O otimizador de um Sistema de Gerenciamento de Banco de Dados Relacionais (SGBDR) é responsável por analisar uma consulta SQL e escolher qual a forma mais eficiente de executá-la. A escolha leva em consideraçőes diversas informaçőes internas do banco de dados. Este artigo explica, de forma geral, o funcionamento de um otimizador.
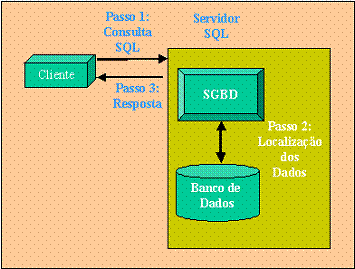
A Figura 1 representa os passos envolvidos na busca de informaçőes. No passo 1, o usuário faz uma requisiçăo de informaçőes através do comando SELECT. Recebido o comando, o SGBDR irá procurar no disco as informaçőes solicitadas (passo 2). Encontrando-as ou năo, o SGBDR sempre retorna uma resposta para o usuário (passo 3). Detalharemos agora o passo 2 deste processo, focando especialmente o otimizador e os mecanismos utilizados por ele. Exemplos práticos serăo demonstrados com os SGBDR InterBase e PostgreSQL.
Em bancos de dados năo relacionais (Cobol, Clipper, Dbase, etc), fica a cargo do programador o processo de otimizaçăo de acesso, ou seja, ele é que determina como as informaçőes devem ser acessadas. Nos SGBDRs, o otimizador leva em conta informaçőes atuais do banco no momento da consulta para determinar o melhor plano de acesso aos dados.
Saiba mais: Cursos de SQL e Banco de Dados
A otimizaçăo em um SGBDR pode ser feita porque em SQL năo se expressa “como” a consulta deve ser executada, mas sim “o que” se pretende recuperar, permitindo que o otimizador escolha o “como” da maneira mais adequada em determinado momento.
O catálogo do sistema (metadado) mantém todas as informaçőes referentes aos dados armazenados no SGBD, como informaçőes sobre tabelas, índices, visőes, procedimentos armazenados, etc. incluindo tanto descriçőes estáticas como dinâmicas. Alguns dos dados estáticos armazenados no catálogo do sistema săo:
Sobre Tabelas:
Sobre Visőes:
Já os dados dinâmicos armazenados no catálogo incluem:
Sobre Tabelas:
Sobre Índices:
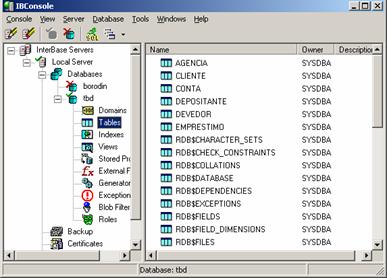
A Figura 2 apresenta o software IBConsole do SGBD InterBase. Nela podemos visualizar as tabelas do catálogo do InterBase juntamente com as demais tabelas criadas pelo usuário. Note que os nomes das tabelas do catálogo nesse SGBDR săo iniciadas por RDB$.
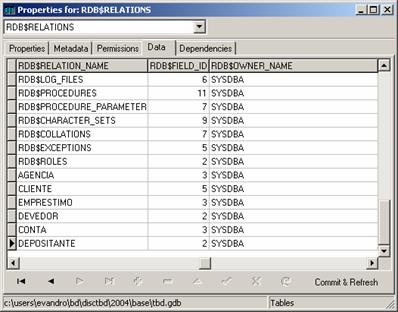
Em destaque na Figura 3 temos a tabela RDB$RELATIONS, responsável por guardar os nomes de todas as tabelas do SGBD (RDB$RELATION_NAME), inclusive as do catálogo do sistema, entre outras informaçőes.
