Preocupado com a proteçăo de Propriedade Intelectual do seu código? Ou curioso com todos os artigos, ferramentas e bibliotecas de geraçăo de código que falam no tal bytecode?
Desenvolvedores de software de código fechado muitas vezes se preocupam com a proteçăo da sua Propriedade Intelectual, năo desejando que nenhum “curioso” possa descompilar facilmente suas classes. Para isso, exploramos a ferramenta open source ProGuard. Veremos também o aspecto de otimizaçăo de bytecode, devido ao qual estas ferramentas podem ser muito úteis até mesmo para projetos de código aberto.
Este artigo trata de um tema com aspectos importantes tanto do nível teórico quanto do prático. Vamos falar do bytecode do Java: sua estrutura, design, vantagens e limitaçőes, seu papel dentro da plataforma. Mas vamos estudar isso no contexto de uma aplicaçăo importante, a prática de ofuscamento e otimizaçăo (ou sua reversa: descompilaçăo) de classes. A princípio vocę poderia aprender a usar estas ferramentas de uma forma superficial, simplesmente lendo suas instruçőes e usando facilitadores como plug-ins para IDEs. Mas o real domínio de qualquer ferramenta sempre depende de saber o que acontece “por baixo do pano”.
Quando eu cursava a graduaçăo, a linguagem da vez era C/C++, gerando executáveis nativos. E uma das melhores liçőes sobre arquitetura de computadores tratou do formato executável nativo na plataforma Wintel: .EXE, .DLL, .OBJ e .LIB. Lembro de um trabalho prático que consistia em fazer o parsing de um arquivo .OBJ e exibir seu conteúdo detalhado – algo como o javap do JDK, mas bem mais complexo pois o formato usado pelo Windows, o COFF, tem um design de baixo nível. Era um daqueles trabalhos que muitos estudantes detestam por que (além de difícil) năo teria aplicaçăo para a enorme maioria dos projetos de software no “mundo real”. No entanto, com o passar dos anos vi que poucos tópicos de estudo me foram tăo úteis para adquirir um insight aprofundado de várias coisas – linguagens de programaçăo, compiladores, sistemas operacionais.
O formato dos arquivos que armazenam um programa executável é de importância fundamental, pois tem enorme envolvimento em vários aspectos da linguagem. Se vocę duvida, basta ver como podemos categorizar linguagens/plataformas em famílias coerentes, pelo seu formato executável: veja o quadro “Linguagens, por Formato Executável”.
Usam o formato executável nativo do S.O., como COFF, ELF ou Mach-O. É o formato mais eficiente em tempo de carregamento/inicializaçăo e consumo de memória (pois facilita o compartilhamento entre processos). Mas é a opçăo mais rígida, inviabilizando a criaçăo de aplicaçőes mais dinâmicas. Parte do princípio que todo o código-fonte que contribuirá para uma aplicaçăo está disponível no momento da compilaçăo, e que uma vez criado um processo, nenhum código será criado ou alterado.
Aplicaçőes nativas podem carregar “bibliotecas dinâmicas” (.DLLs/.SOs), mas isso é só uma facilidade de organizaçăo e compartilhamento de código. Em teoria a aplicaçăo poderia gerar fontes e compilá-los, mas na prática isso é muito difícil, pois a compilaçăo de executáveis nativos é um processo relativamente lento e pesado.
O extremo oposto: linguagens sem nenhum formato executável. Os fontes săo “executados” diretamente. Comum entre shells (CMD, sh, bash etc.), linguagens de macros ou automaçăo de aplicaçőes (VBA), na web (JavaScript), utilitários complexos (awk), e as chamadas “linguagens de scripting” (Perl, Python, Ruby etc.) populares para criar programas simples de forma rápida. Ou como o componente dinâmico de sistemas maiores, como sites web de primeira geraçăo criados com CGI e scripts Perl. Este último cenário de uso deu origem ŕ expressăo glue language, pois a linguagem de scripting fazia apenas um meio-de-campo, “amarrando” processos nativos como webserver e SGBD.
Este modelo (como todos os posteriores) exige o uso de uma JVM (Virtual Machine) capaz de interpretar o programa, já que o S.O. năo é capaz de fazę-lo.
Saiba mais: Introduçăo ao Java Virtual Machine (JVM)
Linguagens como Java, compiladas para um formato binário próprio e portável. Coloco ęnfase no “próprio”, pois embora se fale muito da portabilidade, também há vantagens no fato do formato ser projetado especialmente para as necessidades da linguagem – e năo para as de algum S.O. Linguagens nesta categoria săo praticamente tăo dinâmicas quanto as de scripting, pois seus bytecodes facilitam a manipulaçăo e geraçăo dinâmica, permitindo o uso de APIs sofisticadas de reflection e metaprogramaçăo, e mesmo, criaçăo de código totalmente novo em demanda.
O bytecode também exige o uso de uma JVM (Java Virtual Machine), sendo mais comum que a VM seja capaz de gerar código nativo em demanda (JIT).
Uma linguagem interpretada também poderia usar compilaçăo JIT. Mas na prática isso é incomum, pois sem um formato intermediário de bytecode, a JVM precisa fazer o parsing dos fontes, um processo relativamente demorado e que “bate de frente” com a necessidade de compiladores JIT de fazerem seu trabalho o mais rápido possível. A exceçăo notável é o JavaScript, cujas VMs mais atuais săo obrigadas a carregar o programa de código-fonte (pois é o formato padrăo da web) mas geram bytecode internamente, seja para interpretaçăo ou compilaçăo JIT.
