Ao iniciar os trabalhos com Node.js, rapidamente nota-se que mesmo o mais simples dos códigos acaba viabilizando muitas funcionalidades. Mesmo que vocę seja iniciante, com poucas linhas de código conseguirá criar aplicaçőes de troca de mensagens entre clientes e servidor, como o exemplo mais clássico de aplicaçőes em tempo real, um chat.
Caso possua experięncia em outras tecnologias como Java ou PHP, pode até pensar que isso năo é “algo do outro mundo”, contudo, o grande diferencial é que o Node.js foi planejado e criado para lidar especificamente com aplicaçőes desse tipo, em rede. E mais, ele foi projetado para lidar com alta concorręncia em tempo real. Com isso, ele é capaz de lidar com milhares de clientes conectados ao mesmo tempo, consumindo pouca memória e exigindo pouco processamento do servidor.
Em se tratando de uma tecnologia voltada para o desenvolvimento de aplicaçőes em rede, o Node.js foi construído para ser orientado a eventos e I/O năo bloqueante, ou seja, a entrada e saída de dados năo bloqueiam os processos de execuçăo das aplicaçőes, fazendo com que a concorręncia entre vários clientes simultâneos seja mais performática e eficiente.
Para quem está dando os primeiros passos com o Node, pode parecer um pouco confuso já começar com um exemplo de um servidor web, pois este envolve conceitos de rede, cliente, servidor, o protocolo HTTP, etc. Por outro lado, como o Node foi elaborado tendo como base alguns destes conceitos, a maioria das tecnologias mencionadas já săo fornecidas e até gerenciadas pelos próprios módulos dele.
Saiba mais: Curso de Node.js: Primeiros passos
Caso vocę ainda năo esteja familiarizado com esta soluçăo e seu paradigma orientado a eventos, vamos fazer uma rápida revisăo.
O Node.js é, basicamente, um combinado do engine JavaScript do Google Chrome, denominado V8, com a utilizaçăo de um recurso do sistema operacional que monitora requisiçőes de operaçőes de entrada e saída e que dispara a resposta ao solicitante assim que uma resposta estiver de fato disponível. Em outras palavras, esse monitoramento e, consequentemente, essa resposta, é o que conhecemos popularmente como callback. Cada sistema operacional possui a sua própria implementaçăo desse mecanismo. Em ambientes Unix, por exemplo, esse recurso é chamado de epoll.
Tendo o V8 como engine para interpretar JavaScript e o próprio sistema operacional fornecendo o I/O năo bloqueante, restou aos desenvolvedores do Node.js fazerem a junçăo dessas funcionalidades, agregando a camada de acesso a arquivos, criptografia, rede, e outras features comuns em qualquer linguagem de programaçăo.
O conceito de um servidor web é relativamente simples. Como qualquer tipo de aplicaçăo que age como um servidor, iniciamos uma socket que fica “escutando” uma determinada porta e que recebe conexőes de sockets cliente que desejam trocar informaçőes com este servidor.
Sempre que um servidor é implementado, é preciso definir um protocolo, ou seja, definir a forma como o cliente e o servidor irăo se comunicar. Uma das maneiras mais convenientes de se estabelecer essa comunicaçăo entre é definindo comandos para que o cliente solicite informaçőes ao servidor, que por sua vez pode interpretar esses comandos, associando-os a uma funçăo específica, executá-la e devolver uma resposta ŕ solicitaçăo feita pelo cliente.
Saiba mais Série Programe com o Node.jsNo caso específico de um servidor web, esse protocolo já existe e já é encapsulado pelo Node.js em sua biblioteca padrăo: o protocolo HTTP.
Embora ele facilite a nossa vida, fornecendo uma API completa e cheia de módulos associados, năo só para o protocolo HTTP, mas também para uma gama imensa de recursos relacionados a redes, cabe ao desenvolvedor decidir o que fazer com esses recursos, ou seja, fica a seu critério estabelecer como o servidor web deve se comportar, receber e responder as requisiçőes, controlar o acesso através de login, ou a quantidade de conexőes simultâneas que ele estará apto a receber. Em outras palavras, o Node fornece as ferramentas “pré-prontas” para que vocę possa se concentrar nas regras de negócio da aplicaçăo, sem precisar concentrar esforços na implementaçăo de protocolos HTTP e outras particularidades da conexăo entre cliente e servidor.
Dito isso, eis o que vamos construir para que nosso servidor web funcione como queremos:
Como esse artigo tem por objetivo apresentar uma aplicaçăo básica, năo utilizaremos módulos de terceiros como Socket.IO. Porém, para propósitos de agilizar o desenvolvimento, vamos baixar, através do npm (BOX 1), o nodemon.
É
um programa que faz parte dos arquivos binários do Node.js. Sua funçăo é baixar
e instalar pacotes de módulos para o Node.js criados pela comunidade.BOX 1. npm
O nodemon é uma soluçăo que executa qualquer aplicaçăo escrita em Node.js e que fica “vigiando” os arquivos desta. Com isso, caso algum arquivo presente no diretório onde o nodemon foi iniciado for alterado, a aplicaçăo é reiniciada automaticamente, o que faz com que năo tenhamos que parar a execuçăo de nossa aplicaçăo e reiniciá-la a cada alteraçăo no código.
Além disso, caso a aplicaçăo “quebre”, ela continuará sendo vigiada pelo nodemon, e quando o problema que causou a interrupçăo da aplicaçăo for corrigido, ou seja, o trecho de código que possuir erros for reparado, ele reiniciará a aplicaçăo automaticamente.
