Será desenvolvida uma comparaçăo de desempenho entre as linguagens para a melhor escolha num ambiente de produçăo. As linguagens tratadas no estudo săo C, PL/Perl, PL/pgSQL e SQL. Elas podem ser usadas em ambientes Linux, Windows e até mesmo outras plataformas. A teoria computacional envolvida em índices reversos, bem como a motivaçăo para sua utilizaçăo, é explorada no artigo. Ao final, serăo realizados testes de desempenho indicando quais as melhores opçőes de linguagens quando precisamos realizar consultas, inserçőes e atualizaçőes utilizando índices inversos em bases com grandes volumes de dados.
Os índices reversos, extremamente úteis nos casos de busca por padrőes no final do texto em bancos de dados relacionais (ver Nota 1), nem sempre consistem de soluçőes out-of-box. Desde sua versăo 8i, o Oracle implementa índices reversos nativamente. No caso do SGBD PostgreSQL, precisamos implementá-lo manualmente. Este será o tema do estudo a seguir: uma proposiçăo dos índices reversos no PostgreSQL equivalente ao existente no Oracle.
Nota 1. Índice Reverso
Um índice reverso, comparado a um índice convencional, inverte os bytes da chave a ser indexada. Ele é particularmente interessante no caso de uma coluna de tabela conter valores de texto que comumente apresentam um longo prefixo.
Por exemplo, em uma tabela destinada a armazenar Ordens de Serviço, a coluna chave pode possuir uma forma padronizada com 12 caracteres. O primeiro documento do ano 2008 é indicado com “OS-200800001”, o segundo com “OS-200800002”, e assim por diante. Até a tabela atingir alguns milhőes de registros, os primeiros sete caracteres serăo redundantes e năo trarăo muita contribuiçăo ŕs buscas indexadas. Um índice reverso armazenaria estes códigos na ordem inversa, isto é, como “100008002-SO”, “200008002-SO”, “300008002-SO”, e assim por diante. Com isso, ele permite que o último caractere da chave, mais altamente variável, espalhe os valores entre as estruturas de dados do índice. Tal procedimento aumenta consideravelmente o desempenho no momento da busca.
Os índices reversos permitem acelerar as buscas SQL do tipo “WHERE coluna LIKE "%texto"”. Neste caso, por padrăo o SGBD realiza uma varredura seqüencial (também conhecida como “sequential scan” – ver Nota DevMan 1) na tabela em questăo, o que compromete seriamente o desempenho de uma aplicaçăo. Para resolver isso, podemos emular um índice reverso através de uma funçăo de inversăo de textos (ou strings) aliada a um índice sobre esta mesma funçăo.
1. Varredura de Tabela Seqüencial – Sequential Table Scan.
Uma varredura de tabela seqüencial, ou apenas varredura seqüencial, é um processo que lę todas as linhas em todas as páginas de uma tabela que estăo armazenadas em um banco de dados.
Varreduras seqüenciais surgem no plano curto e longo como correlation_name <seq>, onde correlation_name é o nome da correlaçăo especificado na cláusula FROM, ou entăo o nome da tabela caso nenhum nome tenha sido especificado.
Este tipo de varredura é usado quando o banco de dados “acredita” que a maioria das páginas da tabela possui uma linha que atinja ŕs condiçőes de busca definida na query ou entăo quando um índex adequado năo está definido.
Apesar de a varredura seqüencial poder ler mais páginas que varredura por índice, a carga de I/O no disco pode ser substancialmente menor, pois as páginas săo lidas a partir de blocos contínuos provenientes do disco (esta melhoria de desempenho só é melhor se o arquivo com o banco de dados năo está fragmentado no disco). I/O seqüencial minimiza a sobrecarga devido ŕ latęncia do movimento rotacional do cabeçote do disco. Para tabelas com grande volume de dados, varredura seqüencial também lę grupos de muitas páginas ao mesmo tempo. Isto reduz ainda mais o custo de varreduras seqüenciais em relaçăo ŕ varredura por índices.