Uma categoria menos conhecida, mas bastante interessante, foi adotada por linguagens pioneiras das VMs, como Lisp e Smalltalk. Nestes sistemas, o processo de compilaçăo cria objetos na memória; para preservar num arquivo o código, é feito um dump da “imagem” (estado da VM, inclusive o heap, stacks de threads, e outros dados). Isso se parece com o recurso de hibernaçăo de S.Os. modernos. Exceto pelo fato que, após gerada, a imagem pode ser carregada várias vezes, gerando processos independentes com um estado inicial idęntico (algo como o fork() do UNIX). É uma visăo “purista” do conceito de VM, no qual năo há uma dicotomia entre arquivo executável e processo, só estados diferentes da mesma coisa – ou seus objetos estăo ativos num processo, ou estăo hibernando numa imagem em disco.
Este modelo foi praticamente abandonado, pois tem desvantagens como estabilidade, dificuldade de trabalhar com sistema de controle de versőes, e o caráter monolítico da “imagem” dificultando a criaçăo de uma arquitetura de componentes.
Saiba mais: Guia de Linguagem Java
Algumas empresas de Smalltalk criaram tecnologias para contornar estas limitaçőes, como as “Parcels” do VisualWorks (componentizaçăo) ou o ENVY da OTI (versionamento). Năo sei se estas soluçőes foram insuficientes para o problema, ou se falharam apenas por chegar muito tarde ao mercado, ou por que o Smalltalk acabou morrendo por outros motivos.
Começaremos falando um pouco do bytecode do Java. Ou de forma mais precisa, o formato das classes do Java. Para explorar o assunto de forma mais concreta, começaremos examinando alguma classe de exemplo. Vejamos, por exemplo, a classe java.util.Stack da API do Java. Para inspecioná-la, vocę pode utilizar o utilitário javap do JDK:
C:\>javap java.util.Stack
Compiled from "Stack.java"
public class java.util.Stack extends java.util.Vector{
public java.util.Stack();
public java.lang.Object push(java.lang.Object);
public synchronized java.lang.Object pop();
public synchronized java.lang.Object peek();
public boolean empty();
public synchronized int search(java.lang.Object);
}
Na sua forma mais simples, o javap exibe o que se parece com o código-fonte da classe, exceto pela ausęncia do código (corpo dos métodos ou expressőes de inicializaçăo de atributos). Mas note que já aparece outra novidade, uma mensagem “Compiled from...” que indica o nome do arquivo-fonte que gerou esta classe. Isso é um exemplo simples de metadados do arquivo .class.
Listagem 1. Conteúdo completo de uma classe (com os fontes adicionados).
C:\>javap -v –private java.util.Stack
Compiled from "Stack.java"
public class java.util.Stack extends java.util.Vector
SourceFile: "Stack.java"
Signature: length = 0x2
00 21
minor version: 0
major version: 49
Constant pool:
const #1 = Asciz ()I;
const #2 = Asciz ()TE;;
const #3 = Asciz ()V;
const #4 = Asciz ()Z;
const #5 = Asciz (I)V;
const #6 = Asciz (TE;)TE;;
const #7 = Asciz <init>;
const #8 = Asciz Code;
const #9 = Asciz ConstantValue;
const #10 = Asciz J;
const #11 = Asciz LineNumberTable;
const #12 = Asciz Signature;
const #13 = Asciz SourceFile;
const #14 = Asciz addElement;
const #15 = Asciz elementAt;
const #16 = Asciz empty;
const #17 = Asciz java/util/EmptyStackException;
const #18 = Asciz java/util/Stack;
const #19 = Asciz java/util/Vector;
const #20 = Asciz lastIndexOf;
const #21 = Asciz peek;
const #22 = Asciz pop;
const #23 = Asciz push;
const #24 = Asciz removeElementAt;
const #25 = Asciz search;
const #26 = Asciz serialVersionUID;
const #27 = Asciz size;
const #28 = long 1224463164541339165l;
const #30 = class #17; // java/util/EmptyStackException
const #31 = class #18; // java/util/Stack
const #32 = class #19; // java/util/Vector
const #33 = Asciz <E:Ljava/lang/Object;>Ljava/util/Vector<TE;>;;
const #34 = Asciz ()Ljava/lang/Object;;
const #35 = Asciz (I)Ljava/lang/Object;;
const #36 = Asciz (Ljava/lang/Object;)I;
const #37 = Asciz (Ljava/lang/Object;)V;
const #38 = Asciz (Ljava/lang/Object;)Ljava/lang/Object;;
const #39 = NameAndType #27:#1;// size:()I
const #40 = NameAndType #7:#3;// "<init>":()V
const #41 = NameAndType #24:#5;// removeElementAt:(I)V
const #42 = NameAndType #21:#34;// peek:()Ljava/lang/Object;
const #43 = NameAndType #15:#35;// elementAt:(I)Ljava/lang/Object;
const #44 = NameAndType #20:#36;// lastIndexOf:(Ljava/lang/Object;)I
const #45 = NameAndType #14:#37;// addElement:(Ljava/lang/Object;)V
const #46 = Method #30.#40; // java/util/EmptyStackException."<init>":()V
const #47 = Method #31.#39; // java/util/Stack.size:()I
const #48 = Method #31.#41; // java/util/Stack.removeElementAt:(I)V
const #49 = Method #31.#42; // java/util/Stack.peek:()Ljava/lang/Object;
const #50 = Method #31.#43; // java/util/Stack.elementAt:(I)Ljava/lang/Object;
const #51 = Method #31.#44; // java/util/Stack.lastIndexOf:(Ljava/lang/Object;)I
const #52 = Method #31.#45; // java/util/Stack.addElement:(Ljava/lang/Object;)V
const #53 = Method #32.#40; // java/util/Vector."<init>":()V
const #54 = Asciz Stack.java;
{
private static final long serialVersionUID;
Constant value: long 1224463164541339165l
public java.util.Stack();
Code:
Stack=1, Locals=1, Args_size=1
0: aload_0
1: invokespecial #53; //Method java/util/Vector."<init>":()V
4: return
LineNumberTable:
line 36: 0
line 37: 4
public java.lang.Object push(java.lang.Object);
