


Entre várias questőes estratégicas que giram em torno de uma organizaçăo, pode-se dizer que a capacidade de analisar e reagir rapidamente ŕs mudanças impostas pelo mercado, esta diretamente relacionada ŕ capacidade de digerir as informaçőes e transformá-las em conhecimento.
A utilizaçăo da mineraçăo de dados pode trazer diversos benefícios as empresas e organizaçőes. Para isso, existem importantes técnicas que auxiliam nesse processo, dentre as quais se destacam as regras de Classificaçăo e associaçăo. Partindo dessa observaçăo, definiu-se como objetivo geral, aplicar as técnicas de mineraçăo de dados a um subconjunto de dados de uma empresa varejista.
Com avanço na coleta e no armazenamento de dados, permitiu-se que organizaçőes acumulassem em base de dados uma enorme quantidade de informaçőes. Entretanto, a extraçăo de conhecimento nesses dados, tem provado ser extremamente desafiador. Normalmente, técnicas tradicionais de análise de dados năo podem ser usadas devido ao tamanho do conjunto de dados ser muito grande. Em outras situaçőes a natureza năo trivial dos dados significa que abordagens tradicionais năo podem ser aplicadas.
Diversas organizaçőes, por exemplo, a Wal-Mart, TAM linhas áreas, IBGE e a NASA, detém em seu departamento de tecnologia bases de dados de centenas de terabytes de informaçőes. Sabendo-se que o armazenamento do maior volume possível de informaçőes é benéfico para os seus processos, é aceitável deduzir que a dificuldade de interpretar e analisar esses dados săo diretamente proporcionais ŕ quantidade dos mesmos.
Diversas pesquisas tęm sido direcionadas para o desenvolvimento de técnicas com objetivo de extrair informaçőes a partir de um grande volume de dados e transformar estas informaçőes em conhecimento útil. Esta área é conhecida na literatura como KDD (Fayyad et al., 1996b).
O processo de KDD surgiu no final da década de 80 com o objetivo principal de procurar conhecimento em bases de dados. Há várias definiçőes do seu conceito, sendo a seguinte definiçăo a mais utilizada:
“KDD é um processo, de várias etapas, năo trivial, interativo e iterativo, para identificaçăo de padrőes compreensíveis, válidos, novos e potencialmente úteis a partir de grandes conjuntos de dados” (FAYYAD, 1996).
Este processo pode identificar padrőes e descobrir informaçőes relevantes que auxiliam o comerciante no processo de formaçăo de preços, nas estratégias de marketing, no comportamento de clientes em relaçăo ŕs compras, entre outras coisas.
A fase de mineraçăo de dados é onde realmente se extrai as informaçőes através de algoritmos que executam uma determinada tarefa, consequentemente gerando um padrăo entre itens em uma base de dados.
Este artigo está estruturado da seguinte forma: na seçăo 2 săo apresentados os conceitos a cerca da descoberta de conhecimento (KDD), mineraçăo de dados e a tarefa de Classificaçăo. Săo apresentados na seçăo 3 os experimentos e resultados. Por fim năo seçăo 4 apresentam-se as conclusőes.
A mineraçăo de dados năo foi criada com objetivo de substituir as técnicas atuais de análise de dados. Ela utiliza como base para a maioria de seus trabalhos os experimentos da Estatística, Inteligęncia Artificial, Máquina de Estado e Banco de dados para construir seu modelo.
O desejo dos pesquisadores em mineraçăo de dados de trazer tais técnicas existentes tem contribuído para amplitude do campo, assim como seu rápido crescimento.
O termo KDD surgiu no final da década de 80, com objetivo de procurar conhecimento em bases de dados. Muitas săo as definiçőes para este conceito, sendo a seguinte definiçăo a mais utilizada:
“KDD é um processo, de várias etapas, năo trivial, interativo e iterativo, para identificaçăo de padrőes compreensíveis, válidos, novos e potencialmente úteis a partir de grandes conjuntos de dados” (FAYYAD, 1996).
