O artigo apresenta conceitos e métricas de Garbage Collection em Java, além da categorizaçăo da memória heap em generations. Em seguida, apresenta a JVM HotSpot 6 e seu funcionamento geral com relaçăo ŕ Garbage Collection, assim como a sua personalizaçăo através de opçőes da JVM. A partir daqui, explica sobre cada collector, seu funcionamento, suas opçőes de personalizaçăo e suas implementaçőes, fazendo também um comparativo final mostrando quando é mais adequado utilizar cada um dos collectors disponíveis. Ainda, apresenta a JVM HotSpot 7 e seu novo collector, seu funcionamento e opçőes de personalizaçăo.
Um assunto constantemente deixado de lado atualmente, porém de extrema importância, é a devida configuraçăo do processo de Garbage Collection. É comum de se ver pouco esforço quanto a este respeito, e assim aparecem muitas consequęncias que seriam evitáveis em um processo de Garbage Collection bem configurado.
Tipicamente, é incomum ver um desenvolvedor que se preocupe o suficiente com isto, pois é muito provável que seu ambiente de desenvolvimento năo possua as mesmas necessidades que um ambiente de produçăo, e desta forma ele năo sente bem os flagelos causados por um Garbage Collection mal configurado: as famigeradas pausas e demoras.
Todavia, é possível otimizar a maioria dos cenários, visto que cada aplicaçăo tem uma maneira única quanto ŕ utilizaçăo de memória, sendo assim possível buscar as configuraçőes a serem utilizadas para obter-se o máximo possível do processo de Garbage Collection.
A intençăo deste artigo é demonstrar aos desenvolvedores a importância de entender e otimizar o processo de Garbage Collection. Assim, faz-se necessário um estudo preliminar sobre os conceitos e algoritmos disponíveis em diferentes versőes da Java Virtual Machine (JVM) mais conhecida atualmente, a JVM HotSpot, o que será abordado neste primeiro artigo da série “Entendendo e otimizando o Garbage Collection”.
A linguagem Java possui gerenciamento automático de memória, controlando sua alocaçăo e desalocaçăo. A desalocaçăo de memória é suportada pelo processo conhecido por Garbage Collection.
Esta abordagem difere-se das linguagens tradicionais como C++, onde a memória dinâmica é alocada e desalocada explicitamente, o que costumava ser problemático devido ŕ utilizaçăo de ponteiros de memória, o que possibilita problemas como vazamentos de memória e bugs de ponteiros para regiőes da memória que continham objetos que já foram desalocados.
Em Java, a alocaçăo e desalocaçăo de memória acontece de maneira automática, controlada e transparente ao desenvolvedor, substituindo a utilizaçăo de ponteiros de memória por referęncias de objetos, evitando assim os vazamentos de memória e bugs de ponteiros. Desta forma, a linguagem Java é considerada mais segura neste aspecto.
Em contrapartida, este gerenciamento automático de memória consome recursos computacionais quanto ŕ decisăo sobre a desalocaçăo, fato já sabido pelo desenvolvedor que realizava isto explicitamente em C++. Além disso, este processo é năo-determinístico, ou seja, năo há garantias sobre quando acontecerá a desalocaçăo, se ela vier a acontecer.
Antes de explicar mais detalhes sobre este processo, eis alguns conceitos iniciais:
Tipicamente, throughput e pausa representam um trade-off em Garbage Collection, ou seja, quanto mais esforço se investe em maximizar o throughput, menos se tem em minimizar o tempo de pausa, e vice-versa.
Em determinadas situaçőes, a existęncia de pausas năo caracteriza um problema crítico, como por exemplo em um servidor web, onde o cliente já está ciente que precisará esperar por uma resposta, e assim as pausas de Garbage Collection podem ser disfarçadas pela latęncia de rede, de maneira que o usuário năo consiga perceber que a demora aconteceu por causa de Garbage Collection. Assim, uma boa ideia seria utilizar um collector que busque maximizar o throughput da aplicaçăo.
