


Em uma pesquisa, ao pedir que desenvolvedores de software respondessem a uma pesquisa sobre seu cotidiano e suas perspectivas profissionais, foram constatados dois dados importantes:
· A grande maioria destes profissionais, além de escrever código-fonte, também é responsável pela realizaçăo de outras tarefas, a exemplo: levantar requisitos, participar de reuniőes com clientes, executar testes, ministrar treinamentos e documentar artefatos;
· Cerca de 90% revelaram sentir maior motivaçăo ao exercitar a criatividade com problemas de maior (ou nova) complexidade, do que em realizar tarefas que já dominam e que năo apresentam novos desafios.
Entretanto, esta exigęncia por um perfil de profissional flexível, com vasta bagagem de conhecimento e também capacidade de investigar soluçőes para os problemas apresentados năo é suficiente para melhorar a estatística geral sobre o desenvolvimento de software. Anualmente é publicado o Chaos Report, pelo The Standish Group, cujo objetivo é expor a estatística de sucesso em projetos dessa natureza. A versăo 2013 do Chaos Report informa que 39% dos projetos de software iniciados em 2012 foram concluídos com sucesso, porém 18% foram considerados fracassos (năo săo finalizados ou nunca săo usados) e 43% sofrem com algum problema (atrasam a entrega, extrapolam o orçamento e/ou năo atendem aos requisitos). Ou seja, em 61% dos casos coletados na amostra, o resultado final năo foi o esperado.
Entăo a pergunta feita neste artigo é: como manter motivado um profissional (que se sente estimulado quando surge um novo desafio) e também entregar os projetos de software aos clientes no prazo e qualidade prometidos?
O alvo deste artigo săo os projetos de software envolvendo bancos de dados. A proposta é a de automatizar a escrita de código-fonte, mais precisamente, o que é escrito para tarefas conhecidas pela sigla CRUD (Create, Read, Update, Delete) a qual representa as quatro principais operaçőes com bancos de dados: Criar, Ler, Atualizar e Excluir dados.
Entretanto, gerar código para funcionalidades do tipo CRUD năo é bem uma novidade. Já existem ferramentas capazes de realizar tal tarefa, a exemplo: AspMaker, PhpMaker e MyGeneration. Tais ferramentas permitem que, em poucos cliques, sejam gerados código-fonte para cada tabela de um banco de dados, porém geram este código com as particularidades específicas de quem fabricou a ferramenta. Ou seja, o desenvolvedor terá de esquecer o seu próprio legado de trabalho (exemplo: sua biblioteca pessoal de métodos e classes, sua camada de persistęncia de dados) para adotar o código de terceiros caso opte por usar uma dessas opçőes.
Adotar um código pronto, porém escrito de forma totalmente diferente ao que se está acostumado, demanda do desenvolvedor tempo para seu aprendizado. Tal aprendizado (principalmente em futuras manutençőes da aplicaçăo gerada) poderá ser mais dispendioso do que escrever todo o CRUD sem o uso de ferramentas.
Além disso, sabe-se que um programador experiente năo está disposto a esquecer seu próprio código para adotar um novo totalmente diferente. Forçar um desenvolvedor a fazer isso com certeza o desanimaria. Da mesma forma, uma fábrica de software, com dezenas de projetos já prontos, dificilmente estaria disposta a mudar o seu legado de codificaçăo de programas somente para manter um padrăo conivente com o que é gerado pela ferramenta.
A proposta deste artigo visa a reduçăo de tarefas repetitivas, ainda realizadas por muitos desenvolvedores. Para isso, apresenta como soluçăo o conceito e prática da geraçăo de CRUD por templates. O uso de templates permitirá gerar CRUDs personalizados de acordo as preferęncias de cada desenvolvedor de software (linguagem de programaçăo, métodos já conhecidos, bibliotecas do próprio desenvolvedor ou da própria fábrica de software), acelerando a escrita de código sem comprometer seu entendimento. Esta sugestăo está alinhada com a pesquisa sobre o perfil do profissional desenvolvedor de software, que revela que estes preferem realizar tarefas de maior desafio, envolvendo pesquisa ou novas aptidőes, do que executar trabalhos rotineiros. Em outras palavras: se o profissional puder gastar menos tempo com a escrita de código CRUD, terá mais tempo disponível para cuidar de atividades mais específicas que o sistema exigir. Uma vez que o desenvolvedor criou o seu primeiro CRUD, bastaria transformá-lo em um template e assim novos passariam a ser gerados com menos esforço e tempo.
