


Desenvolvido pela Elastic (a mesma empresa que lidera o desenvolvimento do Elastichsearch), o Logstash é um pipeline de dados que ajuda a processar logs (que podem ser, de forma mais abstrata, registros e outros dados de eventos) a partir de uma variedade de sistemas. Com 165 plugins, o Logstash pode se conectar a uma variedade de fontes e permite a criaçăo de sistema de análise central altamente escalável. Além disso, com o fim dos conectores do tipo River (removidos na versăo 1.5), o Logstash passou a ser definitivamente a melhor forma de conectar-se com bases de dados SQL .
O Logstash é parte da pilha ELK, composta também pelo Elasticsearch e o Kibana. O Elasticsearch é uma ferramenta de indexaçăo textual altamente difundida e o Kibana permite a criaçăo de gráficos a partir de dados indexados no Elasticsearch. A ideia do ELK é simples e muito interessante, como ilustrada na Figura 1: o Logstash recebe os logs de distintas fontes, realiza as transformaçőes, normaliza e agrupa os mesmos, indexa no Elasticsearch, e o Kibana, por sua vez, os apresenta de forma gráfica.

Figura 1. Pilha ELK.
A motivaçăo por trás do Logstash é que dados essenciais aos negócios estăo geralmente espalhados entre diversos sistemas, cada um no seu próprio formato. Logstash permite analisar esses dados e transformá-los para um formato único antes de inseri-lo no Elasticsearch ou em outra ferramenta de análises de sua escolha. Além disso, como a maioria dos registros escritos por infraestrutura e aplicaçőes tęm formatos personalizados, o Logstash fornece uma maneira rápida, conveniente e personalizada para analisar esses logs em grande escala.
Para instalar o Logstash năo é necessário ter o Elasticsearch instalado ou em execuçăo, porém, nesse artigo as duas ferramentas văo ser utilizadas em conjunto. Assim, em uma máquina com Java instalado, deve-se baixar a última versăo do site do Elasticsearch, desempacotá-la e executar o seguinte comando:
./bin/elasticsearchSe tudo ocorreu bem, pode-se chamar localhost:9200 em um navegador e o Elasticsearch irá retornar uma resposta JSON, conforme ilustrado na Listagem 1. Nessa resposta, o parâmetro name provavelmente irá variar para cada leitor, pois é escolhido de forma aleatória (em resumo: năo se preocupe se a resposta JSON năo for exatamente igual a Listagem 1).
Listagem 1. Resposta do Elasticsearch
{
"status" : 200,
"name" : "Alistaire Stuart",
"cluster_name" : "elasticsearch",
"version" : {
"number" : "1.4.5",
"build_hash" : "2aaf797f2a571dcb779a3b61180afe8390ab61f9",
"build_timestamp" : "2015-04-27T08:06:06Z",
"build_snapshot" : false,
"lucene_version" : "4.10.4"
},
"tagline" : "You Know, for Search"
}Para instalar o Logstash deve-se seguir os passos seguintes passos de instalaçăo:
No exemplo apresentado nesse artigo as entradas virăo de logs do Apache Web Server e de um servidor de e-mail. A ideia apresentada na Figura 2 é que esses logs sejam filtrados usando, por exemplo, o Grok, o GeoIP, o Data e o Anonymize (explicados na sequęncia) e enviados ao Elasticsearch. Assim, existem tręs abstraçőes principais no Logstash:
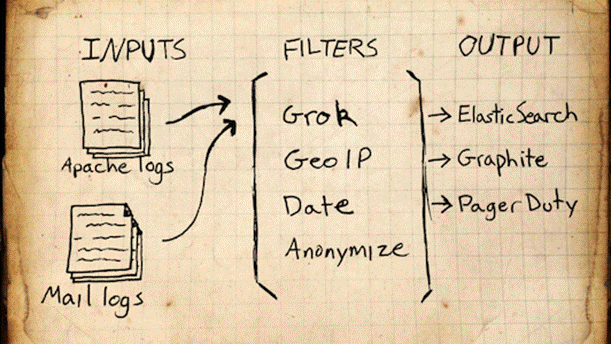
Figura 2. Arquitetura do exemplo.
