Existem no mercado diversos fabricantes com diferentes tipos de SGBDs prontos para atender a todo o tipo de necessidade, desde simples usuários a grandes empresas. O Firebird é um SGBD que surgiu do projeto Borland.
InterBase 6, possuindo a vantagem de ser Open Source e multi-plataforma. Atualmente apresenta-se como uma boa opçăo de banco de dados Cliente/Servidor, robusta e confiável, gerenciando grandes bancos de dados com bom desempenho e com conexőes simultâneas.
O Firebird é disponibilizado em tręs versőes:
Para isso, deve-se instalar o SGBD do Firebird com a opçăo SuperServer e instalar também a ferramenta IBExpert para auxiliar na manipulaçăo do banco de dados.
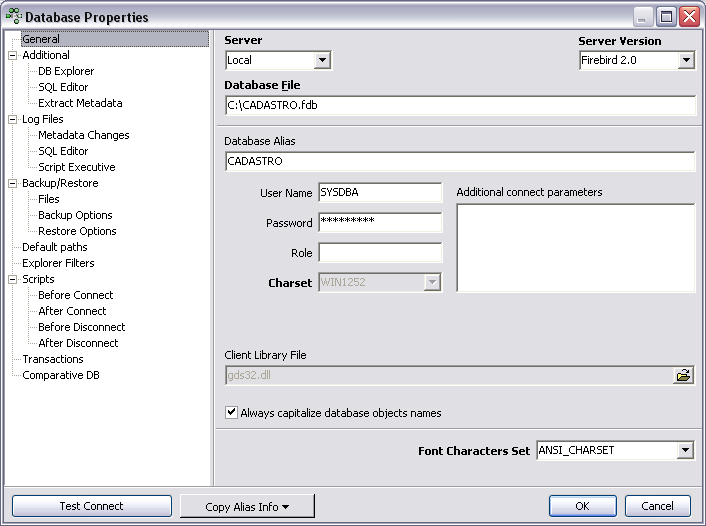
Primeiro, deve-se criar um banco de dados de exemplo. Utilizando o IBExpert, execute o script da Listagem 1 através do menu Tools > Script Executive > Run Script e depois registre o banco em Database > Register Database (ver Figura 1).
O campo Font Characters Set que aparece na Figura 1 é a configuraçăo da fonte da letra utilizada no IBExpert e năo interfere em nenhuma configuraçăo do banco de dados. No decorrer deste artigo, serăo abordadas cada uma das configuraçőes utilizadas no script para criaçăo do banco de dados de exemplo (ver Listagem 1) como Dialetos, Set Names, Page Size, Character Set e Collation utilizados.
Listagem 1. Script para a criaçăo do banco de dados de exemplo
/***********************************************************************/
SET SQL DIALECT 1;
SET NAMES WIN1252;
CREATE DATABASE 'C:\CADASTRO.fdb'
USER 'SYSDBA' PASSWORD 'masterkey'
PAGE_SIZE 4096
DEFAULT CHARACTER SET WIN1252;
/***********************************************************************/
CREATE TABLE PAISES (
CODIGO INTEGER NOT NULL,
NOME VARCHAR(50) COLLATE WIN_PTBR,
DATA_CADASTRO DATE);
INSERT INTO PAISES (CODIGO, NOME, DATA_CADASTRO) VALUES (1, 'África do Sul', '2007-08-25 00:00:00');
INSERT INTO PAISES (CODIGO, NOME, DATA_CADASTRO) VALUES (2, 'Alemanha', '2007-08-25 00:00:00');
INSERT INTO PAISES (CODIGO, NOME, DATA_CADASTRO) VALUES (3, 'Brasil', '2007-08-26 00:00:00');
INSERT INTO PAISES (CODIGO, NOME, DATA_CADASTRO) VALUES (4, 'Japăo', '2007-08-26 00:00:00');
COMMIT WORK;
/***********************************************************************/
ALTER TABLE PAISES ADD CONSTRAINT PK_PAISES PRIMARY KEY (CODIGO);
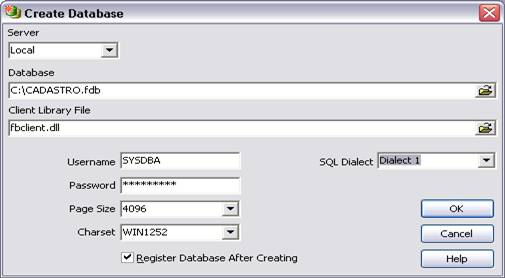
O Firebird baseia-se no conceito de dialetos para permitir utilizar novas características que năo săo compatíveis em versőes anteriores do SGBD, como caracteres delimitados por aspas duplas e campos dos tipos data e hora. O uso de dialetos ajuda diretamente nesta transiçăo, garantindo a compatibilidade com versőes antigas dos bancos de dados. Pode-se definir o dialeto através do script de criaçăo do banco (como na Listagem 1, que contém o comando SET SQL DIALECT 1) ou utilizando o IBExpert, acessando Database > Create Database e selecionando o dialeto no campo SQL Dialect (ver Figura 2).
