


A maioria das aplicań§es que desenvolvemos, independente de plataforma, precisam fazer consultas a bancos de dados com frequĻncia. Os tipos de dados e valores utilizados sŃo vßrios e por isso as consultas devem estar adequadas Ós vßrias situań§es possĒveis.
Por exemplo, fazer uma consulta a uma tabela usando um valor inteiro como filtro ķ relativamente simples, pois esse tipo de dado ķ ōexatoö. Ou seja, um valor numķrico inteiro nŃo possui variań§es como acentos, mai·sculo ou min·sculo, etc.
Porķm, quando trabalhamos com colunas do tipo texto, enfrentamos esse tipo de dificuldade que muitas vezes atrapalham a realizańŃo de queries. O fator que mais causa problema com esse tipo de consulta ķ a variańŃo de letras mai·sculas e min·sculas. Afinal, o usußrio que estß buscando um registro em sua aplicańŃo, nŃo deve ser obrigado a saber exatamente como o texto estß escrito, se totalmente em mai·sculo, em min·sculo, ou com variań§es.
Suponha, por exemplo, uma tabela de clientes com a seguinte estrutura.

Figura 1: Estrutura da tabela de clientes
O usußrio de uma aplicańŃo que acesse essa tabela pode desejar pesquisar os clientes por c¾digo, nesse caso ele deve informar um valor inteiro e que serß facilmente localizado no banco de dados. Porķm, ele pode desejar consultar pelo nome ou endereńo do cliente, nesse caso, independente de como os dados estŃo gravados e de como o valor serß digitado no campo de busca da aplicańŃo, os registros devem ser recuperados. Para esses casos, precisamos de uma consulta CASE INSENSITIVE, ou seja, que desconsidere as diferenńas entre letras mai·sculas e min·sculas.
Alķm disso, a consulta nŃo pode perder desempenho por causa dessa dificuldade. Os resultados devem ser exibidos o mais rßpido possĒvel. Percebemos entŃo que serß necessßrio utilizar algum recurso para garantir o desempenho da aplicańŃo, como criar ═NDICES nas colunas de pesquisa.
Nesse artigo veremos como contornar essa situańŃo utilizando o banco de dados Firebird. SerŃo apresentadas soluń§es adequadas Ós vers§es 1.5, 2.0 e 2.1.2 desse SGBD.
Uma forma de realizar consultas case insensitive ķ converter tanto o texto da coluna quanto o valor buscado para mai·sculo. Porķm, esse mķtodo tem algumas limitań§es, pois nem todos os caracteres podem ser convertidos para mai·sculo, por exemplo, em alguns idiomas europeus.
Para evitar esse problema, ķ preciso definir o mesmo COLLATION para os dois textos, de forma a tornß-los compatĒveis. Como foi dado o exemplo das linguagens europeias, nesse artigo utilizaremos o collation DE_DE e o charset do banco ķ o ISO8859_1.
O collation pode ser definido no momento da criańŃo da tabela ou direto na consulta, como veremos a seguir.
Listagem 1: Definindo o collation na criańŃo da tabela
CREATE TABLE CLIENTES
(
CODIGO INT NOT NULL PRIMARY KEY,
NOME VARCHAR(100) COLLATE DE_DE,
ENDERECO VARCHAR(100) COLLATE DE_DE
)Listagem 2: Definindo o collation na consulta
SELECT CODIGO, NOME COLLATE DE_DE, ENDERECO COLLATE DE_DE
FROM CLIENTESEntŃo jß sabemos como contornar o problema de compatibilidade entre idiomas, resta agora aplicar um mķtodo para garantir o bom desempenho da consulta. A seguir veremos como resolver isso em algumas vers§es do Firebird.
Precisamos de um Ēndice para as colunas NOME e ENDERECO, mas a consulta nŃo serß feita diretamente pelo valor da coluna, pois este serß convertido para mai·sculo. Como no Firebird 1.5 nŃo ķ possĒvel definir um Ēndice que funcione sobre uma funńŃo, uma saĒda ķ criar colunas cujo valor serß o conte·do do nome e endereńo jß convertidos para mai·sculo. Essas colunas podem ser preenchidas em um trigger que seja executado em inserń§es e alterań§es.
Os c¾digos a seguir mostram como fazer isso.
Listagem 3: Criando a tabela com colunas auxiliares
CREATE TABLE CLIENTES
(
CODIGO INT NOT NULL PRIMARY KEY,
NOME VARCHAR(100) COLLATE DE_DE,
NOME_MAIUSC VARCHAR(100) COLLATE DE_DE,
ENDERECO VARCHAR(100) COLLATE DE_DE,
ENDERECO_MAIUSC VARCHAR(100) COLLATE DE_DE
)TerĒamos entŃo o seguinte trigger para preencher as colunas auxiliares.