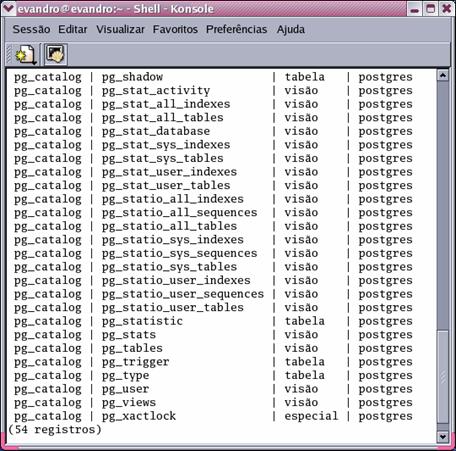
Para quem usa PostgreSQL, o catálogo do sistema pode ser visto digitando no prompt do programa psql o comando \dS. Um exemplo do resultado deste comando pode ser observado na Figura 4. Nas informaçőes obtidas pelo comando, destaca-se, para o contexto deste artigo, a tabela pg_statistic, onde săo armazenadas as estatísticas utilizadas pelo otimizador.
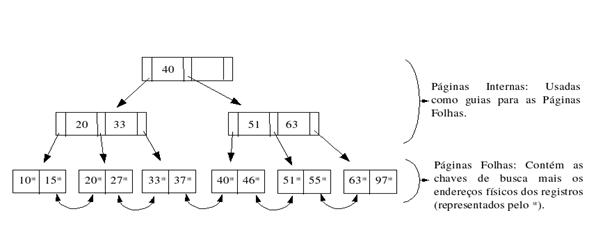
Um dos pontos mais importantes do processo de otimizaçăo de consultas é o uso de índices. Um índice é uma estrutura de dados desenvolvida para agilizar a busca de informaçőes. Quando criamos um índice, o SGBD faz uma cópia do conteúdo dos campos indexados, organizando-os segundo uma estrutura de dados pré-definida, sendo que as estruturas mais utilizadas săo as Árvores B+ e as funçőes Hash.
A estrutura de árvore B+ é a mais utilizada dentre as estruturas de índices, pois mantém sua eficięncia mesmo sob pesada carga de inserçőes e remoçőes de dados. O nome árvore vem da semelhança da estrutura do índice com árvore de cabeça para baixo, onde a raiz está localizada no topo da estrutura e é usada como ponto inicial nos processos de buscas.
Essa estrutura é composta por páginas, ou nós, divididas em dois grupos: páginas internas e folhas. As páginas internas săo usadas para guiar o processo de busca até as páginas folhas, e estas últimas contęm o valor da chave de busca e a localizaçăo da página de dados no disco referente ao registro procurado.
Em cada página da árvore B+ de ordem N, o número de chaves é de no mínimo [INT (N/2)] –1 e no máximo N-1 chaves. De acordo com estas propriedades, uma árvore B+ de ordem N=8 tem no máximo 7 e no mínimo 3 chaves por página.
É importante frisar que na avaliaçăo de custo de uma consulta que use uma árvore B+, considera-se o custo de recuperar uma página do disco e trazę-la para a memória RAM.
A Figura 5 mostra uma árvore B+ com 3 níveis e de ordem N=4. Todas as páginas folhas aparecem no nível 3. Em cada página, as chaves de busca ocorrem em ordem crescente, permitindo utilizar o algoritmo de busca binária [Nota 1] na procura da chave dos registros lidos para a memória.
Além da árvore B+, usa-se também a técnica de hashing (funçăo de dispersăo ou espalhamento) como estrutura de indexaçăo. Esta técnica fornece acesso direto a um registro armazenado através do uso de uma funçăo que aplicada sobre o atributo indexado, fornece um endereço utilizado como base de armazenamento e recuperaçăo de registros em uma tabela conhecida como tabela hashing. O funcionamento da técnica segue alguns passos básicos:
Para um funcionamento ideal da técnica de hashing, é necessário escolher uma funçăo de espalhamento que evite ao máximo o mapeamento das chaves de busca para um mesmo endereço da tabela hashing, o que caracteriza uma colisăo de endereço. Toda colisăo deve ser tratada e o tratamento gera um gasto extra de recurso do SGBD.