Agora, para migrar nosso banco de exemplo para o Dialeto 3, será necessário alterar as seguintes linhas do script original, DIALECT 1 para DIALECT 3 e o tipo DATE para TIMESTAMP (ver Listagem 2). Como no Dialeto 3 o tipo DATE armazena somente a data, será necessário alterar o tipo do campo DATA_CADASTRO para TIMESTAMP para năo ocorrer erro na hora de inserir os dados, já que possuem originalmente valores de data e hora juntos. Năo é possível alterar diretamente o dialeto no banco de dados. A alteraçăo do dialeto só pode ser feita recriando o banco.
/***********************************************************************/
SET SQL DIALECT 3;
...
/***********************************************************************/
CREATE TABLE PAISES (
CODIGO INTEGER NOT NULL,
NOME VARCHAR(50) COLLATE WIN_PTBR,
DATA_CADASTRO TIMESTAMP);
...
Ao criar um novo banco de dados no Firebird, a năo ser que seja necessário manter compatibilidade com bancos de dados de versőes anteriores, o ideal é utilizar o Dialeto 3, pois permite total acesso a novos recursos de futuras versőes do Firebird. O Dialeto 3 ainda dispőe de tręs novas funçőes para obter data e hora do sistema:
Ao executar a query da Listagem 3, a consulta irá retornar todos os países que possuem o valor do campo DATA_CADASTRO igual ŕ data atual do sistema.
Listagem 3. Consulta paises.
select * from PAISES where DATA_CADASTRO = CURRENT_DATE
Na criaçăo do banco de dados (ver Figura 2), pode-se especificar o tamanho da página de dados do banco em bytes, podendo ser definido levando em consideraçăo o tamanho do cluster do servidor de dados. Criar uma base de dados com um tamanho da página de 4096 pode ser visto como uma boa opçăo, pois este é o tamanho do cluster do Windows Server 2003, por exemplo. Consequentemente, os tamanhos maiores só irăo trazer alguma vantagem de desempenho se o tamanho dos clusters forem maiores também.
O Page Size deve ser definido no script de criaçăo do banco (ver Listagem 1, que contém o comando PAGE_SIZE 4096). Utilizando o IBExpert pode-se selecionar o valor desejado no campo Page Size (ver Figura 2). O valor default do Page Size pode ser alterado ao fazer um restore do banco de dados (ver Listagem 4).
Listagem 4. Alterar Page Size
-- Restore do banco utilizando o utilitário gBak
gbak –user SYSDBA –pas masterkey –r –p 8192 -o c:\CADASTRO.fbk localhost:c:\CADASTRO.fdb
O Page Size também irá determinar o tamanho máximo de um campo do tipo blob. Enquanto os tipos de dados varchar possuem o tamanho limitado em 32 Kb, o tamanho máximo de um tipo de dado blob será determinado da seguinte forma:
O Character Set, também chamado de página de código, irá definir um conjunto de caracteres de determinado alfabeto que deverăo ser aceitos pelo banco de dados, influenciando diretamente na utilizaçăo de caracteres especais. Desta forma, deve-se escolher o Character Set a ser utilizado pelo banco de dados de acordo com as configuraçőes regionais e plataforma do sistema operacional com que se irá trabalhar, evitando assim, problemas na hora da gravaçăo de dados no banco.
Os Character Sets ISO8859_1 e WIN1252 săo muito parecidos. Suas diferenças estăo em alguns caracteres especiais e nas características de seus Collates, que serăo abordados no decorrer deste artigo. Normalmente, o Character Set ISO8859_1 é utilizado em bancos de dados hospedados em plataforma Linux e o Character Set WIN1252 em bancos hospedados em plataforma Windows. Através da Tabela 1 pode-se visualizar alguns dos principais tipos de Character Set e Collation suportados pelo Firebird.