Em outras situaçőes, a existęncia de pausas representa um problema crítico, como por exemplo em uma aplicaçăo gráfica e interativa, onde mesmo pequenas pausas serăo percebidas pelo usuário e podem afetar sua experięncia com a aplicaçăo. Assim, uma boa ideia seria utilizar um collector que busque minimizar o tempo de pausa.
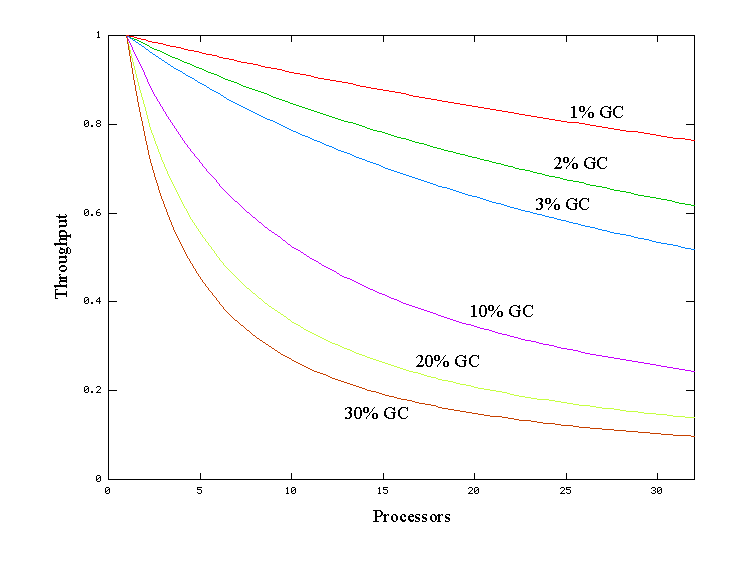
O gráfico da Figura 1, obtido do website da Oracle, representa a porcentagem de throughput perdida em aplicaçőes que gastam diferentes quantidades de tempo com collections, ŕ medida que mais processadores săo adicionados ao sistema. Por exemplo, a linha vermelha representa uma aplicaçăo que gasta 1% do tempo fazendo collections e a linha roxa representa outra aplicaçăo que gasta 10%. Ambas as aplicaçőes năo apresentam perda considerável de throughput em um sistema com 1 processador, pois no gráfico ambas as linhas estăo próximas de 1 de throughput quando temos 1 processador. No entanto, quando operam com 32 processadores, a primeira aplicaçăo apresenta uma perda de mais de 20% de throughput (pois a linha vermelha está um pouco abaixo de 0.8 quando temos 32 processadores), e a segunda aplicaçăo possui mais de 75% de throughput perdido (pois a linha roxa está um pouco acima de 0.2 quando temos 32 processadores).
O objetivo deste gráfico é demonstrar como questőes pouco perceptíveis em sistemas com um processador podem tornar-se verdadeiros gargalos quando as escalamos a sistemas grandes. No entanto, é possível melhorar este cenário com a seleçăo do algoritmo mais apropriado de Garbage Collection, além da realizaçăo de ajustes personalizados.
Um objeto é considerado “garbage” quando năo é mais acessível de qualquer referęncia do programa em execuçăo. O primeiro desafio é identificar tais objetos, para em um segundo momento reclamar a memória previamente ocupada por estes objetos.
O primeiro algoritmo criado para Garbage Collection é conhecido como Mark and Sweep. Até hoje, derivaçőes deste algoritmo săo extensivamente utilizadas.
O algoritmo Mark and Sweep é composto por duas fases: a fase Mark, onde todos os objetos acessíveis do sistema săo visitados e marcados como tal, e logo depois a fase Sweep, onde todos os objetos que năo foram marcados como acessíveis săo reclamados.
Ainda, uma collection que utiliza o algoritmo Mark and Sweep irá suspender temporariamente a execuçăo do programa, enquanto o algoritmo realiza seu trabalho. Assim que todos os objetos năo referenciados săo reclamados, a execuçăo do programa é retomada. Esta característica é conhecida como stop the world, ou como diria Raulzito, “pare o mundo que eu quero descer”.
