


n style="mso-spacerun: yes">
Clique aqui para ler todos os artigos desta ediçăo
Otimizando um servidor Linux para banco de dados - Parte II
por Carlos Eduardo Smanioto
Leitura obrigatória
Para uma melhor compreensăo desse artigo, é aconselhada a leitura da primeira parte publicada na ediçăo 12 da SQL Magazine com o título “Otimizando um servidor Linux para banco de dados”.
Nessa segunda parte do artigo sobre tuning de servidores Linux para banco de dados estaremos focando a otimizaçăo do Kernel do Linux. Veremos também a teoria relacionada com as configuraçőes descritas a fim de dar ao leitor plena conscięncia do que estaremos fazendo. Abordaremos aqui conceitos que năo se aplicam somente a banco de dados, mas também a outros softwares utilizados em servidores de rede, como o SAMBA, que permite montar no Linux um servidor de arquivos e domínio, substituindo Windows 2000 Server como servidor PDC (Primary Domain Controller).
Uma breve introduçăo
Diferente do Windows onde temos poucas opçőes de configuraçăo e otimizaçăo do sistema operacional em relaçăo a um servidor de BD, no Unix (e seus derivados) as configuraçőes do sistema operacional estăo diretamente relacionadas com a performance do SGBD. Nesse artigo, apresentarei as principais modificaçőes no kernel para alcançar o alto desempenho. Antes, no entanto, falaremos de um assunto que foi citado superficialmente na primeira parte do artigo: RAID.
RAIDs
RAID é a sigla para Redundant Array of Inexpensive/Independent Disks - "Matriz Redundante de Discos de Baixo Custo/Independentes". O objetivo do RAID é criar um sistema contra falhas de HD através do armazenamento redundante dos dados em vários discos, aumentando também a performance de gravaçăo e recuperaçăo dos dados.
Podemos criar RAIDs via hardware ou software. É possível criar uma unidade RAID com apenas um HD, no entanto isso năo faria sentido, visto que năo haveria redundância, e portanto năo traria qualquer tipo de vantagem. Consideramos entăo que para se criar um RAID precisamos de no mínimo dois HDs. Uma unidade RAID é composta por “n” HDs, sendo que o sistema operacional năo diferencia os HDs que a compőe, enxergando-os como uma única unidade RAID. Lembram-se da primeira parte do artigo, quando citei o LVM? O RAID tem o mesmo conceito, aliás, o RAID 0 (Striping) foi explicado no LVM. Através do RAID, além de garantirmos a disponibilidade dos dados em caso de falha em algum dos discos, também equilibramos o acesso ŕs informaçőes, diminuindo os gargalos de I/O, aumentando assim o desempenho de acesso ao disco pelo SGBD.
Níveis de RAID
A tecnologia RAID possui diversos níveis. Cada nível representa uma combinaçăo do uso dos discos no que se refere ao espelhamento dos dados, fracionamento (striping), detecçăo de falhas, etc. Estaremos comentando nesse artigo os 6 níveis básicos de RAID.
RAID 0
Conhecido como striping ou fracionamento. Nele os dados săo divididos em pequenos segmentos e distribuídos entre os discos (ver Figura 1). Este nível năo oferece tolerância a falhas, mas é o mais rápido de todos os níveis de RAID. O RAID 0 é usado apenas para ganhar performance, uma vez que a distribuiçăo dos dados entre os discos proporciona grande velocidade na gravaçăo e leitura de informaçőes. Quanto mais discos houver, mais velocidade é obtida. Apesar da limitaçăo do hardware controlador de disco, de maneira geral é possível formar um RAID 0 com até quatro discos. Segundo o site www.mcpdomain.com/artigos/raidsystem.asp, o aumento do desempenho é de 98% com dois HDs, 180% usando tręs HDs, e 250% usando quatro HDs. No entanto, năo recomendo usar um RAID 0 sem técnicas de backup e medidas que permitam proteger a informaçăo contra acidentes, pois ele năo oferece tolerância contra falhas.
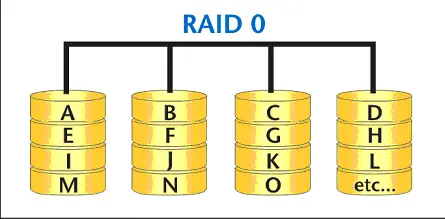
Figura 1. RAID 0.
RAID 1
Também conhecido como mirroring (espelhamento). Nele, cada bit gravado no primeiro HD é gravado no segundo HD, fazendo com que o segundo disco seja um espelho do primeiro. Assim, em caso de crash do primeiro HD, os dados estariam íntegros no segundo. Na Figura 2 vemos oito HDs espelhados em pares. A gravaçăo dos dados no RAID 1 é mais lenta, mas a leitura é bastante rápida, pois o controlador RAID terá duas fontes de pesquisa para localizar o dado requisitado. Esse é um dos níveis de RAID mais caros, pois para cada gigabyte de informaçăo armazenada, é necessário um outro gigabyte para espelhamento.
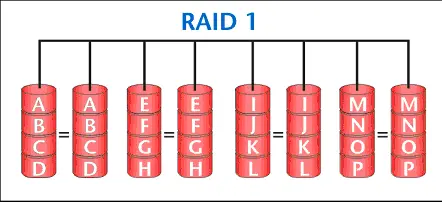
Figura 2. RAID 1.