Apesar de varreduras seqüenciais poderem levar menos tempo que varredura por índice que encontra muitas linhas, elas também podem explorar a cache de forma tăo eficiente quanto a varredura por índice caso a varredura seja executada muitas vezes. Visto que varreduras por índice acessam provavelmente uma quantidade menor de páginas, é mais provável que as páginas estejam disponíveis em cache, o que resultará em um acesso mais rápido. Por causa disto, é muito melhor ter uma varredura por índice para acessos de tabelas que săo repetidos, tais como direito de um JOIN recursivo já armazenado em cache.
No artigo “Garantindo desempenho com o operador LIKE”, publicado na ediçăo 52 da SQL Magazine, foi proposta a funçăo reverse() em linguagem PL/Perl com o objetivo de inverter uma cadeia de caracteres (string) especificada.
Tal implementaçăo, apesar de completamente funcional, tinha o principal defeito de ser lenta, penalizando assim gravemente o desempenho durante as gravaçőes (INSERT e UPDATE) na tabela. Além disso, a cada atualizaçăo é necessária uma chamada a essa funçăo para que o índice funcional seja devidamente atualizado. Isso é observado particularmente durante a criaçăo do índice.
Sempre soubemos que códigos binários escritos na linguagem C tendem a ser muito mais rápidos do que outras linguagens, especialmente se estas últimas forem interpretadas (como Perl ou Python) ou pseudo-interpretadas (como Java). Na seçăo seguinte, construiremos uma funçăo em linguagem C para ser utilizada no PostgreSQL para podermos efetuar os estudos comparativos.
Por que enfrentar o terrível e cruel mundo da linguagem C para escrever uma simples funçăo procedural no PostgreSQL, quando podemos fazer a mesma coisa em uma linguagem bem mais simples e segura como a PL/pgSQL?
Existem diversas respostas para essa questăo:
Năo espere um ganho significativo de velocidade para as requisiçőes SQL de seleçăo (SELECT) utilizando a nova funçăo. Por outro lado, as operaçőes de gravaçăo (sobretudo INSERT e UPDATE) podem ser fortemente auxiliadas. Ainda assim, isso ainda năo se tornará evidente para uma operaçăo unitária, mas durante operaçőes de escrita em massa, como carga massiva de dados, alteraçőes de muitas linhas ao mesmo tempo ou pela simples criaçăo do índice funcional.
Portanto, neste último caso a opçăo de se reescrever em linguagem C torna-se altamente aconselhável.
A extensibilidade do PostgreSQL apóia-se sobre seus mecanismos de carregamento dinâmico de bibliotecas do sistema operacional. Tratam-se de Dynamic Link Libraries (DLLs) no Windows e Shared Objects (SOs) no Linux e UNIX. A interface de programaçăo é relativamente simples, bastando apenas conhecer determinados pontos-chaves.
No presente estudo utilizaremos o PostgreSQL versăo 8.3 hospedado no sistema operacional Debian GNU/Linux. Para dar andamento, baixe o código-fonte do PostgreSQL através do endereço FTP http://www.postgresql.org/ftp/source/v8.3.3/.
Após fazer download do arquivo BZ2, extraia os diretórios e arquivos do código-fonte para o diretório /usr/src e conceda as devidas permissőes ao seu usuário conforme exibido na Listagem 1. Note que isso precisa ser feito com o super-usuário (root).
$ su
# tar xvjf postgresql-8.3.3.tar.bz2 –C /usr/src
# chown –R postgres: /usr/src/postgresql/src
Em seguida, crie um diretório para o projeto e utilize-o para armazenar os arquivos a serem criados na seqüęncia, conforme ilustrado na Listagem 2.
$ cd /usr/src/postgresql/src
$ mkdir reverse
$ cd reverse
$ touch Makefile reverse.sql.in unreverse.sql reverse.c
Os arquivos recém-criados devem ser modificados conforme as listagens a seguir com o editor de texto de sua preferęncia. O primeiro deles, o Makefile, tem a funçăo de definir as regras para a compilaçăo e linkagem da biblioteca SO referente ao módulo externo a ser criado, além da geraçăo automática de arquivos de script SQL para instalaçăo e desinstalaçăo da funçăo no banco de dados. A Listagem 3 traz o conteúdo do Makefile.