Agora que vocę tem uma ideia de como utilizar o nodemon para favorecer a agilidade no desenvolvimento de aplicaçőes, vamos executá-lo em nossa aplicaçăo. Para isso, no entanto, precisamos ter algum arquivo para passar como parâmetro na linha de comando.
Esse é um bom momento para criarmos năo só o arquivo principal de nossa aplicaçăo, mas também toda a sua estrutura de diretórios. Sendo assim, vamos criar um diretório com o nome que acharmos mais apropriado para a aplicaçăo – por exemplo: webserver. A partir desse diretório, crie os demais conforme a Listagem 1.
Listagem 1. Estrutura de diretórios da aplicaçăo.
webserver
└── static
├── css
├── image
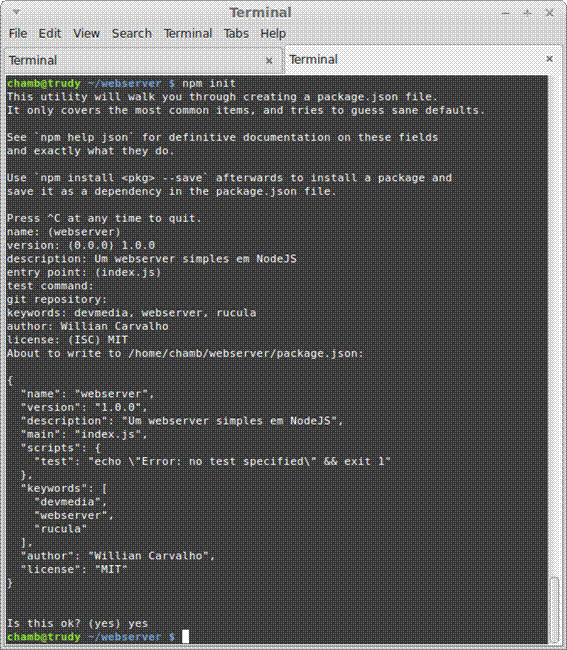
└── scriptNossa aplicaçăo residirá na raiz do diretório webserver. Dentro deste temos o diretório static, que será responsável por manter os arquivos solicitados pelo browser através de requisiçőes HTTP. A partir do diretório webserver que acabamos de criar, execute o comando npm init. Este comando irá gerar um arquivo de nome package.json com informaçőes sobre a aplicaçăo, como: dependęncias, licença, autor, etc.
Quando o comando npm init é executado, ele solicitará algumas informaçőes ao desenvolvedor para preencher adequadamente o package.json. Vocę deverá ver uma tela semelhante ŕ exibida na Figura 1. Preencha-as como achar melhor, porém, mantenha a opçăo entry point com o valor padrăo index.js, pois este será o arquivo principal do servidor web.
Caso năo possua o nodemon instalado, execute o comando npm install -g nodemon no seu prompt do Windows ou terminal, caso esteja trabalhando em um ambiente Unix, como Ubuntu ou MacOS. Isso fará com que o npm instale o nodemon de maneira global, ou seja, vocę estará apto a utilizá-lo de qualquer lugar do seu sistema de arquivos.
Agora que já temos o nodemon instalado, vamos criar os arquivos de código para que ele possa executá-los e monitorá-los. Para tanto, a partir do diretório webserver, crie os seguintes arquivos:
Neste momento seu diretório webserver deve possuir a mesma estrutura apresentada na Listagem 2.
Listagem 2. Estrutura final de diretórios e arquivos da aplicaçăo.
webserver
├── config.json
├── filehandler.js
├── index.js
├── package.json
├── server.js
└── static
├── css
├── image
└── scriptO conteúdo do arquivo principal da aplicaçăo, index.js, ainda que pequeno, diz bastante coisa sobre o servidor web, pois é a partir dele que faremos a inclusăo e utilizaçăo de todos os módulos da nossa soluçăo. Sendo assim, é importante entendermos o que está acontecendo em cada linha, pois do ponto de vista da compreensăo do código, o index.js representa uma visăo macro de tudo que nosso servidor web poderá fazer. O seu conteúdo é exposto na Listagem 3.
A principal e real funçăo do index.js é funcionar como uma espécie de container, centralizando a utilizaçăo dos módulos, que serăo separados por responsabilidades, ou seja, cada módulo será responsável por uma parte do trabalho realizado. Note, contudo, que o arquivo principal năo precisa necessariamente “saber” como os módulos fazem seu trabalho. Basta que ele saiba que esses módulos realizam as tarefas que ele precisa.
Listagem 3. Conteúdo do arquivo index.js.
process.title = 'MyWebServer';
1. var args = process.argv,
2. port = args[2] || 7070,
3. webServer = require('./server');
4.
5. webServer.listen(port, function() {
6. console.log('Server started at port ' + port);
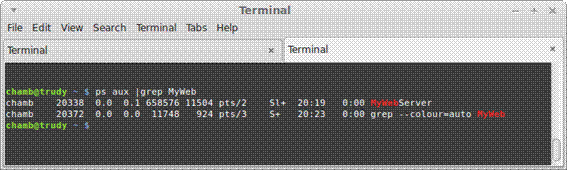
7. });Na primeira linha, ainda que năo seja uma instruçăo fundamental para a aplicaçăo, modificando o atributo process.title, definimos um nome para o processo do servidor no sistema operacional. Assim, quando vocę estiver executando sua aplicaçăo em um sistema operacional derivado do Linux, por exemplo, será possível ver o nome do processo, bem como seu id. Um exemplo disso pode ser verificado na Figura 2.