Na Figura 6 temos a seguinte situaçăo: a tabela da esquerda representa uma tabela hashing com 13 posiçőes ou buckets, e na tabela da direita temos uma tabela de cliente contendo 5 registros. Considere que cada registro de cliente ocupe uma página em disco (o que normalmente năo ocorre). Note que existem mais buckets na tabela hashing do que registros na tabela cliente. Isto é necessário para se evitar colisőes das chaves, pois, quanto maior for o número de buckets menos provável é a ocorręncia de colisőes.
Cada endereço dos buckets na tabela hashing é calculado pela funçăo hash: endereço_hash = Resto da divisăo(chave/13). Suponha que uma tabela contenha os seguintes valores nas chaves: 100, 200, 300, 400, 500. Aplicando a funçăo hash săo obtidos respectivamente os endereços 9, 5, 1, 10 e 6.
| End.Hash | Chave | End.Página | End.Página | Chave | Nome | Cidade | ||
| 1 | 300 | &1015 | &1011 | 200 | Cliente C | Cidade C | ||
| 2 | &1012 | 400 | Cliente E | Cidade E | ||||
| 3 | &1013 | 100 | Cliente A | Cidade A | ||||
| 4 | &1014 | 500 | Cliente B | Cidade B | ||||
| 5 | 200 | &1011 | &1015 | 300 | Cliente D | Cidade D | ||
| 6 | 500 | &1014 | ||||||
| 7 | ||||||||
| 8 | ||||||||
| 9 | 100 | &1013 | ||||||
| 10 | 400 | &1012 | ||||||
| 11 | ||||||||
| 12 | ||||||||
| 13 | ||||||||
Um outro conceito importante que afeta a decisăo sobre usar ou năo um índice é a seletividade do atributo. A seletividade estima, em média, a porcentagem dos registros que deverăo aparecer na resposta dado um determinado atributo. Ela pode ser calculada pela funçăo:
Seletividade (atributo)= 1 - (registros-na-resposta-filtrada-pelo-atributo / total-de-registros)Quanto mais próximo de 1, melhor é a seletividade de um atributo. Vejamos um exemplo: suponha uma tabela de clientes com 500 clientes. Vamos realizar uma consulta pelo CPF. Sabemos que o CPF năo se repete e que existe um índice sobre este campo. Entăo teremos:
Seletividade(CPF) = 1 – (1/500) = 0,998Isto indica que CPF é um excelente atributo para realizaçăo de consultas através do uso do índice, pois cada valor de CPF descarta quase todos os registros da tabela. Agora vamos realizar uma consulta pelo atributo cidade, sabendo que existem clientes de 110 cidades diferentes e que também existe um índice sobre esse campo.
Seletividade(Cidade) = 1 – (110/500) = 0.78;Esta pesquisa retornará em média mais de 20% dos registros. Isto pode indicar para o otimizador năo utilizar o índice sobre o campo cidade e sim fazer uma varredura total sobre a tabela.
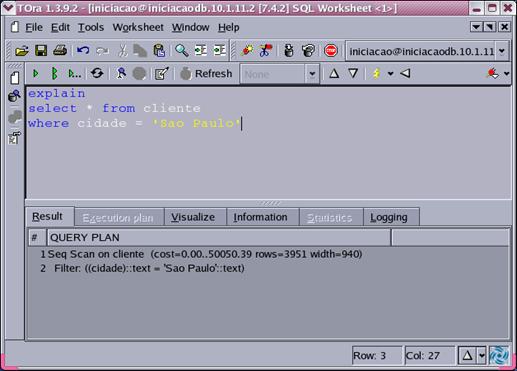
Vamos a um exemplo prático utilizando o PostgreSQL. Para saber como a consulta será realizada, usaremos o comando explain, que indica o plano de acesso adotado pelo SGBD na execuçăo da consulta. Existem as seguintes formas possíveis de acesso aos dados:
Considere a tabela cliente composta pelos campos:
Cliente = {nome_cliente, rua_cli, cidade, obs1, obs2, obs3}A tabela possui um total de 100.000 registros armazenados. Foi criado um índice de árvore B+ sobre o campo cidade, onde existem 95000 registros com valores iguais a “Sao Paulo” e 5000 registros com valores iguais a “Fernandopolis”. Além disto, também existe um índice B+ sobre o campo chave nome_cliente.
