Data Mining: conceitos e casos de uso na área da saúde
Olá pessoal. Estamos de volta e nesta coluna vou conversar com vocęs sobre duas coisas que eu acho muito interessante, Mineraçăo de Dados e aplicaçőes na área da saúde. Minha área é bioinformática, mas aqui vou mostrar alguns cases no uso clínico, muito interessante, vale a pena ŕ leitura.
Bem para começar, data mining é a exploraçăo e a análise, por meio automático ou semi-automático, de grandes quantidades de dados, a fim de descobrir padrőes e regras significativas (Berry et al., 2000). Estes padrőes e regras significativas săo descritos muitas vezes como conhecimento invisível. Săo assim chamados por estarem envoltos em um grande volume de dados e que se năo fossem usadas técnicas inteligentes para procurar esta informaçăo, ou conhecimento, ele năo seria descoberto facilmente pela observaçăo humana. O conhecimento gerado pelo data mining pode ser usado para o gerenciamento de informaçăo, processamento de pedidos de informaçăo, tomada de decisăo, controle de processos, entre outros. Para realizar essa coleta, o processo de Data Mining agrega em suas etapas conhecimento de áreas como a Inteligęncia Artificial e Estatística. Os métodos de Inteligęncia Artificial dăo ao processo de mineraçăo o status de processo inteligente. Técnicas como redes neurais, árvores de decisăo, regras de associaçăo, raciocínio baseado em casos e algoritmos genéticos săo as mais usadas na construçăo deste processo. A estatística doa da sua parte diversas técnicas para agrupamento e análise de dados, uma das técnicas mais utilizadas em data mining é a regressăo, termo e cálculos, herdados da estatística tradicional.
1 - Técnicas
Como descrito na introduçăo deste trabalho, existem diversas técnicas utilizadas dentro do processo de data mining. Para deixar mais claro como o processo trabalha com estas técnicas, vamos descrevę-las um pouco melhor.
Estas técnicas săo utilizadas em diversas atividades (Gobel, et al.,1999) como:
- Previsăo: Dado um determinado item e um respectivo modelo, é a capacidade de deduzir um valor para um atributo específico do item;
- Regressăo: Dado um conjunto de itens, é a análise da dependęncia entre os valores de atributos e, automaticamente, produzir um modelo que possa prever valores de atributos para novos itens;
- Classificaçăo: Dado um conjunto de classes pré-definidas, é determinar a qual destas classes um novo item pertence;
- Agrupamento: Dado um conjunto de itens, determina-se um conjunto de classes, nos quais os itens săo agrupados de acordo com suas características;
- Associaçăo: Dado um conjunto de itens, é a identificaçăo dos relacionamentos existentes entre os atributos destes itens.
1.1 – Regras de Associaçăo
As técnicas de regras de associaçăo estabelecem uma correlaçăo estatística entre certos itens de dados em um conjunto de dados (Gobel et, al., 1999).
A regra de associaçăo pode ser representada por: X1^...^Xn => Y[C,S], onde X1, ..., Xn săo itens que prevęem a ocorręncia de Y com um grau de confiança C e com um suporte mínimo de S e ^ denota um operador de conjunçăo (AND).
Um exemplo desta regra pode ser que 90% dos consumidores de chocolate, também consomem pílulas de emagrecimento. O percentual de 90% é chamado de confiança da regra. O suporte da regra chocolate => pílulas de emagrecimento é o número de ocorręncias deste conjunto de itens na mesma transaçăo.
Alguns algoritmos que utilizam esta técnica săo: Apriori, AprioriTid, entre outros.
1.2 – Árvores de Decisăo
As árvores de decisăo săo representaçőes gráficas onde os nós representam amostras e as folhas representam categorias.
Uma árvore de decisăo designa uma classe numérica (ou saída) para uma entrada padrăo filtrando-se a amostra através dos testes na árvore. Cada teste possui reciprocamente resultados exclusivos e exaustivos.
Quando a amostra de uma populaçăo está sendo estudada com o objetivo de se fazer alguma inferęncia indutiva, as árvores de decisăo săo os modelos mais utilizados.