Os tipos de entradas (ou inputs) para o Logstash săo os mais variados possíveis, entre os quais destacam-se logs de servidores (por exemplo: Apache, Tomcat, Glasfish), arquivos de e-mail, bancos SQL, e outros tipos de arquivo. A Listagem 2 apresenta como declarar um input no arquivo logstash.conf. Deve-se dizer qual é o caminho para acessar os logs no sistema de arquivos, o tipo (que é meramente um nome para referęncia posterior) e a posiçăo de onde o Logstash deve começar a analisar o arquivo.
Listagem 2. Input de logs do Apache
input {
file {
type => "apache-access"
path => "/var/log/apache.log"
start_position => "beginning"
}
}A Listagem 2 é um bom começo, mas năo o suficiente. Imagine a seguinte situaçăo: vocę quer que o Logstash leia os valores dos logs do MySQL a cada segundo (imagine um ambiente com muito processamento), além disso, podemos ativar o debug para saber o que está acontecendo durante o desenvolvimento, e finalmente, no lugar de buscar um arquivo específico, podemos analisar toda a pasta /var/log/mysql/*, mas evitar os arquivos com o final .gz. A Listagem 3 apresenta o input para os logs do MySQL.
Listagem 3. Input de logs do MySQL
input {
file {
type => "mysql"
start_position => "beginning"
debug => true
discover_interval => 1
path => "/var/log/mysql/*"
exclude => "*.gz"
}
}Uma vez que foi configurada as entradas de dados é necessário que as mesmas sejam analisadas e seus valores estruturados. Para tal, a linguagem Grok é atualmente a melhor maneira em logstash para analisar e transformar dados de log năo estruturados em algo estruturado e passível de consulta. Aqui uma dica é importante: para verificar se seu script Grok está executando corretamente ou mesmo encontrar onde está algum tipo de falha é recomendado utilizar o debugger para Grok (vide seçăo Links).
O Grok é uma ferramenta perfeita para logs como syslog, apache e outros logs de servidor web, logs de MySQL, e em geral, qualquer formato de registro, que é escrito para o homem e năo para o consumo do computador. A Listagem 4 apresenta como filtrar apenas mensagens de log do Apache.
A primeira parte do filtro verifica se o valor filtrado vem do input apache-access, na sequęncia garante que só registros que contenham o valor COMBINEDAPACHELOG sejam enviados para a saída.
Listagem 4. Filtro com Grok
filter {
if [type] == "apache-access" {
grok {
match => [ "message", "%{COMBINEDAPACHELOG}" ]
}
}
}Antes de listar os tipos de filtro disponíveis é importante saber que nem todos os filtros estăo disponíveis na distribuiçăo padrăo do Logstash. Para usar esses filtros deve-se instalar plugins, sendo o mais importante chamado de contrib. Para instalar essa ferramenta de forma padrăo deve-se navegar até o diretório de instalaçăo do Logstatsh e executar o comando bin/plugin install contrib.
Além do Grok, a seguir veremos exemplos para alguns tipos de filtros.
Esse filtro retém registros do log de acordo com um valor temporal. Por exemplo, năo maiores que uma certa data, ou a partir de um dia e hora específico. Na Listagem 5 apresenta-se o uso desse plugin.
Listagem 5. Filtro de datas
filter {
date {
match => [ "logdate", "MMM dd YYYY HH:mm:ss" ]
}
}Permite filtrar elementos que năo contenham um certo padrăo de caracteres. Conforme a Listagem 6, o grep evita que registro com certos valores sejam enviados ao Elasticsearch. Esse filtro é parte do pacote contrib.