A expressăo “năo trivial”, demonstra a complexidade na execuçăo e manutençăo dos processos de KDD, o termo “interativo” indica a relevância de se ter um elemento controlando o processo, o termo “iterativo” sugere a possibilidade de repetiçőes em qualquer uma das etapas do processo e finalmente o “conhecimento útil” que é aquele onde o objetivo foi alcançado, trazendo consigo benefícios as aplicaçőes de KDD.
A extraçăo de conhecimento em bases de dados é um processo dinâmico e evolutivo, que envolve relacionamento com outras áreas como estatística, inteligęncia artificial, maquina de estado e banco de dados. Os padrőes extraídos devem ser úteis, gerando um conhecimento que poderá tirar alguma vantagem, seja cientifica ou comercial.
De acordo com FAYYAD et al. (1996), o processo de KDD é constituído de diversas fases, explicadas na figura 1, e tem início na análise do domínio da aplicaçăo e dos objetivos a serem realizados, sendo este processo dividido em 5 fases:
A primeira etapa do processo consiste na escolha da base a ser minerada, podendo ser amostras de dados, subconjuntos de variáveis até grandes massa de dados. A fase de pré-processamento tem como objetivo eliminar ruídos, tuplas vazias, valores ilegítimos. A etapa de transformaçăo dos dados depende do objetivo da busca e do algoritmo a ser aplicado, pois é ele que possui as limitaçőes a serem impostas a base de dados. A melhoria na qualidade dos dados é importante para que haja um melhor resultado, garantindo assim uma melhor qualidade nos padrőes descobertos.
Após a realizaçăo fases anteriores, a mineraçăo de dados (Data Mining) é aplicada. Essa fase é a mais importante do processo de KDD, sendo nela utilizado algum algoritmo que utiliza uma determinada técnica, e que tem como objetivo elaborar um modelo para representar um conjunto de dados.
A Interpretaçăo ou Pós-Processamento é a fase que identifica, entre os padrőes extraídos na etapa de Data Mining. Esta fase envolve todos os participantes que avaliam de forma criteriosa os resultados. É importante interpretar os padrőes minerados, possivelmente retornando a qualquer fase anterior para novas iteraçőes, caso seja necessário, a fim de apresentar o conhecimento descoberto ao usuário. A Figura 1 apresenta as atividades que compőem o processo de KDD.
Mineraçăo de Dados ou Data Mining é o principal processo da fase de descoberta de conhecimento em bases de dados para extraçăo de conhecimento, baseando-se em técnicas da estatística, inteligęncia artificial, computaçăo paralela, máquina de estado, ela constrói um longo histórico de pesquisas relacionadas a estas áreas. Procurando por padrőes, relacionamentos entre dados, anomalias e regras, com objetivo de encontrar informaçőes ocultas, que possam ser relevantes a tomada de decisăo e/ou avaliaçăo de resultados.
Uma das motivaçőes para a utilizaçăo da mineraçăo de dados no comércio é a grande quantidade de dados armazenados eletronicamente, os varejistas podem juntar os dados do ponto de venda (leitores de código de barras) com informaçőes de registros web, registros de atendimentos entre outros para lhes auxiliar a compreender melhor as necessidades de seus clientes e a tomar decisőes de negócio com mais informaçőes precisas. Em outras palavras, descobrir informaçőes sem uma prévia formulaçăo de hipóteses e buscar por algo năo intuitivo, é na verdade tornar dados sem obviedade em valiosas informaçőes estratégicas.
