Na primeira parte deste artigo apresentamos os conceitos básicos e um conjunto de passos que objetivam o entendimento do modelo de negócios que iremos modelar. Definimos os fatos ou métricas (o que estamos avaliando), as dimensőes de negócio (como os fatos serăo analisados), a granularidade das informaçőes (nível mais baixo de detalhe) e sua hierarquia de agrupamento. Para isso, utilizamos um exemplo baseado em um modelo para a área comercial de uma rede de lojas de varejo tomando por base as possíveis necessidades de informaçăo de um gerente comercial.
Nesta segunda parte do artigo vamos modelar um data warehouse ou um data mart que atenda estas necessidades utilizando a modelagem dimensional ou multidimensional. Este tipo de modelagem segue a chamada “escola Ralph Kimball”, introdutor do conceito do “star schema”, um esquema bastante utilizado para a modelagem de bases de dados de suporte ŕ decisăo. Apesar de ser o mais conhecido, o star schema năo é o único. Existem uma série de variaçőes incluindo uma opçăo normalizada deste esquema, o “snowflake”, que também iremos discutir neste artigo.
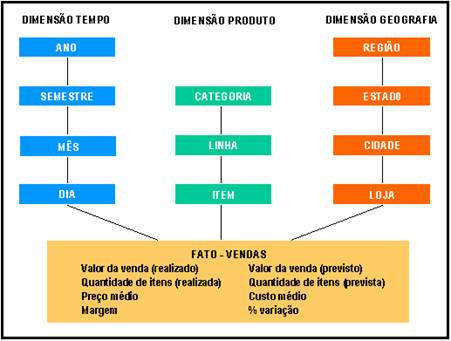
Assim, de posse das informaçőes relevantes para o entendimento das necessidades do negócio, iniciaremos a modelagem da base de dados. A Figura 1 mostra, de forma bem simplificada, a representaçăo das informaçőes que iremos modelar. Estas informaçőes foram definidas durante o primeiro artigo desta série, publicado na ediçăo passada, onde foram apresentadas as necessidades gerenciais de uma empresa que atua na área comercial.
A principal funçăo de uma tabela de dimensăo é reunir os atributos que serăo utilizados para qualificar as consultas e cujos valores serăo utilizados para agrupar e sumariar as métricas (ou fatos). Ou seja, as tabelas dimensăo contęm atributos textuais que funcionam como filtros para as consultas do usuário.
Os atributos de uma dimensăo podem compor uma hierarquia ou serem apenas descritivos. Em nosso exemplo, a dimensăo Produto contém uma hierarquia composta pelos atributos item, linha e categoria, indicando que os itens de produto estăo agrupados em linhas de produto, que por sua vez estăo agrupadas em categorias de produto. Isto será bastante útil, posteriormente, durante a análise de informaçőes pelo usuário. Podemos também incluir uma série de outros atributos descritivos que năo façam, necessariamente, parte desta hierarquia, como o tipo de empacotamento (caixas com 12 unidades etc.), peso e outros que sejam relevantes para o processo de análise. Ralph Kimball sugere que as tabelas de dimensőes possuam o maior número possível de atributos textuais para “enriquecer” o modelo de dados e, por conseqüęncia, as possibilidades de análise de informaçőes. Podem existir, inclusive, várias hierarquias diferentes na mesma dimensăo. Neste caso, porém, nomes de atributos e seus valores devem ser exclusivos para cada uma delas.
Gostaríamos de destacar que devem ser avaliados e escolhidos os atributos que sejam importantes para a análise. O data warehouse/data mart năo deve ser confundindo com um grande cadastro de informaçőes, muitas vezes repleto de dados năo utilizados pelos usuários.
Um atributo muito importante da tabela dimensăo é sua chave. A chave primária de uma tabela dimensăo deve ser sempre um atributo único e definido pelo sistema com um valor genérico, inteiros atribuídos seqüencialmente. Por questőes de desempenho, năo se utilizam chaves compostas por várias partes, nem tampouco chaves concatenadas. A ordem aqui é a da simplicidade, para facilitar o acesso aos grandes volumes de dados armazenados. As chaves serăo utilizadas apenas para possibilitar a junçăo de tabelas entre uma tabela dimensăo e a tabela fato (que será o próximo tópico a ser discutido). Também năo săo utilizados as chaves ou identificadores provenientes de outros sistemas, como código do cliente ou código do produto.
Existem várias razőes para se utilizar chaves genéricas, também chamadas de artificiais, substitutas ou surrogate keys. De acordo com Ralph Kimbal, uma das razőes é que o data warehouse deve se manter isolado das regras operacionais para gerar, atualizar, excluir, reciclar e reutilizar os códigos utilizados nos sistemas transacionais. O data warehouse manterá as informaçőes durante muito tempo (normalmente vários anos) e năo pode ficar vulnerável a problemas de sobreposiçăo de chaves, no caso de aquisiçăo ou consolidaçăo de dados. Outra razăo é o melhor desempenho no acesso ŕs informaçőes. Muitas vezes, o código utilizado em um sistema transacional é um string de caracteres alfanuméricos que apresentam desempenho pior nas operaçőes de acesso ŕ base de dados do que as chaves genéricas, que utilizam o menor inteiro possível.
...
Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.