


O artigo apresenta os componentes comumente encontrados em mecanismos de buscas modernos e como o framework Apache Lucene pode auxiliar na construçăo de soluçőes desse tipo. Uma aplicaçăo de cadastro e busca de currículos é utilizada para demonstraçăo dos recursos da biblioteca.
Em que situaçăo o tema é útil:
O tema é útil nas situaçőes em que o usuário precisa realizar buscas complexas sobre os dados de uma aplicaçăo. Implementaçőes de buscas tradicionais, baseadas em consultas SQL ou na leitura sequencial do conteúdo de arquivos, săo limitadas e podem ter um desempenho ruim. Outras abordagens săo necessárias, tais como a apresentada pelo Lucene.
Resumo DevMan:
O Lucene baseia-se no conceito de índices, estruturas de dados que permitem que qualquer termo e as suas localizaçőes dentro do conteúdo sejam encontrados rapidamente. As suas classes dividem-se grosseiramente naquelas que săo utilizadas para a construçăo do índice e naquelas que, utilizando o índice, săo capazes de realizar buscas eficientes sobre o conteúdo. O Lucene é um framework de baixo nível e, como tal, exige um bom conhecimento de seus conceitos para o seu correto uso na aplicaçăo.
Autores: Paulo Sigrist e Wilson Akio Higashino
A existęncia de bons mecanismos de busca nas aplicaçőes que utilizamos é fundamental para nosso dia-a-dia. Com o aumento da quantidade de informaçőes que produzimos e consumimos, é cada vez mais importante sermos capazes de localizar a informaçăo correta de maneira fácil, rápida e intuitiva.
O que seria da Internet se năo existissem os poderosos motores de busca como o Google e o Bing? De fato, pouco importa a existęncia de muita informaçăo se năo somos capazes de localizá-la. É interessante notar também que năo só na Internet as buscas tęm exercido esse papel tăo fundamental. Sistemas Desktop, como o Mac OS X e o Windows, já integram mecanismos que permitem localizar rapidamente arquivos e recursos pelo seu nome, conteúdo e inúmeros outros filtros. Aplicaçőes tradicionais, como tocadores de mídias e clientes de e-mail, também possuem motores de busca, e até mesmo Smartphones iOS e Android já possuem implementaçőes desses recursos. De certa forma, isso demonstra năo só o aumento do volume de informaçőes que produzimos, mas também que o paradigma usualmente utilizado para organizá-las, baseado em arquivos e diretórios, năo é suficiente para nossas necessidades atuais.
Tradicionalmente, implementamos buscas em nossas aplicaçőes através de consultas SQL, executadas por Sistemas Gerenciadores de Banco de Dados (SGBDs). Todavia, esta abordagem possui uma série de limitaçőes. Ela implica, por exemplo, na existęncia de um SGDB capaz de executar essas consultas. Além disso, nem sempre é fácil transformar uma série de filtros em SQL. Observe, por exemplo, a variedade de consultas que o Google fornece e imagine como elas poderiam ser transformadas em comandos select. Finalmente, o desempenho de tais consultas nem sempre é compatível com o requerido pela aplicaçăo. Consultas por substrings em colunas de tipo texto săo um pesadelo para muitos DBAs e costumam ser evitadas, já que impactam profundamente no desempenho do SGDB.
Pensando nisso, esse artigo apresenta o Apache Lucene, um framework de código aberto poderoso e flexível que pode ser usado para a construçăo de mecanismos de buscas e para a integraçăo destes com aplicaçőes Java de diversas naturezas. Vamos apresentar os seus conceitos básicos através de uma aplicaçăo de cadastro e busca de currículos.
Componentes de um mecanismo de busca
Antes de entendermos o que o Lucene faz, vale a pena revisar os componentes que tradicionalmente compőem um mecanismo de busca. A Figura 1 contém uma representaçăo em alto nível dos componentes principais.
Em um extremo da figura temos o conteúdo propriamente dito, e em outro os usuários que desejam realizar pesquisas sobre esse conteúdo. Para que a busca seja feita de forma rápida e eficiente, os mecanismos de busca baseiam-se nos chamados índices, que săo estruturas de dados que permitem que os termos sejam localizados rapidamente, assim como os locais dentro do conteúdo nos quais os termos săo encontrados. No entanto, índices săo estruturas complexas, cuja construçăo exige grande poder computacional. Assim, é comum dividirmos as aplicaçőes de busca em dois grandes grupos de funcionalidades: a construçăo do índice e as consultas que săo realizadas com o seu auxílio.