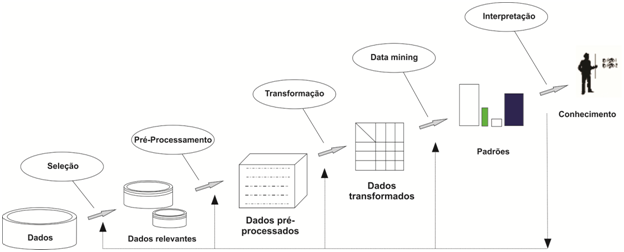
Figura 1: Etapas do KDD (Fonte: Fayyad et al., 1996)
As tarefas da mineraçăo de dados săo os tipos de descoberta que se pretende realizar em uma base de dados, isto é, săo as informaçőes que se deseja extrair. Para determinar qual tarefa a ser resolvida, deve-se ter um bom conhecimento do domínio da aplicaçăo e saber o tipo de informaçăo que se quer obter (FAYYAD, 1996; JOHN, 1997):
A definiçăo da técnica de mineraçăo a ser aplicada está intimamente relacionada com a tarefa de mineraçăo que se deseja executar, já que essa tarefa define o relacionamento entre os dados, ou seja, o modelo. Existem diversas tarefas da mineraçăo de dados entre elas: classificaçăo, clusterizaçăo, regressăo e associaçăo.
Um breve resumo das tarefas mais importantes săo descritos a seguir.
A tarefa de associaçăo foi desenvolvida inicialmente por Agrawal et al. (1993). E tem como objetivo principal encontrar padrőes do tipo X→Y, ou seja, o quanto X implica em Y onde X e Y săo conjuntos distintos. Por exemplo, um cliente que compra o item A freqüentemente compra também o item B. Através dessa tarefa pode-se estimar que um conjunto de item “X” possui uma tendęncia a se repetir freqüentemente em conjunto com um valor “Y”. Esta implicaçăo é avaliada através de dois fatores: suporte e confiança. (Agrawal e Srikant, 1994).
A tarefa de Agrupamento, também denominada de clusterizaçăo ou segmentaçăo, é utilizada para dividir os dados em grupos (clusters). O objetivo é que os objetos dentro de um grupo sejam semelhantes e diferentes de outros objetos de outros grupos. Quanto maior a semelhança dentro de um grupo e maior a diferença entre grupos, melhor ou mais distinto será o agrupamento (TAN, STEINBACH, KUMAR, 2006).
Pode-se, por exemplo, utilizar essa tarefa para analisar dados de tratamentos de uma doença, dividindo-se em grupos baseados na semelhança dos efeitos colaterais produzidos.
A tarefa de Classificaçăo é uma tarefa da mineraçăo de dados que associa ou classifica objetos a determinadas classes, ela busca prever uma classe de um novo dado automaticamente. Por exemplo, uma base de dados que armazena características de clientes, baseando em históricos de transaçőes anteriores, podem-se classificar estes clientes em categorias para liberaçăo de crédito. Um novo cliente poderá ser classificado em uma das categorias definidas, de acordo com suas características.
Na próxima Seçăo será demonstrado detalhadamente todo o processo de KDD, focando na fase de Data Mining e utilizando-se o algoritmo de classificaçăo.
Todo o processo de extraçăo de conhecimento em bases de dados é evidenciado de fato, com os experimentos utilizando uma base de dados proveniente de uma empresa atuante na área do comércio varejista, optante por um acordo NDA(Non-Disclosure Agreement). O software de mineraçăo de dados utilizado para realizar a geraçăo de padrőes úteis foi o Núcleo DM. Desenvolvido em Delphi, este software trabalha com o algoritmo de Classificaçăo C4.5.
De acordo com o conhecimento adquirido na Seçăo 2.1, o início do processo de KDD encontra-se na escolha da massa de dados de acordo com os objetivos a serem alcançados, que neste caso, seria a descoberta de perfis dos clientes, buscar padrőes que gerem regras do tipo: Cliente que compra produdo X, provavelmente levará o produto Y ex: “Se Produto1 = refrigerante entăo Produto2 = suco de laranja”.