A relaçăo entre automatizar e dividir tarefas
Acelerar processos por meio da automatizaçăo de tarefas pode ser relacionado com uma teoria antiga, escrita em 1776 por Adam Smith, a qual afirma que a divisăo do trabalho em tarefas e a consequente especializaçăo das mesmas podem aumentar, drasticamente, a quantidade de produtos produzidos pelas fábricas.
De fato, ao automatizar parte da escrita de um código, há uma divisăo deste trabalho em dois tipos de tarefas: as repetitivas (codificaçăo de CRUD - que poderăo ser geradas automaticamente) e as específicas da soluçăo (que deverăo ser executadas pelas pessoas). Uma vez que os desenvolvedores năo precisem mais se preocupar com as tarefas repetitivas, estes podem se dedicar mais ŕquelas que săo específicas (exemplo: programaçăo de regras de negócio, pesquisa de soluçőes para um problema) o que, consequentemente, influenciará positivamente no sucesso do projeto.
Construçăo de uma ferramenta que gere códigos CRUD por template
A estrutura que será descrita é baseada na experięncia do autor enquanto desenvolvedor de software (trabalhando em fábrica de software e também com empresa própria), o que posteriormente gerou uma ferramenta que está em fase de registro no Instituto Nacional da Propriedade Intelectual (IPNI) com o número de processo BR512015000256-2.
As tecnologias utilizadas na construçăo da ferramenta que será descrita foram: o .NET Framework e a linguagem XML. Para exemplificar seu uso, faremos a geraçăo de código na linguagem PHP.
As primeiras anotaçőes
No momento em que um desenvolvedor, que já possui suas bibliotecas e outros sistemas já prontos, decide criar um CRUD para uma tabela do banco de dados do seu sistema, é possível perceber o seguinte padrăo de tarefas que ele realiza:
1. O uso dos comandos copiar/colar para trazer ŕ pasta do seu projeto seus arquivos contendo a biblioteca de código que utiliza, a exemplo: arquivos JavaScript, arquivos compilados contendo procedimentos úteis, arquivos com funçőes de terceiros, imagens para o projeto e arquivo CSS (esta açăo ocorre principalmente quando um novo programa está sendo feito e ainda năo possui funcionalidade desenvolvida);
2. O uso dos comandos copiar/colar para trazer um arquivo de uma funcionalidade já pronta (exemplo: um arquivo contendo a funcionalidade de cadastrar e editar um registro de uma tabela, em linguagem PHP, já utilizado em outro projeto);
3. O desenvolvedor manipula o arquivo copiado no item 2 (que acaba servindo de modelo para uma nova funcionalidade), alterando onde julgar necessário, para assim gerar um novo arquivo capaz de realizar a persistęncia em outra tabela de seu banco de dados. Dentro dessa necessidade de alterar esse arquivo, basicamente săo executadas as seguintes açőes:
3.1. Mantém inalterados alguns elementos do código como chamadas a bibliotecas comuns, cabeçalhos de métodos, elementos de layout (que săo comuns em toda a sua regra de negócio), inclusăo de arquivos comuns a toda a sua aplicaçăo e etc.;
3.2. Altera (remove, com critério, e digita novas informaçőes) outros elementos do código, como: a persistęncia das informaçőes no banco de dados, o carregamento dos mesmos na tela, a validaçăo de obrigatoriedade dos campos, além de implementar as regras de negócio específicas para aquela “tela” (funcionalidade).