Code:
Stack=2, Locals=2, Args_size=2
# addElement(item);
0: aload_0
1: aload_1
2: invokevirtual #52; //Method addElement:(Ljava/lang/Object;)V
# return item;
5: aload_1
6: areturn
LineNumberTable:
line 50: 0
line 52: 5
Signature: length = 0x2
00 06
public synchronized java.lang.Object pop();
Code:
Stack=3, Locals=3, Args_size=1
# int len = size();
0: aload_0
1: invokevirtual #47; //Method size:()I
4: istore_2
# E obj = peek();
5: aload_0
6: invokevirtual #49; //Method peek:()Ljava/lang/Object;
# removeElementAt(len - 1);
9: astore_1
10: aload_0
11: iload_2
12: iconst_1
13: isub
14: invokevirtual #48; //Method removeElementAt:(I)V
# return obj;
17: aload_1
18: areturn
LineNumberTable:
line 65: 0
line 67: 5
line 68: 10
line 70: 17
Signature: length = 0x2
00 02
public synchronized java.lang.Object peek();
Code:
Stack=3, Locals=2, Args_size=1
# int len = size();
0: aload_0
1: invokevirtual #47; //Method size:()I
4: istore_1
# if (len == 0) {
5: iload_1
6: ifne 17
# throw new EmptyStackException();
9: new #30; //class java/util/EmptyStackException
12: dup
13: invokespecial #46; //Method java/util/EmptyStackException."<init>":()V
16: athrow
# }
# return elementAt(len - 1);
17: aload_0
18: iload_1
19: iconst_1
20: isub
21: invokevirtual #50; //Method elementAt:(I)Ljava/lang/Object;
24: areturn
LineNumberTable:
line 82: 0
line 84: 5
line 85: 9
line 86: 17
Signature: length = 0x2
00 02
public boolean empty();
Code:
Stack=1, Locals=1, Args_size=1
# return size() == 0;
0: aload_0
1: invokevirtual #47; //Method size:()I
4: ifne 11
7: iconst_1
8: goto 12
11: iconst_0
12: ireturn
LineNumberTable:
line 96: 0
public synchronized int search(java.lang.Object);
Code:
Stack=2, Locals=3, Args_size=2
# int i = lastIndexOf(o);
0: aload_0
1: aload_1
2: invokevirtual #51; //Method lastIndexOf:(Ljava/lang/Object;)I
5: istore_2
# if (i >= 0) {
6: iload_2
7: iflt 17
# return size() - i;
10: aload_0
11: invokevirtual #47; //Method size:()I
14: iload_2
15: isub
16: ireturn
# }
# return -1;
17: iconst_m1
18: ireturn
LineNumberTable:
line 114: 0
line 116: 6
line 117: 10
line 119: 17
}
Para tirar um Raio-X completo, vamos usar as opçőes –v (verbose) e –private. Veja o resultado na Listagem 1. Na mesma listagem, adicionei o código-fonte da classe em linhas iniciadas por #; infelizmente o javap năo gera tais linhas, fiz esta alteraçăo manualmente para facilitar a leitura.
A primeira coisa que vocę deve ter notado é que, antes dos métodos, o output começa com uma longa listagem de metadados. No comecinho temos alguns headers, como os números de versăo da classe: major=49 e minor=0 indicam o formato do Java SE 6; nenhuma JVM de especificaçăo inferior será capaz de carregar esta classe, mas qualquer JVM deste nível (ou superior) será capaz. Depois, temos um grande número de linhas “const...”. Esse é o famoso Constant Pool (CP), uma tabela de dados constantes que existe no começo de qualquer classe Java.
O CP contém constantes de vários tipos: strings, valores numéricos primitivos, e símbolos. As primeiras săo mais fáceis de entender, por exemplo, a constante #28 é do tipo long. Podemos ver que este é o valor do atributo privado serialVersionUID, logo no início da classe. Todas as constantes literais utilizadas por atributos ou código de uma classe săo armazenadas no Constant Pool, e referenciados através de seus índices.
Já as constantes simbólicas săo estruturas usadas internamente para a linkagem entre classes, ou seja, referęncias entre classes, métodos e outros artefatos de código. Por exemplo, adiantando a leitura para o método push(), vemos que há uma invocaçăo para o método addElement() (herdado da classe base java.util.Vector). Este método é referenciado pela constante #52 – ou seja, lá no meio do bytecode de push() encontraremos o valor 52, năo um nome ou endereço do método. A JVM usa este valor como índice do CP para encontrar uma estrutura do tipo Method. Esta estrutura (que nada tem a ver com a API java.lang.reflect.Method) é composta por outras duas constantes, #31 e #45. A constante #31 é uma class, também definida com um ponteiro para outra constante, a #18: uma Asciz (string ASCII) com o valor java/util/Vector. Assim, decodificamos a primeira parte do Method #52: é uma referęncia para a classe java.util.Vector. Para a segunda parte, seguimos a constante #45 que é do tipo NameAndType, composto também de duas constantes: #14 e #37. Ambas săo do tipo Asciz, sendo #14 = "addElement" e #37 = "(Ljava/lang/Object;)V".
Ou seja, uma referęncia completa para um método exige especificar tanto a classe quanto o método, sendo que para o método, precisamos indicar o nome do método e também um segundo valor string que é sua assinatura. A assinatura é uma convençăo da especificaçăo Java, que codifica todos os parâmetros e também o tipo de retorno do método. Esta codificaçăo é razoavelmente fácil de ler, pois se parece com a declaraçăo do método. Mas os tipos básicos săo codificados de forma especial, com uma única letra – por exemplo, "V" = void, sendo o tipo de retorno do método e vindo ao final da assinatura. E os tipos năo-primitivos (classes) săo prefixados por "L", como Ljava/Lang/Object, que indica um parâmetro do tipo java.lang.Object. As assinaturas também usam "/" no lugar de "." como separador de package.