Listagem 6. Filtro Grep
filter {
grep{
match => [ "message", "valor" ]
}
}Esse filtro substitui valores de campos usando um hash consistente (ou seja, é possível fazer correlaçőes entre os valores substituídos), a fim de năo revelar números de documentos, nomes de pessoas, ou outras informaçőes sensíveis. Pode-se definir diversos campos para isso, usando o fields e além disso, devemos dizer qual é a chave, ou seja, o valor que será substituído. O algoritmo para geraçăo do novo valor pode ser "SHA1", "SHA256", "SHA384", "SHA512", "MD5", "MURMUR3" ou "IPV4_NETWORK", sendo "SHA1" o padrăo. Veja um exemplo na Listagem 7.
Listagem 7. Filtro Anonymize
filter {
anonymize {
fields => ["address", "firstname", "lastname", "secretData"]
key => "valor"
algorithm => "SHA256"
}
}Esse filtro toma um campo de evento que contém dados CSV, analisa-o e guarda-o como campos individuais (opcionalmente pode especificar os nomes). Este filtro também pode analisar os dados com qualquer separador, năo apenas vírgulas. A Listagem 8 apresenta um exemplo que contém nomes para as colunas e usa como separador pipe em lugar da vírgula.
Listagem 8. Filtro CSV
filter {
csv {
columns => ['A','B','C','D','E']
separator => "|"
}
}Oferece um filtro til para a exclusăo de mensagens duplicadas ou simplesmente para proporcionar um identificador único. Deve ser usado com cuidado, pois ainda é experimental. A Listagem 9 apresenta um exemplo de como usar o filtro checksum.
Listagem 9. Filtro Checksum
filter {
checksum {
add_field => { "campo_%{somefield}" => "Campo do host %{host}" }
}
}Esse filtro adiciona informaçőes sobre a localizaçăo geográfica de endereços IP, com base em dados do banco de dados MaxMind. O campo criado armazena as informaçőes no formato GeoJSON e, quando enviado para o Elasticsearch, mapeia para um campo geo_point ElasticSearch. A Listagem 10 apresenta o filtro GeoIP, onde o único campo obrigatório é o source, que define onde está o IP que será transformado em latitude e longitude. Além disso, pode-se definir qual é o campo de saída usando o target, qual base de dados será usada (no caso GeoLiteCity.dat) e adicionar campos ao pipeline (no caso longitude e latitude).
Listagem 10. Filtro GeoIP
geoip {
source => "clientip"
target => "geoip"
database => "/etc/logstash/GeoLiteCity.dat"
add_field => [ "[geoip][coordinates]", "%{[geoip][latitude]}" ]
add_field => [ "[geoip][coordinates]", "%{[geoip][longitude]}" ]
}Permite verificar se os registros estăo dentro de valores esperados. Săo suportados números e strings, sendo que os números devem estar dentro do intervalo valor numérico e a string respeitar um certo comprimento. Como ilustrado na Listagem 11, para usar o filtro range deve-se definir sobre qual campo se está trabalhando, o tamanho mínimo e máximo que deve ser considerado e o valor de saída.
Listagem 11. Filtro Range
range {
ranges => [
"message", 0, 10, "tag:short",
"message", 11, 100, "tag:medium",
"message", 101, 1000, "tag:long",
"message", 1001, 1e1000, "drop"
]
}Recebe um campo que contém XML e o expande de acordo com sua estrutura. A Listagem 12 apresenta um exemplo desse filtro, onde define-se que os valores do campo message serăo expandidos.
Listagem 12. Filtro XML
filter {
xml {
source => "message"
}
}Permite descodificar os campos que contenham URLs. A Listagem 13 apresenta um exemplo desse campo, onde o mais interessante é que podemos definir o charset de decodificaçăo (no caso foi usado o ISO-8859-7), mas o padrăo é o UTF-8.
Listagem 13. Filtro Urldecode
filter {
urldecode {
charset => "ISO-8859-7"
add_tag => [ "foo_%{somefield}", "taggedy_tag"]
}
}Permite mutaçőes gerais sobre campos. Vocę pode renomear, remover, substituir e modificar os campos em seus eventos. Na Listagem 14 esse filtro irá converter os valores do campo idade em inteiros, irá unir os valores do array entrada (caso o campo năo seja um array, o logstash irá ignorá-lo) e transformar os valores do campo nome em letras minúsculas.