Na declaraçăo das variáveis vemos o módulo process sendo usado novamente, desta vez para recuperar os argumentos da linha de comando, através do atributo argv. Este objeto (args) é um atributo especial do módulo process que preserva todos os parâmetros passados quando o comando node (ou nodemon, no nosso caso, já que estamos em fase de desenvolvimento) é executado.
Por motivos de organizaçăo do código, criamos uma variável chamada args para armazenarmos uma referęncia do objeto argv do módulo process. argv funciona como um array, contendo uma lista dos argumentos passados para o programa na linha de comando do prompt do sistema operacional. Seu primeiro elemento representará o executável node (ou o nodemon, como já explicado). O segundo argumento representará o nome do arquivo sendo executado (no nosso caso o index.js), e a partir do terceiro elemento (args[2]) temos os argumentos opcionais da aplicaçăo, que no nosso caso será a porta na qual o servidor deve ser inicializado, caso seja fornecida.
Logo após a declaraçăo do objeto args, armazenamos o primeiro argumento opcional, ou seja, o terceiro elemento de args, assumindo que este é o valor da porta pela qual o servidor web “escutará” por requisiçőes do browser. Caso nenhum argumento seja encontrado, utilizamos o valor padrăo 7070.
A terceira e última variável declarada, webServer, é o objeto que representa o servidor web propriamente dito e que discutiremos em breve. Nesse momento basta entendermos com que tipo de conteúdo e como a variável webServer está sendo carregada, o que nos leva ŕ instruçăo require, do Node.js, que será explicado a seguir.
Para carregar um módulo em uma aplicaçăo, seja ele criado pelo próprio desenvolvedor, seja ele um módulo importado pelo npm, como o Socket.IO ou um driver de banco de dados como o MySQL ou MongoDB, ou ainda, um módulo da biblioteca padrăo do Node.js, como o módulo fs, é preciso utilizar a instruçăo require, passando como argumento uma String com o nome do arquivo correspondente ao módulo que queremos usar. Se quisermos carregar um módulo criado por nós, o nome do arquivo precisa começar com o caminho relativo “./” e năo é necessário adicionar o prefixo .js ao final. Assim, o require irá carregar o módulo e associá-lo ŕ variável webServer.
Por fim, utilizamos o método listen() do objeto webServer. Este método recebe como argumento a porta na qual o servidor deve receber conexőes dos clientes, e como segundo argumento opcional, uma funçăo de callback que será disparada assim que o servidor for iniciado. No nosso caso, a funçăo apenas exibe uma mensagem no console, dizendo que o servidor foi iniciado na porta especificada.
A única dependęncia do index.js, como vocęs podem notar, é o módulo importado pelo require, chamado server, ou seja, o arquivo server.js, apresentado na Listagem 4 e encontrado no mesmo diretório do arquivo principal. Este arquivo é o responsável por implementar o servidor web propriamente dito.
Listagem 4. Conteúdo do arquivo server.js, implementaçăo do servidor web
1. var http = require('http'),
2. config = require('./config'),
3. fileHandler = require('./filehandler'),
4. parse = require('url').parse,
5. types = config.types,
6. rootFolder = config.rootFolder,
7. defaultIndex = config.defaultIndex,
8. server;
9.
10. module.exports = server = http.createServer();
11.
12. server.on('request', onRequest);
13.
14. function onRequest(req, res) {
15. var filename = parse(req.url).pathname,
16. fullPath,
17. extension;
18.
19. if(filename === '/') {
20. filename = defaultIndex;
21. }
22.
23. fullPath = rootFolder + filename;
24. extension = filename.substr(filename.lastIndexOf('.') + 1);
25.
26. fileHandler(fullPath, function(data) {
27. res.writeHead(200, {
28. 'Content-Type': types[extension] || 'text/plain',
29. 'Content-Length': data.length
30. });
31. res.end(data);
32.
33. }, function(err) {
34. res.writeHead(404);
35. res.end();
36. });
37. }Nas oito primeiras linhas do server.js podemos identificar a inicializaçăo de variáveis e a importaçăo de alguns módulos, como já vimos anteriormente. Contudo, é possível notar algumas peculiaridades em relaçăo ŕ importaçăo do módulo server.js, visto no index.js.
A primeira coisa a se notar é que, na importaçăo do módulo http, năo foi utilizado o caminho relativo “./”. Isso porque, diferente do módulo server.js que nós mesmos escrevemos, o módulo http faz parte da biblioteca do Node.js. Para qualquer módulo da API padrăo, este deve ser chamado sem a necessidade de se especificar qualquer caminho.
A segunda peculiaridade, ainda que năo seja muito visível nesse momento, é a importaçăo do objeto config. Este se trata de um arquivo com a extensăo e formato JSON. Isso mesmo, o require é capaz de importar módulos escritos para o Node, assim como pode converter automaticamente arquivos JSON em um objeto literal JavaScript. No contexto de nossa aplicaçăo, isso quer dizer que, assim como alguns programas utilizam arquivos .ini ou .xml para ler configuraçőes do sistema, estamos utilizando um arquivo JSON para essa finalidade. Vamos discutir esse arquivo com mais detalhes mais ŕ frente.
Perceba também, falando ainda sobre a importaçăo de módulos, a importaçăo do método parse(), que pertence ao objeto url, cujo papel é separar cada trecho de qualquer URL e retornar um objeto com cada um deles. Note que, ao invés de importar todo o objeto url, com todos os seus métodos e atributos, importamos apenas o método que precisamos utilizar, semelhante ŕ importaçăo de métodos no Python ou a utilizaçăo de métodos estáticos do Java, ainda que esse último tenha uma filosofia e finalidade bem diferentes.
