Full Text Search no Oracle - Parte 02
Explorando o Oracle interMedia
Carlos Duarte, Ricardo Rezende e Rodrigo Righetti
O Oracle interMedia é um conjunto de ferramentas que possibilitam o armazenamento e manipulaçăo de dados amplamente usados na web como texto, dados, imagens, áudio e vídeo. Este conjunto de ferramentas está incluído nas versőes Standard e Enterprise Edition desde a versăo 8i do produto.
Como característica, permite que o banco de dados Oracle armazene, gerencie e recupere informaçőes de localizaçăo geográfica, imagens, áudio, vídeo ou qualquer outro dado multimídia de maneira integrada com outras informaçőes da corporaçăo.
Este artigo irá demonstrar características do Oracle interMedia Text, um pool de ferramentas do interMedia que irá basicamente trabalhar com a indexaçăo e busca de conteúdo web e documentos com formataçăo Word, PDF, etc.
O índice do tipo CTXCAT pode fornecer um desempenho melhor do que os índices do tipo CONTEXT porque é possível criar sub-índices internos. Eles funcionarăo como os índices B-Tree compostos. No caso de uma query com mais de coluna, pode-se criar estes sub-índices para ajudar na consulta.
Para exemplificar seu uso, iniciaremos criando a estrutura de armazenamento e carga dos dados com as Listagens 14 e 15.
Listagem 14. Criaçăo da estrutura para armazenamento dos dados
id NUMBER(10) PRIMARY KEY,
name VARCHAR2(200) NOT NULL,
description VARCHAR2(4000) NOT NULL,
price NUMBER(7,2) NOT NULL,
REGION NUMBER NOT NULL);
Listagem 15. Carga dos dados.
FOR i IN 1 .. 1000 LOOP
VALUES (my_items_seq.NEXTVAL, 'Bike: '||i, 'Bike Description ('||i||')', i,1);
END LOOP;
FOR i IN 1 .. 1000 LOOP
VALUES (my_items_seq.NEXTVAL, 'Car: '||i, 'Car Description ('||i||')', i,2);
END LOOP;
FOR i IN 1 .. 1000 LOOP
VALUES (my_items_seq.NEXTVAL, 'House: '||i, 'House Description ('||i||')', i,3);
/
O próximo passo é criar um índice CTXCAT nas colunas DESCRIPTION e PRICE e gerarmos as estatísticas da tabela. Para a criaçăo deste índice, é mandatório criar um conjunto de índice, definido pela cláusula INDEX_SET, com um sub-índice para cada coluna (Listagem 16) referenciada pela funçăo CATSEARCH (Listagem 17).
Listagem 16. Criaçăo do índice e geraçăo da estatística.
EXEC CTX_DDL.CREATE_INDEX_SET('my_items_iset');
EXEC CTX_DDL.ADD_INDEX('my_items_iset','price'); /* SUB-INDEX A */
EXEC CTX_DDL.ADD_INDEX('MY_ITEMS_ISET','PRICE,REGION'); /* SUB-INDEX b */
CREATE INDEX my_items_name_idx
PARAMETERS ('index set my_items_iset');
EXEC DBMS_STATS.GATHER_TABLE_STATS(USER, 'MY_ITEMS', cascade=>TRUE);
Note que foram incluídos dois sub-índices no index set (‘PRICE’ e ‘PRICE,REGION’). Isso ajudará em consultas que irăo trabalhar com uma ou duas colunas. Note que foram criados dois sub-índices nas linhas 2 e 3 do exemplo da Listagem 16. Se a pesquisa for somente pela coluna PRICE, o primeiro sub-índice A será utilizado. Se forem utilizadas as colunas PRICE e REGION, o sub-índice B será utilizado internamente para melhorar a performance.
Para finalizar, fazemos a consulta na tabela procurando por itens com a descriçăo que contenha a palavra especificada e o preço apropriado (Listagem 17).
