


Neste artigo vamos usar o Elasticsearch para unir a aquisiçăo e a apresentaçăo de dados. Também desenvolvido pela Elastic (a mesma empresa que lidera o desenvolvimento do Elasticsearch) o Kibana será apresentado através de um exemplo prático usado a API de dados abertos da Prefeitura do Rio de Janeiro.
Esse artigo apresenta o Kibana, uma ferramenta para apresentaçăo de conteúdos que funciona muito bem com o Elasticsearch e com o Logstash.
O Kibana é parte da pilha ELK, composta também pelo Elasticsearch e o Logstash. O Elasticsearch é uma ferramenta de indexaçăo textual altamente difundida e o Logstash facilita a leitura de logs (em um sentido amplo do termo, que inclui qualquer tipo de dado que represente eventos e seja gerado de forma automática, em um formato bem definido e continuamente). Já o Kibana permite a criaçăo de gráficos a partir de dados indexados no Elasticsearch. A ideia do ELK é simples, mas muito interessante: o Logstash recebe os logs de distintas fontes, realiza transformaçőes, normaliza e agrupa os mesmos, indexa no Elasticsearch, e o Kibana, por sua vez, os apresenta de forma gráfica, como ilustrada na Figura 1.

Figura 1. Pilha ELK
A motivaçăo por trás do Kibana é que a maioria dos dados podem ser apresentados através de um conjunto básico de modelos de visualizaçăo. Assim, essa ferramenta permite a criaçăo de diversos tipos de gráficos, de linhas de tendęncias e de mapas.
Para usar o ELK, obviamente, é necessário ter o Elasticsearch instalado e em execuçăo. Assim, em uma máquina com Java instalado, deve-se baixar a última versăo do site do Elasticsearch (vide seçăo Links), desempacotá-la e executar o seguinte comando:
./bin/ElasticsearchSe tudo ocorreu bem, pode-se chamar localhost:9200 em um navegador e o Elasticsearch irá retornar uma resposta JSON, conforme ilustrado na Listagem 1. Nessa resposta o parâmetro name provavelmente irá variar para cada leitor, pois é escolhido de forma aleatória (em resumo, năo se preocupe se a resposta JSON năo for exatamente igual a Listagem 1).
Listagem 1. Resposta do Elasticsearch
{
"status" : 200,
"name" : "Alistaire Stuart",
"cluster_name" : "elasticsearch",
"version" : {
"number" : "1.4.5",
"build_hash" : "2aaf797f2a571dcb779a3b61180afe8390ab61f9",
"build_timestamp" : "2015-04-27T08:06:06Z",
"build_snapshot" : false,
"lucene_version" : "4.10.4"
},
"tagline" : "You Know, for Search"
}Para instalar o Logstash deve-se seguir os passos seguintes passos de instalaçăo:
Finalmente, para instalar o Kibana deve-se ir a sua página no site da Elastic (vide seçăo Links), fazer download da última versăo, desempacotá-la e executar o comando kibana (no Windows use kibana.bat). Para verificar se o Kibana foi iniciado com sucesso, acesse http://localhost:5601/ e a tela de entrada do Kibana deverá ser muito parecida com a Figura 2.
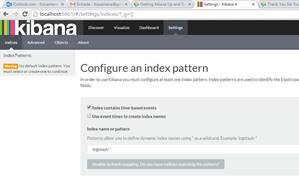
Figura 2. Kibana carregando.
Nesse artigo será apresentado um exemplo de como criar um dashboard usando a API de dados abertos para posicionamento dos ônibus Cariocas (veja o endereço na seçăo Links). As informaçőes săo compartilhadas em formato CSV, conforme apresentado na Listagem 2. Existe também uma versăo dessa mesma API na qual os dados săo compartilhados em formato JSON (seçăo Links), porém a versăo CSV foi escolhida para esse exemplo, pois năo teria o mesmo sentido utilizar o Logstash em dados que já estăo no formato JSON.
Listagem 2. Exemplo de dados abertos da Prefeitura do Rio de Janeiro
dataHora,ordem,linha,latitude,longitude,velocidade
07-13-2015 00:00:29,B63056,,"-22.8676","-43.2585",0
07-13-2015 00:44:12,D53744,846,"-22.88271","-43.49538",30
07-13-2015 01:35:11,A37510,,"-22.81443","-43.325508",0
07-13-2015 02:44:19,B42537,,"-22.8764","-43.3296",0
07-13-2015 03:01:52,D87185,,"-22.916969","-43.608009",0 Assim, o primeiro ponto é configurar o Logstash para extrair as informaçőes necessárias para a criaçăo dos dashboards do Kibana.