Além dessas novidades, podemos ver a importaçăo do módulo filehandler e o uso de variáveis para guardar a referęncia de alguns atributos do objeto config, como o content type do arquivo solicitado, o diretório padrăo dos arquivos providos pelo servidor web (rootFolder) e o nome do arquivo padrăo quando nenhum arquivo for especificado ao chamar a URL do servidor (defaultIndex).
Na linha 10 usamos module.exports, cujo valor atribuído a ele é exatamente o que o require irá importar, seja lá onde for chamado. module.exports, como o próprio nome sugere, é a maneira como o sistema de módulos do Node.js exporta módulos e outros objetos a partir de algum arquivo, de forma que esses módulos possam ser importados e utilizados por outros módulos da aplicaçăo.
Como na maioria das linguagens de programaçăo, nós acabamos separando nosso código por responsabilidades lógicas, cada qual em um arquivo, classe ou módulo diferentes, para manter a modularidade da aplicaçăo. Isso é geralmente uma boa prática, pois além de mantermos a aplicaçăo organizada em responsabilidades lógicas, esses módulos podem ser reaproveitados por outros trechos do código. Por exemplo, um módulo responsável por se conectar a um banco de dados pode ser construído de forma a se conectar com um ou mais bancos diferentes. Paralelamente a isso, é possível ter vários módulos com propósitos específicos que precisam se conectar a bancos de dados. Logo, năo faz sentido replicar esse código em cada um desses módulos, sendo mais interessante importar o módulo que já fornece tal recurso.
No nosso caso, estamos “exportando” a variável server, atribuindo a ela uma instância de nosso servidor web, através do método createServer() do módulo http.
Embora tenhamos escrito essa linha com múltiplas atribuiçőes ao mesmo tempo, com o formato module.exports = server = http.createServer(), visando manter o código mais enxuto, ela pode năo ser tăo legível, chegando a ser confusa para algumas pessoas. Para contornar esse problema, poderíamos, por exemplo, instanciar o servidor web, atribui-lo ŕ variável server e entăo, na linha seguinte, atribuir server a module.exports. Vocę pode atribuir qualquer coisa que quiser ao module.exports, como funçőes, variáveis e objetos literais.
Na linha 12 podemos observar uma das mais notáveis e significantes características do Node: os tăo famosos eventos!
Na maioria dos casos, eventos săo passados como o primeiro argumento de uma funçăo, em forma de string contendo seu nome, como por exemplo, “onload”, “onclick”, “request”, ou simplesmente “on”. Uma vez que o nome do evento é fornecido como argumento de uma funçăo, informa-se a funçăo de callback como segundo argumento, representando a açăo a ser executada quando o evento passado no primeiro argumento for disparado.
Para facilitar a compreensăo, vamos pegar como exemplo o evento click, comumente utilizado em páginas web. Podemos atribuir o evento click a um botăo, a um link ou a qualquer outro elemento HTML que quisermos, mas vamos utilizar um botăo por ser o exemplo mais natural.
Uma vez que temos a referęncia a um botăo, através da atribuiçăo da instância deste a uma variável como myButton (por exemplo: var myButton = document.querySelector(“#myButton”)), teremos acesso ŕ funçăo addEventListener(), que recebe como argumentos uma String com o nome do evento e uma funçăo, a ser executada sempre que o evento descrito no primeiro argumento for disparado, como: myButton.addEventListener('click', triggerEvent). A partir desse registro, toda vez que o usuário clicar no botăo, a funçăo triggerEvent será executada.
O mesmo conceito se aplica a programas escritos com Node.js. Contudo, ao invés de usarmos o método addEventListener() do JavaScript para páginas HTML, temos o método on() do objeto server, que também recebe dois argumentos. O primeiro argumento é uma String com o nome do evento que queremos “escutar” e o segundo argumento é uma funçăo de callback com os argumentos res (response) e req (request) com a açăo a ser realizada a cada vez que o evento for disparado.
No caso da nossa aplicaçăo estamos chamando a funçăo on do objeto server, passando como primeiro argumento o evento request, que é um evento pré-definido pelo servidor HTTP do Node.js, sendo disparado toda vez que uma nova requisiçăo do cliente for enviada ao servidor (o que normalmente ocorre através de um browser).
Para o segundo argumento da funçăo on(), passamos a funçăo onRequest(), declarada na linha 14. Esta corresponde a todas as açőes a serem realizadas para cada nova requisiçăo de um cliente. Outra opçăo seria passar uma funçăo anônima diretamente no segundo argumento. Porém, para manter o código mais didático, este argumento foi declarado com uma named function, ou seja, uma funçăo declarada com um nome, podendo ser reusada em outros trechos do código.
A funçăo onRequest() recebe dois argumentos (res e req) e é executada quando o evento request é disparado. O argumento res representa a resposta (response) a ser enviada ao cliente, tais como códigos HTTP de erro ou sucesso, e o conteúdo da resposta, como um código HTML a ser interpretado pelo browser, um JSON, XML, uma imagem e assim por diante.
O argumento req (request) representa a requisiçăo recebida pelo servidor, enviada pelo cliente. Este objeto possui todas as informaçőes relacionadas ao cliente, tais como IP, informaçőes do browser, que arquivo está sendo solicitado (páginas HTML, imagens, etc.), entre outras informaçőes que precisam ser de conhecimento do servidor.