A chave para identificar as tarefas que podem ser automatizadas é ter a atençăo no item 3 da lista onde, certamente, está a maior parte do trabalho. Entretanto, apesar da possibilidade de poupar esforço, é necessário ter a conscięncia de que năo será possível, somente pela geraçăo de código-fonte de forma automática, abranger todas as necessidades de uma aplicaçăo. O desenvolvimento de software sempre será um trabalho com características “artesanais”, por exemplo: as regras de negócio específicas da aplicaçăo precisarăo ser implementadas caso a caso.
Alguns programadores já fazem uso de pequenos scripts para automatizar a digitaçăo. Geralmente săo scripts que dependem das colunas existentes em uma tabela para gerar algum código. Um exemplo é apresentado logo a seguir: trata-se de uma consulta em linguagem T-SQL (elaborada para ser executada no SQL Server) cujo objetivo é imprimir código capaz de criar variáveis em PHP com os mesmos nomes de colunas de uma tabela chamada “projeto”:
select '$'+name + ' =
@$_POST["'+name+'"]; ' as
codigo_gerado from sys.columns
where object_name( object_id ) = 'projeto'Esse comando define uma consulta para a tabela <em>sys.columns</em> a qual, quando executada, imprime os nomes das colunas da tabela chamada “projeto”. Estes nomes săo concatenados com código da linguagem PHP. O resultado deste comando é a impressăo do código exibido na Listagem 1
Listagem 1. Resultado do comando TSQL: Impressăo de um código PHP.
$ID = @$_POST["ID"];
$pastadestino = @$_POST["pastadestino"];
$pastatemplate = @$_POST["pastatemplate"];
$projeto = @$_POST["projeto"];
$tecnologia = @$_POST["tecnologia"];
$template = @$_POST["template"];
Essa listagem mostra um código em PHP que, se executado, criará variáveis com o mesmo nome das colunas existentes na tabela. Para indicar o valor de cada uma, é escrita a chamada para outra variável $_POST, sendo seus índices também identificados pelo nome das colunas existentes no banco de dados.
Baseado nesta técnica, pode-se concluir que ao permitir que vários destes trechos de código sejam gerados somente levando em conta o nome da coluna de sua tabela, já é possível poupar algum tempo em digitaçăo.
A partir deste conceito, torna-se necessário armazenar tais scripts de forma a permitir seu reaproveitamento. Podemos fazer isso através de variáveis. Assim, podemos armazenar o código que resultará na Listagem 1, porém usando uma variável para representar o nome de cada coluna (que é a informaçăo que mudará). Este código armazenado seria “formatado” para cada registro retornado. Este armazenamento pode ser visto no código a seguir:
${field_name} = @$_POST["{fieldname}"];Conjunto gerador de CRUD
A soluçăo proposta é chamada de Conjunto Gerador de CRUD – CGC – o qual é composto por duas partes: o template e a aplicaçăo geradora de código CRUD. Ambos săo inúteis se usados separadamente, entretanto, săo tratados como itens distintos uma vez que a aplicaçăo poderá operar com vários templates. Cada template conterá definiçőes específicas para a linguagem de programaçăo adotada no projeto e será baseado em um CRUD (modelo) já existente. Uma visăo geral da soluçăo pode ser vista na Figura 1.
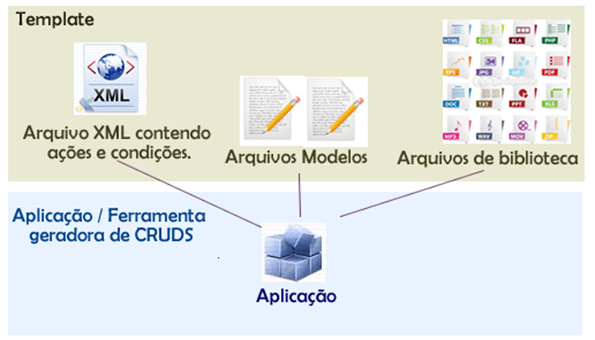
Figura 1. Conjunto gerador de CRUD – CGC.