Devemos criar um input para receber os dados do arquivo CSV. Nesse caso, poderia ser usado um input do tipo websocket (seçăo Links), que permite a leitura de dados diretamente de uma página na Web, em lugar de se ler um arquivo local ao sistema operacional. Entretanto, esse plugin ainda está em fase de desenvolvimento, portanto nesse artigo vamos ler a entrada diretamente a partir do arquivo.
Assim, a Listagem 3 apresenta a configuraçăo de entrada para as informaçőes de ônibus vindas da API de dados abertos. Nesse exemplo, o arquivo foi nomeado onibus.csv e foi copiado para o diretório c:/tmp. Além disso, no campo type demos o nome de onibus-csv para os logs entrados por esse arquivo e definimos que a leitura será feita a partir do início do arquivo. Além disso, nessa mesma listagem apresenta-se a saída para o Elasticsearch contendo o host e nome do índice da instalaçăo do Elasticsearch.
Listagem 3. Input de dados abertos da Prefeitura do Rio de Janeiro
input {
file {
path => "c:/tmp/onibus.csv"
type => "onibus-csv"
start_position => "beginning"
}
}
output {
elasticsearch {
codec => rubydebug
host => "localhost"
index => "devmedia"
protocol => "http"
}
stdout {
codec => rubydebug
}
}Para facilitar o desenvolvimento os exemplos utilizarăo o Sense (seçăo Links), que é um plugin para o Google Chrome que atua como um cliente enviando chamadas REST/HTTP, conforme apresentado na Figura 3. O primeiro passo nesse caso é criar um índice chamado devmedia, usando o comando:
PUT devmediaRepare que esse link for referenciado na última listagem.
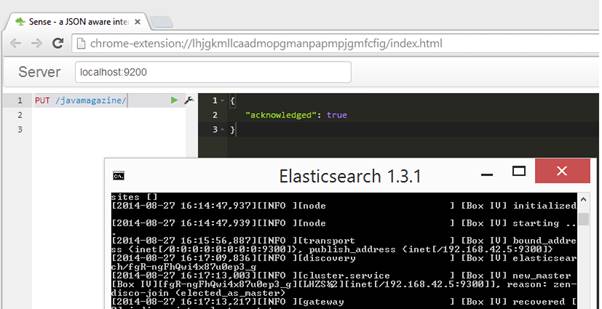
Figura 3. Plugin Sense.
Na sequęncia deve ser criado um tipo nesse índice chamado onibus-csv. Caso năo criemos esse tipo, os dados enviados para o Elasticsearch serăo tratados como string, isso seria um problema para o campo velocidade, latitude e longitude. A Listagem 4 mostra como fazer isso, onde criamos os campos que serăo recebidos pelo Logstash.
Listagem 4. Tipo onibus-csv
POST /devmedia/onibus-csv/_mapping
{
"onibus-csv": {
"properties": {
"linha": {
"type": "string"
},
"datahora": {
"type": "date"
},
"velocidade": {
"type": "double"
},
"localizacao": {
"type": "geo_point"
}
}
}
} Isso é suficiente para enviar os dados para o Elasticsearch. Entretanto, podemos ver na Figura 4 que os dados săo enviados ao Elasticsearch como uma mensagem única, ou seja, toda mensagem é inserida no campo message sem que os dados de data e hora, ordem, linha, latitude, longitude e velocidade estejam divididos.
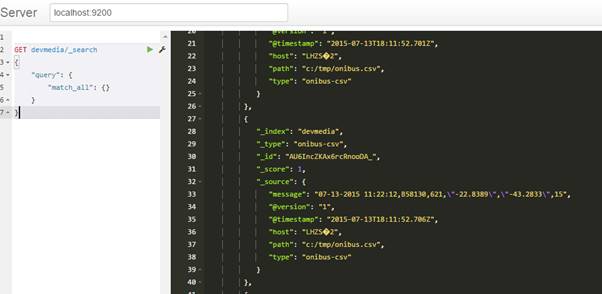
Figura 4. Dados enviados para o Elasticsearch.
Assim, para que os dados sejam apresentados de forma mais elaborada no Kibana, devemos fazer algumas transformaçőes usando os filters. Nesse artigo, os seguintes filters văo ser usados: CSV, Grok, Date e Range. Obviamente, o primeiro filtro a ser utilizado é o CSV, pois esse será responsável por extrair as informaçőes lidas da API de dados abertos, conforme mostra a Listagem 5. Devemos definir o padrăo de entrada, que no caso săo as mesmas colunas do arquivo definidas anteriormente. Além disso, define-se a vírgula como separador.