Após análise do banco de dados, foi selecionado uma amostra de 268.788 registros identificando o faturamento das vendas realizadas no período de 04 de Fevereiro de 2011 a 11 de Abril 2011. Os atributos necessários ao processo de mineraçăo de dados estăo destacados na Tabela 1.
| ATRIBUTO | DESCRIÇĂO | VALORES DISTINTOS |
| LINHAPROD | Linha no qual o produto foi classificado | 8 |
| SEXO | Sexo do cliente | 2 |
| EST_CIVIL | Estado civil do cliente | 4 |
| SALARIO | Faixa de salário do cliente | 3 |
| IDADE | Faixa etária do cliente | 3 |
Tabela 1: Atributos da base de dados submetidos ŕ mineraçăo.
Alguns atributos do cliente, para poderem ser utilizados, tiveram que ser discretizados.
O atributo LINHAPROD representa o grupo no qual os produtos foram classificados, com 8 valores discretizados. Brinquedos, Eletrodomésticos, Máquinas, Móveis e Decoraçăo, Multimídia, Telefonia Convencional, Telefonia Móvel, Bazar. O atributo Salário foi discretizado para Baixo, Médio e Alto. O atributo Idade também foi discretizado para facilitar o processo de Mineraçăo de dados. Veja na Tabela 2 o resumo das discretizaçőes feita para a tarefa de classificaçăo.
| SALÁRIO | IDADE | ||
| Intervalo com valores contínuos | Valor Nominal | Intervalo com valores contínuos | Valor Nominal |
| 200 - 500 | BAIXO | 19 - 30 | JOVEM |
| 501 - 1200 | MÉDIO | 31 - 50 | ADULTO |
| 1201 - 100000 | ALTO | 51 - 100 | SENIOR |
Tabela 2: Atributos da Base de dados submetidos ŕ mineraçăo.
A fase de Pré-processamento, com intuito de eliminar tuplas nulas, valores considerados inconsistentes ou errados, definidos como ruído, e diminuírem redundâncias, reduziu para 252.677 tuplas, sendo posteriormente convertido para o padrăo utilizado no software Núcleo DM. Nessa ferramenta, expôs-se ao processo de mineraçăo de dados, utilizando-se o algoritmo de Classificaçăo C4.5 (QUINLAN, 1993).
Para executar a tarefa de classificaçăo foi escolhido com atributo preditivo o campo (LINHAPROD) e o critério de parada foi de 75%. Para escolher o critério de parada foram testados varias faixas de valores, e a faixa de 75% foi o que apresentou os melhores resultados, por năo gerar uma árvore muito grande e aparentemente com resultados relevantes.
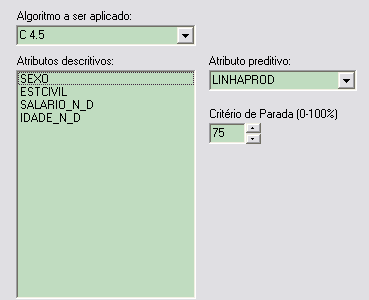
Figura 2: Atributos selecionados para classificaçăo
Os resultados da classificaçăo e a árvore gerada săo exibidos nas figura 3.
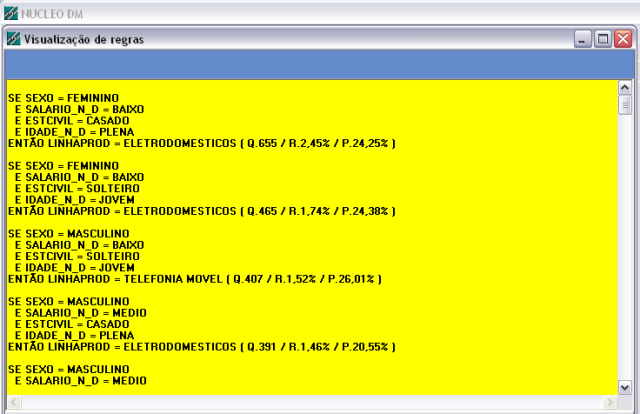
Figura 3: Regras de classificaçăo gerada
Para a extraçăo dos conhecimentos, que foram gerados pela tarefa de classificaçăo por linha de produtos, selecionaram-se as regras mais representativas de cada linha de produto, mostradas a seguir.