O template é formado pelos seguintes itens: arquivo XML (de açőes e condiçőes), arquivos modelos e arquivos de bibliotecas. Os arquivos de bibliotecas săo aqueles fixos de um projeto. Eles podem conter configuraçőes ou funçőes prontas (exemplo: arquivos JavaScript, CSS e imagens).
O arquivo XML contendo açőes e condiçőes surge a partir da necessidade de armazenamento de trechos de código. O arquivo XML é composto por um conjunto de açőes, em que cada uma está identificada por uma tag (rótulo), e cada açăo é composta por suas próprias condiçőes. O exemplo de uma açăo contendo duas condiçőes armazenadas neste arquivo XML pode ser visto na Listagem 2.
Listagem 2. Açăo e condiçăo no arquivo XML.
<headergrid separator ="\r\n" >
<when condition=" primarykey = 1 ">
<![CDATA[header_primary_key]]>
</when>
<when condition=" 1 = 1 ">
<![CDATA[header]]>
</when>
<format>
<![CDATA[
<th align="center" class="#when#">{label}</th>
]]>
</format>
</headergrid>
No exemplo mostrado, uma tag de nome headergrid identifica uma açăo, e sua estrutura é composta por outras duas sub-tags (when e format) além de uma sub-variável #when#, explicadas na Tabela 1.
|
Nome |
Tipo |
Detalhes |
Exemplo |
|
(Nome da propriedade) exemplo: headergrid |
Açăo – Tag XML. Engloba tudo o que é referente ao seu trecho de código. |
Representa uma açăo. Seu nome pode ser qualquer um desejado e suporta uma propriedade chamada “separator”. |
...... |
|
when |
Condicional – Sub-Tag XML |
Permite indicar condiçőes que serăo testadas (as mesmas variáveis que săo colocadas nos trechos de código podem ser utilizadas dentro da sua propriedade condition). Quando sua condiçăo é satisfeita, o seu conteúdo passa ser utilizado como o trecho de código. Cada açăo pode englobar inúmeros condicionais when. |
(….) |
|
format |
Facilitador – Sub-Tag XML |
Pode ser usada para englobar trechos de código que contęm conteúdo do condicional when que estiver sendo satisfeito. |
O condicional satisfeito para {field_name} é #when# |
|
#when# |
Sub-variável com escopo local. Existe apenas dentro da tag |
Representa o resultado obtido dos condicionais nas tags . Existe apenas dentro da tag . |
Tabela 1. Estrutura utilizada em uma tag de açăo.
A sub-tag when faz alusăo ao comando “Case When” utilizado em bancos de dados. No template, seu funcionamento é similar ao usado nos SGBDs: testar várias condiçőes em um mesmo bloco de código – uma mesma tag.
O resultado esperado será a escrita de uma célula (de uma tabela) HTML. Porém, se a coluna que o repetidor estiver lendo for uma chave primária, terá uma classe de estilo Cascade Style Sheets (CSS) diferente das demais. Além da condiçăo, outras variáveis săo utilizadas: {primarykey} que indica 0 ou 1 se a coluna testada é uma chave primária e {label} que representa um nome amigável que o usuário queira dar para aquela coluna no banco de dados.
Além de condiçőes e açőes, outras informaçőes também estăo contidas neste arquivo XML: quais săo os arquivos modelo (para gerar o CRUD baseado neles) e as opçőes de tipos de entrada de dados possíveis para interaçăo com o usuário final (exemplo: TextBox, TextArea, DropDownList, ou qualquer outra entrada criada e customizada pelo próprio usuário criador do template).
Os arquivos de modelo săo aqueles que representam as funcionalidades de um CRUD e que serăo lidos para gerar novos arquivos. Um arquivo modelo é um arquivo misto que contém variáveis, açőes e código-fonte final (é um arquivo originário de um código de CRUD que já funcionava). A Figura 2 exibe um exemplo deste tipo de arquivo onde os retângulos vermelhos representam variáveis e os retângulos azuis săo nomes de açőes armazenadas no arquivo XML do template.