RAID 2 (ECC)
Este tipo de RAID utiliza discos separados para armazenar os dados e as informaçőes de redundância (paridade) (ver Figura 3). As informaçőes de paridade săo geradas a nível de bit, utilizando um processo conhecido por Hamming Error Correcting Codes (ECC), que permite tanto identificar como corrigir possíveis erros nas informaçőes, surgidos depois que as mesmas foram gravadas. Vários fatores fazem com que esse nível de RAID năo seja utilizado atualmente, entre eles está o alto custo devido ao grande número de HDs necessários, e o fato de que os HDs atuais já oferecem correçőes de erro baseadas em ECC no seu próprio hardware. A distribuiçăo dos dados a nível de bits faz com que a performance das leituras randômicas de dados seja terrível.
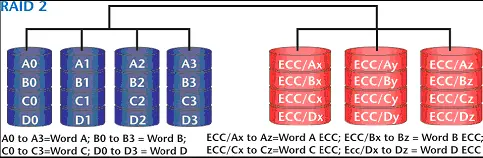
Figura 3. RAID 2.
RAID 3
O RAID 3 utiliza a técnica de striping a nível de byte juntamente com um HD dedicado a armazenar as informaçőes de paridade calculada através de um algoritmo de XOR (“OU exclusivo”) (ver Figura 4). Isto torna possível a reconstruçăo tanto dos dados armazenados como da própria informaçăo de paridade, no caso de falha em qualquer um dos discos envolvidos. O disco de paridade acaba se tornando um gargalo de performance, principalmente durante escritas randômicas de dados, pois para qualquer informaçăo enviada para o array, o disco de paridade tem que ser acessado. Além disso, a ótima performance depende da habilidade de acessar os dados nos HDs sincronizadamente (técnica chamada de “spindle synchronization”), um recurso năo muito comum na maioria dos HDs. Logicamente, este modelo exige no mínimo 3 Hds.
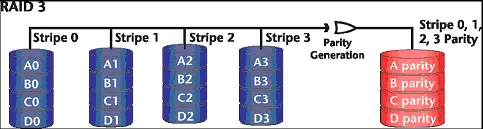
Figura 4. RAID 3.
RAID 4
O RAID 4 segue o mesmo conceito do RAID 3 (ver Figura 5), no entanto oferece uma performance um pouco melhor por fazer uso de block striping ao invés de byte striping. Mas ainda assim o disco dedicado a paridade continua sendo um gargalo de performance.
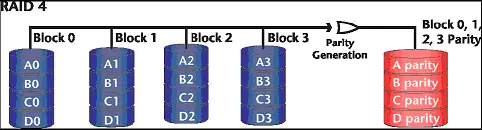
Figura 5. RAID 4.
RAID 5
O RAID 5 é semelhante ao RAID 4, mas ao invés de utilizar um HD dedicado para as informaçőes de paridade, ele as distribui nos mesmos HDs envolvidos para a gravaçăo/leitura dos dados (ver Figura 6). Isso faz com que a performance, mesmo em pequenas operaçőes de I/O, năo seja degradada. A tolerância a falhas é obtida certificando-se que as informaçőes de paridade năo sejam gravadas no mesmo HD contendo os dados a que elas se referem. Devido ao balanceamento de performance, custo e tolerância a falhas, o RAID 5 é o nível mais utilizado em servidores de bancos de dados e processamento de transaçőes. Este nível é utilizado com tręs ou mais HDs.
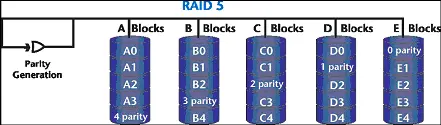
Figura 6. RAID 5.
RAID 10(0+1)
O RAID 10 é uma mistura do RAID 1 com o RAID 0, por isso 10(1 e 0). Um par de HDs é utilizado para dados, usando striping (performance), e o outro par de HDs é utilizado para espelhar (mirroring) o primeiro par (ver Figura 7). Tais características fazem do RAID 0 + 1 o mais rápido e seguro, porém o mais caro de ser implantado, pois para cada par de striping é necessário um par de HDs para fazer mirror.
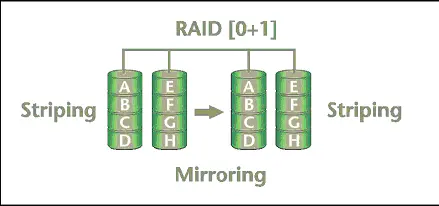
Figura 7. RAID 10(0+1).
Existem ainda outros níveis de RAID, entre eles:
· RAID 6: igual ao RAID 5, porém com dupla paridade.
· RAID 7 (altíssima performance): os dados năo săo gravados diretamente para o disco, sendo controlados e cacheados de forma independente, economizando I/O.
· RAID 53 (alta performance): um RAID 3 com cinco HDs.
O sistema operacional System V e o Linux
O System V é um Unix desenvolvido pela AT&T's Bell Laboratories, que possui elementos que servem de base para muitos outros sistemas operacionais da série Unix e semelhantes. Várias tentativas foram feitas visando unificar as versőes do Unix de Berkeley (BSD) e da AT&T (System V), além das inúmeras outras implementaçőes oferecidas pelo mercado.


Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.