O objetivo deste artigo é apresentar o conceito de indexed views do SQL Server e mostrar como implementar e utilizar esse tipo de view para otimizar consultas.
As views săo conhecidas também como “tabelas virtuais”, já que apresentam uma alternativa para o uso de tabelas no acesso a dados. Uma view nada mais é que um comando SELECT encapsulado em um objeto. A sintaxe para a criaçăo de uma view é a apresentada na Listagem 1.
CREATE VIEW nome_da_visăo [(nome_da_coluna) [ , nome_da_coluna] ...) ] AS subconsulta;Veja um exemplo de criaçăo e uso de view na Listagem 1.
Use NorthWind go
create view vi_vendas_mes
As
Select ano = datepart(yyyy,OrderDate),
mes = datepart(mm,OrderDate),
qtde_total = sum(Quantity)
from Orders o
inner join
[Order Details] od on o.OrderId = od.OrderId
group by
datepart(yyyy,o.OrderDate), datepart(mm,o.OrderDate)
go
select * from vi_vendas_męs
go
ano mes qtde_total contador
----------- ----------- ----------- --------------------
1996 7 1462 59
1996 8 1322 69
1996 9 1124 57
1996 10 1738 73
1996 11 1735 66Dentre as vantagens da utilizaçăo de views, podemos citar :
As views encapsulam comandos SELECT, o que significa que, sempre que elas săo acionadas, os comandos SELECT associados a elas săo executados. As views năo criam repositórios para os para dados que retornam (como faz a tabela). Ora, que bom seria se pudéssemos “materializar” em uma tabela o resultado do comando SELECT encontrado na view, criando índices que facilitassem seu acesso. Pois bem, as indexed views fazem justamente isso. Executar um SELECT em uma indexed view tem o mesmo efeito que executar um select numa tabela convencional.
O principal objetivo das indexed views é aumentar a performance, e a vantagem do SQL Server é permitir que os planos de execuçăo considerem a indexed view como um meio de acesso aos dados, mesmo que o nome da view năo tenha sido explicitado na query. Isso é possível na versăo Enterprise Edition do SQL Server 2000, onde o otimizador de comandos pode selecionar os dados diretamente na indexed view (em vez de selecionar os dados brutos existentes na tabela), como veremos a seguir.
Por exemplo, a Listagem 2 mostra a diferença no resultado de um comando quando a propriedade concat_null_yields_null é alterada.
set concat_null_yields_null ON print null + ‘abc’
--------------------------------------
Set concat_null_yields_null OFF
print null + ‘abc’
--------------------------------------
abcImagine o que aconteceria se a indexed view fosse criada com a propriedade concat_null_yields_null ativada, mas a sessăo atual estivesse com essa propriedade desativada - o mesmo SELECT iria conduzir a resultados diferentes!
Esse problema foi resolvido de forma simples – para criar e utilizar indexed views, é obrigatório configurar o ambiente de acordo com uma lista de valores padrăo. Desse modo, é impossível obter resultados diferentes, pois a view simplesmente năo funcionará se alguma das configuraçőes estiver definida com um valor fora do padrăo.
A Tabela 1 exibe essas configuraçőes e seus respectivos valores padrăo.
| Configuraçăo | Id (*) | Estado exigido p/ indexed views | Padrăo do SQL Server 2000 | Padrăo em conexőes OLE DB (=ADO) ou ODBC | Padrăo em conexőes que utilizam DB Library |
|---|---|---|---|---|---|
| ANSI_NULLS | 32 | ON | OFF | ON | OFF |
| ANSI_PADDING | 16 | ON | ON | ON | OFF |
| ANSI_WARNING | 8 | ON | OFF | ON | OFF |
| ARITHABORT | 64 | ON | OFF | OFF | OFF |
| CONCAT_NULL_YIELDS_NULL | 4096 | ON | OFF | ON | OFF |
| QUOTED_IDENTIFIER | 256 | ON | OFF | ON | OFF |
| NUMERIC_ROUNDABORT | 8192 | OFF | OFF | OFF | OFF |
(*) O id é utilizado no comando sp_configure. Para conferir o que cada configuraçăo faz, leia a seçăo “Configuraçőes Necessárias para indexed views”. Existem duas maneiras para mudar o valor de uma configuraçăo:
Para confirmar o estado de cada um dos parâmetros da Tabela 1, utilize a funçăo SessionProperty(‘nome do parâmetro’) ou o comando DBCC UserOptions.