Em muitos exemplos vemos árvores de decisăo construídas usando sua idéia apenas com resultados booleanos, porém năo estamos limitados a implementaçăo destas funçőes.
Na figura 1 temos um exemplo de uma árvore de decisăo para um jogo de tęnis.
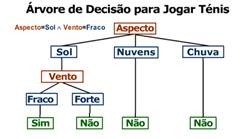
Figura 1
Alguns algoritmos conhecidos de árvore de decisăo săo: CART, CHAID, C5.0, ID3, entre outros.
1.3 – Raciocínio Baseado em Memória
O raciocínio baseado em memória combina as vantagens da recuperaçăo da informaçăo e do raciocínio baseado em regras.
O fato dos programadores utilizarem a experięncia de problemas anteriores para resolverem muitos dos problemas novos, torna o raciocínio baseado em memória particularmente apropriado para sistemas de suporte.
Uma questăo importante em raciocínio baseado em memória é a representaçăo do caso (conhecimento) no computador. Em essęncia, os casos devem manter a informaçăo necessitada pelos usuários. Kolodner (Kolodner, 1993) descreve casos como contendo tręs partes principais, que seriam:
1. A descriçăo do caso, a qual permite sua identificaçăo e armazenamento;
2. O caso em si, contendo as informaçőes relevantes para o domínio de sua aplicaçăo;
3. O estado posterior do domínio quando a soluçăo é aplicada.
Raciocínio baseado em memória é uma tecnologia emergente para a representaçăo e processamento de conhecimento. Usa experięncia passada, acumulando casos e tentando descobrir por analogia soluçőes para outros problemas.
Os principais algoritmos representantes dessa técnica săo: BIRCH, CLARANS, CLIQUE e K-MEANS.
1.4 – Algoritmos Genéticos
Os algoritmos genéticos surgiram de uma metáfora com Teoria da Evoluçăo das Espécies de Charles Darwin.
Os algoritmos genéticos incorporam uma soluçăo potencial para um problema específico numa estrutura semelhante a de um cromossomo e aplicam operadores de seleçăo e cross-over a essas estruturas de forma a preservar informaçőes críticas relativas ŕ soluçăo do problema.
O modelo matemático dos algoritmos genéticos ajuda a compreender melhor como ele trabalha.
Um exemplo de maximizaçăo da funçăo f(x) = x2 pode ser útil para entendermos todo o processo.
Vamos maximizar f(x) = x2 no intervalo de zero a trinta e um. Podemos iniciar a populaçăo de cromossomos com quatro escolhidos aleatoriamente.
x1 = 13, x2 = 24, x3 = 8, x4 = 19
Calculando a funçăo de adaptaçăo (no nosso exemplo o próprio f(x) = x2) para cada termo teremos:
f(x1) = 169, f(x2) = 576, f(x3) = 64, f(x4) = 361
Podemos ver que a melhor soluçăo nesta geraçăo é x2.
A adaptaçăo geral é a soma de todas as adaptaçőes de cada cromossomo, ou seja, 1170. Em percentuais temos x1 participando com 14%, x2 com 49%, x3 com 6% e x4 com 31%. Precisamos sortear quatro números aleatórios entre zero e cem e verificamos em que ponto da reta entre zero e cem esses números encontram-se e entăo fazemos a cópia dos cromossomos. De tal forma o cromossomo x1 será copiado uma única vez, o cromossomo x2 será reproduzido duas vezes, o cromossomo x3 năo será reproduzido, pois nenhum sorteio aleatório caiu dentro da faixa de 6% entre 64% e 69% e o cromossomo x4 será reproduzido apenas uma vez.
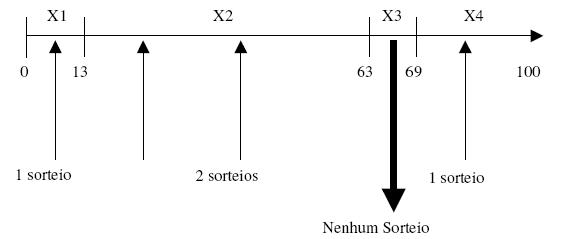
Gráfico 1 – Algoritmo Genético
A nova geraçăo após a reproduçăo será: x1 = 13, x2 = 24, x3 = 24 e x4 = 19.