Perceba que para o uso do índice com CTXCAT é mandatório a utilizaçăo do operador CATSEARCH na query. CATSEARCH é o operador utilizado para informar ao interMedia Text que um índice do tipo CTXCAT está sendo utilizado. Serăo mostrados mais exemplos de operadores nos próximos tópicos.
Listagem 17. Executando a consulta.
FROM my_items
WHERE CATSEARCH(description, 'Bike', 'price BETWEEN 1 AND 5')> 0;
ID PRICE NAME
------ ---------- ------------------------------------------------
1 1 Bike: 1
2 2 Bike: 2
3 3 Bike: 3
4 4 Bike: 4
5 5 Bike: 5
5 rows selected.
FROM my_items
WHERE CATSEARCH(description, 'Car', 'price BETWEEN 101 AND 105 ORDER BY price DESC')> 0;
ID PRICE NAME
------ ---------- ------------------------------------------------
1105 105 Car: 105
1104 104 Car: 104
1103 103 Car: 103
1102 102 Car: 102
1101 101 Car: 101
5 rows selected.
SELECT ID, PRICE, NAME
FROM MY_ITEMS
WHERE CATSEARCH(description, 'Bike', 'price BETWEEN 1 AND 5 and region = 1')> 0
ID PRICE NAME
---------- ---------- -----------------------------------------------
3001 1 Bike: 1
3002 2 Bike: 2
3003 3 Bike: 3
3004 4 Bike: 4
3005 5 Bike: 5
No terceiro exemplo da Listagem 17, perceba que foi “concatenado” a coluna region na funçăo CATSEARCH. Internamente o Oracle irá procurar o melhor caminho utilizando o sub-índice criado no index-set (Listagem 16).
SELECT id, price, name
FROM my_items
WHERE (CATSEARCH(description, 'Bike')> 0 )
AND (price >= 1 AND PRICE <=5)
Um índice CTXRULE é usado para construir aplicaçőes de classificaçăo de documentos por meio de regras. É um índice criado em uma tabela de consultas, onde as consultas servem como regras (rule) para definir o critério de classificaçăo. O operador utilizado neste índice é o MATCHES.
Já índices do tipo CTXXPATH săo utilizados somente para aperfeiçoar consultas em colunas do tipo XML em que é usada a funçăo existsNode().
Estes dois últimos tipos de índices săo menos utilizados, pois atendem a aplicaçőes extremamente específicas. O mais comum é a utilizaçăo dos índices CONTEXT e CTXCAT.
O esquema CTXSYS guarda algumas informaçőes valiosas para criaçăo e manipulaçăo dos índices do Oracle Text que poderăo ser utilizadas como guia de consulta.
A Listagem 18 mostra os “Operadores” que podem ser utilizados para trabalhar com os índices do Oracle Text.
Listagem 18. Objeto Operator, do esquema CTXSYS.
SQL> select OPERATOR_NAME, NUMBER_OF_BINDS from user_operators;
OPERATOR_NAME NUMBER_OF_BINDS
------------------------------ --------------------
CATSEARCH 2
CONTAINS 12
MATCHES 4
SCORE 7
XPCONTAINS 1
No decorrer do artigo, através dos exemplos, ficará bem claro o que cada um desses operadores faz.
Após a criaçăo de um índice intermedia, alguns objetos săo gerados automaticamente conforme a Listagem 19.
Listagem 19. Objetos criados após a geraçăo de um índice interMedia.
CREATE TABLE TABLEDOC(ID NUMBER PRIMARY KEY, TEXTO VARCHAR2(100));
indextype is ctxsys.context;
where table_name like '%TABLEDOC%';
------------------------------
DR$TABLEDOC_IDX$N
DR$TABLEDOC_IDX$R
TABLEDOC
Estas novas tabelas săo importantes para entendermos o funcionamento interno do interMedia. O nome sempre irá conter o prefixo DR$ + nome do índice + $I e $K e $N e $R. A
Listagem 20 mostra uma descriçăo de cada uma delas.
Listagem 20. Examinando as tabelas criadas com o índice interMedia.
