Data Quality: Como está a qualidade dos nossos dados?
Carlos Caldo
Imagine:
Mesmo pagando a fatura, vocę recebe pela terceira vez aquela indesejável carta de cobrança de seu cartăo de crédito. Prontamente, mas irritado, vocę liga apara central de atendimento ao cliente e o atendente lhe diz:
-Sinto muito senhor, consta em nosso sistema que a fatura esta em aberto.
Após muitas ligaçőes e explicaçőes a operadora do cartăo reconhece que foi um erro do sistema. Cansado pelo transtorno vocę solicita o cancelamento do cartăo...
Mais um Cliente perdeu a pacięncia...
Mais uma Empresa perdeu um Cliente...
E tudo porque os DADOS estavam errados!
Mas como isso ocorreu? Que tipo de erro os dados apresentavam? Como podem os dados armazenados estarem incorretos?
Bem, para respondermos a estas perguntas teríamos que analisar minuciosamente o universo de dados do cenário acima e para isto entraríamos no terreno denominado de Data Quality.
O leitor pode agora estar com uma série de perguntas na mente. Vamos tentar respondę-las.
Caldo, o que é Data Quality?
Em minha opiniăo existe uma visăo minimalista sobre Data Quality, pois a maioria das organizaçőes associa o termo única e exclusivamente a uma Ferramenta. Data Quality pode e deve ser visto como algo maior, ou seja, um conjunto de processos que visa garantir que os dados armazenados sejam:
- Corretos;
- Precisos;
- Consistentes;
- Completos;
- Integrados;
- Aderentes ŕs regras de negócio;
- Aderentes aos domínios estabelecidos.
Estes processos devem abranger desde a identificaçăo de problemas com os dados e sua classificaçăo até a correçăo dos valores e a posterior monitoraçăo, ou seja, identificamos aquilo que denominamos de dados “sujos” e promovemos, dentro do possível, a “limpeza” dos mesmos. Depois monitoramos para verificar se erros năo estăo sendo introduzidos novamente. Em outras palavras: Seguimos os princípios de TQM (Total Quality Management): ANALISAR, MEDIR E MELHORAR.
Mas o que podemos entender por dados “sujos”?
Săo aqueles dados armazenados que estăo inconsistentes. Podemos classificar estes dados em categorias, vamos citar algumas, utilizando nomes de Tabelas e Colunas hipotéticos:
Valores Default DUMMY: Quando encontramos Defaults para os valores de colunas ou campos obrigatórios.
Exemplo: CPF com 999.999.999-9
Valores Default “INTELIGENTES”: Quando os Defaults possuem significado. Exemplo: Se a coluna IDADE contiver 000 o cliente é corporativo!
Valores contraditórios: Quando os valores de uma coluna ou campo săo inconsistentes com os valores de outra coluna ou campo relacionado.
Exemplo:
Na Tabela de CLIENTES determinada linha possui os seguintes valores:
Coluna CEP: 031085-020
Coluna Endereço: Rua Amazonas;
Todavia, na Tabela de CEPs este CEP năo é da rua Amazonas!
Violaçăo de Regras de Negócio: Quando o encontramos um valor de uma coluna ou campo que năo está aderente a uma regra de negócio.
Exemplo: Se na Tabela de CONTRATOS a coluna TIPO-DE-CONTRATO conter o valor ‘VIP’ e a coluna DATA-DO-CONTRATO for inferior a ’01.012006’ o valor da coluna PERCENTUAL-TAXA-DE-JURO deve ser inferior a 4. Todavia, encontramos em uma linha da Tabela que obedece a regra, mas a coluna taxa de juro está com o valor 6!
Valores em desacordo com o domínio: Quando os valores de uma coluna ou campo năo obedecem ao domínio estabelecido.
Exemplo: Na Tabela de FUNCIONARIO a coluna SITUACAO-DO-FUNCIONARIO deve conter os seguintes valores: ‘ATIVO’, ‘INATIVO’,’DEMITIDO’. Todavia, encontramos em uma linha da Tabela que possui uma situaçăo igual a ‘AFASTADO!
Estas săo algumas categorias, porém a lista é um pouco maior.
Entendi, mas como implementar os processos de Data Quality?
Bem, como respondi na primeira pergunta, Data Quality năo é somente uma Ferramenta. Portanto, é necessário especificar formalmente o conjunto de processos, com suas entradas, atividades, itens regulatórios, itens de suporte, e suas saídas. Com os processos definidos, podemos depois avaliar com maior precisăo uma ferramenta que seja aderente ŕs necessidades da organizaçăo.