Agora considere a seguinte consulta:
select nome_cliente from cliente where cidade = “Sao Paulo”;Uma vez que 95% dos registros possuem o campo cidade igual a “Sao Paulo”, o uso do índice torna-se dispendioso, indicando para o otimizador que é mais econômico fazer uma varredura em toda a tabela cliente (isto pode ser observado pelo detalhamento Seq Scan on cliente da Figura 7) do que utilizar o índice sobre o campo indexado.
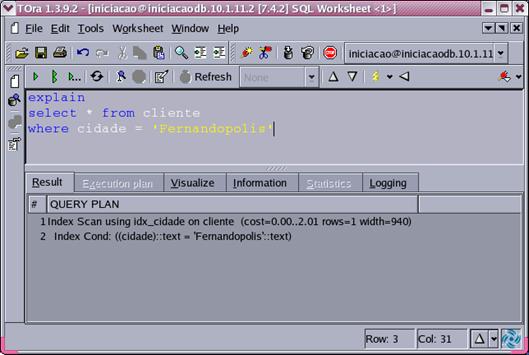
Agora vamos considerar a consulta:
select nome_cliente from cliente where cidade = “Fernandopolis”;Uma vez que somente 5% dos registros possuem o valor “Fernandopolis" para o atributo cidade, é interessante para o otimizador fazer o uso do índice para resolver esta consulta. Observe na Figura 8 que otimizador faz o uso do índice para encontrar os valores dos registros iguais a “Fernandopolis” (explicado pelo detalhamento Index Scan using idx_cidade on cliente, onde idx_cidade é nome do índice).
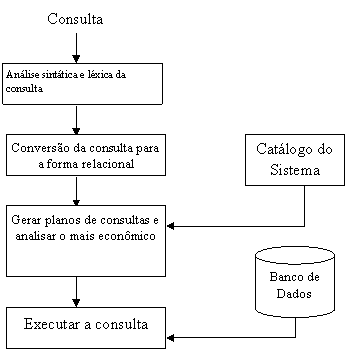
Até aqui vimos alguns dos conceitos utilizados pelo otimizador de um SGBDR. Agora vamos analisar as fases necessárias para a execuçăo de uma consulta. Uma consulta expressa em SQL geralmente pode ser executada de diferentes maneiras. Em um SGBDR, é de responsabilidade do otimizador transformar a consulta definida pelo usuário (select) em uma representaçăo equivalente que possa ser computada mais eficientemente.
Uma consulta passa por quatro etapas, que vai desde a análise sintática dos comandos até sua execuçăo. Mostradas na Figura 9, as quatro etapas săo:
A seguir vamos analisar em detalhes cada uma destas quatro etapas. Para isso, consideraremos que exista uma base de dados armazenando a tabela cliente, definida abaixo.
cliente={Codigo, Nome, Telefone, Rua, Numero, Cidade}Nesta fase é realizada a análise léxica e sintática da consulta (parsing). É aqui que o otimizador valida sintaticamente uma expressăo SQL. Por exemplo, considere a consulta
SELECT c.nome FROM cliente c;O analisador sabe, por exemplo, que após a palavra from obrigatoriamente deve vir um nome de uma tabela (ou visăo) existente no banco de dados. Se alguma das tabelas cliente ou pedido năo existir, ele retornará uma mensagem informando o erro. As consultas validadas nesta fase săo encaminhadas para a fase 2.