Listagem 1: Regras mais representativas da linha Móveis e Decoraçăo
SE SEXO = MASCULINO
E SALARIO = MEDIO (501-1200)
ENTĂO LINHAPROD = MOVEIS E DECORACAO ( Q.1237 / R.6,35% / P.30,05% )
----------------------------------------------------------------------------------------------------------
SE SEXO = FEMININO
E ESTCIVIL = CASADO
E IDADE = SENIOR (51-100)
E SALARIO = BAIXO (200-500)
ENTĂO LINHAPROD = MOVEIS E DECORACAO ( Q.293 / R.1,51% / P.33,91% )
----------------------------------------------------------------------------------------------------------
SE SEXO = FEMININO
E ESTCIVIL = VIUVO
E IDADE = SENIOR (51-100)
E SALARIO = MEDIO (501-1200)
ENTĂO LINHAPROD = MOVEIS E DECORACAO ( Q.134 / R.0,69% / P.34,1% )
Listagem 2: Regras mais representativas da linha Eletrodomésticos
SE SEXO = FEMININO
E ESTCIVIL = CASADO
E IDADE = ADULTO (31-50)
E SALARIO = BAIXO (200-500)
ENTĂO LINHAPROD = ELETRODOMESTICOS ( Q.655 / R.3,37% / P.33,73% )
SE SEXO = FEMININO
E ESTCIVIL = SOLTEIRO
E SALARIO = BAIXO (200-500)
E IDADE = JOVEM (19-30)
ENTĂO LINHAPROD = ELETRODOMESTICOS ( Q.465 / R.2,39% / P.33,79% )
SE SEXO = FEMININO
E ESTCIVIL = SOLTEIRO
E SALARIO = MEDIO (501-1200)
ENTĂO LINHAPROD = ELETRODOMESTICOS ( Q.391 / R.2,01% / P.33,11% )
Listagem 3: Regras mais representativas da linha Telefonia Móvel
SE SEXO = MASCULINO
E SALARIO = BAIXO (200-500)
E IDADE = JOVEM (19-30)
E ESTCIVIL = SOLTEIRO
ENTĂO LINHAPROD = TELEFONIA MOVEL ( Q.407 / R.2,09% / P.34,67% )
SE SEXO = MASCULINO
E SALARIO = BAIXO (200-500)
E IDADE = ADULTO (31-50)
E ESTCIVIL = SOLTEIRO
ENTĂO LINHAPROD = TELEFONIA MOVEL ( Q.127 / R.0,65% / P.31,05% )
SE SEXO = MASCULINO
E SALARIO = BAIXO (200-500)
E IDADE = SENIOR (51-100)
E ESTCIVIL = CASADO
ENTĂO LINHAPROD = TELEFONIA MOVEL ( Q.102 / R.0,52% / P.28,41% )
Após o processamento e a obtençăo dos padrőes obtidos na execuçăo da mineraçăo de dados, as regras geradas pelo software foram validados com a empresa. Segundo os mesmos, 3 regras apresentam um conhecimento novo, já que năo haviam identificado que no segmento Móveis e Decoraçőes, tinham uma maior venda entre indivíduos do sexo masculino e salário médio, e clientes feminino com idade avançada. No caso da linha de eletrodomésticos já era de conhecimento da empresa que os clientes em potencial era do sexo feminino, porém năo era de conhecimento que possuíam uma grande representatividade as mulheres casadas, com idade entre 31 e 50 anos e salário baixo.
Com os resultados obtidos demonstrou-se, na prática, como as diversas tecnologias ligadas ao processo de descoberta de conhecimento em bases de dados podem apoiar as tomadas de decisőes, de forma a manter as organizaçőes competitivas com relaçăo ŕ concorręncia e, principalmente, manterem-se no mercado.

Veja os resultado dos nossos alunos
Conquistas reais de quem está aplicando o método








Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.