Uma collection que visita todos os objetos acessíveis do sistema é denominada Full Garbage Collection. Em Java, logo se percebe que realizar frequentemente Full Garbage Collections năo é uma boa ideia, visto o tempo que seria gasto para tal devido a grande quantidade de objetos que săo criados ao longo da execuçăo de cada programa.
Como uma alternativa ao algoritmo original de Mark and Sweep, surgiram os algoritmos generacionais de Garbage Collection. Estes algoritmos baseiam-se na observaçăo que a maioria dos objetos sobrevive por um curto período de tempo. É uma característica comuns na maioria das aplicaçőes que pode ser utilizada para minimizar o esforço anteriormente gasto pelos algoritmos mais ingęnuos.
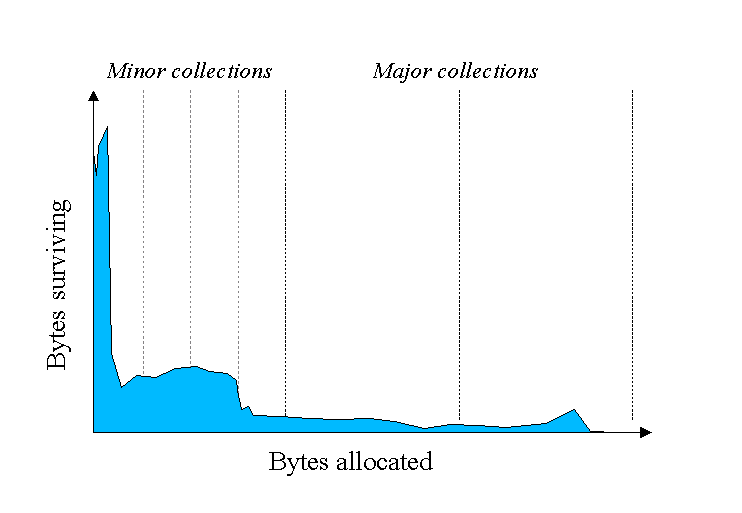
A Figura 2, também obtida do website da Oracle, representa uma distribuiçăo do tempo de vida médio de objetos, onde o eixo X é a quantidade de bytes alocados, e o eixo Y é a quantidade de bytes em execuçăo em um determinado momento. Nota-se que após um breve pico, o número de bytes em execuçăo cai drasticamente, o que significa que tal soma de objetos foi reclamada pouco tempo após ser alocada. Isto é comum de se ver em objetos que săo criados para serem utilizados dentro de métodos curtos e loops. Em contrapartida, alguns objetos permanecem em execuçăo por muito tempo, por exemplo objetos presentes em transaçőes longas ou acesso a banco de dados.
Assim foi idealizada a noçăo de generations (geraçőes) de objetos, que servem para dividir os objetos pelo critério “tempo de existęncia”. Cada generation representa uma ou mais separaçőes físicas ou lógicas do espaço de memória e possui um determinado limite que, quando atingido, desencadeia uma collection. Confira os tręs tipos possíveis de generation:
A JVM HotSpot, que é fornecida no download do Java Runtime Environment (JRE) ou Java Development Kit (JDK) pelo site da Oracle, em sua versăo 6.0, possui alguns collectors que săo estudados a seguir.
Desde a versăo 5.0, a JVM HotSpot possui uma funcionalidade conhecida como Ergonomics, que é a escolha automática de certas opçőes de linha de comando na inicializaçăo da JVM. Esta escolha é baseada no porte da máquina na qual a JVM está rodando, o que sugere características da aplicaçăo. Por exemplo: aplicaçőes mais pesadas devem rodar em máquinas mais potentes.
De maneira geral, Ergonomics seleciona:
Tal escolha automática de um algoritmo de Garbage Collection geralmente resulta em ganhos de performance, mas năo é possível garantir que esta seja a melhor escolha possível. Certos tipos de aplicaçăo que possuam uma utilizaçăo de memória muito particular podem necessitar de escolhas explícitas para alcançar o nível de performance esperado.
A JVM HotSpot 6 divide a memória heap conforme a Figura 3, obtida do blog about:performance.