Tabela 1. Alguns tipos de Character Sets aceitos no Firebird 2.0
| Regiăo | Character Set | Collation | Comentários |
|---|---|---|---|
| Todas | NONE | NONE | Sem character set e collation aplicado, o Firebird será incapaz de executar operaçőes de ordenaçăo e comparaçăo de caracteres de maneira correta. |
| Europa Ocidental | ISO8859_1 | ISO8859_1 | Latin-1, default para Linux |
| DE_DE | Alemăo/Alemanha | ||
| EN_UK | Inglęs/Inglaterra | ||
| EN_US | Inglęs/Estados Unidos | ||
| ES_ES | Espanhol/Espanha | ||
| PT_BR | Portuguęs/Brasil, Case+Accent insensitive (Firebird 2.0) | ||
| Europa Ocidental, Américas | WIN1252 | WIN1252 | Latin-1, com extensőes de Windows |
| WIN_PTBR | Portuguęs/Brasil, Case+Accent insensitive (Firebird 2.0) | ||
| PXW_INTL850 | Paradox Multi-Lingual Latin-1 | ||
| PXW_SPAN | Paradox Espanhol | ||
| China | BIG_5 | BIG_5 | Chinęs |
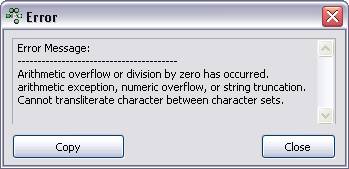
Se em nosso banco de dados o campo NOME passar a utilizar o Character Set BIG_5 (Chinese), por exemplo, năo será possível incluir os dados da instruçăo SQL da Listagem 5, pois o caractere acentuado ‘Á’ năo pertence ao conjunto de caracteres válidos para este Character Set, gerando um erro na hora de incluir este registro (ver Figura 3).
Listagem 5. SQL inserir registro.
A definiçăo do Character Set em um banco de dados pode ser feita através de um valor default para todo o banco ou diretamente nos campos de uma tabela (ver Listagem 6), e para definir o Character Set default utilizando o IBExpert, basta selecionar o valor desejado no campo Charset (ver Figura 2). Para alterar o valor default do Character Set de um banco de dados em produçăo é necessário recriá-lo alterando o script de criaçăo do banco para o valor desejado.
Listagem 6. Scripts definindo Character Set
-- Ao criar o banco de dados
CREATE DATABASE
USER
PASSWORD
PAGE_SIZE
DEFAULT CHARACTER SET
-- Ao criar campos em uma tabela
CREATE TABLE TESTE (
NOME VARCHAR(50) CHARACTER SET WIN1252,
TIPO VARCHAR(15) CHARACTER SET WIN1252);
Set Names especifica o conjunto de caracteres ativos, ajustando o uso do Character Set default do banco de dados (ver Listagem 7) com o Character Set usado em uma conexăo cliente.
Listagem 7. Set Names.
SET NAMES WIN1252;
CONNECT 'C:\CADASTRO.FDB' USER 'SYSDBA' PASSWORD 'masterkey';
É importante definir o Character Set utilizado tanto na base de dados como nas aplicaçőes clientes desenvolvidas em uma determinada linguagem, para que a aplicaçăo acesse corretamente o banco de dados. Se o Character Set de sua conexăo cliente for diferente do Character Set do banco de dados, a comunicaçăo entre o servidor e o cliente será mais lenta. Os dados deverăo ser convertidos de um Character Set para outro sempre que o cliente enviar os dados para o servidor, e vice-versa. Um exemplo desta configuraçăo pode ser observado através do componente SQLConnection da paleta dbExpress no Delphi (ver Figura 4).
Para ser capaz de ordenar e comparar strings, é necessário escolher um Collation para definir qual é a ordem com que os caracteres de um determinado alfabeto deverăo ser tratados para realizar classificaçőes dos dados (por exemplo, tratar diferenciaçăo entre caracteres minúsculos e maiúsculos, e diferenciaçăo entre caracteres acentuados ou năo). Assim, um Collation pode ser:
Na hora de efetuar uma consulta, a característica de ser Case-insensitive ou Accent-insensitive dependerá exclusivamente do Collate escolhido, podendo haver em um mesmo Character Set, Collates com estas características ou năo. Pode-se definir o Collate ao se criar campos em uma tabela, ou pode-se definir na hora de realizar uma consulta (ver Listagem 8).