Podemos notar que x2 é igual a x3 nesta nova geraçăo e que x3 da geraçăo anterior por ser pouco adaptado năo se reproduziu, por isto năo há nenhum representante seu nesta nova geraçăo.
Essa nova geraçăo representa a combinaçăo das soluçőes bem-sucedidas da geraçăo anterior que se casaram e se reproduziram.
É possível continuar o processo de evoluçăo, mas ele pode ser interrompido se o valor for considerado suficiente ou até atingir o valor máximo da funçăo f(x) no intervalo de zero a trinta e um.
1.5 – Redes Neurais
As redes neurais săo uma classe especial de sistemas modelados seguindo analogia com o funcionamento do cérebro humano e săo formadas de neurônios artificiais conectados de maneira similar aos neurônios do cérebro humano (Goebel et. al., 1999).
Um neurônio artificial é uma unidade de processamento lógica que tenta simular o comportamento e funçőes de um neurônio biológico. Nessa estrutura os dendritos do modelo biológico săo substituídos pelas entradas de informaçăo na unidade de processamento e as ligaçőes entre o corpo celular săo realizadas através de pesos, que simulam as sinapses.
As informaçőes captadas na entrada săo processadas pela funçăo de soma (?) e o limite de disparo do neurônio biológico é substituído pela funçăo de transferęncia.

Figura 2 – Modelo de Neurônio Artificial
A proposta de McCullok e Pitts, em 1943, para o trabalho de um neurônio pode ser resumida da seguinte forma:
1. Sinais săo apresentaçőes de entrada.
2. Cada sinal é multiplicado por um número, ou peso, que indica a sua influęncia na saída da unidade.
3. É feita a soma ponderada dos sinais que produz um nível de atividade.
4. Se o nível de atividade exceder um certo limite a unidade produz uma determinada resposta de saída.
Vamos exemplificar melhor.
Suponhamos que existam p sinais de entrada x1, x2,..., xn e pesos w1, w2, ..., wi e o limitador t. Os sinais do nosso exemplo serăo de valores booleanos (0 e 1) e os pesos com valores reais.
No nosso caso, o nível de atividade a é dado por:
a = w1x1 + w2x2 + ... wixn
A saída y é dada por:
y = 1, se a >= t ou
y = 0, se a < t.
Boa parte dos modelos de redes neurais usados possui alguma regra de treinamento onde os pesos săo ajustados de acordo com os padrőes apresentados. De maneira simplória podemos dizer que as redes neurais aprendem através de exemplos.
Normalmente as redes neurais săo apresentadas em forma de camadas, onde a primeira camada, chamada de entrada, recebe as primeiras informaçőes que deverăo ser processadas, a segunda camada é conhecida como camada intermediária ou camada oculta, ela pode ser formada por mais de uma camada de neurônios e nela săo feitos os processamentos da rede. Por último a camada final, denominada saída é onde o resultado é apresentado.
A forma como essas camadas trabalham e como elas săo interligadas definem a topologia de uma rede.
Algumas das principais topologias que encontramos hoje em dia săo: Perceptron, Rede de Kohonem, Rede de Hopfield, Redes ART, Redes MLP, entre diversos outros.
2 – Exemplos de Aplicaçőes na área da Saúde
Consolidando os conceitos apresentados anteriormente, apresentamos exemplos simples e inseridos dentro da área de saúde, sem a intençăo de fazer uma lista exaustiva de casos, nem efetuar uma análise detalhada sobre cada exemplo apresentado. Com os exemplos apresentados, é demonstrado o poder das ferramentas de data mining e quanto as mesmas podem contribuir para melhorar a qualidade dos serviços de saúde.
Para facilitar a compreensăo dos exemplos foi definida uma estrutura de apresentaçăo constituída por contexto, metodologia, técnica utilizada, resultados e conclusăo. Nenhum dos itens definidos expressa qualquer análise ou opiniăo pessoal dos autores deste artigo. O conteúdo referente a cada item mantém, com exatidăo, a idéia expressa no artigo original.