Nesta divisăo, a Young generation é novamente dividida em tręs pedaços: espaço Eden, onde a maioria dos objetos é inicialmente alocada, e dois espaços Survivor, onde objetos săo copiados ao sobreviver a collections.
Tipicamente, objetos em Eden que sobreviveram ŕ primeira collection săo copiados a um dos espaços Survivor, e a cada nova collection que sobreviverem continuarăo a ser copiados entre os espaços Survivor, até serem considerados maduros o suficiente para serem copiados para a Tenured generation. O objetivo após a cópia é sempre deixar Eden e um dos espaços Survivor vazios. Esta forma de Garbage Collection é conhecida como copy collection.
Na Tenured generation, năo há cópia, mas sim liberaçăo de memória, por algoritmos tipicamente derivados de Mark and Sweep. No entanto, quando há liberaçăo de memória, fica-se sujeito a problemas de fragmentaçăo de memória.
Em termos de memória heap, fragmentaçăo causa alocaçăo lenta, longa duraçăo da fase Sweep e possibilidade de OutOfMemoryError quando os espaços entre objetos săo menores que o suficiente para a alocaçăo de novos objetos, conforme demonstrado na Figura 4, obtida do blog about:performance.
Para tal, é necessário mais uma fase, chamada de Compact, onde é realizada a desfragmentaçăo pela compactaçăo do espaço disponível na memória heap, também demonstrado na Figura 4.
Antes de entrar no estudo minucioso dos collectors da JVM HotSpot, é importante apresentar algumas opçőes da JVM para personalizar a configuraçăo da memória heap e as generations:
Além disto, há as seguintes opçőes para imprimir logs sobre Garbage Collection:
A JVM HotSpot 6 até a update 13 possui tręs collectors de Garbage Collection: Serial, Parallel e Concurrent, que serăo estudados a seguir.
O collector Serial foi a escolha padrăo da JVM até surgir Ergonomics (antes do Java 5), e hoje continua sendo a escolha certa para a maioria das aplicaçőes pequenas.
É baseado em uma única thread para realizar todo o trabalho de Garbage Collection. Por um lado, isto é vantajoso devido ao fato que năo há gasto de processamento com sincronizaçăo e comunicaçăo entre threads, mas por outro lado é desvantajoso pois năo aproveita de fato a utilizaçăo de múltiplos processadores quando os mesmos existem no hardware atual.
Assim sendo, o collector Serial é mais adequado em máquinas com único processador, ou máquinas com múltiplos processadores que processem uma quantidade pequena de dados (até aproximadamente 100 MB).
O ponto fraco deste algoritmo é o tamanho da pausa, que tende a ser muito grande comparado aos outros algoritmos disponíveis.
Outra questăo a ser observada é relacionada com a Lei de Amdahl. Segundo a Lei de Amdahl, o ganho de performance na utilizaçăo de múltiplos processadores é limitado pela fraçăo de tempo no qual o processamento paralelo pode ser utilizado.
Em outras palavras, sempre que houver uma porçăo de código que năo pode ser paralelizado (como um método synchronized, por exemplo), o tempo disponível para o processamento paralelo será menor, e assim o ganho de performance diminuirá. Assim, outro fator a favor da utilizaçăo do collector Serial é quando uma aplicaçăo possui muito código năo-paralelizável.
Há duas implementaçőes deste collector:
O collector Serial pode ser explicitamente escolhido utilizando a opçăo da JVM: -XX:UseSerialGC. Esta opçăo seleciona as implementaçőes Serial (para Young generation) e SerialOld (para Tenured generation).
O collector Parallel (também conhecido como collector Throughput) realiza collections em paralelo, otimizando o tempo de processamento significativamente. O objetivo deste collector é maximizar o throughput da aplicaçăo, abrindo măo de minimizar o tempo de pausa, apesar de que as pausas săo significantemente menores que o collector Serial em máquinas com múltiplos processadores. Foi projetado para trabalhar com quantidade média a grande de dados.