Listagem 4: Trigger para preencher as colunas auxiliares
CREATE TRIGGER TGR_CLIENTES_BIU FOR CLIENTES
ACTIVE
BEFORE INSERT OR UPDATE
AS
BEGIN
NEW.NOME_MAIUSC = UPPER (NEW.NOME);
NEW.ENDERECO_MAIUSC = UPPER (NEW.ENDERECO);
ENDAgora sim podemos criar os Ēndices sobre as colunas em mai·sculo, pois elas serŃo utilizadas para consulta.
Listagem 5: Criando Ēndice sobre as colunas auxiliares
CREATE INDEX IDX_NOME ON CLIENTES (NOME_MAIUSC);
CREATE INDEX IDX_ENDERECO ON CLIENTES (ENDERECO_MAIUSC);Na consulta, bastaria aplicar o collate no texto a ser buscado, pois a coluna jß estß devidamente configurada.
Listagem 6: Consulta pelas colunas auxiliares
SELECT * FROM CLIENTES WHERE NOME_MAIUSC = UPPER(:BUSCA COLLATE DE_DE)
SELECT * FROM CLIENTES WHERE ENDERECO_MAIUSC = UPPER(:BUSCA COLLATE DE_DE)De fato essa soluńŃo ķ um tanto ōtrabalhosaö e requer vßrias linhas de c¾digo adicionais. Na versŃo 2.0 isso pode ser resolvido mais facilmente, como veremos a seguir.
Nessa versŃo foi inserido um recurso que permite criar Ēndices sobre express§es e nŃo apenas sobre colunas ōpurasö. Nesse caso, podemos criar um Ēndice que funcione sobre as colunas NOME e ENDERECO jß aplicadas na funńŃo UPPER e com o collate.
Listagem 7: CriańŃo de Ēndices sobre a funńŃo UPPER
CREATE INDEX IDX_NOME ON CLIENTES COMPUTED BY (UPPER (NOME COLLATE DE_DE));
CREATE INDEX IDX_ENDERECO ON CLIENTES COMPUTED BY (UPPER (ENDERECO COLLATE DE_DE));Assim podemos fazer a consulta diretamente pelas colunas originais, utilizando a mesma expressŃo definida no Ēndice.
Listagem 8: Consulta pelas colunas originais com Ēndice
SELECT * FROM CLIENTES WHERE UPPER (NOME COLLATE DE_DE) = UPPER(:BUSCA COLLATE DE_DE)
SELECT * FROM CLIENTES WHERE UPPER (ENDERECO COLLATE DE_DE) = UPPER(:BUSCA COLLATE DE_DE)Como vemos, a soluńŃo nessa versŃo do Firebird ķ bem mais prßtica e simples de se aplicar. Porķm, veremos que na versŃo 2.1.2 ķ possĒvel fazer o mesmo utilizando ainda menos c¾digo.
A partir da versŃo 2.1.2 ķ possĒvel utilizar um novo collation chamado UNICODE_CI que funciona para o conjunto de caracteres UTF8, um padrŃo universal que busca eliminar incompatibilidades entre idiomas, reunindo vßrios tipos de sĒmbolos grßficos (caracteres).
Para definir o charset do banco de dados, basta selecionar a opńŃo correta no momento da criańŃo do mesmo. A figura a seguir mostra a tela de criańŃo de um database no IBExpert, note que hß um campo ōCharsetö em destaque, nele deve ser selecionada a opńŃo ōUTF8ö.
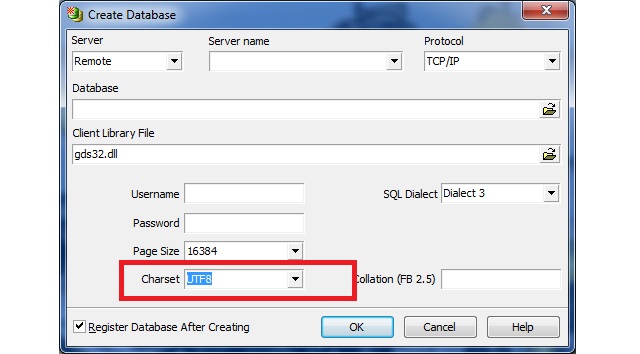
Figura 2: Definindo o charset do banco
O ōCIö no nome do collation significa exatamente CASE INSENSITIVE e faz com que na utilizańŃo da coluna sejam desconsideradas diferenńas entre letras mai·sculas e min·sculas.
Assim, poderĒamos alterar o c¾digo da Listagem 1 para usar esse novo collation.
Listagem 9: Criando a tabela com o collation UNICODE_CI
CREATE TABLE CLIENTES
(
CODIGO INT NOT NULL PRIMARY KEY,
NOME VARCHAR(100) COLLATE UNICODE_CI,
ENDERECO VARCHAR(100) COLLATE UNICODE_CI
)Com isso, a criańŃo dos Ēndices poderia ser feita da forma mais comum, como vemos a seguir.
Listagem 10: CriańŃo dos Ēndices normalmente
CREATE INDEX IDX_NOME ON CLIENTES(NOME);
CREATE INDEX IDX_ENDERECO ON CLIENTES(ENDERECO);A consulta tambķm nŃo precisaria ter o collation ou a funńŃo UPPER.
Listagem 11: Consulta usando o collation UNICODE_CI
SELECT * FROM CLIENTES WHERE NOME = :BUSCA
SELECT * FROM CLIENTES WHERE ENDERECO = :BUSCACom a introduńŃo do collation UNICODE_CI, a realizańŃo de consultas case insensitive se tornou bem mais simples (vale lembrar que esse collation foi criado para o charset UTF8, caso esse nŃo seja o charset do banco, essa soluńŃo nŃo irß funcionar). Porķm, nem sempre ķ possĒvel migrar a versŃo do banco, portanto, aqui foram apresentadas soluń§es para trĻs diferentes vers§es do Firebird.
Espero que as informań§es apresentadas nesse artigo possam ser ·teis. Atķ a pr¾xima oportunidade.


Utilizamos cookies para fornecer uma melhor experiĻncia para nossos usußrios, consulte nossa polĒtica de privacidade.