Dessa forma, configure todos os parâmetros de acordo com a coluna ‘estado exigido para indexed views’ da Tabela 1 – se isso năo for feito, o SQL Server năo permitirá criar/executar a indexed view.
Criaremos uma view para totalizar a quantidade diária vendida na tabela Order Details, localizada no database NorthWind. Veja a Listagem 3.
use NorthWind go
create view vi_vendas_mes
with SchemaBinding
as
select ano = datepart(yyyy,OrderDate),
mes = datepart(mm,OrderDate),
qtde_total = sum(Quantity),
contador = count_big(*)
from dbo.Orders o
inner join
dbo.[Order Details] od
on o.OrderId = od.OrderId
group by datepart(yyyy,o.OrderDate),datepart(mm,o.OrderDate)
goÉ necessário observar algumas particularidades ao criar indexed views:
É necessário criar as indexed views com SchemaBinding. Para manter consistente o conteúdo da view, năo é possível alterar a estrutura das tabelas que a deram origem. Para evitar esse tipo de problema, é obrigatório utilizar SchemaBinding na criaçăo de indexed views, pois essa opçăo năo permite alterar a estrutura da tabela sem que se elimine antes a view.
Para utilizar a cláusula GROUP BY, é obrigatório incluir a funçăo COUNT_BIG(*). A funçăo count_big(*) faz o mesmo que count(*), porém retorna um valor do tipo bigint (8 bytes).
Informe sempre o owner dos objetos referenciados na indexed view. Utilize select * from dbo.Orders em vez de select * from Orders, já que é possível haver tabelas com o mesmo nome mas com proprietários diferentes. Como a opçăo de schemabinding é obrigatória, o SQL Server precisa da especificaçăo exata do objeto para coibir a alteraçăo do schema.
A view criada no item 2 ainda năo se porta como uma indexed view, pois o resultado do comando select năo foi materializado em uma tabela. É possível confirmar essa afirmaçăo executando o comando sp_spaceused no Query Analyzer, que retorna o número de linhas e espaço utilizados pelas tabelas (Listagem 4).
sp_SpaceUsed vi_vendas_mes
--------------------------------------------------------------------------------------
Server: Msg 15235, Level 16, State 1, Procedure sp_spaceused, Line 91
Views do not have space allocated.Observe na Listagem 5 que o processamento da view é puramente lógico, tanto que o valor de Physical Reads é zero. Anote os valores registrados em Logical Reads e Physical Reads (1672+0+4+0=1676) – utilizaremos esses valores em nossas comparaçőes futuras.
Set statistics io ON
Select * from vi_vendas_mes
go
---------------------------------------------------------
ano mes qtde_total contador
----------- ----------- ------------- --------------------
1996 7 1462 59
1996 8 1322 69
1996 9 1124 57
.....
(23 row(s) affected)
Table 'Order Details'. Scan count 830, logical reads 1672, physical reads 0, read-ahead reads 0.
Table 'Orders'. Scan count 1, logical reads 4, physical reads 0, read-ahead reads 0.Para verificar se a view pode ser indexada (materializada), ou seja, se ela foi criada dentro dos padrőes e configuraçőes necessárias a indexed views, o resultado do SELECT a seguir deverá ser igual a 1.
select ObjectProperty(object_id('vi_vendas_mes'),'IsIndexable')Confirmados os pré-requisitos, podemos agora criar o índice. A sintaxe possui o mesmo formato utilizado na criaçăo de índices em tabelas convencionais:
create unique clustered index pk_ano_mes on vi_vendas_mes (ano,mes)Note que o índice cluster é obrigatório porque ele gera páginas de dados. Vocę só poderá criar índices năo-cluster em indexed views depois de criar o índice cluster.