Numa visăo geral, a arquitetura de processos teria o seguinte contexto:
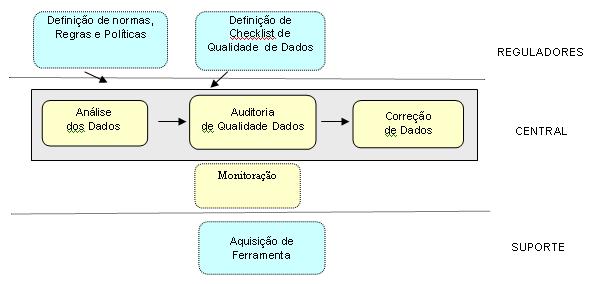
Arquitetura de Processos de Data Quality: Cada retângulo representa um processo a ser especificado detalhadamente.
Poderia falar um pouco mais sobre os processos centrais?
Vamos a uma visăo geral sobre eles:
Analise dos Dados (Profiling): Varre a base de dados e apresenta como estăo os dados, ou seja, é o retrato daquilo que existe armazenado.
Por exemplo, em um relatório de distribuiçăo de freqüęncia poderíamos ter:
Na tabela de CLIENTE a coluna sexo apresenta os seguintes valores armazenados:
1000 linhas com ‘M’
2000 linhas com ‘F’
200 LINHAS COM ‘X’
Auditoria (Audit): Com base no conhecimento daquilo que existe, especifica-se, para efeito de validaçăo e mediçăo, aquilo que deveria existir.
Por exemplo:
Na Tabela CLIENTE a coluna sexo deveria conter somente os valores ‘M’ e ‘F’
Correçăo (Cleansing): Promover a “limpeza” dos dados inconsistentes. Claro que após recebermos os Relatórios de auditoria deve ser feita uma análise de impacto para sabermos aquilo que podemos corrigir. Năo raro, corrigimos aquilo que consideramos critico para o funcionamento do negócio, deixando a correçăo de alguns erros para momento oportuno.
Além dos processos acima citados, temos o de Monitoraçăo que consiste em realizar auditorias periódicas (após a Correçăo) para verificar como está a qualidade dos dados. Através do processo de Monitoraçăo conseguimos, inclusive, apresentar relatórios com Indicadores de Qualidade que permitem uma visăo sobre a melhoria da qualidade de determinada Base de Dados: Estamos melhorando ou piorando?
Caldo, e quanto ao Checklist de Avaliaçăo de Qualidade de Dados?
Esta é uma peça fundamental para que os processos centrais possam ser executados. Neste Checklist definimos os quesitos de qualidade de dados.
Quando vamos executar uma Auditoria na Qualidade dos Dados seguimos este Checklist, ou seja, se, por exemplo, as Tabelas de determinada Base de Dados estăo em conformidade com os quesitos de qualidade tudo está bem, se năo, identificamos onde e o que está com problemas.
Validade de Domínios, Integridade estrutural e de Regras de Negócio săo alguns exemplos de quesitos de Qualidade de Dados. Porém, quando definimos este Checklist para uma Empresa efetuamos adaptaçőes na nomenclatura dos quesitos, bem como adicionamos alguns e retiramos outros, em relaçăo aos quesitos normalmente conhecidos no mercado.
Na arquitetura o processo de aquisiçăo de Ferramenta. Poderia recomendar alguma?
Existem várias ferramentas disponíveis no mercado e cada empresa deve promover uma avaliaçăo que valide se a ferramenta atende as necessidades dos processos Regulatórios e Centrais. Entretanto, podemos apenas dizer que estamos trabalhando em projetos que utilizam alguns produtos da suíte de Data Quality da IBM:
Ř WebSphere ProfileStage
Ř WebSphere AuditStage
Ř WebSphere QualityStage
Ř WebSphere DataStage
Em nossa análise os produtos atendem plenamente as necessidades dos processos de Data Quality e possuem ótimo desempenho para tratamento de grandes volumes de dados.
Conclusăo:
Neste pequeno artigo năo temos a pretensăo de esgotar o assunto Data Quality, mas apenas sensibilizar o amigo leitor, quanto ŕ importância de se entender claramente a amplitude deste tema.
Em tempo, gostaria de recordar que dados incorretos acarretam, entre outros problemas:
Ř Retrabalho para efetuar correçőes (custo com recursos e tempo extra!);
Ř Perda de oportunidades de negócios e clientes;
Ř Risco de Imagem;
Ř Multas por năo cumprimento de normas regulatórias.
Para encerrarmos deixo uma pequena reflexăo:
Será que as razőes acima năo săo suficientes para que nossas empresas empreendam, rapidamente, iniciativas de Data Quality?
Um grande abraço a todos e até o próximo artigo!