Através das constantes simbólicas do CP, a JVM, ao carregar a classe, resolve todas as referęncias que possam existir para outros métodos e classes. Como parte do processo de classloading, estas referęncias simbólicas săo tipicamente substituídas por referęncias mais diretas (como um ponteiro para o endereço de memória onde o elemento referenciado foi carregado), mas isso é um detalhe de implementaçăo / otimizaçăo da JVM.
Vamos, agora, ao bytecode propriamente dito. O qual possui este nome por que todas as operaçőes săo codificadas por um único byte (assim, existem no máximo 256 operaçőes). Algumas operaçőes podem ser seguidas de bytes adicionais para os parâmetros; estes parâmetros săo ou números inteiros, ou índices para o Constant Pool.
Como exemplo, tomemos o código do método peek(). Vamos destrinchá-lo, passo a passo:
public synchronized java.lang.Object peek();
Code:
Stack=3, Locals=2, Args_size=1
A linha acima declara o formato do stack frame do método. Quando o método inicia sua execuçăo, a JVM deve criar um novo frame – uma regiăo de memória no stack do thread. Este frame terá tręs posiçőes (cada uma de uma ‘palavra’ de 32 bits). Destas, duas săo para variáveis locais e uma é para um parâmetro – no caso, o this, parâmetro intrínseco de qualquer método de instância.
# int len = size();
0: aload_0
1: invokevirtual #47; //Method size:()I
4: istore_1
Para invocar métodos, os parâmetros săo empilhados no stack. O método size() também possui somente o parâmetro this. Começamos com uma instruçăo aload, que significa “coloque na pilha (push) uma referęncia para objeto”. Essa instruçăo tem um parâmetro, um índice de variável local. No caso é o índice 0, que é o índice do this de peek(). E como é muito comum executar aload com o parâmetro 0, existe um bytecode especial aload_0 que năo exige nenhum parâmetro, sendo hardwired para o índice 0. Assim, esta instruçăo exige um único byte, na posiçăo 0 do método.
Uma vez passados os parâmetros, a invocaçăo é feita por bytecodes invoke*, conforme o tipo do método-alvo. No caso, usamos invokevirtual pois Vector.size() é virtual (método definido por uma classe, de instância (năo static), e polimórfico (năo final nem private). O invokevirtual exige um parâmetro que identifica o método a invocar; este parâmetro é um índice de 16 bits para o CP. Por isso, a instruçăo completa ocupa 3 bytes, nas posiçőes 1 (o bytecode), 2 e 3 (o índice #47).
O método size() “consome” os parâmetros deixados no stack, e ao retornar empilha o valor gerado, no caso um int. Assim, após o invokevirtual o stack năo terá mais aquele valor empilhado pelo aload_0, mas terá o int com o tamanho do Vector. Finalmente, istore_1 armazena o int que está no topo do stack na variável local de índice 1 (que é len), executando a atribuiçăo.
# if (len == 0) {
5: iload_1
6: ifne 17
A JVM é uma “máquina de pilha”, onde năo só os parâmetros e retornos de método, mas todos os valores manipulados residem no stack (năo há “registradores” como os de CPUs). No código acima, iload_1 empilha o valor da variável int de índice 1, len. Entăo, ifne faz um desvio condicional com base na comparaçăo entre o int no topo da pilha e 0[4]. Assim, iload_1 / ifne equivale a if (len != 0).
O ifne possui como parâmetro um Bytecode Index (bce) de 16 bits, no caso 17, que diz para onde desviar se o resultado da comparaçăo de um int com 0 for not equal. É por isso que o bytecode codifica um len != 0 (o oposto do código-fonte), pois se o valor năo for 0, pulamos o código a seguir, que gera a exceçăo. É comum que o javac inverta a ordem de desvios condicionais para simplificar o bytecode resultante, procurando utilizar o menor número possível de desvios.
# throw new EmptyStackException();
9: new #30; //class java/util/EmptyStackException
12: dup
13: invokespecial #46; //Method java/util/EmptyStackException."<init>":()V
16: athrow
# }
O código acima, que só executa se len == 0 (pois o ifne năo fez o desvio), lança uma exceçăo. Primeiro criamos o objeto de exceçăo com o bytecode new, cujo parâmetro é o índice da constante com a referęncia simbólica para a classe EmptyStackException. O new deixará a referęncia para o objeto criado no topo do stack. Depois o bytecode dup duplica qualquer coisa que estava no topo do stack – teremos, entăo, duas referęncias para a exceçăo. A primeira delas será consumida pelo invokespecial, que invoca o construtor da exceçăo (<init> é o nome de todos os construtores, no bytecode). A segunda referęncia é consumida pelo athrow, que executa o throw da exceçăo.
# return elementAt(len - 1);
17: aload_0
18: iload_1
19: iconst_1
20: isub
No trecho acima, os bytecodes 18-20 implementam a expressăo len – 1. Começamos com o iload_1 (empilha len), depois iconst_1 (empilha a constante int 1), e finalmente isub realiza uma subtraçăo inteira entre os dois valores mais no topo do stack e empilha o resultado.
21: invokevirtual #50; //Method elementAt:(I)Ljava/lang/Object;
24: areturn
Agora invocaremos elementAt(), que exige dois parâmetros (this e um int). O primeiro, this, já havia sido passado pelo bytecode 17, o aload_0. Depois disso executamos os bytecodes 18-20, que calculam len – 1 e empilham o resultado; assim, neste ponto o stack terá precisamente os valores exigidos por elementAt(). Entăo basta fazer o invokevirtual deste método, que mais uma vez, deixará o valor retornado no topo do stack – sendo que dessa vez, uma referęncia para objeto. Finalmente, o bytecode areturn realiza um return do valor de tipo referęncia que está no topo do stack.
LineNumberTable:
line 82: 0
line 84: 5
line 85: 9
line 86: 17
Após o bytecode, temos um atributo LineNumberTable que relaciona os índices de bytecode com as linhas de código. Este atributo é útil, em especial, para depuradores e para o preenchimento do stack trace de exceçőes.