Há tręs implementaçőes deste collector:
Uma particularidade da implementaçăo Parallel Old é que ele năo compacta toda a regiăo Tenured collection todas as vezes, apenas compacta a sub-regiăo que necessite mais.
O collector Parallel pode ser explicitamente escolhido utilizando uma entre as seguintes opçőes da JVM:
É possível personalizar seu funcionamento com as seguintes opçőes da JVM:
-XX:MaxGCPauseMillis=<N>: Especifica a pausa máxima desejada. Por padrăo, năo há pausa máxima desejada previamente definida.
A utilizaçăo desta opçăo faz com que o tamanho da memória heap e outros parâmetros sejam ajustados para tentar manter as pausas menores ou iguais a N milissegundos, podendo assim afetar o throughput da aplicaçăo. Contudo, năo há garantias que o tempo de pausa será menor ou igual a N milissegundos em todas as execuçőes;
O collector Concurrent (também conhecido como CMS, que significa Concurrent Mark and Sweep) também realiza collections em paralelo, assim como o collector Parallel. O objetivo deste collector é minimizar o tempo de pausa, mesmo que as pausas aconteçam com maior frequęncia, abrindo măo de maximizar o throughput da aplicaçăo. Foi projetado para aplicaçőes que necessitem ter um baixo tempo de pausa, e que além disso utilizem quantidade média a grande de dados que permaneçam um bom tempo em execuçăo (formando assim uma grande Tenured generation).
Uma particularidade deste collector é que a maior parte do processo de Garbage Collection acontece ao mesmo tempo em que a aplicaçăo é executada. Desta forma, haverá um maior consumo de processamento, o que poderá afetar o throughput.
O processo ocorre da seguinte maneira:
Por ter este funcionamento, o collector Concurrent năo realiza compactaçăo. Desta forma, fica-se sujeito ŕ fragmentaçăo de memória, que pode gerar um problema de alocaçăo quando o espaço disponível entre os blocos de memória é insuficiente para a alocaçăo de um objeto. Quando isto acontecer, entrará em açăo um outro collector que realizará uma Major collection com direito a compactaçăo da memória heap no final de seu ciclo.
O collector Concurrent pode ser explicitamente escolhido utilizando a opçăo da JVM: -XX:UseConcMarkSweepGC. Esta opçăo seleciona as implementaçőes ParNew (para Young generation), CMS e Serial Old (ambos para Tenured generation). Neste caso, primeiramente tentará utilizar CMS, mas se houver problemas de fragmentaçăo, utilizará Serial Old.
É possível personalizar seu funcionamento com a seguinte opçăo da JVM:
O collector Concurrent possui um modo onde as fases concorrentes acontecem de forma incremental, chamado de Incremental Concurrent (também conhecido como i-CMS ou Train). Neste modo, quando múltiplas threads estăo trabalhando no processo de Garbage Collection, o trabalho a ser feito é dividido em pequenas porçőes que săo agendadas para acontecer entre Minor collections. Foi projetado para oferecer baixo tempo de pausa sem consumir muito throughput, sendo ideal para máquinas com número pequeno de processadores (como 1 ou 2).
Uma particularidade deste modo é o uso de duty cycle para controlar a quantidade de trabalho que deve ser realizado antes do collector devolver o processador para a aplicaçăo. Duty cycle é a porcentagem de tempo de Minor collections que este collector pode utilizar.
O processo ocorre da seguinte maneira:
O collector Incremental Concurrent pode ser explicitamente escolhido utilizando as opçőes da JVM: -XX:UseConcMarkSweepGC e -XX:+CMSIncrementalMode. Estas opçőes selecionam as implementaçőes ParNew (para Young generation), i-CMS e Serial Old (ambos para Tenured generation). Novamente, primeiramente tentará utilizar i-CMS, mas se houver problemas de fragmentaçăo, utilizará Serial Old.
É possível personalizar seu funcionamento com as seguintes opçőes da JVM:
Conforme já discutido, o melhor collector para uma aplicaçăo depende de vários fatores, como o porte da máquina a ser utilizada, a maneira que a aplicaçăo utiliza a memória heap em termos de alocaçăo, o tempo de vida dos objetos, a importância de maximizar o throughput ou minimizar o tempo de pausa, entre outros fatores. Assim, é necessário um estudo mais aprofundado para identificá-lo.