Figura 2. Arquivo modelo com variáveis, açőes e código-fonte.
A aplicaçăo geradora de CRUD
A composiçăo da aplicaçăo geradora de CRUDs pode ser vista na Figura 3. Esta aplicaçăo foi desenvolvida com a tecnologia .NET utilizando os módulos para aplicaçőes Windows, sendo dividida em quatro funcionalidades:
· Leitor de Banco de dados: É a parte responsável por trazer informaçőes do banco de dados que será o alvo do CRUD. Estas informaçőes compreendem: suas tabelas, colunas, informaçőes específicas de cada coluna (exemplo: nome, tipo de dado, tamanho do dado, comentário, se permite valor nulo, chaves estrangeiras). Nesta aplicaçăo foi implementada a leitura dos bancos SQL Server, MYSQL e PostgreSQL;
· Leitor de Template: Consiste na leitura do arquivo XML de açőes e condiçőes;
· Parametrizador: Recebe os dados do leitor de banco de dados e do template e utiliza-os para que o usuário possa alterar ou adicionar informaçőes sobre cada coluna das tabelas do banco de dados. Estas informaçőes, colocadas em cada coluna, passam a fazer parte das variáveis que săo utilizadas nas açőes criadas e nos arquivos modelo. A tela do parametrizador pode ser vista na Figura 4;
· Repetidor: Responsável por substituir as variáveis e açőes por código, gerando CRUD para as tabelas indicadas no parametrizador.
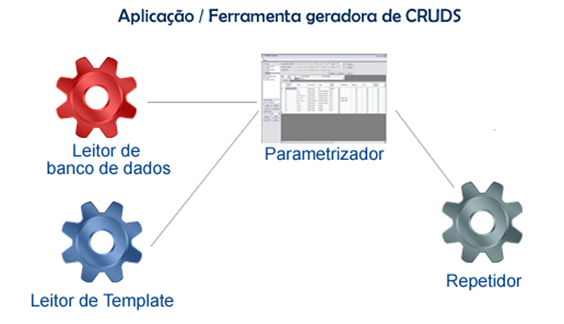
Figura 3. Estrutura da aplicaçăo geradora de CRUD.
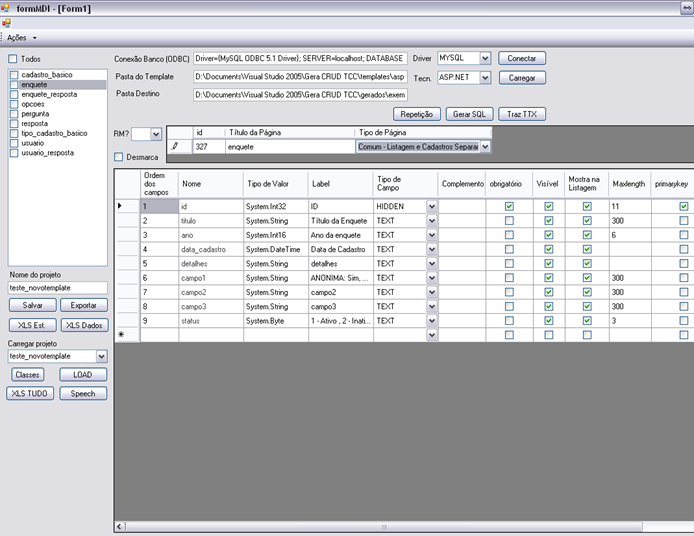
Figura 4. Parametrizador.