Listagem 14. Filtro Mutate
filter {
mutate {
convert => { "idade" => "integer" }
join => { "entradas" => "," }
lowercase => [ "fieldname" ]
}
}Permite remover eventos com base em uma whitelist/blacklist de nomes de campo ou seus valores (nomes e valores também podem ser expressőes regulares). Na Listagem 15 apresenta-se como utilizar o prune para garantir que só eventos com os campos method, referrer, status ou que termine com field sejam enviados ao Elasticsearch.
Listagem 15. Filtro Prune
filter {
prune {
add_tag => [ "pruned" ]
whitelist_names => [ "method", "(referrer|status)", "${some}_field" ]
}
}Os filtros podem ser combinados com o Grok. Por exemplo, na Listagem 16 apresenta-se como combinar o Grok e um filtro de Date e Mutate. Como pode-se notar, um filtro só pode ter várias partes, ou seja, formará um pipeline (uma sequęncia) por onde a informaçăo vai fluir.
Listagem 16. Combinando Filtro com Grok com Data
filter {
if [path] =~ "access" {
mutate {
replace => { type => "apache_access" }
}
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
} else if [path] =~ "error" {
mutate { replace => { type => "apache_error" } }
} else {
mutate { replace => { type => "random_logs" } }
}
}Finalmente, devemos criar um output para que as informaçőes de log sejam inseridas no Elastisearch. A Listagem 17 apresenta essa atividade, sendo que devemos escolher: o host, a porta, o índice que já deve estar criado previamente, e o protocolo de envio.
Sobre o protocolo de envio, além do HTTP, que usa uma conexăo RESTful para comunicar-se com o Elasticsearch, pode-se usar os tipos node e transport.
O protocolo node irá se conectar ao cluster como um nó normal de um cluster Elasticsearch, permitindo, por exemplo, fazer descoberta multicast (ou seja, năo seria necessário especificar o host e porta do Elasticsearch).
Para usar o protocolo node deve-se liberar a comunicaçăo bidirecional na porta 9300 da máquina onde o Logstash está conectado. O protocolo transport vai se conectar ao host também usando o protocolo de comunicaçăo usado entre os nós do Elasticsearch, mas nesse caso, o Logstash năo vai aparecer como mais um nó do cluster. Isso é interessante quando năo se pode liberar o acesso bidirecional entre o Logstash e o Elasticsearch.
Listagem 17. Criar um output
output {
elasticsearch {
host => "localhost"
port => 80
index => "devmedia"
protocol => "http"
}
}Para que seja possível usar o Logstash, deve-se criar o índice devmedia. Para a criaçăo desse índice, pode-se usar o Sense (vide seçăo Links), que é um plugin para o Google Chrome que atua como um cliente enviando chamadas REST/HTTP. Conforme ilustrado na Figura 3, o comando PUT /devmedia/ irá criar um índice chamado devmedia.
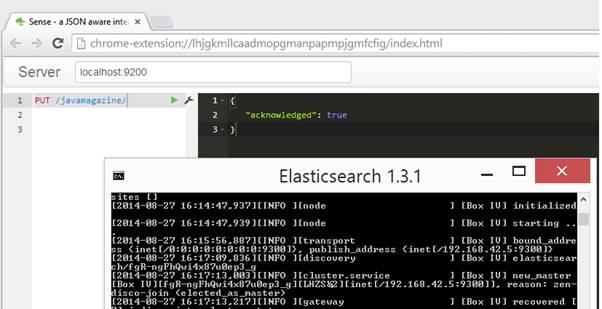
Figura 3. Sense no Chrome.
Para começar a enviar seus registros, vocę terá que baixar Logstash e colocar os trechos de configuraçăo vistos no arquivo logstash.conf. Em seguida, é preciso iniciar o Logstash com o comando:
bin/logstash agent -f logstash.confUma vez que os registros estejam registrados no índice, esses podem ser explorados usando Kibana ou as próprias buscas do Elasticsearch.