No item destinado ŕ descriçăo da técnica utilizada, será indicada, basicamente, a atividade do processo de data mining, de acordo com Gobel (Gobel et al., 1999). Năo săo analisados os detalhes computacionais apresentados no artigo original, pois a intençăo é apenas mostrar a aplicabilidade de uma ferramenta de data mining.
2.1 – Exemplo 01: A process-mining framework for the detection of healthcare fraud and abuse.
Contexto:
Neste trabalho (Yang, 2006), desenvolvido por pesquisadores da Universidade Changhua de Taiwan, é proposto um processo de data mining, baseado no conceito de pathways (“Guide Lines”) para elaboraçăo automática de modelos para detecçăo de casos abusivos ou fraudulentos nos sistemas de saúde (pena no Brasil năo haver interesse nisso).
A motivaçăo do trabalho vem da constataçăo do grande percentual de comportamentos abusivos e fraudulentos ocorridos nos sistemas de seguro saúde.
O objetivo principal é aplicar técnicas de data mining e, a partir de dados de casos clínicos, construir modelos a partir dos quais seja possível distinguir, automaticamente, comportamentos fraudulentos de atividades normais.
Metodologia:
Os dados utilizados para a avaliaçăo do modelo foram a base do BNHI (Bureau of National Health Insurance) de Taiwan. Para este estudo, foram utilizados os dados referentes ao departamento de ginecologia, especificamente sobre PID (Pelvic inflammatory disease) que é a patologia mais comum neste departamento. Foram coletados dados de um hospital regional, provedor de serviços para o NHI. Inicialmente, foram selecionados dados de 2543 pacientes referentes ao período de 07/2001 a 06/2002 e a partir daí preparados dois conjuntos de dados: um contendo os casos normais e outro os fraudulentos. A preparaçăo dos dados ocorreu através dos seguintes passos:
- Os dados iniciais foram filtrados para eliminar os registros com itens de dados sem valores ou com valores incoerentes. Neste processo foram eliminados 77 registros.
- Baseado nos registros restantes, as atividades médicas envolvidas do processo foram identificadas. Nesta etapa, foram identificadas 127 atividades médicas relacionadas ao processo de diagnóstico e tratamento de PID.
- A próxima etapa foi a identificaçăo “manual” dos casos fraudulentos, no conjunto de dados selecionado. A identificaçăo foi realizada por dois ginecologistas que examinaram todos os registros e identificaram 906 casos fraudulentos.
- Finalmente, os mesmos ginecologistas selecionaram 906 casos considerados normais para elaborar a base de teste contendo 1812 registros.
Técnicas Data Mining utilizadas:
O framework proposto envolve as técnicas de Regressăo e Classificaçăo.
Inicialmente foi definido um fluxo geral que compreende todo o processo de data mining proposto, conforme a figura 3. Neste processo, dois conjuntos de exemplos clínicos servem como entrada; um normal e um fraudulento. A partir desta entrada, os padrőes săo extraídos e, consequentemente, os modelo săo definidos. Há modelos que representam casos fraudulentos e modelos que correspondem a casos normais. Com os modelos de detecçăo elaborados, os registros das atividades podem ser submetidos para um mecanismo de induçăo que os classificarăo como normais ou fraudulentos.
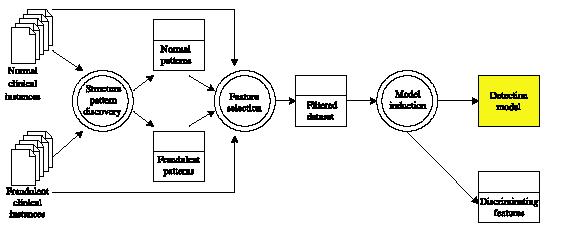
Figura 03 – Data mining framework
A técnica de data mining utilizada para a representaçăo dos modelos é baseada em grafos que determinam as atividades envolvidas em um caso clínico e a respectiva seqüęncia temporal.