Na linha 15 utilizamos o método parse() para interpretar o endereço HTTP solicitado pelo browser e transformá-lo em um objeto JSON, para facilitar o manuseio. Quando o endereço é submetido ao método parse(), este retorna um objeto contendo atributos da URL separados convenientemente para que possamos trabalhar com os valores da URL, como pathname, hostname, port, search e outros. No nosso caso utilizaremos o atributo pathname, pois ele contém o caminho e o nome do arquivo solicitado pelo browser. Em seguida, atribuímos o caminho do arquivo ŕ variável filename que, mais tarde, será fornecida ao nosso módulo de leitura de arquivos.
Na linha 19, caso o valor da variável filename seja a string “/”, quer dizer que o usuário năo especificou nenhum arquivo ao enviar a requisiçăo ao servidor, o que nos leva a carregar o arquivo padrăo, representado pela variável defaultIndex. Lembre-se que defaultIndex possui o valor que foi carregado do arquivo de configuraçăo config.json.
Na linha 23 atribuímos ŕ variável fullPath o caminho completo do arquivo solicitado pelo usuário, juntando o conteúdo da variável de configuraçőes rootFolder, que assim como a variável defaultIndex, foi carregada a partir do arquivo de configuraçăo config.json, somado ao conteúdo da variável filename, que acabamos de analisar.
Já na linha 24 utilizamos a funçăo substr() do módulo String do JavaScript para capturar apenas a extensăo do arquivo solicitado pelo usuário. A partir dessa informaçăo podemos saber qual será o tipo de conteúdo (Content Type) a ser entregue ao usuário.
Caso vocę năo esteja familiarizado com o protocolo HTTP, cada arquivo oferecido pelo servidor web é entregue com uma série de outras informaçőes, sendo uma delas o tipo de conteúdo e o seu tamanho em bytes. Isso informa ao browser como ele deve lidar com o arquivo. Por exemplo, se o servidor web informar que o tipo de conteúdo é text/plain, o browser saberá que se trata de um texto simples. Por outro lado, se o servidor informar que o tipo de conteúdo é image/png, o browser saberá que se trata de uma imagem, e que ele deve tratar o conteúdo como uma imagem e “pintá-la” na tela.
Alguns desses tipos de conteúdo também estăo armazenados no arquivo config.json, para que possam ser lidos e interpretados pela aplicaçăo, fornecendo o tipo de conteúdo correto de acordo com a solicitaçăo de arquivo feita pelo usuário. Esses tipos de conteúdo foram carregados na variável types, um subobjeto do objeto config. Mais adiante iremos entender a estrutura de dados do arquivo config.json e como ele está organizado.
Agora que sabemos qual arquivo devemos carregar para enviar ao usuário e qual é o content type, ou seja, com qual tipo de arquivo o browser deve interpretar os dados recebidos, podemos utilizar a funçăo fileHandler() para realizar a tarefa de ler este arquivo do diretório static para nós. Portanto, da linha 26 ao fim do arquivo, podemos ver a funçăo fileHandler(), outro módulo de nossa aplicaçăo cujo conteúdo analisaremos mais ŕ frente.
A funçăo fileHandler() é importada na linha 3 através da instruçăo require do Node.js. Como verificado, o sistema de exportaçăo e importaçăo de módulos do Node.js pode exportar qualquer coisa, seja essa coisa um objeto, uma variável ou mesmo uma funçăo, como é caso de fileHandler(). Isso serve de exemplo para mostrar que podemos importar diferentes tipos de dados, como quando importamos o módulo server, por exemplo, que é um objeto mais complexo, composto de variáveis e funçőes.
Assim como index.js apenas precisava fazer uso do módulo server, o módulo server apenas precisa saber usar a funçăo fileHandler(), e é por isso que a isolamos em um novo arquivo. Recapitulando o que foi abordado no começo do artigo, lembre-se que dividimos os módulos do sistema em responsabilidades lógicas. Nosso index.js é responsável por iniciar a aplicaçăo, servindo como um container da aplicaçăo, e por isso depende do arquivo server.js para fazer todo o trabalho associado ao servidor web.
O arquivo server.js, por sua vez, é responsável por toda a lógica associada ao servidor web e por interpretar requisiçőes (requests) e respostas (responses) HTTP, porém ele depende de um módulo responsável pela leitura de arquivos, e é aqui que entra a dependęncia do fileHandler().
A funçăo fileHandler() recebe tręs argumentos: o caminho completo de onde o arquivo deve ser lido, uma funçăo de callback de sucesso e uma funçăo de callback de erro.
A funçăo de sucesso possui um argumento que representa os dados carregados do arquivo solicitado, e o corpo da funçăo (note que dessa vez utilizamos uma funçăo anônima, para mostrar que vocę tem liberdade de trabalhar da maneira que achar melhor) utiliza o método writeHead() do objeto res. O primeiro argumento passado a esse método é o código HTTP (200 quer dizer que a resposta está Ok) e o segundo argumento é um objeto com informaçőes do cabeçalho HTTP; no caso, o tipo de conteúdo (Content-Type) e o tamanho dos dados em bytes (Content-length).
Note que foi usado o formato types[extension] para capturar o valor da extensăo do objeto types. Caso năo esteja familiarizado com essa notaçăo, em JavaScript é possível recuperar o valor do atributo de um objeto usando-se o ponto seguido do nome do atributo, ou utilizar colchetes envolvendo o nome do atributo entre aspas. Por exemplo: objeto.atributo ou objeto['atributo']. Como capturamos a extensăo em forma de string, faz mais sentido utilizar o formato com colchetes, ou seja, types[extension].