Listagem 5. Filtro CSV para os dados abertos da Prefeitura do Rio de Janeiro
filter {
csv {
columns => ["dataHora","ordem","linha","localizacao.lat","localizacao.lon","velocidade"]
separator => ","
}
}A Listagem 6 apresenta o filtro Date, que irá garantir que os valores lidados do log tenham o formato correto para sua data e hora.
Listagem 6. Filtro Date
filter {
date {
match => [ " dataHora", "MMM dd YYYY HH:mm:ss" ]
}
}O próximo passo é a Listagem 7, que irá filtrar apenas os ônibus que estăo em movimento, ou seja, os quais o campo velocidade seja maior que 0. Para isso, o filtro mutate será necessário, pois transforma o valor de entrada para a velocidade no tipo float, garantindo que as linhas que tenham valor de velocidade 0 sejam ignorados.
Listagem 7. Filtro de velocidade.
mutate {
convert => [ "velocidade", "float" ]
}
if (["velocidade"]==0) {
drop{}
}O arquivo logstash.conf tem o mesmo formato que o apresentado na Listagem 8, ou seja, cada uma das partes deveria estar inserida em input, filter e output.
Listagem 8. Formato do arquivo logstash.conf
input {...
}
filter {...
}
output {...
}Com esse arquivo completo, pode-se entăo iniciar o Logstash com o seguinte comando:
logstash agent -f logstash.conf -l log1.txt –debugOnde o parâmetro -l irá definir onde os logs do próprio Logstash serăo escritos e --debug definirá o nível de log para debug.
O Logstash tenta evitar que dados repetidos sejam processados várias vezes, por isso, ele gerencia o tamanho do arquivo de entrada. Como apresentado na Listagem 9, se o tamanho do arquivo continua o mesmo, nada é enviado ao Elasticsearch. Assim, se tentarmos executar o comando de execuçăo do logstash novamente, nada será enviado ao Elasticsearch. Isso é destacado em: sincedb last value 411899, cur size 411899.
Para alterar esse comportamento, adicione a seguinte linha, a fim de evitar o armazenamento e recuperaçăo dessa informaçăo:
sincedb_path => "/dev/null"Listagem 9. Arquivo logstash.conf completo
{:timestamp=>"2015-07-13T16:28:49.510000-0300", :message=>"c:/tmp/onibus.csv: sincedb last value 411899, cur size 411899", :level=>:debug, :file=>"/Users/Luiz/Desktop/Campus Party - Exemplo/logstash-1.5.2/logstash-1.5.2/vendor/bundle/jruby/1.9/gems/filewatch-0.6.4/lib/filewatch/tail.rb", :line=>"146", :method=>"_open_file"}
{:timestamp=>"2015-07-13T16:28:49.515000-0300", :message=>"c:/tmp/onibus.csv: sincedb: seeking to 411899", :level=>:debug, :file=>"/Users/Luiz/Desktop/Campus Party - Exemplo/logstash-1.5.2/logstash-1.5.2/vendor/bundle/jruby/1.9/gems/filewatch-0.6.4/lib/filewatch/tail.rb", :line=>"148", :method=>"_open_file"}
{:timestamp=>"2015-07-13T16:28:49.522000-0300", :message=>"c:/tmp/onibus.csv: file grew, old size 0, new size 411899", :level=>:debug, :file=>"/Users/Luiz/Desktop/Campus Party - Exemplo/logstash-1.5.2/logstash-1.5.2/vendor/bundle/jruby/1.9/gems/filewatch-0.6.4/lib/filewatch/watch.rb", :line=>"96", :method=>"each"}Após executar esses comandos, já teremos os dados necessários para apresentá-los no Kibana. Porém, para entender o que está acontecendo atrás das cenas, vamos apresentar como executar as consultas que serăo posteriormente geradas no Kibana diretamente no Eleasticsearch. Com auxílio do Sense, vamos testar quatro consultas:
A Listagem 10 ilustra a consulta para agregaçăo, que permite saber quantos ônibus existem para cada linha naquele momento. Para descobrir se um certo ônibus está ou năo em funcionamento, usa-se nesse artigo o critério de que tempo de partida seja menor que uma hora, ou seja, por essa definiçăo todos trajetos tęm tempo máximo menor que uma hora.
