR(50),
dataNascimento DATE),
METHOD idade() RETURNS INTEGER) NOT FINAL;
CREATE METHOD idade() FOR TipoPessoa RETURNS INTEGER
BEGIN
RETURN YEAR(CURRENT_DATE) - YEAR(SELF.dataNascimento);
END;
-- Cria novos tipos a partir de TipoPessoa.
CREATE TYPE TipoEmpregado UNDER TipoPessoa AS
(salário INTEGER, departamento REF(TipoDepartamento));
CREATE TYPE TipoCliente UNDER TipoPessoa AS (telefone CHAR(12));
CREATE TABLE Pessoas OF TipoPessoa
VALUES FOR código ARE SYSTEM GENERATED (PRIMARY KEY código);
CREATE TABLE Empregados OF TipoEmpregado UNDER Pessoas
VALUES FOR código ARE SYSTEM GENERATED (PRIMARY KEY código);
CREATE TABLE Clientes OF TipoCliente UNDER Pessoas
VALUES FOR código ARE SYSTEM GENERATED (PRIMARY KEY código);
-- A consulta a seguir seleciona năo só dados na tabela Pessoas, mas também em suas subtabelas.
SELECT P.nome FROM Pessoas P WHERE P.idade() > 25
-- Restringe a seleçăo ŕ tabela Pessoas.
SELECT P.nome FROM ONLY(Pessoas) P WHERE P.idade() > 25
Para cada registro na subtabela existe um registro correspondente na supertabela. Por outro lado, pode haver registros na supertabela que năo estăo associados a registros em uma subtabela. A manipulaçăo dos registros correspondentes em supertabelas e subtabelas acontece da seguinte forma:
- Seleçăo: uma seleçăo sobre uma subtabela retorna somente registros dessa entidade. Uma seleçăo sobre uma supertabela retorna, além de seus próprios registros, todas as informaçőes de suas subtabelas (pode ser restringido com o uso da cláusula ONLY).
- Inserçăo: uma inserçăo na subtabela automaticamente causa uma inserçăo na supertabela. Uma inserçăo na supertabela năo tem efeito sobre as subtabelas.
- Remoçăo: uma deleçăo na subtabela automaticamente apaga o registro equivalente na supertabela. Uma deleçăo na supertabela apaga todos os registros associados nas subtabelas.
- Atualizaçăo: qualquer alteraçăo em um campo herdado na subtabela automaticamente modifica o campo correspondente na supertabela. Qualquer atualizaçăo de um campo particular ŕ subtabela somente afeta a ela própria.
Embora esse mecanismo de herança entre tabelas permita o mapeamento mais direto de hierarquias de classes da aplicaçăo, algumas questőes importantes ainda permanecem sem resposta. Por exemplo, como representar um cliente que se torna um empregado? A soluçăo seria remover o cliente e inserí-lo como um empregado. Outra questăo seria representar uma pessoa que é empregado e cliente (neste caso seriam criados dois registros na tabela Pessoa, ao invés de somente um como era de se esperar).
Conclusăo
Este artigo passa uma visăo geral das características da última versăo do SQL. Podemos perceber que, até o SQL-92, havia interesse dos fabricantes de SGBDs em manter seus produtos em conformidade com o padrăo. Michel Stonebraker, um dos grandes expoentes da área de pesquisa em bancos de dados objeto-relacionais, costumava se referir ao SQL como a “linguagem de dados intergaláctica” por causa do uso padronizado em todos os SGBDs existentes.
No entanto, diante de um cenário em que năo há mais uma organizaçăo como o NITS para impor a conformidade do padrăo, a universalidade do SQL fica uma tanto ameaçada. O que o futuro reserva para a linguagem, por enquanto, ainda é uma incógnita.