Os principais elementos exibidos na Figura 4 săo:
1. Campo para informar o caminho do template que será utilizado. Ao carregar o template, o arquivo XML lido (por padrăo, foi chamado de actions.xml) contém as açőes e tipos de opçőes para entrada de dados;
2. Campo para informar a conexăo ODBC para o banco de dados;
3. Caixa de listagem (CheckBoxList ŕ esquerda) para selecionar qual tabela do banco de dados carregado se deseja parametrizar;
4. Dados da tabela selecionada. Săo exibidos o nome da tabela, o nome amigável da mesma (chamado de título da página – que vira uma variável: {table_title}) e o tipo de CRUD (chamado de tipo de página) que se deseja usar;
5. Os botőes: e (para ser útil como um dicionário de dados do projeto);
6. Uma tabela contendo as colunas carregadas com seus dados padrăo (nome, tipo de valor, comentário, se é nulo, se é chave primária). Está mesma tabela permite que o usuário altere estas informaçőes, as quais completarăo a lista de variáveis disponíveis para uso no template.
Para implementar a leitura de vários bancos de dados foi utilizada a tecnologia ODBC (Open Database Connectivity) e o design pattern bridge (ponte). O ODBC faz uma boa parte do trabalho, sendo capaz de ler tabelas e colunas de um SGBD (basta que utilize o driver correto). O padrăo de projetos surge da necessidade de enviarmos comandos específicos para cada banco de dados a fim de obter mais detalhes sobre cada coluna de suas tabelas (exemplo: chaves estrangeiras, tamanho em caracteres da coluna e se a mesma aceita valor nulo).
Resultados
Nesta seçăo săo apresentados os resultados do uso do GCG. Para isso, foi feita uma avaliaçăo de tempo com o uso dessa soluçăo e uma pesquisa de opiniăo com desenvolvedores de software a fim de avaliar se a ideia principal, que é automatizar tarefas repetitivas, pode ser aceita.
Avaliaçăo de tempo com o uso da ferramenta GCG
A fim de avaliar a eficięncia da ferramenta, foi feito um experimento para comparar o tempo gasto na criaçăo de dois novos CRUDs (um considerado simples e outro completo). Cada CRUD criado foi desenvolvido primeiro sem a ferramenta e depois com ela. O voluntário foi um Coordenador de TI, com experięncia em programaçăo, infraestrutura e liderança de equipes. Acompanhando seu trabalho, cada tempo foi registrado e o resultado é mostrado na Tabela 2.
|
Tipo de Funcionalidade |
Tempo de desenvolvimento sem a ferramenta |
Tempo de desenvolvimento com a ferramenta |
Ganho |
|
Simples - 8 campos de entrada de dados. |
3h30min |
1h30min |
57% |
|
Complexa – 32 campos de entrada de dados envolvendo 5 tabelas. |
5 dias (40 horas) |
3 dias (24 horas) |
40% |
Tabela 2. Resultados do experimento de tempo.
Foi levada em consideraçăo a funcionalidade completamente pronta, ou seja, atendendo aos requisitos de persistęncia (CRUD) e as suas regras de negócio específicas. Após gerar o CRUD, houve a necessidade de alteraçőes para adequaçăo ŕs regras de negócio. Mesmo assim o uso da ferramenta demonstrou um ganho de tempo a partir de 40%.
O template utilizado foi para a linguagem ASP.NET com C#, o qual demorou 10 horas para ser elaborado e testado (criado a partir de outro CRUD existente).
Os CRUDs utilizados neste estudo foram classificados como simples ou complexo baseado na quantidade de campos para entrada de dados e na quantidade de tabelas que precisavam ser manipuladas de alguma forma (consulta ou subcadastro) na tela que estava sendo feita. Este raciocínio é o mesmo do utilizado em contagem por pontos de funçăo.
Pesquisa de opiniăo
Um grupo contendo 32 desenvolvedores de software foi convidado a responder uma pesquisa de opiniăo on-line cujo título foi: “Perspectivas profissionais dos desenvolvedores de software”. O objetivo desta pesquisa foi avaliar as preferęncias destes profissionais quanto a tarefas realizadas em seu cotidiano.