No entanto, é proposto aqui um ponto de partida para identificar o collector mais adequado. Em seguida, sugere-se analisar o tempo gasto com collection por meio de opçőes da JVM, realizar testes de performance e testar diferentes configuraçőes buscando cada vez mais otimizaçăo.
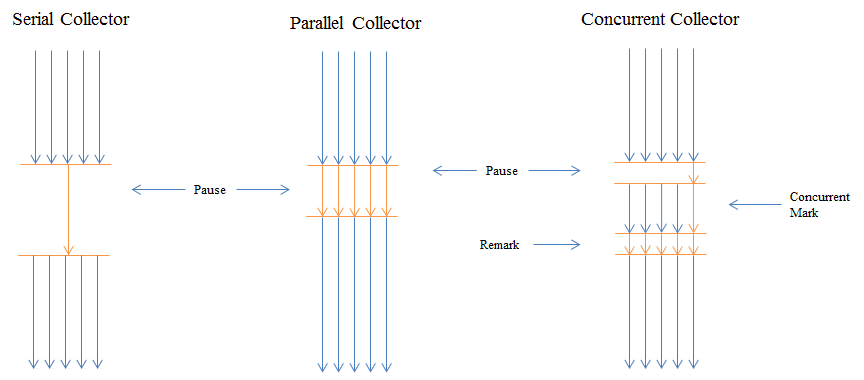
A Figura 5 resume os intervalos de pausa entre os tręs collectors apresentados. Cada seta representa uma thread; as setas de cor azul săo threads da aplicaçăo e as setas de cor laranja săo threads de collectors.
Como regra geral, a menos que seja muito importante ter um tempo de pausa baixo, é recomendado primeiramente deixar a JVM escolher e configurar o collector a ser utilizado através de Ergonomics.
Se a performance năo estiver suficiente, recomenda-se o seguinte:
Note que estas recomendaçőes năo garantem que os tempos de pausa sempre serăo menores que um segundo ou que o throughput sempre será alto, visto que a JVM HotSpot é năo-determinística, ou seja, ela trabalha buscando uma boa combinaçăo geral de fatores a troco de abstrair certos detalhes internos do programador. Para ter garantias reais, é necessário utilizar outros tipos de JVM, como por exemplo, as que implementem a JSR-1, também conhecida como Real-Time Specification for Java (RTSJ).
Se o collector recomendado năo alcançar a performance desejada, a primeira personalizaçăo a ser feita é o ajuste do tamanho da memória heap. Além disso, pode-se alterar os tamanhos das generations. Este é um fator muito sensível, pois uma Young generation muito grande pode aumentar o throughput mas prejudicar o tempo de pausa, visto que as collections que acontecerem nesta generation demorarăo mais. Em contrapartida, uma Young generation muito pequena diminuirá o tempo de pausa, mas prejudicará o throughput.
Se ainda assim năo houver sucesso com relaçăo ŕ performance, busque utilizar o collector Concurrent para reduzir tempos de pausa e o collector Parallel para aumentar o throughput em uma máquina com múltiplos processadores.
A JVM HotSpot 7 basicamente manteve os collectors Serial e Parallel, porém decidiu substituir Concurrent por Garbage First, um novo collector considerado como o próximo estágio de evoluçăo dos algoritmos generacionais, ao menos em teoria.
O collector Garbage First (também conhecido como G1) é generacional e realiza collections em paralelo, assim como seus antecessores Parallel e Concurrent. O objetivo deste collector é possibilitar simultaneamente alto throughput e alta probabilidade de cumprir tempos de pausa pré-definidos (Garbage First é, portanto considerado um collector suave de tempo real). Foi projetado para sistemas com múltiplos processadores e com grande quantidade de memória.