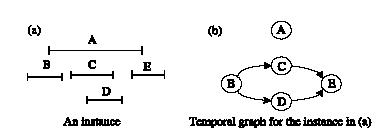
Figura 04 – Grafo para caso clínico
O algoritmo utilizado para induçăo (classificaçăo de uma ocorręncia como normal ou fraudulenta) foi o CBA (Classification Based on Associations).
Resultados:
A avaliaçăo dos resultados referentes a induçăo, foi baseada nas medidas de “Sensibilidade” e “Especificidade”, onde sensibilidade corresponde ao percentual de casos fraudulentos detectados, com base no total de casos fraudulentos existentes e especificidade equivale ao percentual de casos normais identificados diante do total de casos normais.
Os melhores resultados obtidos foram 64% e 67% para sensibilidade e especificidade, respectivamente. A figura 5 mostra a variaçăo destes resultados, de acordo com ajustes efetuados no algoritmo de classificaçăo.
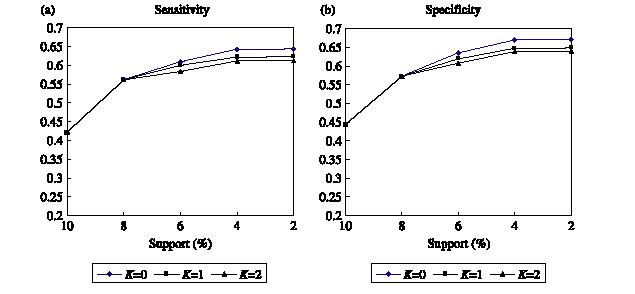
Figura 05 – Sensibilidade e Especificidade.
Conclusăo
Os autores concluíram que o framework desenvolvido auxiliou na descoberta das características que possuem alto poder discriminatório para representaçăo de casos clínicos e o mostrou-se eficiente na identificaçăo de alguns casos abusivos e fraudulentos que năo seriam facilmente identificados manualmente.
2.2 – Exemplo 02: Data Mining approach to policy analysis in a healh insurance domain.
Este artigo (Chae, 2001) é bem rico no emprego de técnicas de data mining, pois săo aplicados métodos para regressăo, previsăo e definiçăo de regras de associaçăo.
Contexto:
Desenvolvido por pesquisadores do Departamento de Cięncia da Computaçăo da Pohang University e Yonsei University, ambas da Coréia do Sul.
O objetivo do trabalho é a aplicaçăo de técnicas de data mining na base de dados KMIC (Korea Medical Insurance Corporation) visando a descoberta de informaçőes năo triviais para auxílio no monitoramento do programa de controle de hipertensăo.
Metodologia:
Para o desenvolvimento e conseqüente validaçăo da aplicaçăo de data mining, foram selecionados um subconjunto de dados do KMIC. Os registros foram selecionados aleatoriamente de uma populaçăo de 127.886 beneficiários. Inicialmente foram incluídos 100% dos beneficiários com hipertensăo (9.103) e, posteriormente, foram selecionados, de forma aleatória, o mesmo número de registros para beneficiários sem hipertensăo, totalizando 18.206 registros. Os registros continham dados biométricos, coletados durante o exame físico realizado bienalmente, como pressăo, taxa de glicose, colesterol, altura, peso, etc. A hipertensăo foi definida pelos valores da pressăo sistólica > 140 mmHg e diastólica > 90 mmHg.
Neste conjunto de dados, a idade média dos homens era de 52,1 anos e das mulheres 51,4 anos. Entre os homens, 47,7% eram fumantes e 16.5% ex-fumantes. Entre as mulheres, apenas 0.4% eram fumantes e também 0,4 % ex-fumantes. A maioria da populaçăo considerada estava dentro do peso adequado.
Atividades do Data Mining Utilizadas:
Regressăo:
A técnica de regressăo foi utilizada para identificar os fatores de risco para hipertensăo, através de características do paciente, seu histórico, dados sobre o estilo de vida e resultados dos exames físicos. Estes dados correspondem ŕs variáveis independentes, enquanto o status da hipertensăo assume o papel da variável dependente. Um dos artefatos técnicos utilizados no algoritmo para determinar a importância das variáveis consideradas, foi a equaçăo “maximum-likelihood ratio”.