MODULES = reverse
DATA_built = reverse.sql
DATA = unreverse.sql
PGXS := $(shell pg_config pgxs)
include $(PGXS)
O segundo arquivo, reverse.sql.in, serve apenas de modelo (ou template) para a criaçăo do arquivo reverse.sql que conterá o script final para a instalaçăo do módulo num banco de dados do PostgreSQL. Esse script é gerado a partir do template com a substituiçăo da string MODULE_PATHNAME pelo caminho completo do arquivo objeto compilado. O conteúdo do arquivo reverse.sql.in está ilustrado na Listagem 4.
SET search_path = public;
CREATE OR REPLACE FUNCTION reverse(varchar)
RETURNS varchar AS "MODULE_PATHNAME", "reverse"
LANGUAGE "C" IMMUTABLE STRICT;
Note que o script reverse.sql poderá apenas ser executado por um usuário do PostgreSQL com direitos de administrador, pois funçőes C săo consideradas năo-confiáveis e sendo assim săo de responsabilidade de um administrador.
O arquivo referente ao script de desinstalaçăo do módulo, unreverse.sql, é o mais simples de todos. Ele apenas exclui a funçăo reverse() do banco de dados e tem o conteúdo exibido na Listagem 5.
SET search_path = public;
DROP FUNCTION reverse(varchar);
Lembre-se de que uma funçăo pode apenas ser excluída do banco de dados caso ela năo esteja associada a nenhum outro objeto, como um índice funcional ou constraints de uma tabela.
Finalmente, vamos ao código-fonte em linguagem C da funçăo reverse(). A Listagem 6 ilustra o conteúdo do arquivo reverse.c.
// cabeçalhos necessários
#include "pg_config.h"
#include "postgres.h"
#include "fmgr.h"
#include "mb/pg_wchar.h"
#include "utils/elog.h"
// definiçăo da assinatura mágica
#ifdef PG_MODULE_MAGIC
PG_MODULE_MAGIC;
#endif
// definiçăo da funçăo reverse()
Datum reverse(PG_FUNCTION_ARGS);
#ifndef SET_VARSIZE
#define SET_VARSIZE(n,s) VARATT_SIZEP(n) = s;
#endif
// corpo da funçăo reverse()
PG_FUNCTION_INFO_V1(reverse);
Datum reverse(PG_FUNCTION_ARGS)
{
int len, pos = 0;
VarChar *str_out, *str_in;
// obter endereço do argumento
str_in = PG_GETARG_VARCHAR_P_COPY(0);
// calcular o tamanho da string em bytes
len = (int) (VARSIZE(str_in) VARHDRSZ);
// criar uma string vazia de mesmo tamanho
str_out = (VarChar *) palloc(VARSIZE(str_in));
// a resultante terá o mesmo comprimento
SET_VARSIZE(str_out, VARSIZE(str_in));
// verificar se a codificaçăo da string no
// argumento concorda com a codificaçăo do BD
pg_verifymbstr(VARDATA(str_in), len, false);
// copiar a string do modo inverso
while (pos < len)
{
int charlen = pg_mblen(VARDATA(str_in) + pos);
int i = charlen;
while (i--)
*(VARDATA(str_out) + len - charlen + i - pos) = *(VARDATA(str_in) + i + pos);
pos = pos + charlen;
}
PG_FREE_IF_COPY(str_in, 0);
// retorna a cópia (resultante)
PG_RETURN_VARCHAR_P(str_out);
}
Para maiores detalhes sobre a implementaçăo da funçăo reverse() e para conhecer outras funcionalidades ao se utilizar a linguagem C, recomenda-se a leitura da documentaçăo “Funçőes em Linguagem C” (http://developer.postgresql.org/pgdocs/postgres/xfunc-c.html). A leitura dos arquivos de cabeçalho (extensőes .h) utilizados no código-fonte também permite uma melhor compreensăo suplementar sobre as estruturas de dados utilizadas.
A seguir, iremos dar início ŕ construçăo do módulo no PostgreSQL através do utilitário make (por isso é necessária a criaçăo do arquivo Makefile). Execute os comandos exibidos na Listagem 7.
$ cd /usr/src/postgresql/src
$ make
Note que nesta última operaçăo o compilador C da GNU (gcc) é invocado com inúmeros argumentos e ao final do processo um arquivo com a extensăo .SO é gerado. Este é o produto final: o módulo do PostgreSQL contendo o binário para a execuçăo da funçăo reverse().