Após configurarmos todos os parâmetros a serem enviados no cabeçalho HTTP de volta ao cliente, temos na linha 31 o método end() que encerra a comunicaçăo com o cliente, enviando os dados solicitados. Na linha 33 utilizamos a mesma técnica empregada para enviar o conteúdo solicitado ao cliente; porém, por se tratar de uma funçăo de callback de erro, informamos o código HTTP 404, que quer dizer que o arquivo solicitado năo foi encontrado, e o método end() é passado sem qualquer argumento.
Obviamente existem muitos outros códigos HTTP, como 500, 304, 401, entre outros, cada qual com seu significado e interpretado de forma diferente pelo browser.
Agora que entendemos como nosso servidor está funcionando, vamos detalhar o funcionamento da funçăo fileHandler(), utilizada nas últimas linhas deste. A implementaçăo desta funçăo é realizada no arquivo filehandler.js,
Listagem 5. filehandler.js – responsável por ler os arquivos solicitados pelo cliente.
1. var fs = require('fs');
2.
3. module.exports = function(filename, successFn, errorFn) {
4. fs.readFile(filename, function(err, data) {
5. if(err) {
6. errorFn(err);
7. } else {
8. successFn(data);
9. }
10. });
11. };Com o Node.js é possível exportar qualquer coisa, até mesmo funçőes, e é justamente uma funçăo que é exportada a partir do arquivo filehandler.js.
Na linha 1 importamos o módulo fs (filesystem) da API padrăo do Node, e como o próprio nome diz, serve para manipulaçăo de arquivos e diretórios, sendo responsável por quase todo o trabalho de nosso módulo.
Já sabemos o que está acontecendo na linha 3 e já sabemos para que servem os argumentos da funçăo, mas recapitulando rapidamente, temos o nome do arquivo a ser lido, uma funçăo de callback caso a leitura do arquivo ocorra com sucesso e outra funçăo de callback caso a leitura do arquivo falhe.
O único método que usaremos do módulo fs é o readFile(). Este recebe uma string como primeiro argumento, contendo o caminho e nome do arquivo a ser lido, e o segundo argumento é uma funçăo de callback que recebe outros dois argumentos: um objeto de erro e os bytes do arquivo lido, caso a leitura seja bem sucedida.
O simples fato do argumento err possuir alguma informaçăo que represente um valor válido, isto é, o valor da variável for diferente de null, undefined, uma string vazia, 0 ou false, significa que um erro ocorreu, como arquivo năo encontrado, acesso negado ou qualquer outro tipo de problema ao recuperar os dados do arquivo solicitado.
Em nosso código, se qualquer erro ocorrer, disparamos a funçăo de callback errorFn(), que deve ser fornecida pelo “usuário” da funçăo filehandler(), no nosso caso, o nosso módulo server. Caso năo haja erro, o conteúdo do arquivo é recuperado e passado como argumento ŕ funçăo de callback successFn(), também declarada no módulo server.
Na Listagem 6 é exibido o conteúdo do arquivo config.json.
Listagem 6. Conteúdo de config.json – configuraçőes utilizadas pela aplicaçăo.
{
"rootFolder": "./static",
"defaultIndex": "/index.html",
"types" : {
"htm": "text/html",
"html": "text/html",
"jpg": "image/jpeg",
"jpeg": "image/jpeg",
"png": "image/png",
"css": "text/css",
"js": "text/javascript",
"json": "application/json"
}
}O arquivo config.json conta com tręs atributos: rootFolder, defaultIndex e types, referentes ŕs variáveis que carregamos no server.js.
Note que, para que possa ser carregado corretamente pelo Node, config.json precisa ser um JSON válido, ou seja, deve respeitar as regras de um JSON, expostos a seguir:
O atributo rootFolder contém o caminho a partir de onde o servidor web deve ler arquivos – no nosso caso, o diretório /static. Já o atributo defaultIndex contém o nome do arquivo padrăo, caso o cliente năo especifique o arquivo desejado, e o atributo types contém um objeto cujas chaves săo extensőes de arquivos, como por exemplo, “html”, e o valor para cada chave é o content type, como por exemplo, “text/html” como valor da chave “html”. Lembre-se que é através do objeto types que conseguimos saber o content type dos arquivos.
Vocę pode verificar exemplos da utilizaçăo do atributo types na linha 28 do arquivo server.js, onde isolamos a extensăo do arquivo (ex.: html) e, a partir dessa extensăo, obtemos o tipo do conteúdo, através da expressăo types[extension], onde, na ocasiăo, extension representa o valor html.
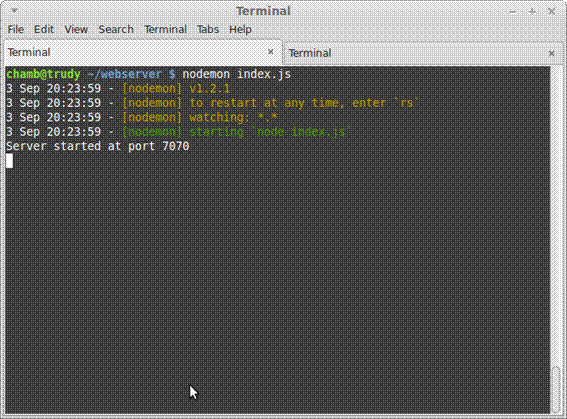
Uma vez que vocę tenha implementado todos os arquivos, podemos executar a aplicaçăo com o comando nodemon index.js; ou, se vocę já havia executado o nodemon desde o começo, pode notar que ele recarrega a aplicaçăo a cada vez que um arquivo é modificado.
Caso tudo ocorra como esperado, vocę verá uma tela parecida com a mostrada na Figura 3.