Existem também outros atributos que năo mostramos, como o Exception table que mapeia blocks try/catch ou o InnerClass que mapeia classes aninhadas. Também năo entramos no detalhe de tipos genéricos do Java 5, que exigem mais alguns malabarismos no Constant Pool. Mas estes săo detalhes incrementais; a partir do que for exposto, o leitor só precisa de uma referęncia completa da especificaçăo da JVM (ver java.sun.com/docs/books/jvms/) – e alguma pacięncia – para ler diretamente qualquer classe Java, no formato de bytecode.
Se o leitor quiser utilizar bibliotecas de geraçăo dinâmica de classes, como o ASM ou CGLIB, precisará ter familiaridade com a estrutura do bytecode. Veja “A Dinâmica do Java”, Ediçăo 14.
Nosso principal foco prático é nas ferramentas de ofuscaçăo e otimizaçăo de bytecode Java. (Veja o quadro “A necessidade de ofuscamento”.) Existe uma variedade dessas ferramentas, com algumas diferenças de capacidade e usabilidade, mas todas săo conceitualmente iguais. Vamos adotar no artigo o ProGuard, por ser a mais popular soluçăo open source.
Comece baixando o ProGuard de proguard.sourceforge.net. No momento em que escrevo, a última versăo estável é a 4.2, mas aproveitarei a empreitada para testar o 4.3, hoje em desenvolvimento (usei o beta3), mas talvez já finalizado quando vocę receber esta ediçăo.
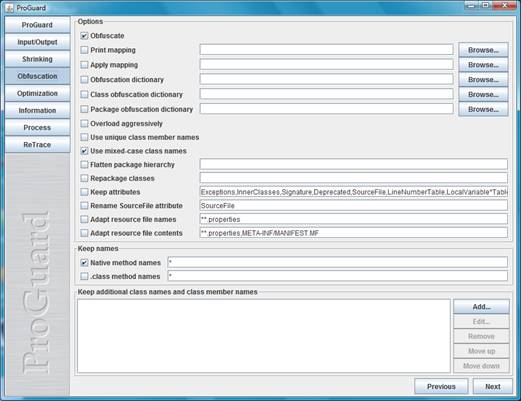
[nota] ADVERTĘNCIA: jamais use uma versăo năo-estável de um ofuscador para seu “trabalho sério”. Ofuscadores săo ferramentas perigosas, e os melhores săo os mais perigosos. Qualquer bug pode resultar em arquivos .class/.jar que năo funcionam, gerando erros bizarros da JVM tais como ClassFormatError, LinkageError ou VerifyError. [/nota]O ProGuard pode ser usado de várias formas: linha de comando, Ant/Maven, plug-ins de IDEs, ou sua GUI própria. Esta última opçăo é uma novidade da versăo 4.3, e muito didática por expor de forma clara as muitas opçőes do ProGuard. Assim, comece executando bin/proguardgui (Figura 1).
[nota] Na falta desta GUI, o ProGuard exige arquivos de configuraçăo bastante complexos, especificando as mesmas opçőes numa sintaxe própria. Ou XMLs do Ant ou Maven com as mesmas opçőes, que podem ser encapsuladas pelo XML e várias formas. Ou ainda, as GUIs específicas de plug-ins de IDEs. Como a lista de opçőes é bastante extensa, năo pretendemos com este artigo fornecer uma referęncia ou manual do usuário do ProGuard, pois isso tomaria um espaço enorme; preferimos focar apenas nos conceitos e funcionalidades. [/nota]Para testar o ProGuard, precisamos de alguma aplicaçăo Java já compilada, mas năo já ofuscada. Escolhi duas: o demo Font2DTest do JDK 6 (demo/jfc/Font2DTest); e o Java PC, um emulador de PC visto na Ediçăo anterior (www-jpc.physics.ox.ac.uk/JPC.jar). Reporto resultados para ambos os testes, mas advirto o leitor que o processamento do JPC é bem lento (vários minutos).
A GUI do ProGuard é muito simples. Começando pela aba Input/Output, use Add Input para selecionar o arquivo jar da aplicaçăo original, e Add Output para nomear o arquivo que será criado. Ambas as aplicaçőes que escolhi săo simples, possuem apenas um jar de entrada e nenhuma dependęncia de compilaçăo (só as APIs do JDK, que o ProGuard já configura por default).
O ProGuard oferece um enorme número de opçőes, organizadas pela GUI nas seguintes abas:
Para nossos projetos, vocę só precisará alterar a opçăo Information > Skip non-public library classes, ativada por default; desative-a. Pelo menos com o ProGuard 4.3-beta3 e as duas aplicaçőes de teste que selecionei, a configuraçăo default resulta em falha de processamento.
Com a configuraçăo pronta, execute Process > Process! e aguarde até o ProGuard reportar sucesso da operaçăo. Depois, execute a aplicaçăo processada, utilizando o arquivo jar gerado pelo ProGuard ao invés do original.
Os ofuscadores surgiram inicialmente para dificultar a descompilaçăo. Mas os programadores logo perceberam um interessante “efeito colateral”: programas menores, e talvez até mais rápidos.
Nos meus testes, as classes do Font2DTest.jar foram reduzidas de 78Kb para 58Kb, uma dieta de 25%. Já as classes do JPC.jar foram reduzidas de 1.277Kb para 693Kb, um enxugamento ainda mais impressionante de 45%. Note que estes números săo apenas para os .class brutos; a reduçăo do tamanho dos jars é menor, devido ŕ compressăo do formato JAR e ŕ presença de recursos (como imagens, ou no caso do JPC, enormes “discos virtuais”) que năo săo afetados pelo ProGuard.
