


A mineraçăo de dados (data mining) pode ser definida como o processo automático de descoberta de conhecimento em bases de dados muito volumosas. Os primeiros softwares para mineraçăo de dados começaram a ser desenvolvidos em meados da década de 90, ainda em ambiente acadęmico. Hoje em dia já existem algumas dezenas de ferramentas comerciais para data mining, desenvolvidas por empresas como SAS (Enterprise Miner), IBM (Intelligent Miner) e SPSS (Clementine). Além disso, diversos recursos para mineraçăo de dados encontram-se disponibilizados nas versőes mais recentes dos SGBD’s Oracle e SQL Server.
Este artigo pretende apresentar ao leitor uma das ferramentas de data mining mais simples e largamente utilizadas: a ferramenta Weka. O sistema Weka é um software livre (de código aberto) para mineraçăo de dados, desenvolvido em Java, dentro das especificaçőes da GNU (General Public License). As suas características, bem como as técnicas nele implementadas săo descritas de forma detalhada em [Witten e Frank 2005], cujos autores săo os responsáveis pela implementaçăo da ferramenta. O software está disponível para Windows, Linux e outras plataformas.
2 Árvores de Decisăo
A ferramenta Weka possui como ponto forte a extraçăo de classificadores em bases de dados. Um classificador (ou modelo de classificaçăo) é utilizado para identificar a classe ŕ qual pertence uma determinada observaçăo de uma base de dados, a partir de suas características (seus atributos).
A mineraçăo de modelos de classificaçăo em bases de dados é um processo composto por duas fases: aprendizado e teste. Na fase de aprendizado, um algoritmo classificador é aplicado sobre um conjunto de dados de treinamento. Como resultado, obtem-se a construçăo do classificador propriamente dito. Tipicamente, o conjunto de treinamento corresponde a um subconjunto de observaçőes selecionadas de maneira aleatória a partir da base de dados que se deseja analisar. Cada observaçăo do conjunto de treinamento é caracterizada por dois tipos de atributo: o atributo classe, que indica a classe a qual a observaçăo pertence; e os atributos preditivos, cujos valores serăo analisados para que seja descoberto o modo como eles se relacionam com o atributo classe. Para exemplificar estes conceitos, considere o conjunto de dados de treinamento apresentado na Tabela 1. Neste exemplo, o conjunto de dados é composto por observaçőes selecionadas a partir de uma base hipotética de informaçőes censitárias. Cada observaçăo contém os dados de uma pessoa entrevistada. Observe que o atributo “Rico” - utilizado para indicar se uma pessoa possui renda anual igual ou superior a R$ 50.000,00 - representa o atributo classe, enquanto os atributos “escolaridade” e “idade” săo preditivos.
Tabela 1 Base de Dados Censitários
|
NOME |
ESCOLARIDADE |
IDADE |
RICO |
|
Alva |
Mestrado |
>30 |
Sim |
|
Amanda |
Doutorado |
<=30 |
Sim |
|
Ana |
Mestrado |
<=30 |
Năo |
|
Eduardo |
Doutorado |
>30 |
Sim |
|
Inęs |
Graduaçăo |
<=30 |
Năo |
|
Joaquim |
Graduaçăo |
>30 |
Năo |
|
Maria |
Mestrado |
>30 |
Sim |
|
Raphael |
Mestrado |
<=30 |
Năo |
Após o classificador ser construído, inicia-se a etapa de teste, que visa avaliar a sua acurácia através do emprego de um conjunto de dados de teste. O conjunto de teste contém observaçőes que também săo selecionadas aleatoriamente a partir da base de dados. No entanto, estas observaçőes devem ser diferentes das que foram selecionadas para compor o conjunto de treinamento. A acurácia do classificador representa a porcentagem de observaçőes do conjunto de teste que săo corretamente classificadas por ele. Caso a acurácia seja alta, o modelo de classificaçăo é considerado eficiente e pode ser utilizado para classificar novos casos.
Diversas técnicas podem ser utilizadas para a construçăo de classificadores, tais como redes neurais, métodos Bayesianos e árvores de decisăo, entre outros. As árvores de decisăo (Figura 1) tęm sido muito utilizadas pelos softwares de mineraçăo de dados. Isto é justificado pelo fato delas possuírem uma representaçăo intuitiva, que torna o modelo de classificaçăo fácil de ser interpretado.
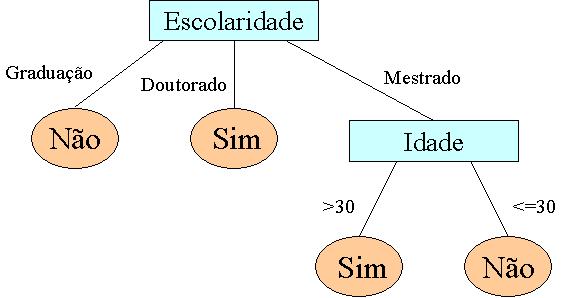
Figura 1 Árvore de decisăo construída a partir do conjunto de dados da Tabela 1.