Previsăo:
Esta técnica foi implementada através de uma árvore de decisăo que considera as variáveis definidas pela técnica de regressăo como fatores de risco e determina qual é a tendęncia de um determinado paciente para a hipertensăo. Para a árvore de decisăo foram utilizados dois algoritmos, CHAID e C5.0, para efeito de comparaçăo. O CHAID apresentou melhor resultado.
Regras de associaçăo:
A técnica de associaçăo foi usada para identificar a ocorręncia de relaçőes entre o resultado positivo de hipertensăo e as variáveis de risco, como “fumar”, “beber”, etc, na tentativa de descobrir relaçőes entre estes itens.
Resultados:
O resultado da técnica de regressăo mostra que variáveis biomédicas săo excelentes indicadores da hipertensăo, e, dentre estas variáveis destacam-se o índice de massa corpórea, proteína urinária, taxa de glicose e colesterol.
A técnica de previsăo que, através da árvore de decisăo, define o percentual de probabilidade de o indivíduo adquirir hipertensăo, no algoritmo CHAID tem a sensibilidade de 76,3%.
A técnica para descobrimento de regras de associaçăo definiu um grande número de associaçőes entre os fatores de riscos. A figura 6 apresenta uma visăo parcial da tabela de regras de associaçőes encontradas com os respectivos índices de suporte e confiança; onde suporte é a probabilidade de i1 e I2 ocorrerem juntos, e confiança é a proporçăo de ocorręncia de i2 considerando todas as ocorręncias de i1.
Conclusăo:
Os autores concluíram que as técnicas de data mining foram eficientes na descoberta de padrőes sobre programas de gerenciamento de hipertensăo, mesmo assumindo as limitaçőes do conjunto de dados utilizados no experimento.
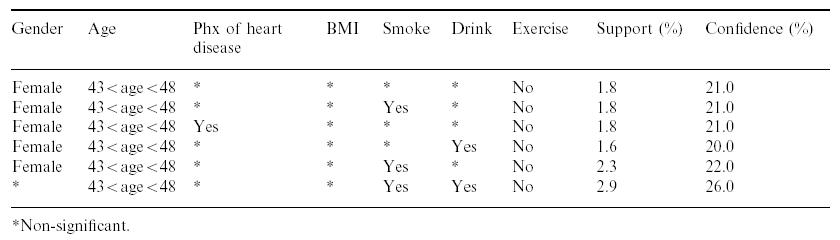
Figura 06 – Exemplo de associaçőes descobertas
2.3 – Caso 03: Association Rules and Data Mining in Hospital Infection Control and Public Health Surveillance
Este terceiro artigo (Stephen, 1998), embora năo muito recente, apresenta uma perspectiva diferente e interessante sobre a aplicaçăo da técnica data mining para a identificaçăo de regras de associaçőes.
Contexto:
Desenvolvido por pesquisadores da Alabama University em parceria com o Centro para Controle e Prevençăo de Doenças dos Estados Unidos (CDC).
O objetivo do trabalho é apresentar um processo de análise de dados capaz de identificar, automaticamente, novos e interessantes padrőes nos dados referentes a infecçăo hospitalar e vigilância sanitária.
Os sistemas de vigilância săo essenciais para a detecçăo de novas ameaças de infecçőes na saúde pública e nos ambientes hospitalares. A eficácia de um sistema desta natureza é determinada pela sua habilidade de analisar, rapidamente, séries históricas de dados e detectar grupos de doenças năo comuns.
O principal problema abordado pelos autores é que a maioria de sistemas e técnicas para análise dos dados assume que o usuário já tem uma situaçăo pré-definida (ex. infecçőes por Salmonella em uma determinada regiăo) cuja incidęncia é monitorada no tempo. Isto significa que, mudanças nas características da incidęncia que năo estăo sendo monitoradas, năo săo detectadas. Visando resolver este problema, os autores propőem a utilizaçăo de técnicas de Data Mining que năo restrinjam a análise apenas aos indicadores definidos pelo usuário, mas que sejam capazes de identificar novos padrőes e associaçőes que consigam detectar mudanças na forma de incidęncia de uma epidemia ou endemia ou qualquer programa de controle sanitário.