Para alcançar seu objetivo, o collector Garbage First particiona fisicamente a memória heap em regiőes de mesmo tamanho. Deste modo a separaçăo entre generations é meramente lógica. Algumas regiőes serăo atribuídas a Young generation, outras serăo a Tenured e as restantes a Permanent.
Assim como Concurrent, Garbage First possui uma fase de marcaçăo concorrente, onde busca identificar as regiőes cheias de objetos năo-alcançáveis, que seriam idealmente coletadas primeiro. Para tal, é calculado o índice de liveliness destas regiőes, o que representa a quantidade de objetos alcançáveis que cada regiăo contém no momento.
O processo de collection é feito através de pausas para evacuation, onde Garbage First seleciona determinadas regiőes, identifica os objetos sobreviventes dentro destas regiőes, os copia para outras regiőes e finalmente reclama o espaço total das regiőes primeiramente selecionadas. Ao selecionar regiőes, dá prioridade ŕquelas com menor liveliness, ou seja, com mais objetos a serem coletados. Seu nome Garbage First surgiu por causa desta ideia, que busca maximizar a quantidade de objetos coletados por cada execuçăo de collection, o que significa uma otimizaçăo no processo convencional de collection.
A maioria das pausas para evacuation coleta regiőes pertencentes ŕ Young generation, tal como os outros collectors, mas por vezes algumas regiőes pertencentes ŕ Tenured generation săo também selecionadas junto com as primeiras para serem coletadas na mesma pausa para evacuation.
Outra particularidade é a respeito de Garbage First conseguir cumprir tempos de pausa pré-definidos com alta probabilidade de acerto, devido ao fato que a granularidade das collections é por regiăo e năo por generation, tendo desta forma objetivos menores e menos propensos a atrasos. É muito mais preciso estimar o tempo de collection de uma regiăo em comparaçăo a toda a generation, e assim Garbage First utiliza esta estimativa para decidir quantas regiőes deverăo ser coletadas para cumprir o tempo de pausa desejado pelo usuário. Além disso, Garbage First tem autorizaçăo para diminuir um pouco o throughput em favor do cumprimento mais preciso deste tempo de pausa.
O collector Garbage First visa substituir Concurrent por resolver dois problemas que o último possui: fragmentaçăo e baixo determinismo com relaçăo ao tempo de pausas (pois quando a fragmentaçăo chega ao seu limite, será necessário chamar um collector como SerialOld para coletar e compactar a memória heap toda, ocorrendo inesperadamente um tempo de pausa muito alto). O primeiro problema é resolvido por compactaçăo, visto que Garbage First é um compacting collector, e o segundo problema é resolvido pela carga menor de trabalho de cada collection, visto que apenas determinadas regiőes săo coletadas por vez.
Garbage First foi introduzido na JVM HotSpot 6 update 14 de forma experimental e pode ser explicitamente escolhido utilizando as opçőes da JVM: -XX:+UnlockExperimentalVMOptions -XX:+UseG1GC. Na JVM HotSpot 7 apenas o segundo parâmetro é necessário.
É possível personalizar seu funcionamento com as seguintes opçőes da JVM:
Um último detalhe é que Garbage First é muito mais verboso que os outros collectors da JVM HotSpot quando utilizando a opçăo -XX:+PrintGCDetails, pois pretende fornecer mais informaçőes para troubleshooting.
Este artigo visou demonstrar que, embora apresentem diferenças marcantes, os collectors da JVM HotSpot buscam resolver o mesmo problema, porém apresentando certas especialidades adequadas a determinados cenários. Basta saber identificar o collector mais adequado, experimentá-lo e analisar seu desempenho a fim de otimizar seu funcionamento por meio de opçőes da JVM. É também importante verificar se todos os objetivos de um determinado collector estăo em conformidade com as necessidades do cenário em questăo.
A seguir, as próximas partes desta sequęncia de artigos pretendem explorar collectors de outras JVMs, em particular as JVMs de tempo real; apresentar como desenvolver código para otimizar a utilizaçăo de memória e facilitar a vida do collector; e como analisar a situaçăo da memória heap e do Garbage Collection por meio de ferramentas especializadas. Até breve!


Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.