[nota] Os jars ofuscados poderiam ter ficado ainda menores, bastaria desativar a opçăo Information>Preverify, que gera metadados de pré-verificaçăo (usados pelo Java SE 6 e também no Java ME). Mas isso năo é recomendado; no Java ME a pré-verificaçăo é obrigatória, e no Java SE 6, é benéfica pois torna o carregamento das classes mais rápido. [/nota]Outro dado interessante é a velocidade de carregamento das aplicaçőes. Testei isso apenas para o JPC, que tem um volume de bytecode grande o bastante para ter impacto sensível no tempo de carga e inicializaçăo. No meu teste – iniciar o JPC e dar boot na imagem default – o consumo de CPU foi de 11.575ms para o JPC.jar original, e 9.640ms para o JPC.jar ofuscado / otimizado. Este diferencial de 2 segundos é impressionante, pois uma grande fatia do tempo de execuçăo deste teste é I/O de discos virtuais, e muito processamento para fazer o boot completo do PC emulado. Estimo que o tempo de carga e inicializaçăo das classes tenha caído para menos da metade do original.
Estes resultados mostram que os ofuscadores de bytecode săo muito interessantes mesmo quando năo existe necessidade de proteçăo de Propriedade Intelectual. Até um software open source pode fazer bom proveito dessa ferramenta. (Aliás, se o código-fonte é fornecido, năo há nenhuma vantagem em fornecer os binários num formato que permita fácil engenharia reversa.) Os seguintes cenários indicam o uso de ofuscadores para simples otimizaçăo:
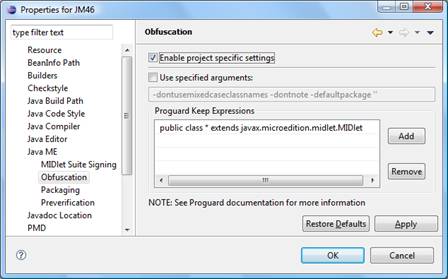
No caso específico de Java ME, o suporte integrado a ofuscadores chega a ser um recurso padrăo de IDEs, ver Figura 2. Infelizmente năo vejo esse suporte para projetos em outras categorias, onde o ofuscamento também poderia ser muito útil. De qualquer forma, o ProGuard também pode ser executado na linha de comando ou através de plugins para o Ant ou Maven.
O ofuscamento funciona realmente? Para tirar a prova, selecionei mais ou menos ao acaso um método do código-fonte original do Font2DTest. Compare as quatro versőes do código na Listagem 2. (Em cada caso, exibo apenas a metade inicial do método, que é suficiente para a discussăo.) As versőes descompiladas foram geradas com o JAD (Java Decompiler), um descompilador gratuito disponível em www.kpdus.com/jad.html.
Listagem 2. Método avaliado par ofuscamento.
/// Resets the scrollbar to display correct range of text currently on screen
/// (This scrollbar is not part of a "ScrollPane". It merely simulates its effect by
/// indicating the necessary area to be drawn within the panel.
/// By doing this, it prevents creating gigantic panel when large text range,
/// i.e. CJK Ideographs, is requested)
private void resetScrollbar( int oldValue ) {
int totalNumRows = 1, numCharToDisplay;
if ( textToUse == RANGE_TEXT || textToUse == ALL_GLYPHS ) {
if ( textToUse == RANGE_TEXT )
numCharToDisplay = drawRange[1] - drawRange[0];
else /// textToUse == ALL_GLYPHS
numCharToDisplay = testFont.getNumGlyphs();
totalNumRows = numCharToDisplay / numCharAcross;
if ( numCharToDisplay % numCharAcross != 0 )
totalNumRows++;
if ( oldValue / numCharAcross > totalNumRows )
oldValue = 0;
verticalBar.setValues( oldValue / numCharAcross,
numCharDown, 0, totalNumRows );
}
private void resetScrollbar(int i)
{
int j = 1;
if(textToUse == 0 || textToUse == 1)
{
int k;
if(textToUse == 0)
k = drawRange[1] - drawRange[0];
else
k = testFont.getNumGlyphs();
j = k / numCharAcross;
if(k % numCharAcross != 0)
j++;
if(i / numCharAcross > j)
i = 0;
verticalBar.setValues(i / numCharAcross, numCharDown, 0, j);
}
private void b(int i1)
{
int j1;
if(i.g(D) == 0 || i.g(D) == 1)
{
int k1;
if(i.g(D) == 0)
k1 = i.i(D)[1] - i.i(D)[0];
else
k1 = i.b(D).getNumGlyphs();
j1 = k1 / a;
if(k1 % a != 0)
j1++;
if(i1 / a > j1)
i1 = 0;
i.j(D).setValues(i1 / a, b, 0, j1);
}
private void a(int i1)
{
int j1;
i k1;
if((k1 = a_i_fld).f_int_fld == 0 || (k1 = a_i_fld).f_int_fld == 1)
{
i l1;
int i2;
if((l1 = a_i_fld).f_int_fld == 0)
i2 = (l1 = a_i_fld).a_int_array1d_fld[1] –
(l1 = a_i_fld).a_int_array1d_fld[0];
else
i2 = ((i) (i2 = a_i_fld)).a_java_awt_Font_fld.getNumGlyphs();
j1 = i2 / a_int_fld;
if(i2 % a_int_fld != 0)
j1++;
if(i1 / a_int_fld > j1)
i1 = 0;
((i) (i2 = a_i_fld)).a_javax_swing_JScrollBar_fld
.setValues(i1 / a_int_fld, b_int_fld, 0, j1);
}
A primeira descompilaçăo, feita a partir do bytecode original, difere dos fontes só pela falta da formataçăo original, comentários, nomes de variáveis locais e parâmetros (o demo deve ter sido compilado com javac –g:none), e constantes (como RANGE_TEXT ® 0). Mas o significado do código ainda é fácil de deduzir, devido ŕ presença de muitos identificadores como resetScrollbar, textToUse, testFont, numCharsAcross, etc.; e ŕ recuperaçăo da estrutura do código perfeita.