O modelo relacional permite que consultas sejam expressas através de operadores sobre as relaçőes. As tabelas săo consideradas conjuntos de registros e, portanto, podem ser operadas pelos operadores de conjuntos como uniăo (?), intersecçăo (?) e produto cartesiano (?). Além disso, podem ser filtradas por operadores de seleçăo (s), ou podem ser projetadas (p) em relaçőes com menos atributos.
Para ilustrar este artigo, vamos usar apenas os operadores que envolvem uma única tabela de cada vez. Consideramos inicialmente o operador de seleçăo, representado por s?(condiçăoC)R (que pode ser lido como “Encontre todos os dados da relaçăo R que atendam a condiçăo C”) . Ele seleciona apenas os registros da relaçăo R que atendem ŕ condiçăo C. Já um operador de projeçăo p?{ai}R (que pode ser lido como “Mostre os valores do atributos AI da relaçăo R) retorna todos os registros da relaçăo R, mas de cada registro recupera apenas os atributos indicados na lista AI de atributos.
Por tratar os algoritmos de manipulaçăo de relaçőes como operaçőes bem definidas, o gerenciador pode usar as propriedades matemáticas desses operadores para escolher as melhores opçőes de consulta. Entăo, neste estágio, a consulta em SQL é convertida internamente para uma forma algébrica equivalente. Por exemplo, a consulta feita em SQL:
SELECT nome, telefone FROM cliente WHERE nome like(‘Pedro%’) AND cidade=‘Săo Carlos’;pode ser expressa algebricamente, por exemplo, como:
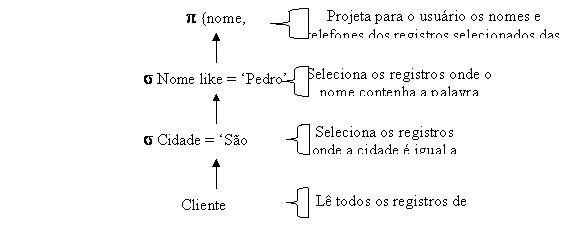
p {nome, telefone} (s nome like(‘Pedro%’) (s cidade=’Săo Carlos’(cliente)))Nessa representaçăo interna, a tabela cliente é lida e filtrada pelo operador de seleçăo s cidade=’Săo Carlos’. O resultado é lido novamente e filtrado pelo operador s nome=’Pedro’. Finalmente, o resultado é projetado (p) em uma relaçăo que tem apenas os atributos nome e telefone. Para facilitar a compreensăo deste plano de consulta por parte do leitor, esta expressăo será convertida em uma representaçăo gráfica denominada árvore de consulta (Figura 10).
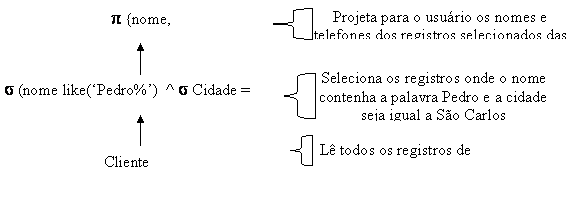
Uma alternativa é expressar a consulta original como:
p {nome, telefone} (s (nome like(‘Pedro%’) ^cidade=’Săo Carlos’) (cliente))Nesta representaçăo interna, a tabela cliente é lida e filtrada pelo operador de seleçăo (s (nome=’Pedro’ ^ cidade=’Săo Carlos’), minimizando a quantidade de leituras e escritas intermediárias necessárias. A árvore de consulta referente a esta alternativa está representada na Figura 11.
Este passo envolve a criaçăo de um conjunto de planos de alternativos expressos em álgebra relacional, considerando aspectos como a existęncia de índices, distribuiçăo de valores de dados (seletividade), agrupamento físico de dados armazenados, etc.