Resta ainda copiar estes arquivos criados automaticamente para o diretório de instalaçăo do PostgreSQL. Para fazer isso, simplesmente execute os comandos ilustrados na Listagem 8. Note que é preciso ter direitos de super-usuário para copiar os arquivos para os locais definitivos.
$ cd /usr/src/postgresql/src
$ su
# make install
Veja que esta última operaçăo năo é obrigatória, mas apenas recomendada. Podemos, durante a instalaçăo de um módulo no PostgreSQL, definir o caminho absoluto onde o arquivo .SO se encontra no sistema de arquivos, desde que o usuário postgres (geralmente o dono do serviço no Linux) tenha direitos de acesso a este local alternativo. Sendo assim, basta indicar no script de instalaçăo reverse.sql a localizaçăo da biblioteca reverse.so.
Para testar o funcionamento da biblioteca, crie um banco de dados no PostgreSQL através da instruçăo CREATE DATABASE e em seguida execute o script de instalaçăo reverse.sql nele. As respectivas instruçőes estăo contidas na Listagem 9. Observe que estes comandos precisam ser executados pelo super-usuário do banco de dados, normalmente chamado postgres no sistema operacional.
$ su – postgres
$ createdb sqlmag8
$ psql sqlmag8 –i reverse.sql
Feito isso, inicie a ferramenta PgAdmin III e selecione o banco de dados recém-criado. Abra a janela Query Analyzer e execute a instruçăo SQL contida na Listagem 10.
SELECT reverse("Funçőes em C săo mais rápidas");
----
>> sadipár siam oăs C me seőçnuF
Se quiséssemos desinstalar o módulo do banco de dados, bastaria executar o script unreverse.sql, tal como exemplificado na Listagem 11. Observe que estes comandos precisam ser executados pelo super-usuário do banco de dados, normalmente chamado postgres no sistema operacional.
$ su – postgres
$ psql sqlmag8 –i unreverse.sql
Pronto! Conseguimos atingir o primeiro objetivo do estudo: criar uma funçăo procedural em linguagem C para ser utilizada como uma extensăo do PostgreSQL. Resta ainda efetuar os testes comparativos de desempenho com outras linguagens, especialmente as interpretadas. Este será o tema da seçăo a seguir.
Para os testes comparativos, criaremos cinco funçőes idęnticas ŕ reverse(), mas que sigam diferentes abordagens utilizando as seguintes linguagens procedurais no PostgreSQL: PL/Perl, PL/Python, PL/pgSQL e SQL.
Antes de qualquer coisa, devemos habilitar a criaçăo de funçőes com essas linguagens no banco de dados. Isso é feito através da instruçăo CREATE LANGUAGE e somente pode ser executado pelo super-usuário do banco de dados, pois algumas dessas linguagens săo consideradas năo-confiáveis (untrusted). A Listagem 12 contém os comandos para as instalaçőes, respectivas, das linguagens PL/pgSQL, PL/Perl e PL/Python.
CREATE LANGUAGE plpgsql;
CREATE LANGUAGE plperl;
CREATE LANGUAGE plpython;
No PgAdmin III, clique com o botăo direito no banco de dados, e em seguida na opçăo Refresh. Abra o nó Linguagens e confira se as linguagens foram habilitadas com sucesso.
Em seguida, vamos criar as funçőes para os testes. Na primeira abordagem, utilizaremos a linguagem procedural PL/Perl, que possui a sintaxe da linguagem interpretada Perl, muito difundida durante o surgimento das aplicaçőes para a Internet aliada ŕ tecnologia CGI (Common Gateway Interface). Veja na Listagem 13 a instruçăo SQL para a criaçăo dessa nova funçăo, a ser chamada de reverse2(). Repare como o corpo da funçăo, ou seja, o código-fonte essencial fica extremamente enxuto na linguagem Perl.
Veja na documentaçăo oficial do PostgreSQL maiores detalhes em como escrever funçőes usando a PL/Perl.
CREATE OR REPLACE FUNCTION reverse2(varchar)
RETURNS varchar AS $$
return reverse $_[0];
$$ LANGUAGE plperl IMMUTABLE STRICT;
Após isso, partiremos para outra linguagem interpretada muito conhecida por usuários Linux: o Python. A linguagem procedural correspondente no PostgreSQL é a PL/Python. Execute as instruçőes contidas na Listagem 14 para a criaçăo da funçăo reverse3() em linguagem PL/Python.