O perfil de profissionais que responderam ŕs perguntas compreende: desenvolvedores e analistas de sistemas, entre 21 a 41 anos, com tempo de experięncia entre 1 a 13 anos, trabalhando (todo ou parte do tempo) com programaçăo de sistemas em plataformas desktop, web ou dispositivos móveis. Estes profissionais, quanto ao mercado de atuaçăo, compreendem microempresários e funcionários de empresas públicas e privadas. O resultado da pesquisa foi:
· 87% dos profissionais, além de programar, executam outras tarefas complementares ao desenvolvimento de software;
· 87% revelaram que se sentem confortáveis em executar outras tarefas que năo envolvem programaçăo;
· 19% năo gostam de desenvolver software e gostariam de realizar outra atividade;
· Apenas 7% se veem de forma confortável realizando tarefas cotidianas;
· 90% revelou que prefere exercitar a criatividade com problemas de maior desafio, do que realizar tarefas que já dominam e que năo apresenta novos problemas;
· 30% das tarefas realizadas por estes profissionais săo CRUD e 27% săo consultas e relatórios.
As quatro açőes documentadas neste artigo (a investigaçăo, a criaçăo de um conjunto gerador de CRUD, a avaliaçăo comparativa de tempo e a pesquisa de opiniăo) revelaram dados positivos quanto ao retorno do esforço empregado em automatizar a criaçăo de código para CRUD.
O conjunto gerador de CRUD desenvolvido é a prova de que é possível gerar código customizado seguindo um template elaborado. Atualmente, os templates existentes servem para gerar CRUD nas linguagens ASP.NET (C#) e PHP. O objetivo é que esta abrangęncia cresça, atingindo mais linguagens e padrőes de projetos, através de templates desenvolvidos por qualquer desenvolvedor de software.
A avaliaçăo comparativa revelou que, usando o conjunto gerador de CRUD, é possível ter ganhos em economia de tempo no desenvolvimento de funcionalidades envolvendo banco de dados. Seus resultados revelam o potencial de utilidade da ferramenta.
Validando todo o esforço empregado na construçăo desta soluçăo, a pesquisa de opiniăo on-line revelou que a grande maioria dos desenvolvedores prefere gastar seu tempo em tarefas que envolvem maior complexidade e desafio do que em tarefas rotineiras (que podem ser automatizadas com o GCG). Traçar o perfil do profissional que desenvolve softwares é muito importante para saber o que o deixa motivado em seu dia a dia. A pesquisa revela que a grande maioria năo tem interesse em se acomodar programando apenas CRUDs.
DOMINGUEZ, Jorge. The Curious Case of the CHAOS Report 2009. 2009.http://www.projectsmart.co.uk/the-curious-case-of-the-chaos-report-2009.html
MICROSOFT. Microsoft Open Database Connectivity (ODBC). 2007.http://support.microsoft.com/kb/110093/pt-br
PHP GROUP. PHP Manual - $_POST 2013b.http://www.php.net/manual/en/reserved.variables.post.php
ROUSE, Margaret. CRUD cycle (Create, Read, Update and Delete Cycle). 2008.http://searchdatamanagement.techtarget.com/definition/CRUD-cycle
THE STANDISH GROUP. Chaos Manifesto 2013.http://versionone.com/assets/img/files/ChaosManifesto2013.pdf
Referęncias
BIENIEK, D., DYESS, R., HOTEK, M., LORIA, J., MACHANIC, A. MCTS: Microsoft SQL Server 2005 Implementation and Maintenance Study Guide: Exam 70-431. Redmond: Microsoft Press, 2006.
GASNIER, G. D. Guia prático para gerenciamento de projetos: manual de sobrevivęncia para o profissional de projetos. Săo Paulo: IMAM, 2000.
BOOCH, G., RUMBAUGH, J., JACOBSON, I. UML – guia do usuário. Rio de Janeiro: Editora Campus, 2006.
ROBBINS, S. P. Administraçăo mudanças e perspectivas. Săo Paulo: Saraiva, 2000.
WEBB, J. MCAD/MCSD Self Paced Training Kit: Developing Web Applications with Microsoft Visual Basic .NET and Microsoft C# .NET. Exams: 70-305 and 70-315. 2. ed. Redmond: Microsoft Press, 2002.


Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.