SQL> desc DR$TABLEDOC_IDX$I
Name Null? Type
----------------------------------------- -------- -------------------
TOKEN_TEXT NOT NULL VARCHAR2(64)
TOKEN_TYPE NOT NULL NUMBER(3)
TOKEN_FIRST NOT NULL NUMBER(10)
TOKEN_LAST NOT NULL NUMBER(10)
TOKEN_COUNT NOT NULL NUMBER(10)
TOKEN_INFO BLOB
SQL> desc DR$TABLEDOC_IDX$K
Name Null? Type
----------------------------------------- -------- -------------------
DOCID NUMBER(38)
TEXTKEY NOT NULL ROWID
SQL> desc DR$TABLEDOC_IDX$N
Name Null? Type
----------------------------------------- -------- -------------------
NLT_DOCID NOT NULL NUMBER(38)
NLT_MARK NOT NULL CHAR(1)
SQL> desc DR$TABLEDOC_IDX$R
Name Null? Type
----------------------------------------- -------- -------------------
ROW_NO NUMBER(3)
DATA BLOB
A tabela DR$TABLEDOC_IDX$I é a mais importante do índice interMedia porque mantém um mapa de bits para todas as palavras chave dos documentos armazenados na tabela principal.
As tabelas DR$TABLEDOC_IDX$K e DR$TABLEDOC_IDX$R fazem o mapeamento do Rowid do documento armazenado na tabela principal.
Já a tabela DR$TABLEDOC_IDX$N é usada para manter um registro de documentos/registros que foram apagados, muito úteis em uma situaçăo em que seja necessário reconstruir determinada informaçăo.
É possível fazer select diretamente nestas tabelas, mas é desaconselhável qualquer manipulaçăo direta a năo ser que isso seja instruído pelo suporte da Oracle.
As Listagens 21, 22 e 23 apresentam como a manutençăo de um índice funciona ao utilizar o interMedia Text.
Listagem 21. DML’s na tabela TABLEDOC.
SQL> insert into tabledoc values(1,'Usar o intermedia e muito simples');
SQL> insert into tabledoc values(2,'Intermedia e uma ferramenta poderosa, e mesmo assim facil de aprender');
Na Listagem 21 alguns registros săo inseridos na tabela TABLEDOC, mas se tentarmos consultar os registros inseridos năo será possível. Isso porque o índice está desatualizado em relaçăo ŕ tabela.
É possível consultar quais registros estăo desatualizados pesquisando a tabela CTX_USER_PENDING como mostra a Listagem 22.
Listagem 22. Verificando se o índice interMedia está ou năo desatualizado.
SQL> select pnd_index_name, pnd_rowid from ctx_user_pending;
PND_INDEX_NAME PND_ROWID
------------------------------ ------------------
TABLEDOC_IDX AAAB2SAAGAAAAHXAAA
TABLEDOC_IDX AAAB2SAAGAAAAHXAAB
A primeira coluna informa qual o índice desatualizado enquanto a segunda coluna informa o ROWID da linha que năo está em sincronismo. É possível ver o registro fora de sincronismo fazendo um select na tabela where rowid = PND_ROWID.
A forma mais simples para entender este funcionamento é a seguinte: quando um DML ocorre na tabela, o rowid da linha alterado é “armazenado” na view CTX_USER_PENDING. O que está nesta view está desatualizado, mesmo que o DML seja um DELETE. Para sincronizar os registros, basta executar a procedure como mostra a Listagem 23.
Listagem 23. Sincronizando um índice de interMedia Text.
SQL> select pnd_index_name, pnd_rowid from ctx_user_pending;
no rows selected
A freqüęncia com que esta procedure deve ser utilizada irá depender da freqüęncia de modificaçăo dos registros, o tempo que estes registros podem estar defasados para pesquisa e o tempo que irá levar para cada sincronismo.
Este sincronismo năo irá re-sincronizar todo o índice, somente as linhas que estăo defasadas na view CTX_USER_PENDING.