Tal como em Perl, a funçăo reverse() escrita em Python fica ligeiramente simples. Veja na documentaçăo oficial do PostgreSQL maiores detalhes em como escrever funçőes usando a PL/Python.
CREATE OR REPLACE FUNCTION reverse3(varchar)
RETURNS varchar AS $$
return args[0][::-1];
$$ LANGUAGE plpython IMMUTABLE STRICT;
A seguir, escolheremos a linguagem procedural default do PostgreSQL: a PL/pgSQL (equivalente ŕ PL/SQL do Oracle ou ŕ TransactSQL no SQL Server). Desta vez seguiremos duas abordagens distintas com essa mesma linguagem. A primeira abordagem, a funçăo reverse4(), é apresentada na Listagem 15 e trata-se de um laço de repetiçăo FOR invertido para a montagem do texto de retorno.
CREATE OR REPLACE FUNCTION reverse4(varchar)
RETURNS varchar AS $$
DECLARE
len int := length($1);
ret varchar := "";
BEGIN
FOR ii IN REVERSE len..1 LOOP
ret = ret || substring($1 FOR 1 FROM ii);
END LOOP;
RETURN ret;
END
$$ LANGUAGE plpgsql IMMUTABLE STRICT;
Já na segunda versăo, chamada de reverse5(), o conceito de recursividade é explorado na linguagem PL/pgSQL. A Listagem 16 traz o os comandos para a criaçăo desta outra funçăo. Note que, apesar de parecer mais enxuta e econômica que a reverse4(), a funçăo reverse5() traz consigo a complexidade de um procedimento recursivo. Veja na documentaçăo oficial do PostgreSQL maiores detalhes em como escrever funçőes usando a PL/pgSQL.
CREATE OR REPLACE FUNCTION reverse5(varchar)
RETURNS varchar AS $$
BEGIN
IF length($1) > 1 THEN
RETURN reverse5(substr($1,2)) || substr($1,1,1);
ELSE
RETURN $1;
END IF;
END
$$ LANGUAGE plpgsql IMMUTABLE STRICT;
Para finalizar, escreveremos uma última funçăo utilizando a simples linguagem SQL. Através do conceito de manipulaçăo de arrays no PostgreSQL e com a ajuda das respectivas funçőes de suporte, criaremos a funçăo reverse6(). O código-fonte desta última está ilustrado na Listagem 17. Veja na da documentaçăo oficial do PostgreSQL maiores detalhes em como escrever funçőes usando a SQL.
CREATE OR REPLACE FUNCTION reverse6(varchar)
RETURNS varchar AS $$
SELECT array_to_string(array(
SELECT substring($1, s.i, 1)
FROM generate_series(length($1),1,1) AS s(i) ),"");
$$ LANGUAGE sql IMMUTABLE STRICT;
Podemos agora testar a execuçăo de todas as funçőes recém-criadas de uma só vez através da instruçăo SQL contida na Listagem 18. O resultado da execuçăo de todas as funçőes deve ser o mesmo: a string inversa “fed cba”.
SELECT reverse("abc def"), reverse2("abc def"), reverse3("abc def"), reverse4("abc def"),
reverse5("abc def"), reverse6("abc def");
>> fed cba, fed cba, fed cba, fed cba, fed cba, fed cba,
Agora que possuímos a funçăo reverse() em linguagens procedurais distintas, podemos iniciar os testes de desempenho para analisarmos quais as abordagens mais adequadas para usarmos em situaçőes onde a velocidade de atualizaçăo é um fator crítico no banco de dados. Este será o tema da seçăo a seguir.
O primeiro passo para se realizar o benchmark das linguagens procedurais é criar o ambiente de testes. Quanto maior o porte deste ambiente, mais precisos serăo os resultados comparativos. Isto é, se a base de dados utilizada para os testes for muito pequena, poderemos năo perceber as diferenças no desempenho de cada uma das funçőes.
Uma sugestăo é criar um banco de dados contendo a lista de palavras de um dicionário. No Linux, podemos extrair as palavras de um verificador ortográfico como o myspell. Primeiramente, execute uma instruçăo de busca como find ou locate para descobrir a localizaçăo exata do arquivo DIC. Cada linha deste arquivo, que é do formato texto, contém uma palavra válida para o dicionário em questăo. A Listagem 19 traz um exemplo de utilizaçăo do pacote mlocate para a busca do arquivo de dicionário. Observe que o primeiro comando, updatedb, precisa ser executado por um usuário com poderes de administrador, geralmente o root.