Listagem 10. Agregaçăo por nome de linha
GET devmedia/_search
{
"query": {
"filtered": {
"query": {
"match_all": {}
},
"filter": {
"range": {
"datahona": {
"gte": "now-1h",
"lte": "now"
}
}
}
}
},
"aggs": {
"products": {
"terms": {
"field": "linha",
"size": 5
}
}
}
}Na Listagem 11 apresenta-se o uso de um filtro para garantir que apenas ônibus ativos durante um certo intervalo de tempo. Isso é representado através das leituras de GPS anteriores a duas horas, entre duas e uma hora e mais recentes que uma hora.
Listagem 11. Filtro do tipo range
GET devmedia/_search
{
"query": {
"match_all": {}
},
"aggs": {
"range": {
"date_range": {
"field": "dataHora",
"ranges": [
{ "to": "now-2h" },
{ "from": "now-2h", "to": "now-1h" } ,
{ "from": "now-1h" }
]
}
}
}
}}A Listagem 12 seleciona os ônibus que estejam dentro de um raio de 10 quilômetros do ponto do centro do Rio de Janeiro (cuja latitude e longitude săo respectivamente -22,9034011 e -43,1916759), inserido no filtro geográfico geofilter. Além disso, para uma apresentaçăo mais interessante, os resultados săo ordenados de acordo com sua distância em relaçăo ao ponto passado na consulta.
Listagem 12. Filtro por distância geográfica
{
"filtered" : {
"query" : {
"match_all" : {}
},
"filter" : {
"geo_distance" : {
"distance" : "10km",
"localizacao" : {
"lat" : -22,9034011,
"lon" : -43,1916759
}
}
}
}
} A Listagem 13 apresenta todos ônibus que tenham enviado sinais de GPS nos últimos 10 minutos. Além disso, como os resultados estăo agregados por linha, cada ônibus aparecerá apenas uma vez.
Listagem 13. Apresentaçăo dos registros mais recentes para cada linha
GET devmedia/_search
{
"query": {
"filtered": {
"query": {
"match_all": {}
},
"filter": {
"range": {
"datahona": {
"gte": "now-10m",
"lte": "now"
}
}
}
}
},
"aggs": {
"products": {
"terms": {
"field": "linha",
"size": 5
}
}
}
}Os resultados dessas consultas anteriores devem ser parecidos com a Listagem 14.
Listagem 14. Resultado das consultas
{
"took": 16,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 7039,
"max_score": 1,
"hits": [
{
"_index": "devmedia",
"_type": "onibus-csv",
"_id": "AU6JVRyIAx6rcRnooNbi",
"_score": 1,
"_source": {
"message": [
"07-13-2015 13:15:11,B10159,,\"-22.8153\",\"-43.1874\",0"
],
"@version": "1",
"@timestamp": "2015-07-13T21:32:10.790Z",
"host": "LHZS~2",
"path": "c:/tmp/onibus.csv",
"type": "onibus-csv",
"dataHora": "07-13-2015 13:15:11",
"ordem": "B10159",
"localizacao": {
"lat":"-22.8153",
"lon": "-43.1874"
},
"velocidade": 0
}
},
...
]
},
"aggregations": {
"range": {
"buckets": [
{
"key": "*-2015-07-13T20:08:00.328Z",
"to": 1436818080328,
"to_as_string": "2015-07-13T20:08:00.328Z",
"doc_count": 0
},
...
]
}
}
}Com as consultas prontas, pode-se criar os dashboards do Kibana. Para isso, serăo criadas quatro visualizaçőes, de acordo com as consultas apresentadas anteriormente, que ao final serăo reunidas em um só dashboard.
Primeiramente é necessário configurar o Kibana para apontar para o índice correto. Para tal, entre novamente na página inicial do Kibana no endereço http://localhost:5601/. Nessa página configure o acesso ao Kibana escolhendo devmedia na caixa de texto chamada ´Index name or pattern´, conforme ilustrado na Figura 5. Além disso, deve-se escolher o nome do campo que iremos usar para controlar a sequęncia do tempo, nesse caso datahora. Seria possível também utilizar um padrăo para o nome usando-se uma expressăo regular para isso (por exemplo, o padrăo devmed* iria configurar todos índices que comecem com as letras dev como acessíveis pelo Kibana).
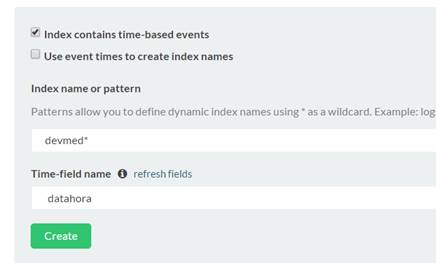
Figura 5. Configurando o uso do índice devmedia.