Agora o SELECT encontrado na view foi materializado, o que pode ser comprovado com o comando sp_spaceused no Query Analyzer (Listagem 6).
sp_SpaceUsed vi_vendas_męs
go
-----------------------------------------------------
Name Rows Reserved data index_size Unused
vi_vendas_mes 23 24 KB 8 KB 16 KB 0 KB
Uma das maneiras de acessar uma indexed view (assim como uma view convencional) é fazendo referęncia a seu nome no comando SELECT:
select * from vi_vendas_mesCompare o volume de páginas movimentadas na Listagem 5 (1672+4=1676) com o da Listagem 7 (2+0=2). A diferença é bastante expressiva – a criaçăo da indexed view reduziu o total de I/O necessário em 1674 páginas.
Set statistics io ON select * from vi_vendas_mes
go
---------------------------------------------------------
ano mes qtde_total contador
----------- ----------- ------------- --------------------
1996 7 1462 59
1996 9 1124 57
.....
(23 row(s) affected)
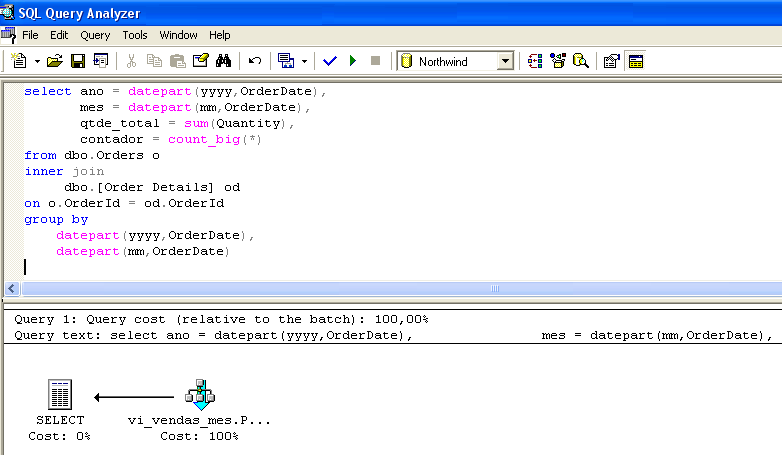
Table 'vi_vendas_mes'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0.Vejamos outro exemplo. A Figura 1 mostra o plano de execuçăo de uma query. Confirme que a view foi selecionada mesmo sem estar presente na linha do SELECT.
Durante a construçăo do plano de execuçăo da query, o otimizador constatou que já existiam dados pré-sumariados para a query em vi_vendas_mes e optou por selecionar os dados diretamente na indexed view.
Repare que a query executada na Figura 1 é idęntica ŕ encontrada na view vi_vendas_mes. No entanto, o acesso ŕ view pelo otimizador independe da semelhança entre a consulta executada e a consulta da view. A seleçăo da indexed view pelo processador de queries leva em conta apenas o custo-benefício. Desse modo, as queries executadas năo precisam ser idęnticas ŕ view (observe a Figura 3).
Entretanto, é necessário seguir algumas regras para que a indexed view seja considerada pelo otimizador de queries:
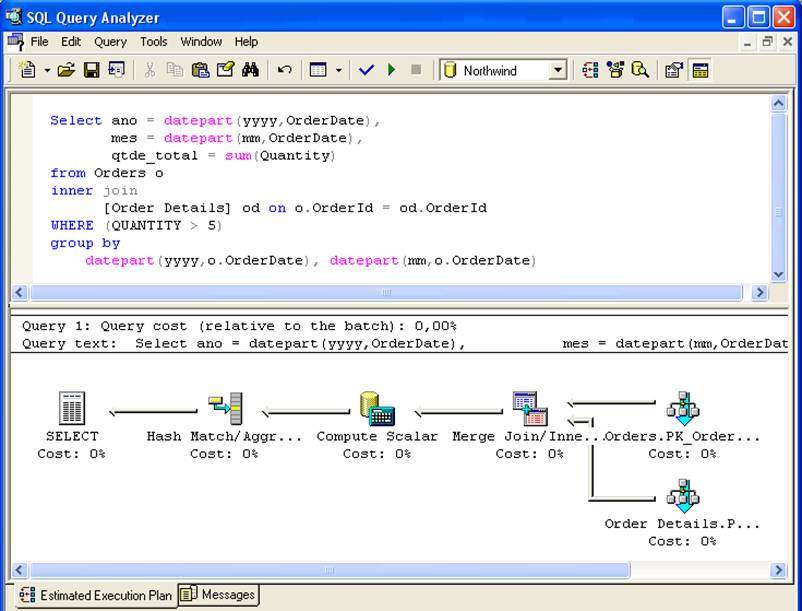
Por outro lado, se a query possuir a condiçăo where sum(Quantity) > 5, a view vi_vendas_mes será considerada no plano de execuçăo, pois a condiçăo da pesquisa é um subconjunto do SELECT presente na view.