# updatedb
$ locate .dic | grep spell
Na distribuiçăo de Linux usada no estudo, um dos arquivos foi encontrado no endereço /usr/share/myspell/dicts/pt-BR.dic. Ele possuía cerca de 5 MB de tamanho e mais de 300 mil linhas. Trata-se do dicionário em língua portuguesa do Brasil usado em correçőes ortográficas em editores de texto. Arquivos desse tipo săo facilmente encontrados na Internet e geralmente acompanham aplicaçőes como editores de texto em suítes de escritório.
O que faremos na seqüęncia é importar todas as linhas desse arquivo de texto para o banco de dados PostgreSQL, na forma de registros de uma tabela. Antes disso, precisamos tratar os dados. Abra o arquivo pt-BR.dic num editor de textos qualquer do Linux, como vi ou Kwrite. Veja o resultado na Figura 1.
Analisando o seu conteúdo, percebemos que a primeira linha do arquivo de texto contém a quantidade de palavras no próprio arquivo. Além disso, podemos notar que geralmente cada linha do arquivo contém uma palavra do dicionário seguida de uma barra e uma determinada codificaçăo, que năo nos interessa nesse estudo. Execute entăo a instruçăo contida na Listagem 20 para tratar o arquivo texto para ser importado futuramente.
$ sed –e "1d" –e "s/\r//" –e "s/^\(.*\)\/.*/\1/" \ /usr/share/myspell/dicts/pt-BR.dic > dict.dat
O comando que acabamos de executar através do utilitário SED cria um outro arquivo de texto chamado dict.dat. Este novo arquivo conterá todas as linhas do arquivo pt-BR.dic, excetuando-se a primeira, e em cada linha só haverá a palavra sem os códigos adicionais. Quebras de linha do tipo Windows, CR+LF, serăo substituídas por apenas LF, o padrăo do Linux. Verifique com um editor de textos o resultado obtido neste arquivo. Veja na Figura 2 o resultado.
Vamos agora criar a tabela no banco de dados para armazenar a lista de palavras do dicionário. No pgAdmin III, execute a instruçăo SQL contida na Listagem 21. O tipo de dados serial em PostgreSQL é na verdade um alias para um inteiro (int ou int4) vinculado a uma seqüęncia, ou seja, o campo id será um auto-incremento.
CREATE TABLE dict (
id serial PRIMARY KEY,
word varchar
);
Em seguida, através da linha de comando do Linux, execute as instruçőes da Listagem 22. Isso fará com que as palavras presentes no arquivo de texto dict.dat sejam definitivamente importadas para a tabela DICT que acabamos de criar no PostgreSQL. No exemplo, sqlmag8 refere-se ao nome do banco de dados utilizado nos testes (criado na Listagem 9).
$ (echo "copy dict (word) from stdin;"; cat dict.dat) |\ psql sqlmag8
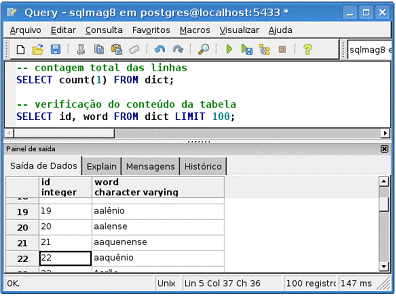
Verifique o conteúdo da tabela DICT através das instruçőes SQL da Listagem 23. A primeira executa a contagem de registros na tabela e a segunda exibe as primeiras 100 linhas desta, que devem ser coincidentes com o arquivo de texto dict.dat. O resultado é ilustrado na Figura 3.
--contagem total das linhas
SELECT count(1) FROM dict;
--verificaçăo do conteúdo da tabela
SELECT id, word FROM dict LIMIT 100;
Agora que possuímos uma tabela com um volume razoável, com um pouco mais de 300 mil registros, podemos realizar o benchmark das linguagens procedurais.
Através das instruçőes SQL contidas na Listagem 24 criaremos os índices reversos vinculados a cada uma das funçőes do tipo reverse().