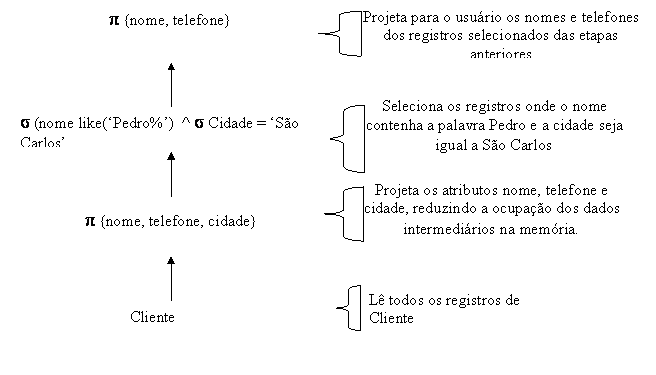
No exemplo anterior, além das duas alternativas já mostradas, outras menos óbvias săo geradas tais como:
p {nome, telefone} (s (nome like(‘Pedro%’) ^ cidade=’Săo Carlos’)
(p {nome, telefone, cidade} cliente))Note que estas variaçőes trazem uma otimizaçăo considerável, pois ŕ medida que a tabela cliente é lida, apenas os atributos que serăo utilizados posteriormente săo passados para os próximos operadores, reduzindo a ocupaçăo dos dados intermediários na memória. Assim, ao analisar o custo de cada maneira de executar a consulta, o otimizador escolherá esta última. A Figura 12 representa a árvore de consulta da alternativa 3.
É neste estágio que a consulta escolhida será executada e o resultado, entregue para o usuário.
Agora que já temos uma visăo geral do funcionamento do otimizador de consulta de um SGBDR, vamos a alguns exemplos práticos. Os exemplos demonstram a escolha ou năo do uso de índices na execuçăo de consultas. A tabela usada é a mesma apresentada no exemplo de seletividade.
Considere a seguinte consulta:
select * from cliente where nome_cliente = "nome1898";As Figuras 13 e 14 apresentam o plano de acesso adotado pelo InterBase 6.5 e PostgreSQL 7.4.2, respectivamente. É importante saber que ambos os SGBDs estăo com as estatísticas atualizadas.
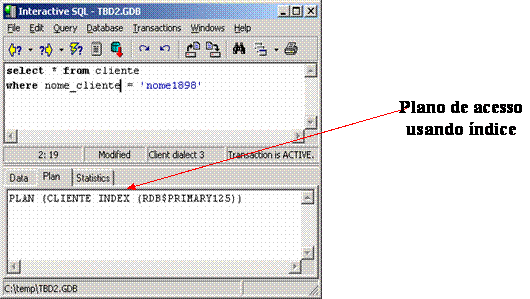
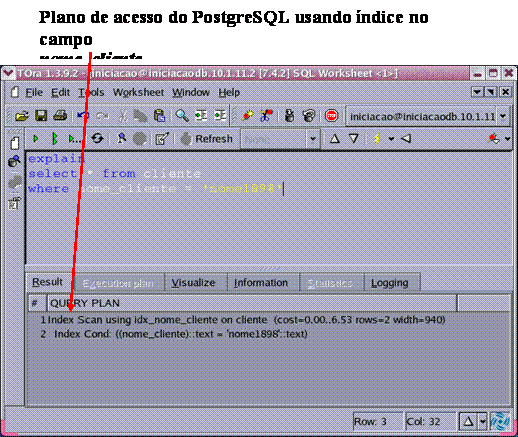
Comparando: Nota-se pelo resultado das Figuras 13 e 14 que foram utilizados os índices existentes sobre o campo usado na comparaçăo. Nesta situaçăo ambos otimizadores tiveram desempenho semelhante.
Agora um segundo exemplo onde procuramos os clientes que residem na cidade de Săo Paulo.