Gerenciando documentos DATASTORE
Com o Oracle intermedia Text é possível gerenciar e executar pesquisas em diversos tipos de documentos tais como: DOC, XLS, PPT, PDF, HTML, etc... A lista completa pode ser consultada em http://tahiti.oracle.com.
Para realizar tal tarefa, podemos usar alguns dos meios de armazenamento que já possuímos tais como LOB, External Tables e busca na internet onde o documento năo está armazenado no BD.
Já observamos que os dados de um índice interMedia podem ser armazenados diretamente no banco de dados. Esse método é chamado de DIRECT_DATASTORE, onde podemos usar campos do tipo VARCHAR, VARCHAR2, BLOB, CLOB ou BFILE para compor este índice.
Também é possível utilizar LONG e LONG RAW, mas como sabemos, esse tipo de armazenamento só é mantido por compatibilidade e totalmente desaconselhável desde a versăo 8.
O mais interessante do interMedia Text é que ele reconhece automaticamente o formato do documento que está sendo indexado.
No site http://download-east.oracle.com/docs/cd/B19306_01/text.102/b14218/afilsupt.htm#CCREF1300 há uma lista com todos os formatos suportados pelo interMedia Text.
Também é possível criar uma Stoplist. A Stoplist é uma lista de palavras que năo devem ser indexadas. Nas versőes mais atuais do interMedia Text há algumas já prontas no schema CTXSYS e em vários idiomas. Também é possível criar suas Stoplists utilizando as procedures na packages CTX_DDL CREATE_STOPLIST, ADD_STOPWORD e REMOVE_STOPWORD.
A Tabela 1 mostra exemplos de palavras em inglęs e a Tabela 2, palavras em portuguęs.
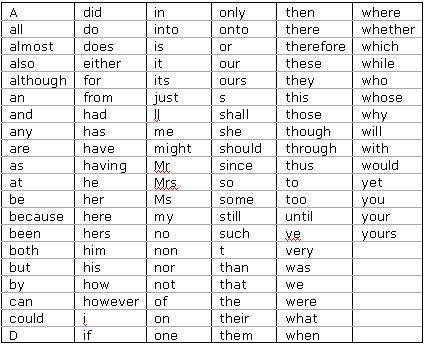
Tabela 1. Stoplist de palavras em inglęs.
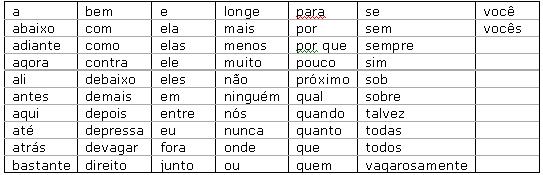
Tabela 2. Stoplist de palavras em portuguęs.
Uma lista completa esta disponível no link:
http://download-west.oracle.com/docs/cd/B19306_01/text.102/b14218/astopsup.htm#CEGBGCDF
Outra forma de armazenamento é o DETAIL_DATASTORE que consiste na criaçăo de um índice interMedia que será usado na tabela principal para pesquisas onde năo será necessário fazer a junçăo entre a tabela Principal e a tabela Detalhe, facilitando assim o gerenciamento destes documentos.
Vejamos uma demonstraçăo na Listagem 24 onde primeiro criaremos nossas tabelas Principal e Detalhe.
Listagem 24. Criaçăo das tabelas Principal e Detalhe.