Após configurar o índice, o Kibana irá nos mostrar quais foram os campos que ele foi capaz de encontrar nesse índice (essa página foi omitida de apresentaçăo nesse artigo pois é apenas informativa).
Na sequęncia vamos criar a primeira visualizaçăo, que – como ilustrada na Figura 6 - nesse caso será um gráfico de linha (Line chart), já que a primeira consulta retornará todos ônibus disponíveis ao longo do tempo.
Figura 6. Criaçăo de uma nova visualizaçăo
Na próxima página (omitida por ser muito simples) devemos escolher “From a new search” para criarmos uma nova busca. A outra opçăo seria escolher uma consulta pré-salva, que poderá ser bastante útil em um projeto grande que evolua ao longo do tempo.
No último passo, teremos uma página parecida com a apresentada na Figura 7, na qual podemos criar uma consulta usando as ferramentas visuais.
Figura 7. Criar nova busca.
Como exemplo, podemos recriar a primeira consulta apresentada anteriormente. A Figura 8 ilustra o resultado para a seguinte sequęncia de configuraçőes:
O resultado é o mesmo da consulta diretamente no Sense, onde teremos um gráfico apresentando o número de registro para cada linha. A criaçăo das outras consultas segue a mesma lógica dessa consulta apresentada, porém, como essas ferramentas săo bastante completas e fáceis de se utilizar, deixamos a cargo do leitor explorá-las e dominá-las.
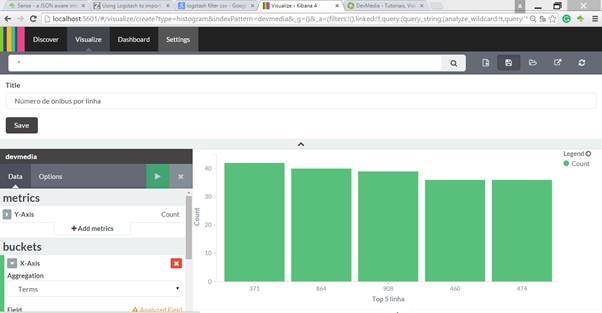
Figura 8. Agregaçăo por linhas
No último passo vamos salvar essa visualizaçăo usando o segundo botăo do menu superior e escolhendo um título para essa visualizaçăo.
Todas consultas tem a mesma forma. Entăo, com essas quatro consultas, podemos finalizar esse resultado com um dashboard que unifique a visăo sobre os documentos. Assim, para criar um iremos na aba Dashboard e clicaremos no primeiro ícone do lado direito (o que tem um símbolo de soma dentro de um círculo), conforme ilustrado na Figura 9. Uma lista de visualizaçőes será apresentada, e posteriormente, podemos agregar uma série delas em um mesmo dashboard. Ao final, usaremos novamente o símbolo para salvar esse dashboard.
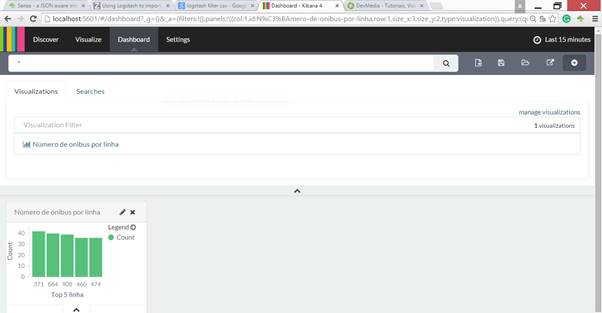
Figura 9. Criaçăo de dashboards.
Veja que com a interface fica bem fácil criar as várias consultas que ainda devemos criar.
Com isso, espero que tenham gostado do artigo. Até a próxima.
Links
Elasticsearch
https://www.elastic.co/products/elasticsearch
Logstash
https://www.elastic.co/products/logstash
Kibana
https://www.elastic.co/products/kibana
Ônibus Carioca em CSV
http://dadosabertos.rio.rj.gov.br/apiTransporte/apresentacao/csv/onibus.cfm
Ônibus Carioca em JSON
http://dadosabertos.rio.rj.gov.br/apiTransporte/apresentacao/rest/index.cfm/obterTodasPosicoes
Plugin WebSocket
https://github.com/logstash-plugins/logstash-input-websocket
Sense
https://github.com/bleskes/sense


Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.