O Logstash foi construído com extensibilidade em mente, por isso fornece uma API para o desenvolvimento de plugins. Dessa forma, a comunidade pode publicar novos plugins a qualquer momento. Um dos principais plugins para Logstash é o Logstash Forwarder (vide seçăo Links), que facilita a entrada dos arquivos de log, pois permite que os mesmos sejam enviados através de um endereço de rede usando protocolos de transporte seguros.
A primeira providęncia é adicionar o Logstash Forwarder como uma entrada. A Listagem 18 mostra como fazer isso: deve-se criar um input do tipo lumberjack (esse era o nome antigo do Logstash Forwarder), a porta pela qual os logs chegarăo, os caminhos para os certificados SSL e o type que é apenas um nome.
Listagem 18. Configuraçăo do Logstash Forwarder
input {
lumberjack {
port => 12345
ssl_certificate => "path/to/ssl.crt"
ssl_key => "path/to/ssl.key"
type => "somelogs"
}
}Para instalar o Logstash Forwarder deve-se compilar seus códigos em Go (vide seçăo Links). Em seguida baixe o código do logstash-forwarder usando o Git e complie seu código da Listagem 19.
Listagem 19. Construir o Logstash Forwarder
git clone git://github.com/elasticsearch/logstash-forwarder.git
cd logstash-forwarder
go build -o logstash-forwarderOs autores do projeto Logstash-Fowarder recomendam que năo se use gccgo para compilar este projeto, caso contrário será produzido um binário com dependęncias para libgo o que inviabiliza a execuçăo independente do Logstash-Fowarder.
Os pacotes criados devem ser copiados em /opt/logstash-forwarder, e para execuçăo usa-se o seguinte comando:
logstash-forwarder -config logstash-forwarder.confO arquivo logstash-forwarder.conf deve ter a configuraçăo da Listagem 20, onde o campo network vai definir os parâmetros dos servidores para onde os logs devem ser enviados (no exemplo, 10.0.0.5:5043 e 10.0.0.6:5043), e o campo files quais săo os arquivos que serăo enviados para esses servidores.
Listagem 20. Construir o Logstash Forwarder
{
"network": {
"servers": [ "10.0.0.5:5043", “10.0.0.6:5043” ],
"ssl certificate": "/etc/ssl/certs/logstash-forwarder.crt",
"ssl key": "/etc/ssl/private/logstash-forwarder.key",
"ssl ca": "/etc/ssl/certs/logstash-forwarder.crt"
},
"files": [
{
"paths": [ "/var/log/syslog" ],
"fields": { "type": "iptables" }
},
{
"paths": [ "/var/log/apache2/*access*.log" ],
"fields": { "type": "apache" }
}
]
}O Logstash Forwarder permite a criaçăo de arquiteturas bastante complexas para o tratamento de logs. Por exemplo, a Figura 4 mostra como ele poderia ser usado em uma arquitetura que contaria também com duas instâncias do Logstash (uma para recebimento e outra para indexaçăo) e o Redis, além do Elasticsearch e do Kibana.
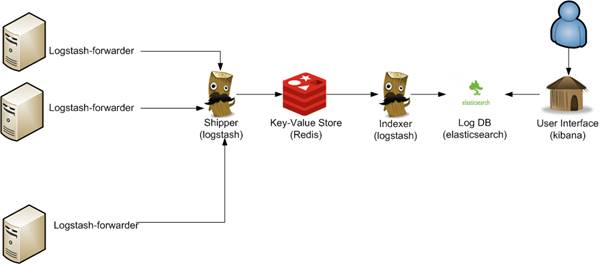
Figura 4. Arquitetura avançada usando o Logstash Forwarder
Links
Logstash
https://www.elastic.co/downloads/logstash
Debugger para Grok
http://grokdebug.herokuapp.com/
GeoIp para bancos MaxMind
http://www.maxmind.com/en/geolite
Sense
https://github.com/bleskes/sense
Forwarder
https://github.com/elastic/logstash-forwarder
Go
http://golang.org/doc/install


Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.