CREATE TABLE ORDEM_COMPRA
(ORDID NUMBER PRIMARY KEY,
DESCRI VARCHAR2(150),
ITEM_DET_J CHAR(1));
(DETID NUMBER,
DETSEQ NUMBER,
ITEM_DETAIL VARCHAR2(1000));
INSERT INTO ORDEM_COMPRA(ORDID,DESCRI)
VALUES(1,’Itens de Escritorio’);
INSERT INTO ORDEM_COMPRA(ORDID,DESCRI)
VALUES(2,’Itens de Manutencao’);
INSERT INTO ORDEM_DET(DETID, DETSEQ,ITEM_DETAIL)
VALUES(1,1,’Canetas para serem usadas pela engenharia’);
INSERT INTO ORDEM_DET(DETID, DETSEQ, ITEM_DETAIL)
VALUES(1,2,’Papeis timbrados da Oracle’);
INSERT INTO ORDEM_DET(DETID, DETSEQ, ITEM_DETAIL)
VALUES (1,3,’Teclado ergometrico’);
INSERT INTO ORDEM_DET(DETID, DETSEQ, ITEM_DETAIL)
VALUES (2,1,’Hard Drive 80gb’);
Para que o DETAIL_DATASTORE funcione, precisamos criar uma definiçăo de preferęncia e o índice baseado sobre essa preferęncia. É necessário o privilégio de execuçăo na package CTX_DDL. Veja o exemplo na Listagem 25.
Listagem 25. Criaçăo da preferęncia e do índice baseado nela.
GRANT EXECUTE ON CTXSYS.CTX_DDL TO ORDSYS;
CTX_DDL.CREATE_PREFERENCE(‘IT_PREF’,’DETAIL_DATASTORE’);
CTX_DDL.SET_ATTRIBUTE(‘IT_PREF’,’DETAIL_TABLE’,’ORDEM_DET’);
CTX_DDL.SET_ATTRIBUTE(‘IT_PREF’,’DETAIL_KEY’,’DETID’);
CTX_DDL.SET_ATTRIBUTE(‘IT_PREF’,’DETAIL_LINENO’,’DETSEQ’);
CTX_DDL.SET_ATTRIBUTE(‘IT_PREF’,’DETAIL_TEXT’,’ITEM_DETAIL’);
/
CREATE INDEX PREF_IDX ON ORDEM_COMPRA(ITEM_DET_J)
PARAMETERS(‘DATASTORE IT_PREF’);
SELECT *
WHERE CONTAINS(ITEM_DET_J,’engenharia’) >0;
ORDID DESCRI
---------- ----------------------------------------------
1 Itens de Escritório
Veja que a pesquisa foi feita pela string “engenharia”. O banco, internamente, procurou na tabela de detalhes qual registro continha esta entrada. Após encontrar o registro, lę a definiçăo da preferęncia no metadata e retorna o registro da tabela pai correspondente.
Outra forma de gerenciamento e pesquisa é o armazenamento externo usando o módulo FILE_DATASTORE (Listagem 26) e URL_DATASTORE (Listagem 27).
Esse método irá usar URLs (Uniform Resource Locators) para identificar os arquivos e năo fará referęncia ao campo do tipo BFILE. Isto permite efetuarmos buscas diretamente em arquivos armazenados na web via requisiçăo http e ftp, assim como as ferramentas de buscas mais avançadas.
Listagem 26. Criando um FILE_DATASTORE.
ctx_ddl.create_preference('COMMON_DIR','FILE_DATASTORE');
ctx_ddl.set_attribute('COMMON_DIR','PATH','/mydocs');
(id number primary key,
docs varchar2(2000));
create index myindex on mytable(docs)
parameters ('datastore COMMON_DIR');
Na Listagem 26 criamos uma referęncia de file datastore chamada COMMON_DIR cujo caminho é /mydocs.
Ao inserir dados na tabela, é necessário apenas indicar o nome do arquivo. O atributo PATH informa ao sistema onde procurar durante o processo de indexaçăo. Depois é só criar o índice.
Já no exemplo da Listagem 27 foi criada uma preferęncia de URL_DATASTORE chamada URL_PREF para a qual foram definidos os atributos http_proxy, no_proxy e timeout. Depois foi criada a tabela e inseridos os valores, contendo as URLs em questăo. Finalmente, foi criado o índice especificando URL_PREF como um datastore.