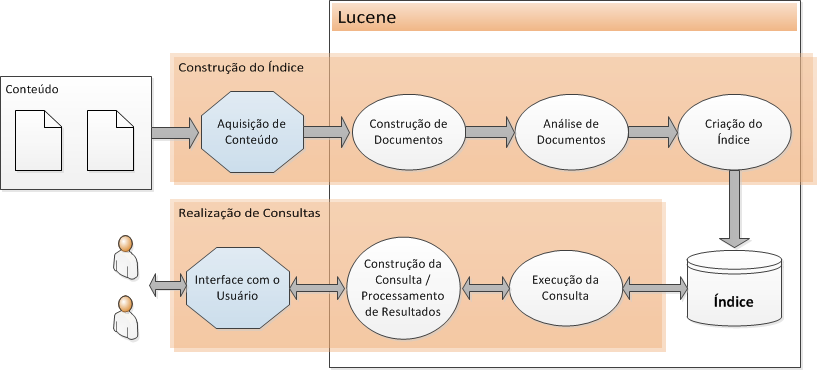
Figura 1. Componentes de uma aplicaçăo de busca (adaptado de [4]).
Para a construçăo do índice, o primeiro passo consiste na etapa de aquisiçăo do conteúdo. Por exemplo: o Google possui robôs, chamados de crawlers, que navegam pela Web a procura de novas páginas a serem indexadas. Em outros casos, essa etapa é muito mais simples: em um cliente de e-mail o conteúdo săo as próprias mensagens dos usuários, que podem ser acessados diretamente pela aplicaçăo.
Uma vez obtido o conteúdo, eles săo transformados nos chamados “documentos”, que nada mais săo que representaçőes canônicas, definidas pelo mecanismo de busca, e que representam o conteúdo obtido. Por exemplo: as buscas embutidas nos sistemas operacionais săo capazes de encontrar palavras-chave em arquivos PDF, documentos Word ou até mesmo em mensagens armazenadas em clientes de e-mail. Portanto, nesta etapa do processo de indexaçăo, todos esses diferentes tipos de documentos săo convertidos para um formato comum, normalmente composto por um conjunto de campos padronizados, tais como autor, data de criaçăo e o próprio conteúdo.
Em seguida, esses documentos săo analisados a fim de tornar o índice mais efetivo. Alguns processamentos simples, tais como a conversăo de maiúsculas para minúsculas, e a eliminaçăo de conectivos, tais como “a”, “e” e “ou”, săo comuns durante essa etapa. Todavia, outros mecanismos mais complexos também săo utilizados. Por exemplo, é comum que as palavras sejam processadas a fim de reduzi-las ŕ sua raiz morfológica. Assim, termos como “computaçăo” e “computadores” săo transformados em uma raiz comum, “computa”, permitindo que termos relacionados sejam encontrados. O resultado da análise é um conjunto de tokens, que săo as “palavras” que efetivamente farăo parte do índice. Esta etapa é uma das mais importantes do processo de indexaçăo, podendo determinar o sucesso ou o fracasso da aplicaçăo.
Por fim, a última etapa do processo de indexaçăo alimenta o índice com os tokens obtidos a partir do documento analisado. Como todo esse processo é custoso, normalmente um conjunto de documentos dăo origem a uma versăo inicial do índice, que é modificado de forma incremental através de adiçőes de novos documentos e de atualizaçőes dos já existentes.
Já no outro extremo da arquitetura temos os usuários, que interagem com a aplicaçăo através de uma interface na qual ele entra com a busca desejada. Em seguida, há uma etapa em que a entrada do usuário é convertida para uma consulta em um formato definido pelo mecanismo de busca. Como uma analogia, pense na conversăo de um filtro para uma consulta SQL a ser executada em um banco de dados.
A consulta é entăo executada utilizando como auxílio o índice construído anteriormente. É importante ressaltar novamente a importância do índice para uma execuçăo eficiente da consulta. Sem ele, as buscas teriam que varrer todo o conteúdo em busca da informaçăo requerida. Em um programa de e-mail ou em seu Desktop, o tempo necessário para essa varredura pode ser aceitável, mas para a Internet é inviável imaginarmos essa situaçăo.
Finalizada a execuçăo da busca, os resultados săo finalmente apresentados para o usuário, geralmente ordenados por relevância ou outro critério que facilite localizar a informaçăo desejada.
O Lucene
O Lucene é um framework que foi criado por Doug Cutting em 2000 como um projeto pessoal, mas que vem desde setembro de 2001 sendo mantido pelo grupo Apache. No momento da escrita deste artigo, sua última versăo era a 3.5.0. Ele auxilia nas etapas de construçăo e análise de documentos, indexaçăo, construçăo e execuçăo de buscas, e o gerenciamento dos resultados. Desta maneira, a aplicaçăo que utiliza o Lucene é ainda responsável por duas partes fundamentais: a aquisiçăo de conteúdo e a interface pela qual o usuário irá interagir.
...

Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.