Metodologia:
A principal característica do processo de data mining aqui proposto, é a mudança de paradigma. Enquanto nos sistemas tradicionais de vigilância prioriza-se uma alta freqüęncia e um alto grau de confiança nas regras de associaçőes existentes, a proposta aqui é inversa; as associaçőes com uma alta freqüęncia e com um baixo nível de confiança săo as mais utilizadas. A razăo é simples: Se um fenômeno B ocorre toda vez que um fenômeno A ocorre e o fenômeno A ocorre com muita freqüęncia, provavelmente trata-se de uma situaçăo trivial ou muito bem conhecida. Se, por outro lado, um fenômeno B ocorre em apenas algumas situaçőes que A ocorre, nestas condiçőes a associaçăo A Ţ B é uma associaçăo de baixa confiança. Porém, se, ao longo do tempo, o grau de confiança desta associaçăo aumentar, isto pode indicar uma alteraçăo na característica de incidęncia do problema. Este fato é extremamente importante para atividades de prevençăo e, raramente săo detectados por ferramentas de análises tradicionais.
O processo geral da soluçăo data mining proposta, é muito simples e constituído basicamente pelas seguintes etapas:
- Os dados que serăo analisados săo divididos em partes, seguindo uma divisăo temporal, e, em cada parte săo aplicadas técnicas de data mining para descobrir todas as associaçőes com alta freqüęncia;
- Para cada regra de associaçăo identificada neste conjunto de dados (que corresponde a um determinado período de tempo), o seu grau de confiança é comparado com o grau de confiança apresentado por esta mesma regra, no conjunto de dados que corresponde ao período anterior;
- Se o grau de confiança de uma regra sofreu um aumento significativo de um período para o outro, esta regra é sinalizada como um evento que merece atençăo;
Para validaçăo da aplicaçăo de data mining foram utilizados dados do UAB Hospital (University of Alabama Birmingham). O escopo de análise foi reduzido aos casos de infecçőes provocadas por Pseudomonas Aeruginosa durante o ano de 1996. Cada registro corresponde a um caso de infecçăo por Aeruginosa e é constituído, basicamente, pelos atributos: data de ocorręncia, localizaçăo do paciente no hospital, CEP do paciente e resultado do teste (R = Resistente; I = Intermediário; S = suscetível) para piperacillin, ticarcillin / clavulanate, ceftazidime, imipenem, amikacin, gentamicin, tobramycin, e ciprofloxacin.
Para detecçăo de novas regras de associaçăo, o experimento foi realizado por tręs vezes, considerando diferentes divisőes dos dados. Em cada divisăo foi considerado um período de tempo diferente. Foram considerados períodos de um, tręs e seis meses, respectivamente, para os experimentos A, B e C.
Para análise das regras de associaçăo foi considerada uma freqüęncia 10 em todos os experimentos.
Técnicas Data Mining utilizadas:
Associaçăo:
A soluçăo proposta no trabalho, basicamente, consiste na aplicaçăo de técnicas de associaçăo visando a identificaçăo de novas correlaçőes nos dados. Foi utilizado o algoritmo simples chi-square para a definiçăo de regras de associaçăo.
Resultados:
O processo de data mining descobriu e monitorou mais de 2.000 associaçőes no experimento A, mais de 12.000 no experimento B e mais de 20.000 no C. Uma análise dos eventos descobertos mostrou que, a maioria dos eventos descobertos no experimento A năo foram detectados no experimento B e, também, năo foram encontrados no C. No entanto, alguns eventos interessantes foram detectados e para eles, açőes preventivas foram sugeridas, como mostra a figura 7.

Figura 07 – Eventos descobertos e açőes sugeridas
Conclusăo:
Os autores definiram um novo processo de data mining para identificaçăo e monitoramento de novos padrőes e associaçőes nos dados, o qual se mostra eficiente e adequado para sistemas de vigilância sanitária. Os experimentos realizados validaram a eficięncia do processo para a identificaçăo de eventos interessantes, mesmo sem conhecimento prévio, podendo, inclusive, gerar açőes preventivas.