Listagem 27. Criando uma URL datastore.
ctx_ddl.create_preference('URL_PREF','URL_DATASTORE');
ctx_ddl.set_attribute('URL_PREF','HTTP_PROXY','www-proxy.us.oracle.com');
ctx_ddl.set_attribute('URL_PREF','NO_PROXY','us.oracle.com');
ctx_ddl.set_attribute('URL_PREF','Timeout','300');
(id number primary key,
docs varchar2(2000));
values(111555,'http://context.us.oracle.com');
values(111556,'http://www.sun.com');
create index datastores_text on urls ( docs )
parameters ( 'Datastore URL_PREF' );
A grande mágica do FILE_DATASTORE e URL_DATASTORE é que a informaçăo gerada no banco é somente o índice.
Imagine que vocę tem um website interno e deseja indexá-lo sem carregar todas as páginas que săo dinâmicas para o seu banco de dados. Isso é possível somente fornecendo o link para o interMedia Text. Ele irá ler toda a página e indexá-la da forma mais eficiente para consulta. Isso sem precisar gravar a página no disco.
Como regra geral, a única ferramenta necessária para utilizaçăo do interMedia é a clausula “CONTAINS”. Todo o restante da query é exatamente igual, como cláusula where, group, having, count e as demais. Para ajudar na pesquisa e trazer resultados mais seletivos, é possível utilizar alguns operadores. Abaixo segue alguns nomes, exemplos e funcionalidades para cada um deles (uma lista completa pode ser encontrada no site: http://download-east.oracle.com/docs/cd/B19306_01/text.102/b14218/cqoper.htm#sthref1006)
Todos os operadores citados aqui deverăo ser utilizados dentro da clausula CONTAINS.
Este operador avalia se uma palavra está perto da outra, com qual distancia e se deve respeitar a ordem na funçăo.
Na Listagem 28, a query deve respeitar se a palavra DOG esta perto da palavra CAT em 50 posiçőes e deve respeitar a ordem. Primeiro encontrar DOG, depois CAT.
Listagem 28. Query com o operador NEAR.
SQL> select *
from ANIMAIS
where contains(TIPO,'near((dog, cat), 50, TRUE)') > 0;
Este operador remove uma palavra da expressăo pesquisada. Pode também ser utilizado o operador “-“. O exemplo da Listagem 29 irá selecionar todos os modelos de carro da FORD que năo tenha a palavra ESPORTIVO.
Listagem 29. Query com o operador MINUS.
SQL> select *
from CARROS
where contains(MODELO,'FORD - esportivo') > 0;
SQL> select *
from CARROS
where contains(MODELO,'FORD MINUS esportivo') > 0;
Este operador pesquisa palavras com a mesma lingüística. Ele irá considerar que quando o usuário faz pesquisa por cat, também seja aceito cats ou qualquer outra variaçăo da palavra como na Listagem 30.
Pode também ser utilizado o operador “$“.
Listagem 30. Query com o operador STEM.
SQL> select *
from ANIMAIS
where contains(TIPO,'$CAT') > 0;
TIPO
---------------
cat
cats
O mais importante neste tópico é notar que as queries săo sempre seguidas do “CONTAINS” e o operador desejado. O restante é só intercalar os valores e funçőes.
Estas funçőes podem ser utilizadas em conjunto como segue na Listagem 31 com os operadores AND (&) e OR ( | ). A query irá buscar qualquer ocorręncia da palavra “cat” e suas variaçőes e também deverá trazer palavras “dog” ou “dogs” e năo deverá trazer palavras “cobra”.
Listagem 31. Query com mais de um operador.
SQL> select *
from ANIMAIS
where contains(TIPO,'$CAT & (DOg | DOGS) MINUS COBRA') > 0;
A grande questăo em termos de banco de dados é: “Tenho a informaçăo armazenada, mas como recuperá-la rapidamente quando eu precisar dela?”.
Para responder esta pergunta, o Oracle nos traz o Oracle interMedia e, em especial, o Oracle Text capaz de recuperar informaçőes de forma eficiente. Uma bela ferramenta para buscar a informaçăo onde quer que ela esteja armazenada.