Listagem 8. Scripts definindo Collation
-- Nos campos de uma tabela
CREATE TABLE TESTE (
NOME VARCHAR(50) CHARACTER SET WIN1252 COLLATE WIN_PTBR,
TIPO VARCHAR(15) CHARACTER SET WIN1252 COLLATE PXW_INTL850);
-- Order by
ORDER BY NOME COLLATE WIN_PTBR
-- Clausula Where
WHERE NOME COLLATE WIN_PTBR = 'Brasil'
Muitos desenvolvedores utilizam o Character Set WIN1252 com o COLLATE PXW_INTL850 para utilizar a ordenaçăo correta para o portuguęs e manter compatibilidade com programas que utilizam o BDE para conexăo com o banco de dados. A partir da versăo 2.0 do Firebird foi adicionado o novo COLLATE WIN_PTBR, que além de possuir a ordenaçăo correta para o portuguęs é Case-insensitive e Accent-insensitive, e pode-se criar um índice com campo de até 250 caracteres, enquanto Collates mais antigos aceitam somente até 83 caracteres.
No intuito de demonstrar as características de um Collate em uma consulta, vamos executar a query select * from PAISES where NOME = 'japao' no banco CADASTRO.FDB, onde o campo NOME possui o COLLATE WIN_PTBR (ver Listagem 1). O resultado da consulta será o apresentado na Tabela 2. Mesmo se alterarmos o valor para ‘Japăo’, ‘JAPAO’ ou ‘JAPĂO’, o resultado será o mesmo.
Tabela 2. Resultado da query com COLLATE WIN_PTBR.
| CÓDIGO | NOME | DATA_CADASTRO |
|---|---|---|
| 5 | Japăo | 26/08/2007 00:00:00 |
Agora, se alterarmos a query para select * from PAISES where NOME collate PXW_INTL850 = 'japao', o resultado será o apresentado na Tabela 3. O resultado só retornará o valor desejado se o valor informado for igual a ‘Japăo’ devido ŕs características do COLLATE PXW_INTL850.
Tabela 3. Resultado da query com COLLATE PXW_INTL850.
| CÓDIGO | NOME | DATA_CADASTRO |
|---|
O Collation também irá influenciar diretamente na ordenaçăo dos dados, desta forma, ao executar a query select * from PAISES order by NOME no banco de dados de exemplo CADASTRO.FDB, o resultado da consulta será o apresentado na Tabela 4.
Tabela 4. Resultado da query com COLLATE WIN_PTBR.
| CÓDIGO | NOME | DATA_CADASTRO |
|---|---|---|
| 1 | África do Sul | 25/08/2007 00:00:00 |
| 2 | Alemanha | 25/08/2007 00:00:00 |
| 3 | Brasil | 25/08/2007 00:00:00 |
| 4 | Japăo | 25/08/2007 00:00:00 |
Mas, se a consulta for realizada pela query select * from PAISES order by NOME collate WIN1252 o resultado será diferente (ver Tabela 5) devido ŕ alteraçăo do COLLATE na cláusula ORDER BY da consulta.
Tabela 5. Resultado da query com COLLATE WIN1252.
| CÓDIGO | NOME | DATA_CADASTRO |
|---|---|---|
| 2 | Alemanha | 25/08/2007 00:00:00 |
| 3 | Brasil | 25/08/2007 00:00:00 |
| 4 | Japăo | 25/08/2007 00:00:00 |
| 1 | África do Sul | 25/08/2007 00:00:00 |
O Firebird procura cada vez mais ser compatível com os padrőes definidos para o SQL-ANSI-92, fornecendo novas palavras reservadas, regras de sintaxe que aumentam a capacidade de criaçăo de consultas, filtros e instruçőes SQL. Possuindo ainda a flexibilidade de rodar em diversas plataformas como Windows, Linux, Unix e Mac OS.
A correta configuraçăo de seus parâmetros leva ŕ construçăo de bancos de dados mais robustos e confiáveis, otimizando o seu desempenho na manipulaçăo de dados.
Saiba mais: Cursos de Banco de Dados


Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.