-- linguagem C
CREATE INDEX dict_ix1 ON dict (
reverse(word) varchar_pattern_ops);
-- linguagem PL/Perl
CREATE INDEX dict_ix2 ON dict (
reverse2(word) varchar_pattern_ops);
-- linguagem PL/Python
CREATE INDEX dict_ix3 ON dict (
reverse3(word) varchar_pattern_ops);
-- linguagem PL/pgSQL
CREATE INDEX dict_ix4 ON dict (
reverse4(word) varchar_pattern_ops);
-- linguagem PL/pgSQL
CREATE INDEX dict_ix5 ON dict (
reverse5(word) varchar_pattern_ops);
-- linguagem SQL
CREATE INDEX dict_ix6 ON dict (
reverse6(word) varchar_pattern_ops);
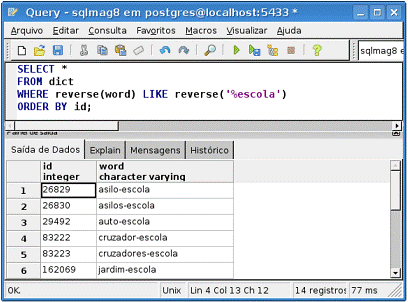
Para testar o funcionamento do índice que utiliza a funçăo reverse(), escrita em linguagem C, basta executar a instruçăo SQL da Listagem 25. Com esta requisiçăo săo retornadas rapidamente as palavras do dicionário que sejam finalizadas pelo texto “escola”. Sem o índice, o tempo de resposta poderia ser efetivamente desastroso para o servidor de banco de dados.
SELECT *
FROM dict
WHERE reverse(word) LIKE reverse("%escola")
ORDER BY id;
Veja na Figura 4 o resultado obtido com a instruçăo SQL. Observe que a funçăo reverse() está presente em ambos os lados do operador LIKE. Podemos fazer o teste com as demais funçőes com a simples substituiçăo no texto da instruçăo SQL pelos nomes reverse2, reverse3, e assim por diante. Com isso, teremos uma idéia da diferença no desempenho entre as diferentes linguagens procedurais.
Agora que os índices reversos foram definidos na tabela DICT, podemos forçar a recriaçăo de cada um deles através da instruçăo de DDL contida na Listagem 26. Execute os comandos REINDEX individualmente, e em cada invocaçăo observe a duraçăo do processo. Este tempo definirá quăo otimizada a funçăo em questăo é, uma vez que ela será chamada neste teste pelo menos 300 mil vezes durante a recriaçăo do índice.
-- linguagem C
REINDEX INDEX dict_ix1;
-- linguagem PL/Perl
REINDEX INDEX dict_ix2;
-- linguagem PL/Python
REINDEX INDEX dict_ix3;
-- linguagem PL/pgSQL
REINDEX INDEX dict_ix4;
-- linguagem PL/pgSQL
REINDEX INDEX dict_ix5;
-- linguagem SQL
REINDEX INDEX dict_ix6;
No melhor caso, como esperado, o índice baseado na funçăo em linguagem C foi recriado em 3,5s. Em PL/Perl levou 6,4s e em PL/Python 5,5s. Os piores casos foram registrados com as linguagens PL/pgSQL, com 10 s (com loop) e 18 s (recursiva), e na linguagem SQL com 14s.
Apesar de termos tido uma boa idéia sobre o desempenho das funçőes em cada linguagem, podemos estar fazendo aproximaçőes grosseiras devido a outros fatores envolvidos no sistema gerenciador de banco de dados.
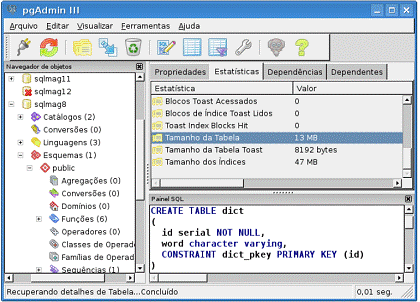
Uma das fundamentais diferenças reside num conceito extremamente importante no SGBD: o cache das informaçőes. A tabela DICT usada previamente nos testes, apesar de conter mais de 300 mil linhas, possui apenas 13 MB de tamanho em disco. Seus índices, por sua vez, ocupam apenas 47 MB (vide Figura 5). Com isso, bastam 60 MB de espaço para armazenar todas estas estruturas completamente em memória. Lembre-se também que a cláusula IMMUTABLE na criaçăo das funçőes faz com que os resultados das chamadas a elas sejam também sujeitos a algoritmos de caching.
