Design do Prefuse
No artigo anterior, aprendemos como construir uma aplicaçăo simples utilizando o prefuse, no entanto recebi vários emails de leitores pedindo mais informaçőes sobre como construir suas próprias visualizaçőes. Entăo este artigo irá tratar sobre o design do Prefuse, năo nos iremos nos prender a código, mas entender o motivo de usar cada etapa de uma visualizaçăo.
Etapas para o desenvolvimento de uma visualizaçăo
O prefuse possui o design baseado no modelo de referęncia de visualizaçăo de informaçőes, de forma que o processo de visualizaçăo é quebrado em etapas discretas. Essas etapas variam desde a aquisiçăo e modelagem dos dados até a visualizaçăo interativa. Para qualquer visualizaçăo do prefuse, é preciso seguir essas etapas: coleta de dados(i), visualizaçăo(ii), açőes(iii) e controles(iv).
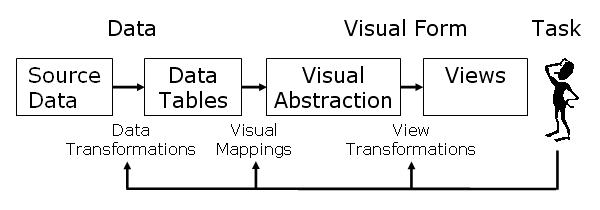
Figura 1 – Design do prefuse, disponível em http://prefuse.org/doc/manual/introduction/structure/
Primeira etapa
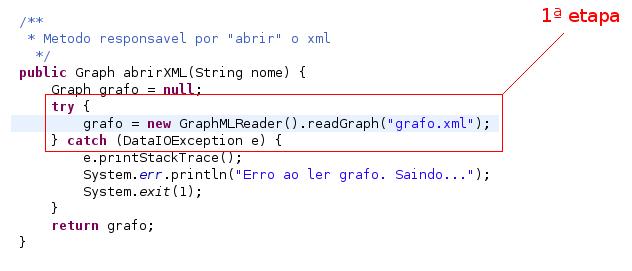
A primeira etapa para a criaçăo de uma visualizaçăo consiste na coleta dos dados para a tabela de visualizaçăo (Table, Graph, Tree). Esses dados podem ser de diversas fontes (prefuse.data.io) inclusive do banco de dados. Sendo que os dados podem ser tabela de figuras, grafos de redes sociais, árvores, etc.
Essa primeira etapa consiste na extraçăo dos dados (arquivos) gerados para a tabela de dados(o modelo de grafo, ou árvore) que o prefuse entende. No exemplo do artigo passado utilizamos um arquivo graphml que utiliza a linguagem XML para representaçăo de grafos, no entanto esses dados podem ser também árvores(treeml) ou tabelas(csv).
Segunda etapa
A segunda etapa consiste na construçăo da visualizaçăo que mapeia os dados para a abstraçăo visual (processo visual, renderizaçăo, interaçăo). Cada elemento pode ter vários VisualItems correspondentes, que representam um objeto interativo na tela. Cada VisualItem contem propriedades como posiçăo (x,y), cor, forma e tamanho.

Terceira etapa
A terceira etapa consiste na construçăo de uma série de açőes de processamento de dados(Actions) que operam sobre a abstraçăo visual. Essas instâncias de Action podem ser agrupadas em ActionLists para várias tarefas de processamento.
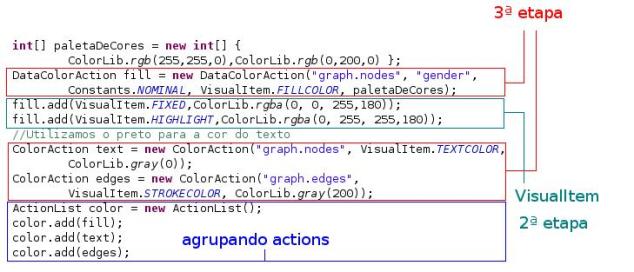
Alguns leitores tiveram dificuldade em entender para que serviam todos esses argumentos no DataColorAction, entăo vamos gastar um pouco mais de tempo com ele:
DataColorAction
· o nome do grupo de dados a ser processado(No nosso caso serăo os nodos)
· o nome do atributo que será a base para as cores(No nosso caso gender)
· o tipo de dado do campo: nominal, ordinal, numerical.