Na segunda descompilaçăo, feita sobre o bytecode ofuscado, quase todos estes nomes foram eliminados, sendo substituídos por outros sem qualquer significado – b, i1, i, g, etc. Os únicos nomes significativos que restaram foram getNumGlyphs e setValues, mas com tăo pouca ajuda, fica muito mais difícil entender um método tăo complexo. Note também que o ofuscador fez algumas alteraçőes na estrutura do código: por exemplo, textToUse == 0 virou i.g(D) == 0.
A última descompilaçăo foi feita para o bytecode ofuscado com algumas opçőes extra: Overload aggressively, Repackage classes, Allow Access Modification, e Merge interfaces aggressively. Estas opçőes permitem embaralhar ainda mais o código. Por exemplo, o trecho textToUse == 0 foi agora transformado em (k1 = a_i_fld).f_int_fld == 0. Isso vai confundir quem tentar entender o código.
[nota] As otimizaçőes e ofuscamentos mais simples săo basicamente manipulaçőes do Constant Pool: a ferramenta altera o valor de símbolos que representam classes e outros artefatos, substituindo os Asciz com nomes descritivos por outros menores e sem nenhum significado. Também reduzem o número de constantes, quando conseguem compartilhar o mesmo nome entre vários elementos da mesma classe. Mas as otimizaçőes/ofuscamentos mais agressivos realizam transformaçőes pesadas na seqüęncia de bytecodes dos métodos, inclusive fazendo “refactorings” como criar, mesclar ou eliminar métodos, introduzir ou eliminar parâmetros, mudar a ordem de parâmetros, e até coisas muito piores. [/nota]Nosso código está protegido? Mesmo na última listagem, um programador que tenha bom conhecimento do domínio (no caso, código de GUIs) ainda conseguirá deduzir a funçăo do método. Mas é óbvio que isso demandará um esforço muitíssimo maior de estudo dos fontes; se soubermos o que o método deve fazer, pode ser mais fácil escrevę-lo do zero do que tentar recuperar fontes inteligíveis a partir de um código tăo ofuscado. Por isso, minha resposta é “Sim”. Para detalhes, veja novamente o quadro “A Necessidade de Ofuscamento”.
Dois cuidados básicos devem ser tomados com estas ferramentas. O primeiro é năo ofuscar demais. Ao ofuscar as classes que pertencem a determinado grupo (ex.: um único jar, ou um conjunto de jars ofuscados em conjunto), vocę năo deve alterar a assinatura de nenhuma classe, método ou atributo que seja acessível de fora daquele grupo. Entăo, se o seu util.jar contém uma API pública Util.fazTudo(), vocę năo pode mudar o nome deste método (ou reduzir sua visibilidade para private), pois isso “quebraria” outros componentes ou aplicaçőes que o utilizam. O mesmo vale para código seu que estende algum framework externo: por exemplo, se na sua implementaçăo de algum componente Swing, vocę tiver um método paint(Graphics), năo pode permitir que este método seja renomeado, caso contrário este deixará de ser uma redefiniçăo de JComponent.paint(Graphics), e sua aplicaçăo deixará de funcionar corretamente. Para evitar problemas deste tipo, ofuscadores possuem várias espertezas, como năo mexer em assinaturas de métodos que redefinem métodos definidos em classes externas ao conjunto sendo ofuscado. Também permitem especificar regras de exclusăo, para proteger classes, métodos ou atributos especificados do ofuscamento.
[nota] Cuidado especial com reflection. Se vocę acessa classes, métodos ou atributos dinamicamente, com APIs como Class.forname(), getMethod() etc., vocę terá que dar uma “măozinha” ao ofuscador, fornecendo regras de exclusăo que impeçam o ofuscamento de qualquer nome de classe, método ou atributo manipulável através de reflection. Caso contrário, o resultado será um erro como ClassNotFoundException ou NoSuchMethodException. [/nota]O segundo problema é que o ofuscamento pode complicar o suporte de aplicaçőes em produçăo. Se a aplicaçăo estiver instrumentada para logar exceçőes imprevistas, o código ofuscado terá um stack trace bem confuso – por exemplo, mostrando uma NullPointerException num método b(int).
Como saber que isso se refere ao método resetScrollbar(int)?
Simples, no ProGuard existe uma opçăo de gerar um arquivo de mapeamento entre os nomes originais e os obfuscados. De posse destes arquivos, vocę pode posteriormente usar a funçăo “ReTrace” para desembaralhar um stack trace. É óbvio que tais arquivos de mapeamento devem ser mantidos privados, năo distribuídos.
Finalmente, os níveis mais agressivos de ofuscamento e otimizaçăo podem ter impacto no desempenho do código. Este impacto pode ser tanto positivo quanto negativo. Algumas transformaçőes de bytecode que podem parecer custosas, como a introduçăo de novos métodos, podem năo custar nada por serem compensadas por otimizaçőes da JVM como inlining – mas é arriscado confiar nisso de olhos fechados. Em contrapartida, as melhores ferramentas săo capazes de realizar no próprio bytecode algumas otimizaçőes que normalmente só săo feitas por compiladores JIT, tais como eliminaçăo de expressőes redundantes, propagaçăo de constantes, etc. (O javac é conhecido por năo fazer praticamente nenhuma otimizaçăo, e isso é assim por design.) O aconselhável, para código com características críticas de desempenho, é fazer benchmarks e comparar o desempenho do bytecode original com o ofuscado/otimizado, para garantir que năo há nenhuma regressăo.
Ofuscadores evitam que seu código compilado seja muito fácil de ler. Como vimos, os arquivos .class do Java săo quase tăo fáceis de entender quanto os fontes originais. Mesmo que vocę năo conheça a sintaxe do bytecode, basta usar um descompilador como o JAD (www.kpdus.com/jad.html). Isso é obviamente um problema para softwares proprietários, de fonte fechado.