Para ver o resultado de nosso desenvolvimento, basta abrir seu browser e acessar http://localhost:7070, preferencialmente, com as ferramentas de desenvolvedor habilitadas na seçăo de rede. Para isso, no Google Chrome, por exemplo, navegue até o menu Tools > Developer Tools, onde teremos acesso a uma porçăo de informaçőes sobre a página sendo visualizada, bem como os arquivos que foram baixados, tempo de download de cada um, verificar se algum arquivo falhou por qualquer motivo que seja e assim por diante.
Muitas vezes, enquanto estamos desenvolvendo uma aplicaçăo web, pode ocorrer de năo termos nenhuma informaçăo visual no browser em si. Porém, mantendo as ferramentas do desenvolvedor habilitadas, temos acesso a muitas informaçőes por trás dos bastidores da comunicaçăo entre browser e servidor web.
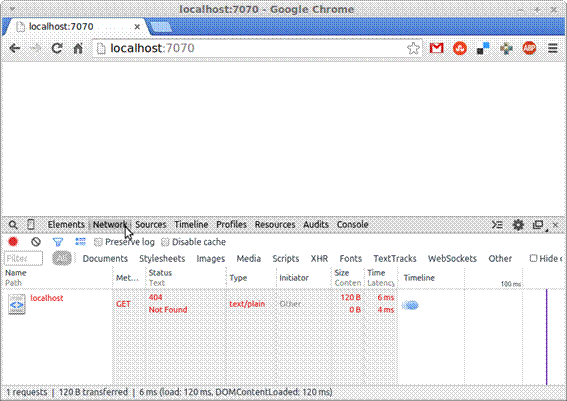
Dando continuidade, após ter habilitado as ferramentas do desenvolvedor e acessado a URL do seu servidor, vocę deverá ver uma tela semelhante ŕ exibida na Figura 4.
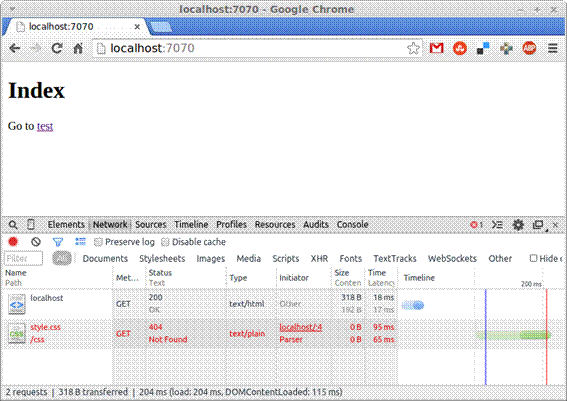
Caso vocę também tenha visto uma tela em branco com uma informaçăo em vermelho no log de rede, por mais estranho que seja, o servidor web funcionou! Contudo, como năo temos nenhum arquivo na pasta static, o servidor retornou um erro 404, conforme codificamos no server.js, o que é bastante recompensador, porém, frustrante ao mesmo tempo, já que năo exibimos nenhum conteúdo no browser.
Para resolver esse problema, vamos criar algum conteúdo a partir da pasta static, lembrando que já havíamos criado a estrutura de diretórios dentro dessa pasta. Deste modo, crie o arquivo index.html em static com o código demonstrado na Listagem 7.
Listagem 7. Conteúdo da página index.html.
<!DOCTYPE html>
<html>
<head>
<link rel="stylesheet" type="text/css" href="css/style.css">
<title>My web server</title>
</head>
<body>
<h1>Index</h1>
Go to <a href="teste.html">test</a>
</body>
</html>Como vocę pode notar nesse pequeno arquivo HTML, importamos o estilo css/style.css e definimos um link com a famosa tag <a> para outra página HTML, chamada teste.html. Nesse momento, se recarregarmos o browser, seremos capazes de visualizar algum conteúdo, que seria todo o conteúdo da página index.html que acabamos de criar. Porém, como ainda năo criamos o estilo style.css, nossa página aparecerá sem nenhuma formataçăo, como pode ser observado na Figura 5. Também, se tentarmos clicar no link, nenhum conteúdo será exibido, pois também ainda năo criamos a página teste.html.
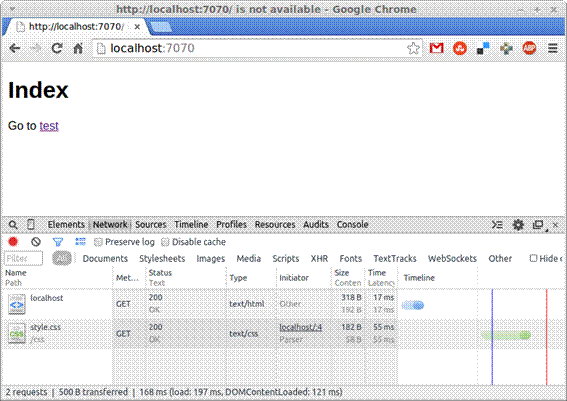
Agora já é possível ver o conteúdo de index.html que, embora năo tenhamos especificado ao chamar a URL http://localhost:7070, declaramos em nossa aplicaçăo que, na ausęncia deste, o index.html seria automaticamente escolhido pelo servidor web.
Nas ferramentas do desenvolvedor do browser, localizadas na parte inferior do browser, se vocę acessar a aba de rede, poderá notar que temos o código de sucesso 200, referente ao index.html, e um erro 404, referente ao arquivo style.css, que ainda năo definimos. Para solucionar esse problema, crie o arquivo style.css na pasta css com o conteúdo da Listagem 8.