Bom, o campo de aplicaçăo para as técnicas e ferramentas de data mining é bastante amplo. Em diversos segmentos, para diferentes problemas, as soluçőes construídas a partir do conceito de mineraçăo de dados, vęm se mostrando eficientes. Na área da saúde, onde qualquer atividade é altamente dependente de informaçăo, a aplicabilidade deste tipo de ferramenta é ideal e, em alguns casos, extremamente necessária.
Os sistemas de saúde de maneira geral, e os sistemas de informaçăo em saúde em particular, tęm-se beneficiado das técnicas e instrumentos de mineraçăo de dados já há anos, seja na recuperaçăo de informaçăo eventualmente utilizada em descobertas baseadas em literatura, seja na extraçăo de conhecimento de bases de dados factuais, bibliográficas e de texto completo, como as mantidas em extranets pela industria farmacęutica.
A mineraçăo de dados na própria web ainda é relativamente pouco realizada e, surpreendentemente, tem ocorrido com menor freqüęncia, Porém é prática comum em vários domínios. [http://www.kdnuggets.com/polls/2005/data_types.htm].
Foram apresentados, neste trabalho, alguns conceitos básicos e exemplos sobre esta tecnologia que propőem soluçőes a problemas inerentes aos sistemas de saúde, que săo importantes e relativamente comuns a praticamente todos os países do mundo.
No primeiro exemplo é apresentado um dos problemas mais sérios da saúde, que em muitos casos provocam verdadeiros colapsos no sistema. Uma soluçăo, baseada em técnicas de data mining é apresentada através de um mecanismo de detecçăo de fraudes e abusos. Se bem sucedida, a soluçăo proposta representará uma expressiva economia em benefício do sistema de saúde.
O segundo exemplo mostra como uma ferramenta Data Mining capaz de prever a ocorręncia de patologias ou simplesmente mostrar a tendęncia de ocorręncia baseada nas características da populaçăo, pode aumentar a qualidade preventiva da saúde pública e auxiliar, de maneira substancial, os programas de saúde implantados por governos ou instituiçőes.
O terceiro exemplo reforça, de maneira brilhante, a idéia de como este tipo de soluçăo pode, de fato, contribuir decisivamente nas açőes preventivas destinadas ŕ saúde pública. É apresentada uma soluçăo, destinada ŕ vigilância sanitária, que identifica e monitora padrőes de comportamento de problemas, como epidemias e endemias, e detecta mudanças nas características destes problemas, permitindo que açőes sejam tomadas antes mesmo de um surto da situaçăo.
Os casos apresentados mostram que é possível utilizar soluçőes construídas a partir de técnicas de data mining para resolver problemas existentes na gestăo dos serviços de saúde e conseqüentemente beneficiar a populaçăo que recebe estes serviços.
É isso ai pessoal. Espero que tenham aproveitado, até a próxima coluna.
Referęncias
Berry, J.A, Linoff, Gordon S. Mastering Data Mining. New York: John Wiley & Sons; 2000.
Chae, Young Moon; Ho, Seumg Hee; Cho, Won Kyoung; Lee, Dong Ha; Ji, Sun Ha. Data Mining approach to policy analysis in health insurance domain, International Journal of Medical Informatics, 62 (2001) 103-111.
Goebel, M, Gruenwald, L. A survey of data mining and knowledge discovery software tools. SIGKDD Explorations 1999 Jun; 1: 20-33.
Kolodner, J. Case-Based Reasoning. Florida: Morgan Kaufmann; 1993.
Stephen E. Brossette, Alan P. Sprague, J. Michael Hardin, Ken B. Waites, Warren T. Jones, Stephen A. Moser. Associations Rules and Data Mining in Hospital Infection Control and Public Health Surveillance, Journal of the American Medical Informatics Association, V. 5 N. 4 (1998) 3713-181.
Yang, Wan-Shiou, Wang San-Yih. A process-mining framework for the detection of healthcare fraud and abuse, Expert Systems with Applications 31 (2006) 56–68.
Vander Emiro Muniz
www.triscal.com.br