A árvore de decisăo apresentada na Figura 1 indica se uma pessoa é rica ou năo com base nos seus outros atributos, os atributos preditivos. A estrutura possui as seguintes características:
- cada nó interno é um teste em um atributo preditivo;
- uma ramificaçăo partindo de um nó interno representa um resultado para o teste (por exemplo, Escolaridade = “Doutorado”);
- uma folha da árvore representa um rótulo de classe (por exemplo, Rico = “Sim” ou Rico = “Năo”);
- em cada nó da árvore, um atributo deve ser escolhido para dividir as observaçőes do conjunto de treinamento em classes, na medida do possível.
- uma nova observaçăo é classificada seguindo um caminho na árvore, da raiz até a folha.
É importante observar que uma árvore de decisăo pode ser utilizada com duas finalidades: previsăo (exemplo: descobrir se um cliente será um bom pagador em funçăo de suas características) e descriçăo (fornecer informaçőes interessantes a respeito das relaçőes entre os atributos preditivos e o atributo classe numa base de dados).
Uma árvore de decisăo é formada por um conjunto de regras de classificaçăo. Cada caminho da raiz até uma folha representa uma destas regras. A árvore de decisăo deve ser definida de forma que, para cada observaçăo da base de dados, haja um e apenas um caminho da raiz até a folha. As quatro regras de classificaçăo a seguir, compőem a árvore de decisăo da Figura 1.
1. (Escolaridade = “Graduaçăo”) Ţ (Rico = “Năo”)
2. (Escolaridade = “Doutorado”) Ţ (Rico = “Sim”)
3. (Escolaridade = “Mestrado”) & (Idade = “>30”) Ţ (Rico = “Sim”)
4. (Escolaridade = “Mestrado”) & (Idade = “<=30”) Ţ (Rico = “Năo”)
Uma regra de classificaçăo é uma expressăo da forma A Ţ B, onde A é denominado antecedente e B é denominado conseqüente. O antecedente deve ser formado por um ou mais atributos preditivos, enquanto o atributo classe aparece no lado do conseqüente. Uma regra do tipo A Ţ B indica que a classe B pode ser determinada pelos atributos preditivos indicados no antecedente. Medidas como a probabilidade condicional podem ser utilizadas para avaliar a qualidade de uma regra de classificaçăo.
Existem diversos algoritmos na literatura utilizados para a construçăo de árvores de decisăo, tais como ID3, C4.5 e CHAID. Detalhes sobre as características e a implementaçăo destes algoritmos podem ser obtidos em [Berry e Linoff 2004] e [Han e Kamber 2006]. De forma resumida pode-se dizer que os algoritmos para classificaçăo săo recursivos e que eles constroem a árvore utilizando uma abordagem top-down. Os algoritmos classificadores possuem como meta a construçăo de árvores que possuam o menor tamanho e a maior acurácia possíveis. Uma questăo chave para a construçăo de uma árvore de decisăo consiste na estratégia para a escolha dos atributos que estarăo mais próximos da raiz da árvore (ou seja, os atributos que săo inicialmente avaliados para determinar a classe a qual uma observaçăo pertence). Observe que na Figura 1, o atributo “Escolaridade” encontra-se na raiz da árvore, pois foi considerado pelo algoritmo classificador como o atributo mais importante para determinar se uma pessoa é rica ou năo. Geralmente săo utilizadas medidas baseadas na entropia para tratar este problema.
3. Construçăo de uma Árvore de Decisăo Utilizando a Ferramenta Weka
A ferramenta Weka trabalha com arquivos de entrada no formato ARFF, que corresponde a um arquivo texto contendo um conjunto de observaçőes, precedido por um pequeno cabeçalho. O cabeçalho é utilizado para fornecer informaçőes a respeito dos campos que compőem o conjunto de observaçőes. Dessa forma, antes da mineraçăo de dados, a ferramenta pode verificar alguma inconsistęncia na base de dados e sinalizá-la. A Figura 2 ilustra um exemplo de arquivo ARFF, contendo um cabeçalho e um conjunto de 8 registros que representam a base de dados apresentada na Tabela 1. Observe que o cabeçalho contém a declaraçăo da relaçăo que o arquivo representa (comando @relation), uma lista de atributos (comando @attribute) e a relaçăo de valores que os mesmos podem assumir. O conjunto de observaçőes é precedido por um comando @data. Cada observaçăo é representada por uma linha. Os valores dos campos dentro de uma observaçăo devem ser separados utilizando a vírgula.
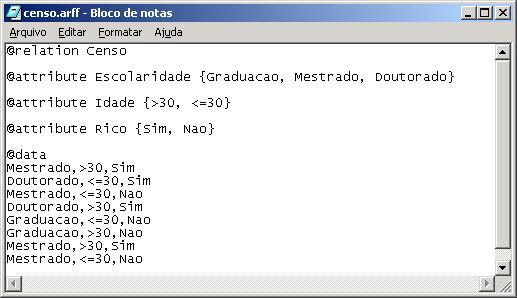
Figura 2 Arquivo ARFF.