Por estas razőes, é preciso aplicar os procedimentos de criaçăo de índices reversos em uma tabela com maior volume de dados num servidor PostgreSQL otimizado e num ambiente próximo ao de produçăo para mensurar as reais diferenças entre as abordagens.
Esse teste foi realizado com uma tabela contendo cerca de 10,5 milhőes de linhas de uma base de dados real de um cadastro de pessoas. Os índices reversos foram criados no campo contendo o nome completo de cada indivíduo. Uma poderosa aplicaçăo deste conceito é que com instruçőes SQL semelhantes ŕ da Listagem 25 podemos efetuar buscas de pessoas pelo sobrenome. E como agora o volume da tabela e índices passa a ser de grande porte (cerca de 2,5 GB ao total), a influęncia do mecanismo de cache é minimizada consideravelmente.
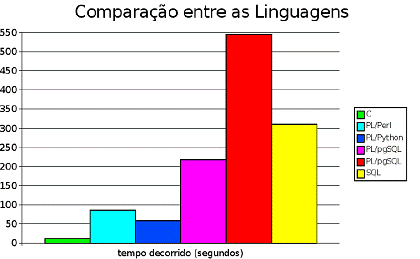
A Tabela 1 foi montada com base em médias de mediçőes de tempo em sucessivas execuçőes da instruçăo REINDEX em cada uma das funçőes do tipo reverse() nessa base de dados de pessoas.
| Linguagem | Funçăo | Tempo Decorrido (segundos) | Relaçăo com a Linguagem C (em %) |
|---|---|---|---|
| C | reverse() | 11,37s | - |
| Perl | reverse2() | 85,97s | 756% acima |
| PL/Python | reverse3() | 58,89s | 518% acima |
| PL/pgSQL | reverse4() | 218,18s | 1919% acima |
| PL/pgSQL | reverse5() | 546,62s | 4807% acima |
| SQL | reverse6() | 311,77s | 2742% acima |
As mesmas informaçőes săo apresentadas no formato de gráfico, em unidade de segundos, na Figura 6.
A abordagem em linguagem C foi simplesmente esmagadora: chegou a ser de 5 a 48 vezes mais rápida que as demais. As funçőes em linguagens PL/pgSQL e SQL revelaram-se as piores no quesito desempenho, especialmente a reverse5(), que implementa a recursividade. As linguagens interpretadas Perl e Python ficaram mais próximas do resultado ideal com a linguagem C.
Neste artigo foram apresentadas técnicas de otimizaçőes em consultas usando o SGBD PostgreSQL usando índices reversos. Vimos que uma funçăo customizada responsável pela inversăo de strings pode ser desenvolvida de inúmeras maneiras e utilizando as várias linguagens procedurais disponíveis no PostgreSQL, tendo o mesmo resultado final. Quando a performance é um fator decisivo, percebemos a partir de testes realizados que as linguagens C (principalmente), PL/Phyton e PL/Perl săo as que apresentam, respectivamente, os melhores desempenho em consultas e criaçőes de índices, o que nos dá um bom indicador para quando precisamos levar em consideraçăo o desempenho final da aplicaçăo.
Quando olhamos para a simplicidade de codificaçăo de cada uma das linguagens utilizadas, exclusivamente no caso da funçăo reverse(), as linguagens PL/PERL e PL/Phyton foram as funçőes mais simples de serem implementadas, o que pode ser observado pela complexidade dos códigos descritos nas Listagens 13 e 14. A complexidade da linguagem SQL (Listagem 17) também é baixa, comparada com as demais linguagens utilizada. Assim, é necessário fazer uma análise a respeito de “desempenho x complexidade” quando formos construir uma funçăo a ser utilizada pelo PostgreSQL. Como a implementaçăo da funçăo é realizada em um único momento, enquanto que a sua execuçăo é feita milhares de vezes, acredita-se que possa valer a pena investir um pouco mais de esforço na codificaçăo da funçăo com o propósito de usufruir de um melhor desempenho do banco de dados.


Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.