· a forma da cor do campo
o stroke – é utilizado para desenhar linhas ou bordas, se quisermos que o nossos nodos sejam vazados, devemos preencher com stroke, no nosso caso, preferimos que fossem sólidos, por isso usamos o fill.
o fill – é utilizado para preencher, no caso, os os nossos tiveram a aparęncia de sólidos, ou seja “pintados” por dentro.
o Text – é utilizado para texto.
· Paleta de cores (opcional)
Quarta etapa
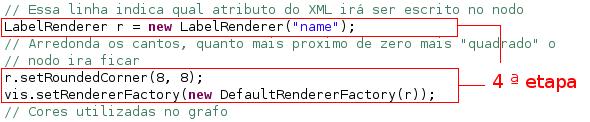
A quarta etapa consiste na especificaçăo da forma que itens visuais serăo desenhados na tela. Para ver formas abstratas, rótulos de texto ou imagens, é necessário construir um RendererFactory. O RendererFactory mapeia os itens visuais para a instância de Renderer. O Renderer é responsável pelo desenho de itens visuais na tela. Para ver texto nos nodos, precisa-se criar um LabelRenderer e no nosso caso que queremos que o nome contido na tag name seja escrito no nodo, precisamos passar o valor de "name" nos nós. A Visualization contém uma instância de DefaultRendererFactory, que desenha linhas para arestas por padrăo.
Última etapa
Falta apenas adicionar os controles sobre a visualizaçăo. No caso, os Displays suportam várias transformaçőes, tais como panning e zooming , para manipular os itens visuais. Interatividade pode ser aplicada usando controles pré-construídos (prefuse.controls).
O presufe também da suporte a buscas ricas e filtros. Vários engines de busca (prefuse.data.search) e queries dinâmicas(prefuse.data.query) estăo disponíveis.
Notem que ao contrário do exemplo no artigo anterior, agora foi adicionado um outro controle, o NeighborHighlightControl. Esse controle permite que ao focalizarmos um nodo com o mouse, os vizinhos sejam destacados. Volte até a terceira etapa e vejam que foram adicionadas duas novas linhas, tratam-se exatamente das cores desse novo controle. Quando passamos o argumento VisualItem.FIXED, dizemos que quando mouse focalizar aquele nodo, ou seja, quando estiver fixo, deverá possuir a cor passada logo depois. Quando passamos o argumento VisualItem.HIGHLIGH, declaramos a cor dos nodos vizinhos que estăo ligados ao nodo fixo pelo mouse.

Pacotes
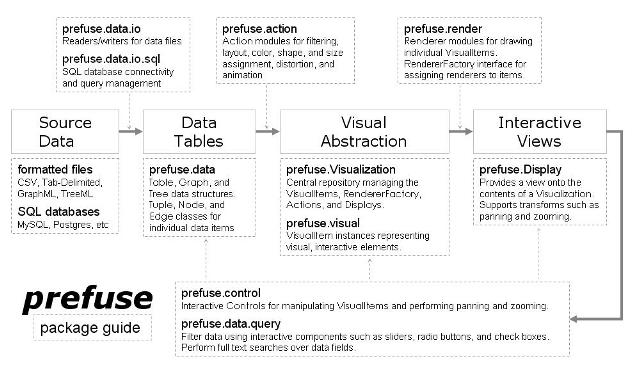
Figura 2 – Pacotes do prefuse, disponível em http://prefuse.org/doc/manual/introduction/structure/
Pacote prefuse.data – Esse pacote providencia uma estrutura de dados de Table, Graph, e Tree. No caso, as linhas da tabela săo representadas pela classe Tuple. O prefuse também providencia uma linguagem de expressăo interpretada para escrita de queries nas estruturas de dados do prefuse, essas classes de expressőes estăo no pacote prefuse.data.expression.
Pacote prefuse.data.io – Esse pacote providencia classes para leitura e escrita de dados tabela, grafo e árvore para arquivos formatados. Para tabelas, săo suportados arquivos CSV (comma-separated-values). Para estrutura de redes, săo suportados os formatos de arquivos GraphML e TreeML baseados em XML.
O pacote prefuse.data.io.sql providencia facilidades para consultas SQL.
Pacote prefuse.control – Esse pacote permite adicionar controles a aplicaçăo, como os controles de zoom, panning, drag, etc.
Pacote prefuse.action – Permite criar os actions para a visualizaçăo.
Pacote prefuse.renderer – Permite criar os renderers.
Acredito que quem olhou o primeiro artigo possa ter tido um melhor entendimento do design do prefuse, e saber quais processos necessários para criar a própria visualizaçăo,
obrigado,
Samuel Félix