O instalador da ferramenta Weka pode ser obtido de maneira gratuita (juntamente com seu código fonte) no site http://www.cs.waikato.ac.nz/~ml/weka. Uma vez instalado, o sistema Weka pode ser utilizado para minerar árvores de decisăo através da execuçăo dos seguintes passos:
PASSO 1: Executar o programa. A partir do menu Iniciar / Programas, selecione WEKA e clique em Weka 3-4 (versăo atual do sistema). O menu principal Weka GUI Chooser será exibido na tela. Clique no botăo “Explorer” (Figura 3).

Figura 3 Weka GUI Chooser
PASSO 2: Importar o arquivo ARFF. Após iniciar o Weka Explorer, a opçăo “Open File” deve ser utilizada para abrir o arquivo ARFF que será minerado.
PASSO 3: Selecionar os Atributos. Em seguida, o Weka abrirá uma tela que permite com que o usuário possa definir qual o atributo da base que será utilizado como classe e quais os atributos que serăo utilizados como preditivos (Figura 4). No momento da importaçăo, por default, o Weka irá considerar o último atributo especificado no cabeçalho do arquivo ARFF, como o atributo classe, enquanto os demais atributos serăo tratados como atributos preditivos. Observe que, nesta tela (aba Preprocess), também é possível consultar gráficos de barra que indicam os cruzamentos de freqüęncia envolvendo todos os atributos preditivos e o atributo classe.
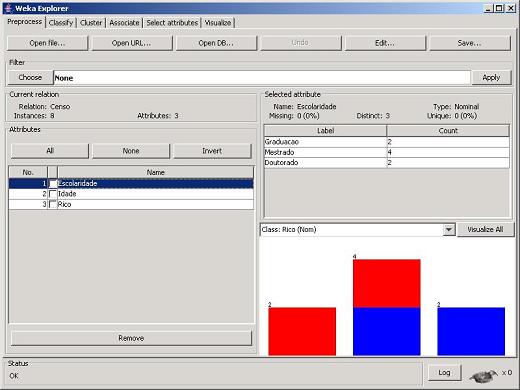
Figura 4 Seleçăo da Classe e dos Atributos Preditivos
PASSO 4: Selecionar o Algoritmo de Mineraçăo. Clique na aba “Classify”. A partir desta tela é possível escolher e executar um algoritmo de classificaçăo sobre a base de dados importada. Os resultados da mineraçăo também poderăo ser consultados neste mesmo local. Clique no botăo "Choose". Será aberta uma janela que permitirá a escolha do algoritmo de mineraçăo de dados. Clique na pasta "trees" (algoritmos de árvore de decisăo) e selecione a opçăo "Id3" (Figura 5).
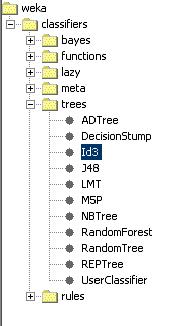
Figura 5 Seleçăo do Algoritmo de Mineraçăo de Dados
PASSO 5: Executar o Algoritmo de Mineraçăo. No painel “Test options” selecione a opçăo “Use training set”. Esta seleçăo indica ao Weka que toda a base de dados será utilizada como base de treinamento durante o processo de mineraçăo. A seguir clique no botăo "Start". A árvore de decisăo gerada pelo algoritmo ID3 é apresentada no canto direito da tela do Weka, conforme ilustra a área destacada no círculo vermelho da Figura 6. Na mesma tela săo apresentadas algumas medidas de interesse que indicam a qualidade da árvore minerada.
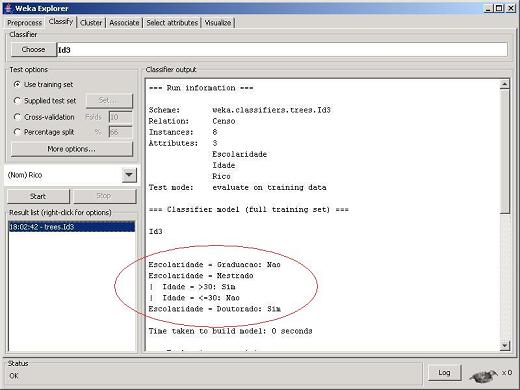
Figura 6 Árvore de Decisăo Minerada pelo Weka
4. Conclusőes
Este artigo demonstrou os passos necessários para a extraçăo de árvores de decisăo a partir de bases de dados através da utilizaçăo da ferramenta de data mining Weka. O trabalho também apresentou conceitos introdutórios sobre a mineraçăo de classificadores e sobre árvores de decisăo.
Como trabalho futuro pretende-se apresentar outros conceitos associados ŕ mineraçăo de árvores de decisăo como, por exemplo, as medidas de interesse para avaliar a qualidade destas árvores. Além disso pretende-se descrever outras capacidades do sistema Weka, como a mineraçăo de regras de associaçăo e clusters de dados e a obtençăo de modelos de classificaçăo através de outros algoritmos diferentes do ID3.
Referęncias

Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.