Listagem 8. Conteúdo do arquivo style.css.
body {
font-family: arial, helvetica;
font-size: 16px;
}Como pode ser notado, este CSS é um arquivo bem simples, apenas para modificar o estilo da fonte, visto que nosso objetivo aqui é testar o servidor web. Ao carregar a página novamente, vocę verá algo semelhante ao demonstrado na Figura 6.
Agora que definimos o estilo CSS para nossa página index.html e vimos que a página ficou mais bonita, tendo seu texto formatado, resta criar o conteúdo de teste.html. Com esta pendęncia, já sabemos que o link que aponta para teste.html irá falhar, entăo, antes de clicar no link, crie o arquivo teste.html na pasta static. Seu conteúdo pode ser visualizado na Listagem 9.
Listagem 9. Arquivo teste.html, chamado por um link da página index.html.
<!DOCTYPE html>
<html>
<head>
<title>My test page</title>
<link rel="stylesheet" type="text/css" href="css/style.css">
</head>
<body>
<h1>Hello world</h1>
<img src="image/logo.jpg">
<p>Go back to <a href="index.html">the index page</a>.</p>
<script type="text/javascript" src="script/app.js"></script>
</body>
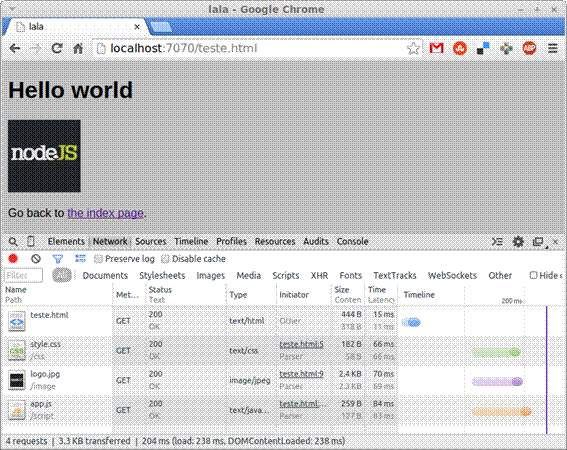
</html>Note que assim como em index.html, a página teste.html importa o estilo style.css. Porém, além de importar tal arquivo de estilo, para demonstrar que nossa aplicaçăo está pronta para carregar mais tipos de arquivo além de arquivos HTML e CSS, teste.html também importa um arquivo JavaScript, do caminho script/app.js, e ainda carrega uma imagem (disponível em image/logo.png), com a tag <img>.
Para que seja possível carregar a imagem mencionada, copie-a para a pasta image. O código do script importado por teste.html pode ser visualizado na Listagem 10.
Listagem 10. Conteúdo do arquivo app.js
(function(window) {
var d = window.document,
b = d.body,
bStyle = b.style;
bStyle.backgroundColor = 'silver';
}(this));Mais uma vez o arquivo JavaScript é bastante simples, pois serve apenas para testarmos se nosso servidor web está funcionando corretamente. Nesse caso, nosso script pinta o fundo da tela de cinza claro.
Agora que criamos um conteúdo simples para testar as funcionalidades do servidor web, volte ao browser, recarregue a tela e entăo clique no link para ver se a página de teste funcionou, conforme a Figura 7.
Ao constatar que tudo correu bem, nosso teste estará completo e nosso servidor web estará pronto.
Esta é uma aplicaçăo simples em Node.js, porém, que pode năo parecer tăo simples para iniciantes devido ao número de tecnologias e conhecimentos prévios que o desenvolvedor precisa ter. Além disso, mesmo sendo uma aplicaçăo básica, ela demonstra diversos aspectos e recursos da tecnologia que vocę utilizará no dia a dia, caso siga em frente com o desenvolvimento com Node.js.
Caso esteja começando ou já teve algum contato inicial básico, uma boa sugestăo é prestar bastante atençăo nos seguintes pontos: primeiramente, a programaçăo orientada a eventos, que como reforçamos diversas vezes ao decorrer do artigo, é o coraçăo do Node.js; o sistema de carregamento de módulos, observando como exportar e importar corretamente módulos, objetos e funçőes, conteúdo demonstrado na importaçăo e exportaçăo dos módulos server e fileHandler(); e procure conhecer mais a fundo a biblioteca padrăo do Node.js, todos os seus recursos, como as facilidades que economizam a implementaçăo de coisas que já estăo prontas, como os módulos http e fs, conforme abordado no decorrer do nosso estudo.
Agora que vocę já tem uma noçăo da capacidade do Node.js e da quantidade de possibilidades que a tecnologia oferece, tente aprimorar o seu servidor web. Antes disso, no entanto, uma boa sugestăo é começar realizando uma cópia de segurança do código desenvolvido. Feito isso, tente deixar o servidor mais sofisticado. Aqui văo algumas sugestőes:
Outra sugestăo é tentar criar uma aplicaçăo do zero, como um servidor de echo (vocę envia uma mensagem a um servidor e ele te responde com a mesma mensagem), ou faça experięncias no CLI (Command Line Interface) do Node.js. Para isso, basta abrir um terminal e digitar o comando node. Vocę verá que o prompt de seu sistema operacional mudará para o CLI do Node.js, onde vocę pode começar a escrever qualquer código em JavaScript, que é a linguagem natural do Node,js. Para sair do CLI, basta digitar CTRL+C duas vezes.
Assim, vocę notará que o Node.js é uma tecnologia muito divertida de aprender e fácil de testar, e quanto mais vocę aprende, mais se interessa e acaba se aprofundando nos estudos.


Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.