Considere a seguinte consulta:
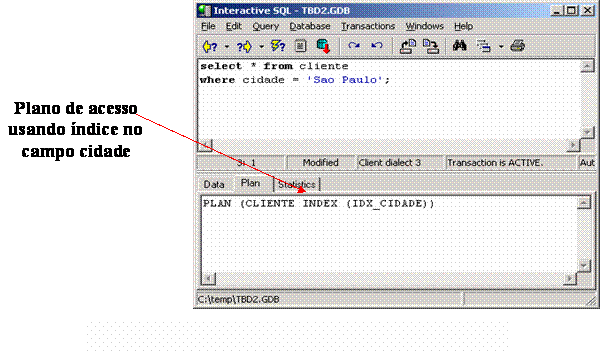
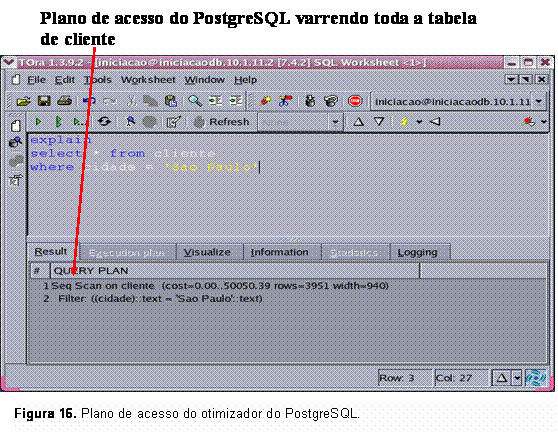
select * from cliente where cidade = "Sao Paulo";É importante salientar que o campo cidade possui uma seletividade muito baixa, pois 95% dos registros possuem valor igual a ‘Săo Paulo’. As Figuras 15 e 16 apresentam o plano de acesso adotado pelo InterBase e PostgreSQL, respectivamente.
Comparando: Nesta consulta, o otimizador do PostgreSQL (observado na Figura 16), após fazer a análise, constatou que o custo de fazer uma varredura em toda a tabela de clientes é mais econômico que utilizar o índice existente sobre o campo cidade, tendo em vista que existe muita repetiçăo do valor de cidade igual a ‘Săo Paulo’. Já o otimizador do InterBase (observado na Figura 15) escolheu o uso dos índices mesmo tendo a informaçăo que a seletividade do índice cidade é baixa, devido ŕ repetiçăo do valor ‘Săo Paulo’. De acordo com estes dados, nota-se, para esta situaçăo, que o otimizador do PostgreSQL obteve melhor desempenho que o otimizador do InterBase.
Este artigo apresentou os principais elementos envolvidos na execuçăo de uma consulta realizada por um SGBDR. As sequęncias adotadas para representaçăo no texto năo săo obrigatoriamente as mesmas para todos os SGBDs. Cada fabricante desenvolve seu otimizador da maneira mais conveniente, e este é um dos maiores diferenciais entre os diversos gerenciadores existentes: um gerenciador será tăo mais eficiente quanto melhores e mais precisas forem as estratégias de busca descobertas e selecionadas por seu otimizador.
É importante salientar que em uma consulta, o principal fator de desempenho é o uso ou năo de índices. Como foi mostrado, os índices melhoram sensivelmente a velocidade em que os dados săo encontrados. Mas este benefício possui o custo da manutençăo destes índices, o que torna inviável sua criaçăo em excesso. A dica sugerida é que o DBA analise os índices existentes e verifique se estăo sendo utilizados pelas consultas. Para os índices que năo estiverem em uso, atualize suas estatísticas. Se ainda continuarem em desuso, converse com os programadores sobre a possibilidade da destruiçăo destes índices. Da mesma forma, verifique a possibilidade de criaçăo de índices para os atributos de busca nas sentenças mais usadas.
Veja os resultado dos nossos alunos
Conquistas reais de quem está aplicando o método







Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.