As colunas com funçőes de agregaçăo na query precisam “estar contidas” na definiçăo da view: se a view retorna a coluna qtde=sum(Quantity) e a query possui uma coluna vlr_unitario=sum(UnitPrice), a view năo será considerada.
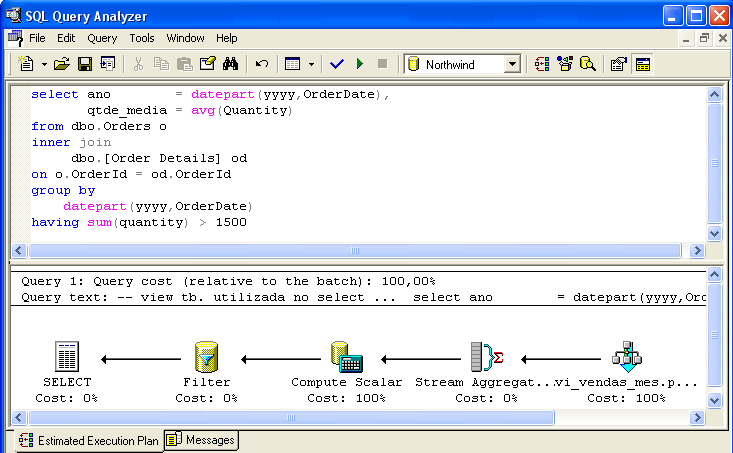
A Figura 3 mostra um comando SELECT que permite comprovar a inteligęncia do otimizador de comandos - o cálculo AVG(Quantity) foi substituído pela divisăo entre SUM(Quantity) / Count_Big(*), representada pelo ícone Compute Scalar. O predicado where sum(Quantity) > 1500 (representado pelo ícone Filter) também é considerado.
Consideraçőes gerais sobre a utilizaçăo de indexed views:
Define a forma como as comparaçőes com valores nulos săo efetuadas (Listagem 8).
set ANSI_NULLS ON
declare @var char(10)
set @var = null
if @var = null print 'VERDADEIRO'
else print 'FALSO'
-------------------------------------
FALSO
set ANSI_NULLS OFF
declare @var char(10)
set @var = null
if @var = null print 'VERDADEIRO'
else print 'FALSO'
--------------------------------------
VERDADEIRODetermina como devem ser armazenadas as colunas char, varchar, binary e varbinary quando seu conteúdo for menor que o tamanho definido na estrutura da tabela. O padrăo do SQL Server 2000 é manter ansi_padding ativado (=ON); nessa condiçăo valem as regras abaixo:
Quando ativado, finaliza a execuçăo da query ao encontrar uma divisăo por zero ou algum tipo de overflow.
Quando ativado, permite o uso de aspas duplas para especificar nomes de tabelas, colunas etc. – dessa forma, esses nomes poderăo possuir espaços e\ou caracteres especiais.
Controla o resultado da concatenaçăo de strings com valores nulos. Quando ativado, determina que essa junçăo deve retornar um valor nulo; caso contrário, retornará a própria string.
Quando ativado, determina a geraçăo de mensagens de erro quando:
Controla como o SQL Server deve proceder ao encontrar perda de precisăo numérica em operaçőes aritméticas. Se o parâmetro estiver ativado e uma variável com precisăo de duas casas decimais receber um valor com tręs casas decimais, a operaçăo será abortada. Se o parâmetro estiver desativado, o valor será truncado para duas casas decimais.
Quando se trata de otimizaçăo de queries, asindexed viewssăo uma boa escolha para alavancar a performance. Portanto, avalie minuciosamente as queries que lidam com sumarizaçőes e que săo executadas com certa freqüęncia e parta para a criaçăo deindexed views. O resultado vale a pena!


Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.