Os ofuscadores contornam o problema realizando uma série de alteraçőes no bytecode. Informaçőes de debug (como nomes de variáveis locais e linhas de código) săo totalmente eliminadas. Nomes descritivos de classes, métodos e atributos, como validaConta(), săo substituídos por nomes aleatórios, como k8(). A estrutura de controle também pode ser bastante “embaralhada”. Por exemplo, um código como este:
public void algoritmoSecreto () {
if (x > y) {
a += 10;
}
}
Pode ser substituído por algo como:
private void a () {
a += 10;
while (x - 1 < y) {
b();
break;
}
}
private void b () {
a -= 10;
}
Terá exatamente o mesmo efeito, mas é muito mais confuso e dificulta a compreensăo de algoritmos e regras de negócio. Além de fazer transformaçőes de controle e eliminar o nome original do método, o ofuscador também criou um novo método (um refactoring), e transformou o método original public em private (o que só é válido se este método năo era invocado de nenhuma outra classe).
Estes truques de ofuscamento năo impedem totalmente a engenharia reversa do código, porém, nenhuma técnica impede isso. Até para código nativo há descompiladores, que geram listagens em Assembly bem estruturado, ou até mesmo em C (ver http://www.itee.uq.edu.au/~cristina/dcc.html). Na prática, o bytecode Java (bem ofuscado!) năo é muito pior que código nativo. Hackers interessados em plagiar software, ou criar vírus e outros malwares (tarefa que muitas vezes exige descompilar até o kernel do S.O. a ser atacado), năo săo impedidos por nenhum formato executável. Nem por alguns produtos (tanto ofuscadores Java quanto “protetores” de código nativo) que encriptam o código. Essa técnica torna o trabalho mais difícil, mas ainda assim possível, pois o código precisa ser decriptado para ser executado. Basta conferir a disponibilidade de “cracks” para qualquer aplicaçăo, game, ou padrăo de DRM popular. A proteçăo absoluta de Propriedade Intelectual digital, com mecanismos puramente de software, é impossível.
Ainda assim, o ofuscamento pode reduzir o problema do nível qualquer novato em Java consegue ler o código e entender os algoritmos em 10h para o nível somente um expert consegue ler o código, e mesmo assim, levará 300h para desembaralhar os algoritmos. Para a maioria das finalidades, isso é proteçăo suficiente (tornar a engenharia reversa economicamente pouco compensadora).
Uma questăo comum: o bytecode năo poderia ter um formato mais difícil de entender? Isso seria possível, e é o caso de linguagens antigas como UCSD Pascal e Forth. Mas as linguagens “virtuais” modernas possuem recursos de runtime dinâmicos, como reflection, suporte a debugging e profiling, serializaçăo, geraçăo e transformaçăo dinâmicas de código e outros, que exigem um formato binário de alto nível e que inclui informaçăo simbólica detalhada. Por isso, é difícil ofuscar aplicaçőes ou APIs que fazem uso intenso destes recursos dinâmicos. Tipicamente, deve-se fornecer ao ofuscador uma lista de nomes de classes, métodos e atributos que năo podem ser ofuscados.
Tudo isso vale igualmente para a plataforma .NET, cujo bytecode é igualmente fácil de ler. E provavelmente, para qualquer outro padrăo de bytecode / código portável.
O bytecode do Java foi um dos seus chamarizes desde o lançamento da plataforma, devido ŕ vantagem da portabilidade. Outras vantagens se acumularam com o tempo, como bom desempenho (graças a compiladores JIT avançados) e capacidades de programaçăo dinâmica, inclusive geraçăo fácil e eficiente de classes em demanda.
Por outro lado, a facilidade de ler o bytecode sempre foi uma preocupaçăo para quem năo quer compartilhar seus algoritmos com olhares curiosos; e o tamanho do bytecode nunca é suficientemente enxuto, para quem deseja transferi-lo pela internet ou instalá-lo em dispositivos Java ME com limitaçőes de tamanho de MIDlets. Estas necessidades deram origem ŕ criaçăo de ferramentas de ofuscamento e otimizaçăo de bytecode; as quais evoluíram junto com os descompiladores, numa verdadeira competiçăo de gato-e-rato. Como um descompilador possui alguns limites impossíveis de eliminar, por exemplo, năo tem como deduzir nomes descritivos de elementos do programa, meu veredito (também baseado na análise das ferramentas) é que a briga foi vencida pelos ofuscadores, os quais oferecem um nível aceitável de proteçăo de Propriedade Intelectual, para quem precisa disso.
Uma nota final: muitos softwares proprietários possuem licenças de uso que proíbem expressamente qualquer técnica de engenharia reversa, inclusive e especialmente a descompilaçăo do bytecode (ou mesmo a visualizaçăo do bytecode puro com o javap). Isso é uma infelicidade; eu mesmo já fui obrigado a ignorar estas licenças, e descompilar assim mesmo, em várias ocasiőes em que tive que diagnosticar bugs difíceis, que acabei descobrindo que eram bugs em alguma biblioteca proprietária (sem fontes abertos, porém năo ofuscada). Mas antes que alguém venha me processar por tabela, fica o pedido ao leitor: “faça o que eu digo, năo faça o que eu faço” – năo descompile programas cujos termos de licença proíbem fazę-lo.
Hardwired: Comportamento que é “amarrado” no código, năo sendo possível modificá-lo sem alterar os fontes, recompilar e reiniciar a aplicaçăo. O termo costuma ser aplicado a coisas que poderiam facilmente ser parametrizadas externamente (por arquivo de configuraçăo, descritor, etc.) – por exemplo, a URL de conexăo com a database da aplicaçăo – mas năo o săo por algum motivo. Pode ser um mau motivo como preguiça ou indisciplina do programador, ou um bom motivo como otimizaçăo (é o caso dos bytecodes com parâmetros fixos como aload_0) ou simplicidade (comum em código para artigos, que deve ser didático). No Brasil, outra traduçăo que gosto de hardwired é “chumbado”.

Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.